










24年10月来自清华和CMU的论文“Inference Scaling Laws: An Empirical Analysis Of Compute-optimal Inference For LLM Problem-solving ”。
虽然大语言模型 (LLM) 训练的规模化规律已得到广泛研究,但 LLM 的最佳推理配置仍未得到充分探索。本文研究推理规模化规律和计算-最优推理,重点关注模型大小和使用不同推理策略生成额外tokens之间的权衡。作为理解和设计计算-最优推理方法的第一步,研究贪婪搜索、多数投票、n 选一、加权投票和两种不同的树搜索算法等推理策略的成本-性能权衡,使用不同的模型大小和计算预算。本文研究结果表明,在给定相同计算预算的情况下,较小的模型(例如 Llemma-7B)可以胜过较大的模型,并且较小的模型与高级推理算法配对可产生Pareto最优的成本-性能权衡。例如,配备新树搜索算法的 Llemma-7B 模型在所有 FLOPs 预算上在 MATH 基准测试中始终优于使用标准多数投票的 Llemma-34B。
神经网络的规模化定律(Hestness,2017;Rosenfeld,2019)已在一系列领域建立,包括语言建模(Kaplan,2020;Hoffmann,2022;OpenAI,2023)、图像建模(Henighan,2020;Yu,2022;Peebles & Xie,2023 年)、视频建模(Brooks,2024)、奖励建模(Gao,2023)和棋盘游戏(Jones,2021)。这些研究表明模型性能如何受模型大小和训练计算量的影响。然而,对于在模型训练后,推理过程中计算的变化如何影响模型性能的知识有限。
过程奖励模型 (PRM) 已成为一种提高 LLM 推理和解决问题能力的技术。这些模型将奖励分配给 LLM 生成序列的中间步骤。事实证明,PRM 可有效选择错误率较低的推理轨迹,并在强化学习式算法中提供奖励(Uesato,2022;Polu & Sutskever,2020;Gudibande,2023)。(Ma 2023) 应用 PRM 对中间步骤给予奖励并指导多步骤推理过程。PRM 可以针对人工标记的数据(Lightman,2023a)或模型标记的合成数据(Wang,2023)进行训练。
为了提高大语言模型 (LLM) 的任务性能,推理技术通常涉及在推理时进行额外的计算作为性能最大化的步骤 (Nye,2021;Wei,2022;Wang,2022b;Yao,2023;Chen,2024b)。计算最优推理必须考虑这些技术的计算成本。例如,蒙特卡洛树搜索 (MCTS) 方法 (Jones,2021) 可能会提高任务性能,但可能需要比简单地多次采样解决方案更多的计算。一般来说,需要全面了解各种推理时间方法(例如,n 中最佳、多数投票 (Wang,2022a;Li ,2023))如何在性能和成本之间权衡。
具体来说,探索如何选择语言模型的最佳大小和有效的推理策略(例如,贪婪搜索、多数投票、n 中最佳、加权投票及其树搜索变型),以在给定的计算预算下最大化性能(即准确性)。让语言模型生成更多tokens,对进一步的候选解决方案进行采样并使用奖励模型对其进行排名,控制固定模型的推理计算(FLOPs)。分析在数学推理基准上,例如,GSM8K 测试集(Cobbe,2021a)和 MATH500 测试集(Hendrycks,2021b;Lightman,2023b),给定不同推理 FLOPs 各种大小微调模型的性能。实验涵盖多个模型系列,包括通用 LLM,例如 Pythia (Biderman,2023) 和 Mistral (Jiang,2023),以及数学专用模型,例如 Llemma (Azerbayev,2023)。
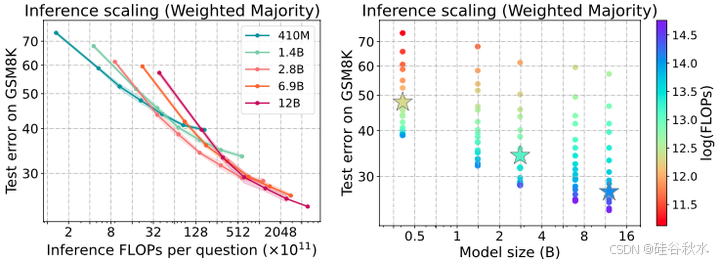
如图所示:Pythia (Biderman,2023) 模型和 GSM8K 测试误差表现出的推理规模化规律。用各种大小和数量的采样解决方案进行加权多数投票,评估模型的错误率(越低越好)。左图:随着推理计算的增加,每种模型大小的错误率稳步下降,最后收敛。右图:最佳模型大小( 241、244 和 2^47 FLOPs 显示为星号)根据推理时间计算预算而变化。例如,较小的模型在 2^41 和 2^44 FLOPs 时计算最佳。图中两个轴都是对数刻度。
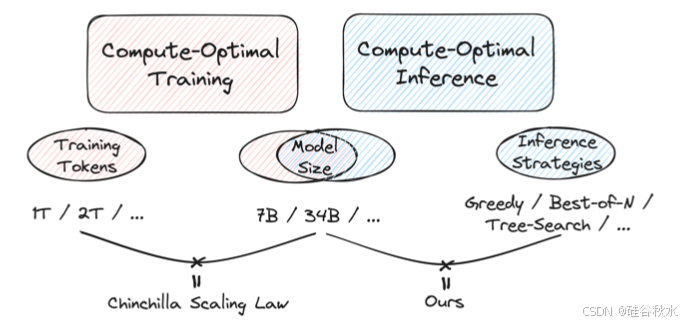
如图所示,探讨以下问题:给定固定的 FLOPs 预算,应该如何为策略模型选择最佳模型大小,以及如何选择有效的推理策略来最大化性能(即准确性)?
