










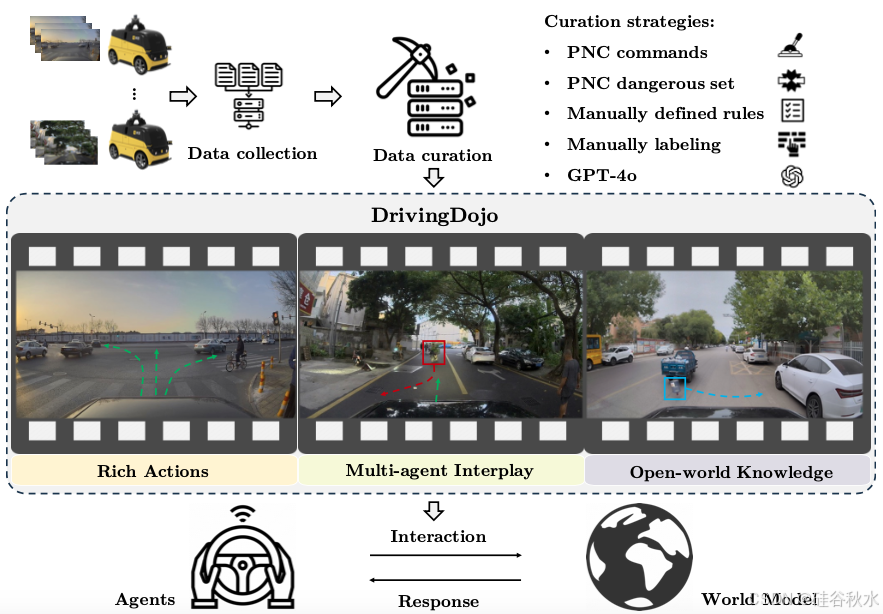
24年10月来自中科院自动化所、中科院大学、美团和中科院香港科学创新研究院的论文“DrivingDojo Dataset: Advancing Interactive and Knowledge-Enriched Driving World Model”。
驾驶世界模型因其能够对复杂的物理动态进行建模而受到越来越多的关注。然而,由于当前驾驶数据集中的视频多样性有限,其出色的建模能力尚未得到充分释放。DrivingDojo,是一个专门为训练具有复杂驾驶动态的交互式世界模型而量身定制的数据集。该数据集包含具有完整驾驶操作、多样化多智体交互和丰富开放世界驾驶知识的视频片段,为未来的世界模型开发奠定了基础。而且为世界模型定义了一个动作指令跟随 (AIF) 基准,并展示了数据集在生成动作-控制的未来预测方面优势。
世界模型 [17, 20, 33, 21] 因其能够模拟复杂的现实世界物理动态而受到越来越多的关注。它们还具有作为通用模拟器的潜力,能够根据不同的动作指令预测未来状态。在视频生成技术 [53, 24, 3, 2] 的推动下,像 Sora 这样的模型在制作高质量视频方面取得了显著的成功,从而开辟了一条将视频生成视为现实世界动态建模问题的新途径 [47, 19, 56]。特别是生成世界模型作为现实世界模拟器具有重大前景,并在自动驾驶领域获得了广泛的研究 [28, 48, 30, 49, 54, 60, 13]。
然而,现有的驾驶世界模型无法满足自动驾驶中基于模型规划的要求,该规划旨在提高具有多样化自我操控以及自车与其他道路使用者之间复杂交互场景中的驾驶安全性。这些模型在非交互式车道中操控方面表现良好,但在遵循变道等更具挑战性的动作指令方面能力有限。构建下一代驾驶世界模型的一个重大障碍在于数据集。当前世界模型文献中常用的自动驾驶数据集,如 nuScenes [6]、Waymo [45] 和 ONCE [37],主要以感知导向的方式设计和整理。因此,它包含有限的驾驶模式和多智体交互,可能无法完全捕捉现实世界驾驶场景的复杂性。交互数据的稀缺限制了模型准确模拟和预测现实世界驾驶环境复杂动态的能力。
如图所示,本文的数据集DrivingDojo 示例。 (a) 展示各种驾驶动作,例如变道、在交通控制处紧急刹车以及在路口转弯。 (b) 说明了自车与其他动态智体的交互,包括切入和切出操作。 © 与摇滚或下落的目标、移动或漂移未知目标的相遇,以及与交通信号灯和栏杆的交互。 (d) 现实世界驾驶场景中遇到的各种极端案例。

