










24年10月来自斯坦福和伯克利分校的论文“The Scene Language: Representing Scenes With Programs, Words, And Embeddings”。
场景语言,是一种视觉场景表示,可以简明而准确地描述视觉场景的结构、语义和身份。它用三个关键组件来表示场景:指定场景中实体的层次和关系结构的程序、总结每个实体语义类别的自然语言单词,以及捕获每个实体视觉身份的嵌入。给定文本或图像输入,可以通过无需训练的推理技术从预训练语言模型中推断出这种表示。可以使用传统、神经或混合图形学渲染器将生成的场景渲染成图像。总之,这形成了一个鲁棒的自动化系统,用于高质量的 3D 和 4D 场景生成。与场景图等现有表示相比,该场景语言可以生成具有更高保真度的复杂场景,同时明确地对场景结构进行建模,以实现精确的控制和编辑。
如图所示:使用场景语言进行结构化场景生成和编辑。其开一个场景表示,用于 3D 场景生成和编辑任务。给定文本场景描述,可以通过预先训练的大语言模型推断表示,以 3D 形式呈现,并按照语言指令进行编辑。该表示包含一个程序,该程序由绑定到单词的语义感知函数组成,提供高可解释性和直观的场景编辑界面,以及允许使用精细控制进行编辑的嵌入,例如,通过更新控制场景全局属性的 将 <z1*> 的样式从用户输入图像迁移到生成的场景。
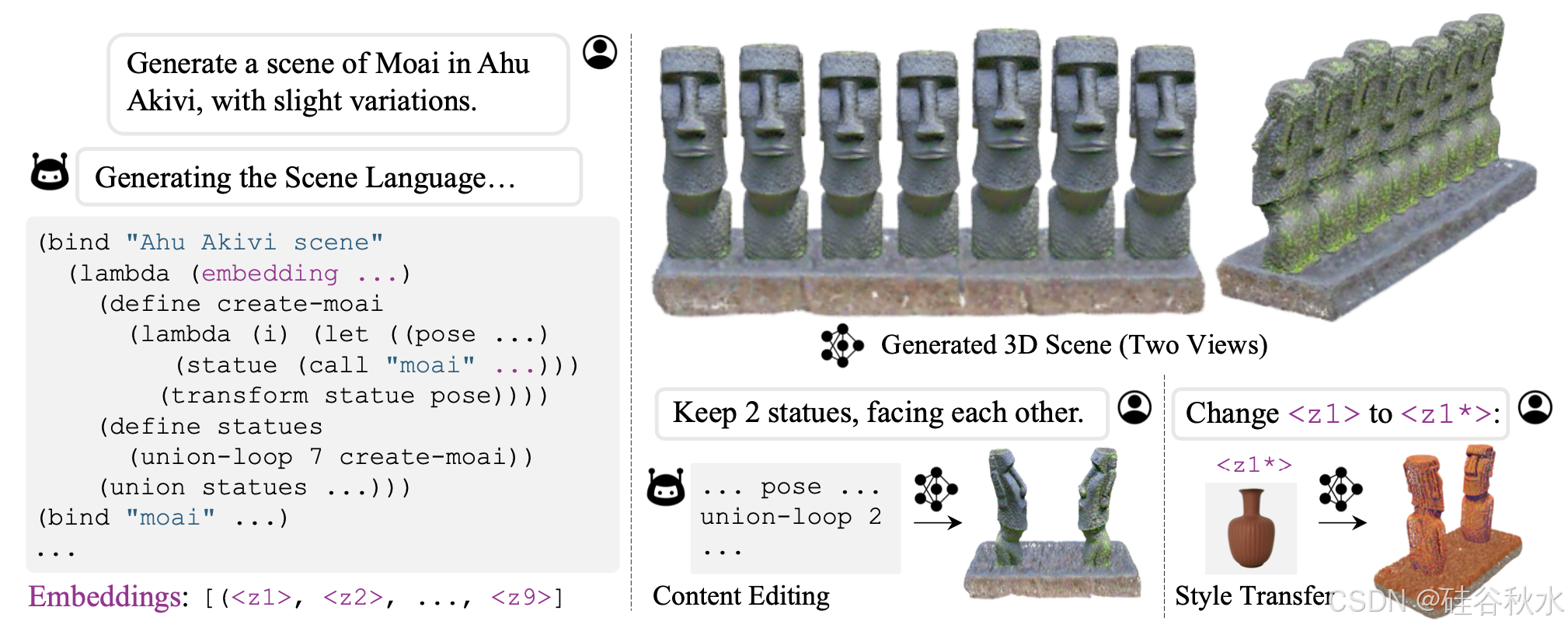
如何描述一个场景?想象一下,刚刚去了复活节岛,想向爱丽丝解释阿胡·阿基维的奇妙场景:“一排排七个摩艾石像,面朝同一个方向。”“什么是摩艾石像?”爱丽丝问道。“摩艾石像是一种没有腿的石人像,但每个石像看起来也略有不同。”此时,仅使用自然语言似乎很难准确地解释这个场景。
事实上,这个例子强调了一个完整的场景表示需要至少三种类型的互补信息:结构知识,即多个实例的联合分布,如“一排排七个摩艾石像,面朝同一个方向”,最自然地描述为程序;类别级语义,可能在实例之间共享,通常用文字描述,如“摩艾石像”;实例级内在属性,与每个特定目标或部分的身份相关,例如其几何形状、颜色和纹理,很难描述但很容易识别。
现代人工智能技术为这三种模态提供了自然基础,但还未能涵盖所有方面:预训练语言模型 (LM) 的上下文学习可以实现特定领域的程序推理 (Brown,2020);LM 可以根据自然语言中的单词捕获丰富的语义信息;通过文本反转 (Gal,2023) 或低秩自适应(LoRA)等技术获得的嵌入可以最好地捕获目标身份 (Hu,2022) 。然而,这些现有表示中的任何一种都不足以用于场景生成和编辑。
视觉场景表征可以说是计算机视觉中最基本的问题。
场景表征为程序
程序不仅可以指定场景组件之间的关系,还可以指定层次结构和重复等结构模式,使其适合作为场景结构的明确描述。先前的研究提出使用以执行命令序列形式的程序作为以目标为中心的表示,然后使用神经执行器将程序渲染为 3D 形状(Tian,2019;Sharma,2018;Deng,2022)。相比之下,ShapeAssembly(Jones,2020)在其程序表示中引入了具有语义上有意义的函数名(例如“椅子”和“靠背”)的高级函数。ShapeAssembly 采用了函数抽象的设计原则,这使得组件之间的层次关系清晰,程序可编辑性更好。然而,ShapeAssembly 使用长方体作为形状表示,不对外观进行建模。