为了解决这个问题,将解决的错误率 E(N, T ; S) 表示为模型参数数量 N、生成的tokens数量 T 和推理策略 S 的函数。计算预算 C 是一个基于 N 和 T 的确定性函数 FLOPs(N, T ; S)。目标是在测试-时间计算约束 FLOPs(N, T, S) = C 下最小化 E。
固定模型的推理计算 (FLOPs) 可以通过使用策略模型和推理策略生成更多 token 来调整,例如,对其他候选解决方案进行采样,然后使用奖励模型对其进行排名。作为推理策略,主要考虑与重排名或多数投票相结合的采样和树搜索方法。这包括贪婪搜索、多数投票、n 选一、加权投票及其树搜索变型。
蒙特卡洛树搜索 (MCTS) 已被证明在棋盘游戏等需要战略决策的领域非常有效 (Silver,2016;2017;Jones,2021)。最近的研究表明,将 MCTS 适应 LLM 的环境可以增强文本生成过程 (Zhang,2023;Zhou,2023;Liu,2024;Choi,2023;Chen,2024a;Tian,2024;Chen,2024a)。在此背景下,MCTS 与价值模型配对,以评分和指导探索步骤。
MCTS 或其变型,例如思维树(Yao,2023)的近期研究,主要集中于提高所研究任务的性能(例如,准确性)。然而,在计算预算(以生成的tokens或处理时间衡量)方面,MCTS 与传统方法(如 n 选 1 和多数表决)的一般性比较很少,或者表明潜在不利的成本效益。例如,MCTS 消耗的资源要多得多,通常需要比简单方法多生成几十倍的tokens。具体而言,搜索树中很大一部分路径用于估计和选择节点,这些路径不一定成为最终候选解的一部分,尽管 MCTS 确保采样的解包含高质量的中间步骤。相反,采样方法并行且独立地生成多个解,并且所有生成的序列都包含在候选解中。但是,这些序列中的中间步骤不能保证质量很高,因为没有机制可以修剪较差的步骤或利用有希望的步骤。
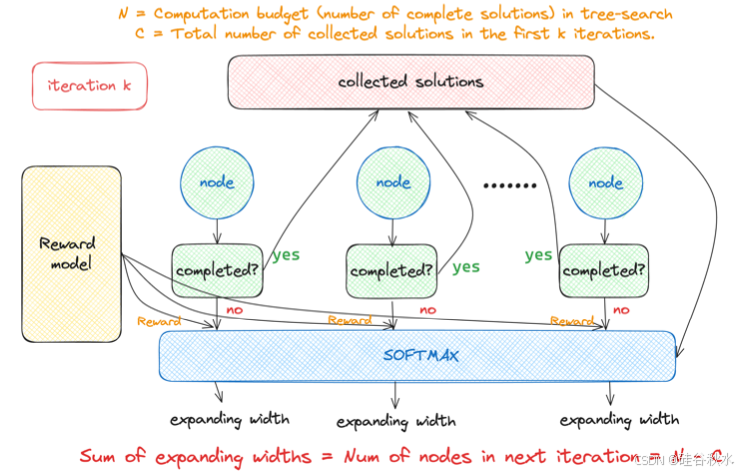
这凸显对一种树搜索方法的需求,该方法可以实现与 MCTS 相当(或更好)的性能,并且计算成本较低,成本与加权多数投票和最佳 n 相似。为此,本文就提出了奖励平衡搜索 (REBASE)。如图所示:REBASE 树搜索方法继承树搜索的利用和修剪属性,同时仅使用奖励模型来估计中间节点的质量。与 MCTS 等方法相比,这节省了计算量,因为它不涉及使用显式部署来估计节点质量。简而言之,基本思想是使用过程奖励模型(PRM)来确定每个节点在每个深度应扩展多少。也就是说,REBASE 根据节点的 softmax 归一化奖励分数在给定深度扩展节点,但要遵守总扩展预算。
实验设置如下。
数据集。在两个数学问题解决数据集上进行了实验,研究推理-计算规模化对具有挑战性的问题和简单问题的影响。具体来说,MATH(Hendrycks,2021a)和 GSM8K(Cobbe,2021b)分别是包含高中数学竞赛级问题和小学级数学推理问题的数据集。接下来(Lightman,2023b;Wang,2024;Sun,2024),用 MATH500 子集作为测试集。
策略模型(解决方案生成器)。为了研究使用固定策略增加推理计算性能如何扩展,变化的主要轴是模型大小。因此,选择 Pythia(Biderman,2023)作为基础模型,因为 Pythia 系列中有各种模型大小。为了研究不同推理策略(例如树搜索、加权多数投票)下的推理扩展,用数学专门的 Llemma 模型(Azerbayev ,2024)。用全参数监督微调(Full-SFT)在 MetaMath 数据集(Yu,2024)上对这些模型进行微调。此外,还测试 Mistral-7B(Jiang,2023),扩展到不同的模型和架构中。
奖励模型。所有实验都使用相同的 Llemma-34B 奖励模型,在合成过程奖励建模数据集 Math-Shepherd (Wang,2024) 上对该模型进行微调。在模型中添加了一个奖励头,使其能够在每个步骤结束时输出标量奖励。
推理配置。用抽样和树搜索方法来生成多个候选答案,并通过 n 选 1、多数投票或加权投票来选择答案。每个配置都会运行多次以计算平均值和方差,从而减轻随机性的影响,从而提高结论的可靠性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