如图所示DrivingDojo数据集作为驾驶世界模型开发的垫脚石,其增强世界模型中交互式和知识-丰富的学习。数据在世界建模中起着至关重要的作用。DrivingDojo 是一个大型视频数据集,从数百万个每日收集的视频中精选而出,旨在研究现实世界的视觉交互。DrivingDojo 具有全面的动作、多智体交互和丰富的开放世界驾驶知识,是研究驾驶世界模型的绝佳平台。
将驾驶世界模型用作真实世界模拟器需要它准确地遵循动作提示。现有的自动驾驶数据集,例如 ONCE [37] 和 nuScenes [6],通常都是为开发感知算法而精心挑选的,因此缺乏多样化的驾驶操控。
如表是本文与之前世界模型的驾驶数据集比较。该比较强调视频内容的多样性,较少关注注释或传感器数据。视频是从约 7500 小时的数据库中精选出来的。与表中先前数据集相比,该数据集具有完整的驾驶动作、多样化的多智体交互和丰富的开放世界驾驶知识。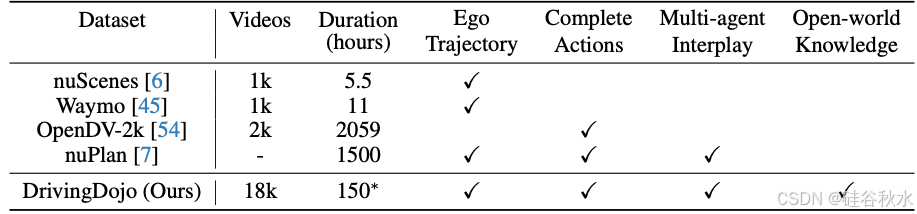
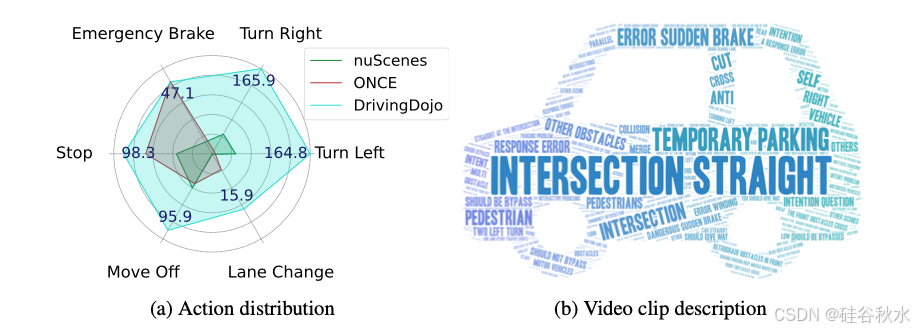
为了使世界模型能够生成无数高保真、可控制动作的虚拟驾驶环境,创建一个名为 DrivingDojo-Action 的子集,其特点是驾驶操控的平衡分布。这个子集包括多种纵向操控,例如加速、减速、紧急制动和走走停停驾驶,以及横向操控,包括变道和车道保持。如图 a 所示,与现有的自动驾驶数据集相比,DrivingDojo-Action 子集提供一组更加平衡和完整的自车动作。
除了在静态道路网络环境中导航外,对多智体相互作用(如合并和让行)进行动态建模也是世界模型的一项重要任务。然而,当前的数据集要么是在没有考虑多智体相互作用的情况下构建的,例如 nuScenes [6] 和 Waymo [45],要么是从缺乏适当管理和平衡的大规模互联网视频构建的,例如 OpenDV-2K [54]。
DrivingDojo 具有多样化的自车动作、与道路使用者的丰富互动以及罕见的驾驶知识,这些对于高质量的未来预测至关重要,如表所示,DrivingDojo 数据集分为三个子集:DrivingDojo-Action、DrivingDojo-Interplay 和 DrivingDojo-Open,以支持特定任务的研究。

为了解决这个问题,设计 DrivingDojo-Interplay 子集,重点关注与动态智体的交互作为数据集的核心组成部分。本文精心挑选这个子集,其包含以下驾驶场景中的至少一个:切入/切出、相遇、阻塞、超车和被超车。这些场景涵盖了各种现实情况,例如车辆切入、遇到迎面而来的车辆以及紧急制动的必要性。通过结合这些不同的场景,该数据集使世界模型能够更好地理解和预测与动态智体的复杂交互,从而提高它们在现实世界驾驶条件下的性能。