上述所有表示都需要 3D 数据集进行训练。最近,随着语言模型 (LM) 的发展,一些方法 (Zhou et al., 2024b; Hu et al., 2024; Yamada et al., 2024; Sun et al., 2023; Zhang et al., 2023a; Tam et al., 2024) 提出使用零样本 LM 推理来生成将渲染到场景中的程序。这些方法在特定图形学渲染器(例如 Blender)的程序语法之上运行(Community,1994),并且它们不允许在高维嵌入空间中使用参数。
用语义图表征场景
先前的语义场景表示通常采用图来编码语义场景组件,例如目标和部分。特别是,(Yuille & Kersten 2006);(Huang2018)提出使用上下文无关语法的解析图来表示场景,使用终端节点对应目标及其属性。两项工作都采用分析综合的方法从严重依赖域特定先验的图像中推断表示。替代表示包括场景图(Johnson,2015;2018;Gao,2024),其中图中的每个节点对应一个目标,一条边对应一个成对关系,以及 StructureNet(Mo,2019),它专注于以目标为中心的设置并使用节点表示目标部分。虽然这些表示保留了场景或目标的高级语义,但它们忽略了低级精度;因此,语言或手工规则无法完全指定的几何、纹理或关系细节通常会被忽略。
用生成模型潜空间表示场景
视觉生成模型的潜空间可以作为视觉场景的表示空间。这种潜空间可以有效地捕捉场景的精确视觉内容,包括几何和外观细节,并且可以直接推断,例如在变分推理(Kingma,2014)和模型反演(Zhu et al., 2016)中。最近,文本-到-图像的扩散模型,在图像合成中表现出了显著的效果。这类模型提供了几个候选表示空间,包括文本嵌入空间(Gal et al., 2023)、低秩网络权重(Hu et al., 2022)、全模型权重(Ruiz et al., 2023)或扩散过程中的噪声向量(Song et al., 2021; Mokady et al., 2023; Ho et al., 2020)。然而,这种表示通常不提供可解释的语义或明确编码分层场景结构。
目标是设计一种视觉场景表示,对场景的结构、语义和视觉内容进行编码。为了实现这一目标,提出场景语言,它用三个组件来表示场景:一个程序,通过指定场景组件的存在和关系来编码场景结构,称为实体;自然语言中的单词,表示场景中每个实体的语义组;神经嵌入,通过允许富有表现力的输入参数空间来涉及实体的低级视觉细节和身份。
场景语言概述如图所示。场景语言用三个组件来表示场景:由实体函数组成的程序、表示实体函数语义类别的一组单词(例如 pawn)以及捕获场景中每个实体身份的嵌入列表(例如 )。每个实体函数都与单词给出的实体类名绑定,并将输入嵌入映射到该类的输出实体。执行程序可以有效地计算所有实体;计算图显示在右侧。实体依赖关系(如箭头所示)反映了场景中实体的层次关系。

场景 s 的场景语言,表示为 Φ(s),正式定义如下:
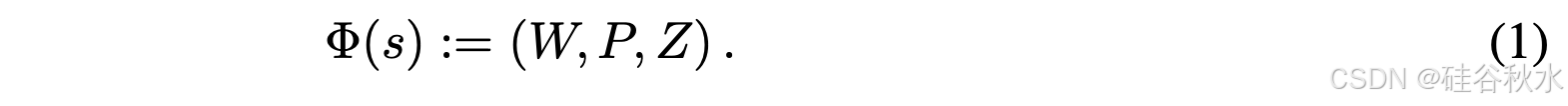
