










24年10月来自 Meta 田博团队的论文“Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces”。
在人类认知理论中,人类思维受两个系统支配:快速而直观的系统 1 和速度较慢但更具深思熟虑的系统 2。最近的研究表明,将系统 2 流程纳入包括大语言模型 (LLM) 在内的 Transformers 中,可显著增强其推理能力。然而,纯粹类似于系统 2 思维的模型需要更高的计算成本,并且响应速度要慢得多。为了应对这一挑战,Dualformer,提出一个无缝集成快速和慢速推理模式的单一 Transformer 模型。Dualformer 通过对随机推理轨迹的数据进行训练获得,其中轨迹的不同部分在训练期间被丢弃。丢弃策略是根据轨迹结构专门定制的,类似于分析人类思维过程并使用模式创建短路方式。在推理时,模型可以配置为仅输出解决方案(快速模式)或推理链和最终解决方案(慢速模式),或者自动决定采用哪种模式(自动模式)。在所有情况下,Dualformer 在性能和计算效率方面均优于相应的基线模型:(1)在慢速模式下,Dualformer 以 97.6% 的时间对未见过的 30×30 迷宫导航任务进行最佳解决,超过了 Searchformer(使用具有完整推理轨迹的数据训练)基线性能的 93.3%,同时仅减少了 45.5% 的推理步骤;(2)在快速模式下,Dualformer 以 80% 的最佳速率完成这些任务,明显优于仅解决方案模型(使用仅有解决方案的数据训练),该模型的最佳速率仅为 30%;(3)在自动模式下运行时,Dualformer 实现了 96.6% 的最佳速率,同时与 Searchformer 相比减少了 59.9% 的推理步骤。对于数学问题,该技术也通过 LLM 微调实现了更高的性能,显示出其超越任务特定模型的泛化能力。
在心理学中,双重过程理论(Wason and Evans,1974)解释了思维可以通过两个不同的过程产生。通常,一个过程是隐性的(自动和无意识的),另一个过程是显性的(受控和有意识的)。著名著作《思考,快与慢》(Kahneman,2017)广泛探讨了双重过程理论的概念。它描述了两种不同的思维系统。系统 1 对应于隐性过程,快速、直观和情绪化。系统 2 对应于显性过程,速度较慢、更具深思熟虑和更具逻辑性。Kahneman 将这一理论应用于广泛的认知和行为活动,以说明这两个系统如何影响人类的决策和推理。正如书中所概述的,系统 1 可能导致偏见,并且由于缺乏自愿控制而容易出现系统性错误。作为一种平衡,系统 2 更适合需要仔细分析、考虑和规划的任务。
Transformer (Vaswani,2017) 是一种序列建模工具,是大语言模型 (LLM) (Dosovitskiy,2020;Baevski,2020;Radford,2021;Touvron,2021;Hsu,2021;Touvron,2023;Dubey,2024) 等各个领域基础模型的基石,已广泛应用于许多研究解决推理和规划问题,例如参见 (Zhou 2022);(Kojima 2022);(Pallagani 2022);(Valmeekam 2023a);(Chen 2024);(Gundawar 2024); (Wang & Zhou 2024)。有趣的是,双重过程理论可以推广到人工智能,可以将 Transformer 的推理模式分为快速和慢速。在快速模式下,Transformer 将直接输出最终解决方案而无需任何推理步骤,而在慢速模式下,中间的思考步骤(例如用于寻找短路径的搜索轨迹)将与规划一起生成。这两种推理模式与人类固有的两种思维系统有着相似的优点和缺点。如之前论文所讨论的(Wei,2022b;Valmeekam,2023b;Lehnert,2024;Gandhi,2024;Saha,2024),在快速模式下运行的模型,具有较低的计算成本并允许更快的响应,但与慢速模式模型相比,它们的准确性和最优性有所欠缺。这就引出了一个问题:
能否将快速和慢速模式都融入到基于 Transformer 的推理智体中,就像人类拥有两个不同的思维系统一样,并让它们相互补充?