以前感知和预测模型将高维传感器输入压缩为低维向量表示,与之相比,世界模型在像素空间中操作表现出卓越的建模能力。这种增加的容量使世界模型能够有效地捕捉开放世界驾驶场景的复杂动态,例如动物意外穿过马路或包裹从车辆后备箱掉落。
然而,现有的数据集,无论是面向感知的 ONCE [37] 还是面向规划的数据集,如 nuPlan [7],都没有足够的数据来开发和评估世界模型的长尾知识建模能力。因此,特别强调包括丰富开放世界知识的视频片段,并构建 DrivingDojo-Open 子集。描述这样的开放世界驾驶知识,具有挑战性,因为它的复杂性和多变性,但这些场景对于确保安全驾驶至关重要。
DrivingDojo-Open 子集包含 3.7k 个关于驾驶场景中开放世界知识的视频片段。该子集是从车队数据中整理出来的,其中包括异常天气、路面上的异物、漂浮障碍物、坠落目标、接管情况以及与交通信号灯和护栏的交互。上图 b 显示 DrivingDojo-Open 视频描述的一个词云。DrivingDojo-Open 是驾驶世界建模的宝贵补充,它包含了驾驶知识,而不仅仅是与结构化道路网络和其他常规道路使用者的互动。
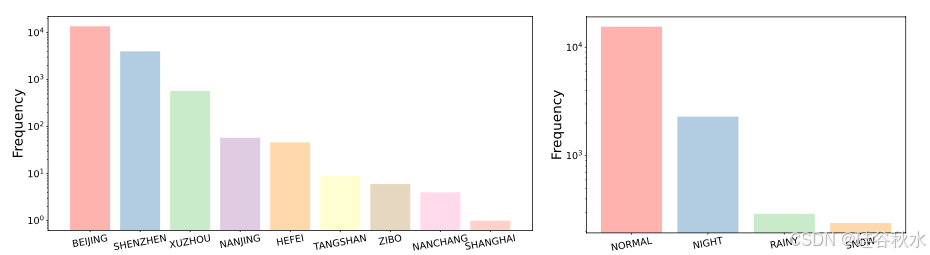
DrivingDojo 数据集包含约 18k 个视频,分辨率为 1920×1080,帧率为 5 fps。视频片段来自中国主要城市,包括北京、深圳、徐州等,如图所示。此外,这些视频是在不同的天气条件下和不同的日光条件下录制的。所有视频都与同步相机姿势配对,这些姿势来自车载 HD-Map 驱动的高精度定位堆栈。DrivingDojo-Open 子集中的视频与关于每个视频中发生的罕见事件文本描述配对。
用美团自动驾驶配送车平台收集多模态车队数据。数据集由前视摄像头录制的视频片段组成,水平视野为 120 度,可捕捉全面的视觉信息。共收集了 900,000 个视频和约 7,500 小时的驾驶镜头,这些镜头在录制前经过了预过滤。
为了确保数据的多样性以及平衡的自车行动和多智体相互作用分布,纳入了具有不同标准的车队数据。 DrivingDojo 的数据来源包括 1)安全检查员在车辆运行期间的干预数据,2)自动紧急制动的数据,3)从收集的视频中随机抽取的 30 秒普通视频,4)选定的不同场景,例如交通信号灯变化、护栏打开、左转和右转、直行交叉口、车辆相遇、变道和行人互动,5)手动分类的稀有数据,包含道路上的移动和静态异物、漂浮障碍物、坠落和滚动物体。
为了避免侵犯隐私并遵守监管法律,用高精度车牌和人脸检测器 [31] 来检测和模糊所有视频每一帧的这些 个人识别信息(PII)。标注团队已手动仔细检查所有视频的 PII 删除程序是否正确执行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