已经提出了多种方法。一种流行的范例是从纯系统 2 开始,然后进行微调以使其像系统 1 一样更高效,例如将系统 2 的输出提炼到系统 1(Yu,2024;Deng,2024),或者通过蒸馏(Wang,2023;Shridhar,2023)或从符号系统引导,例如 Searchformer(Lehnert,2024)、搜索流(Gandhi,2024),来提高现有系统 2 的推理效率。然而,在这些情况下,需要进一步微调,这需要耗费大量的计算资源,而且要让生成的系统在运行过程中更像系统 1 或系统 2 并非易事。为了解决这个问题,(Saha 2024) 设计了一个显式元控制器在两个不同的系统之间切换。
本文工作工作建立在 团队之前(Lehnert 2024) 的工作基础之上。为了执行规划,训练了一个 Transformer 来建模一个token序列,该序列按顺序表示规划任务、A* 算法的计算以及从 A* 搜索中得出的最优解决方案。
token化方法如图所示。作为一个玩具示例,考虑在 3 × 3 迷宫中进行导航任务,其中目标是找到从起始单元到目标单元的一条最短路径,而不会撞到墙单元。A* 算法已成功确定了最佳规划。使用一系列tokens来表达任务和迷宫结构,这也作为 Dualformer 的提示。
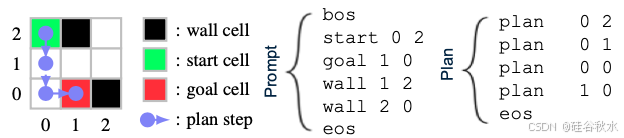
解决方案由使用坐标描述路径的规划tokens序列表示。A* 算法生成一个搜索跟踪序列,记录执行的动态,如图所示。回想一下,A* 算法是加权图上的寻路算法。 create 子句将节点(由后续坐标表示)添加到搜索边界,close 子句将节点添加到封闭集。每个子句(create 或 close)后面都跟有tokens,即 x、y、c0 和 c1,分别表示节点的坐标、自开始以来的成本值和启发式价值。
(Lehnert et al., 2024) 提出的 Searchformer 已被证明能够有效解决各种复杂的决策任务。然而,它仍然受到两个重要限制。
首先,该模型仅在慢速模式下运行,并输出冗长的推理链,这显著增加了推理时间。虽然可以通过 bootstrapping (Lehnert et al., 2024) 来减少这一时间,这是一种迭代细化技术,由展开的循环和微调组成,但这样的过程会对计算资源产生显著的额外需求。
其次,Searchformer 难以生成多样化的解决方案,其中经常会采样相同的展开。例如,在测试的 1000 个 30 × 30 迷宫问题中,Searchformer 的推理链平均包含 1500 多个tokens,并且只能在 64 个响应中找到 7.6 条唯一可行路径。
为了应对这些挑战,本文提出一个利用随机推理轨迹的训练框架。其方法受到两条工作的启发。首先,尽管 Searchformer 是在完整的 A* 搜索轨迹上进行训练的,但它会生成较短的轨迹来勾勒搜索过程。其次,人类在做决定时经常依赖短路和模式,这一概念被称为系统 1 思维 (Kahneman, 2017)。这些观察结果,加上 dropout 技术 (Hinton, 2012; Srivastava, 2014) 的成功,该技术在训练期间随机从神经网络中丢弃单元,促使探索在框架中使用随机推理轨迹,目标是通过利用其结构化元素并为每个训练示例选择性地删除某些部分来简化 A* 搜索轨迹。
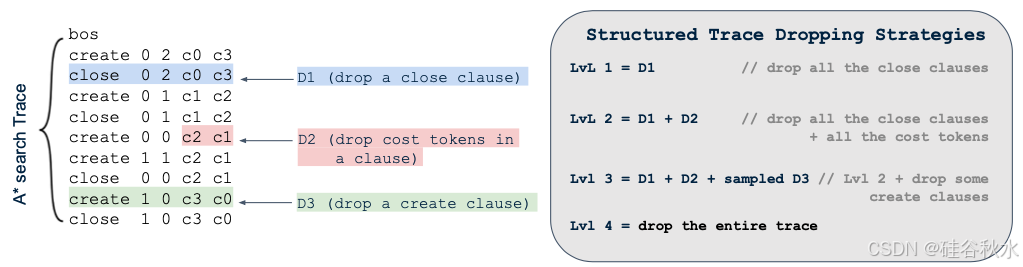
如上图所示,A* 搜索轨迹包含创建create和关闭close子句,每个子句都包含节点的坐标及其到达起点和目标位置的(估计)成本。为了推导 Dualformer,利用搜索轨迹的结构并为每个训练示例丢弃其中的某些部分。有三种自然的丢弃类型:
• D1:丢弃关闭close子句
• D2:丢弃子句中的成本tokens
• D3:丢弃创建create子句
基于它们,开发四个级别的丢弃策略,每个级别都建立在前一个策略的基础上。具体来说,
• 级别 1 策略从搜索轨迹中丢弃所有关闭close子句。
• 级别 2 策略更进一步,额外丢弃所有成本tokens。
• 级别 3 策略更加激进。它进一步随机丢弃 30% 的创建create子句。
• 最终,级别 4 策略丢弃整个轨迹。
如上图使用前面提到的迷宫任务说明了该策略。直观地看,第 1 级丢弃指示 Dualformer 有效地绕过 A* 搜索的闭合集计算,第 2 级丢弃促使 Dualformer 绕过闭合集和成本计算。第 3 级和第 4 级丢弃鼓励 Dualformer 省略某些或所有搜索步骤。这些策略有效地指导 Dualformer 学习更简洁、更高效的搜索和推理过程。
为了促进训练数据的多样性,不将丢弃作为数据预处理步骤。相反,在训练时,对于批次中的每个训练示例,从分类分布 Cat(p0, p1, p2, p3, p4) 中随机抽取丢弃策略,其中 p1, …, p4 是执行第 1-4 级丢弃的概率,p0 是保持完整踪迹的概率。这种训练框架使 Dualformer 能够从多个简化的踪迹中学习,即使对于单个训练示例也是如此,因为同一个例子可能出现在多个批次中。
与 Token 掩码的比较。该训练框架是否类似于 BERT 等 LLM 使用的 token masking 技术 (Devlin, 2018; Liu, 2019; Song, 2019; Gauthier & Levy, 2019; Sinha et al., 2021; Kitouni et al., 2024)?然而,其与那些掩码技术有显著的不同。首先,标准掩码技术通常会随机均匀地掩码一个序列的输入 token。相反,本文的掩码策略仅适用于搜索轨迹。其次,掩码 LLM 通常使用双向注意层并预测被掩码的 token,而 Dualformer 使用因果注意层,训练目标仅仅关注下一个 token 预测,总体目标是提高其推理和规划能力。从计算角度来看,该训练过程也更高效。丢弃token可以缩短输入序列并节省计算量。例如,在 8 块 Tesla V100 32GB GPU 上训练 Dualformer 完成 30 × 30 迷宫任务需要 30 小时,而如果使用完整推理跟踪则需要 36 小时。
以数学推理为例,用包含各种数学问题和答案的数据集对 Llama-3-8B 和 Mistral-7B 模型进行微调,其中包含详细的推理步骤,其中使用一种轨迹丢弃技术,该技术也利用了数学问题推理轨迹的特定结构。将生成的模型与直接在数据集上微调的相应基础模型进行基准测试。
用名为 Aug-MATH 的数据集评估所有模型,该数据集源自 MATH 数据集 (Hendrycks et al., 2021),其中包含 7500 个数学问题和解决方案的训练示例以及 5000 个测试示例。按照 (Yu et al. 2023) 的方法,查询 Llama-3.1-70B-Instruct 模型以重写解决方案,包含更详细的中间步骤,并遵循给定的格式。为了鼓励推理轨迹的多样性,用温度 0.7 和 top-p = 0.9 为每个问题抽样 4 个 LLM 响应。然后,生成的数据集包含 30000 个训练示例和 5000 个测试示例。
Llama-3.1-70B-Instruct 重写的数学问题答案平均包含 6-10 个中间推理步骤,其中每个步骤可能包含多个句子。用框架中类似的随机训练程序。对于批次中抽样的每个训练示例,以概率 p 随机丢弃每个中间推理步骤。
对所有模型进行 2 个 epoch 的训练,使用批次大小为 32。用 AdamW 优化器,对于 Llama 模型,学习率为 5 × 10−6,对于 Mistral 模型,学习率为 8 × 10−6。学习率的选择如下。扫描 3 个值 2 × 10−6、5 × 10−6、8 × 10−6,并选择产生最低验证损失的学习率。然后,用选定的学习率在完整训练数据集上重训练模型并报告结果。对其他超参数使用默认值。更具体地说,不使用线性速率预热、权重衰减或多步梯度累积。对 AdamW 使用 betas=(0.9, 0.999)、eps=1e − 8、γ = 0.85(乘以逐步学习率衰减),并使用“packing”作为批处理策略。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