W 是自然语言中的短语集合,称为单词,而 P := {f/w} 是由一组以 w ∈ W 为索引的实体函数 f/w 组成的程序。特定场景 s 的完整场景语言 Φ(s) 还包含一组有序的神经嵌入 Z := [z/1 , z/2 , · · · , z/J ],对应于场景 s 中的 J 个特定实体 [h/1, h/2, · · · , h/J ],其中 h/j ∈ J 通过在输入 z/j ∈ Z、γ/j ⊂ Z 上应用实体函数计算。
至关重要的是,程序 P 从三个方面捕获场景结构。首先,每个实体函数 f/w ∈ P 将多个子实体(例如 64 个方块)转换并组合成一个新的、更复杂的实体(例如棋盘),自然地反映场景中的层次结构、部分与整体的关系,如上图的箭头所示。其次,多个实体 h/j 可能属于同一语义类 w(例如方块),因此可以通过重复使用具有不同嵌入 z/j 的同一实体函数 fw 来表示。最后,每个实体函数还通过指定子实体在组合过程中的相对姿势来捕获子实体的精确空间布局,例如 64 个方块形成一个 8×8 网格。
实体函数 f/w 输出语义类 w 的实体 h。函数 f/w 接受两个输入:指定 h 身份的嵌入 z,以及包含 h 所有后代实体嵌入的有序集 γ。f/w(z, γ) 递归定义为
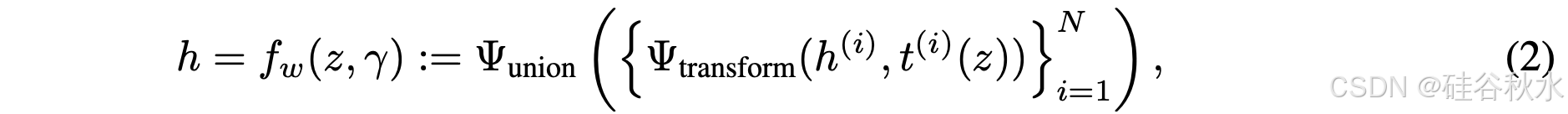
fw 指定了通过两个操作从 N 个子实体 {h(i)} 获取输出 h 的计算过程:Ψ/transform 将输入相关的姿势 t(i)(z) 应用于子实体 h^(i),将其从其规范框架转换为 h 的世界框架,Ψ/union 将多个子实体组合成一个实体。
为了从场景语言 Φ(s) = (W, P, Z) 中获得场景 s,程序执行器从 P 中识别一个不依赖于任何其他函数的根实体函数 f/w1(例如,上图中的 w1 = 棋盘),并使用第一个嵌入 z1 ∈ Z 及其余嵌入作为其后代来评估该根函数,γ/1 := [z/2,··· ,z/J] ⊂ Z,以获得 s = f/w1(z/1,γ/1)。
评估 f/w1 (z/1 , γ/1 ) 会将计算递归扩展至其子函数 h/j = f/wj (z/j , γ/j ),如公式 (2) 中定义,获得场景中所有实体 h/j 的完整序列,其中 j = 1,2,··· ,J, z/j ∈ Z, w/j ∈ W。Z 中的顺序对应于从 z1 开始的计算图的深度优先搜索(DFS)。
用下表中指定的域特定语言 (DSL) 具体化前面的定义。为了在 DSL 中定义实体函数,引入宏操作 union(用于 Ψ/union)、union-loop(在 for-循环中评估的实体上调用 union)和 transform(用于 Ψ/transform)。用这四个宏操作和依赖函数的函数调用来定义实体函数。实体函数通过两种特殊形式与 DSL 中的相关词进行标识:bind(将实体函数 f/w 绑定到词 w)和 tries(在给定 w 的情况下检索 f/w 并将 f/w 应用于实际嵌入参数)。如果 w 从未绑定到函数,则它对应于没有子实体的实体函数(即等式 (2) 中 N = 0),在这种情况下,call 返回没有子实体的原始实体。

实体 h(等式 (2))的数据类型表示为 Entity。它存储两个数据字段 Word 和 Embedding,分别描述实体的语义组和身份,并将每个子实体与其在 h 框架中的姿势一起存储。具体来说,Embedding 捕获视觉细节,需要高度富有表现力的表示,例如神经嵌入。用 OpenCLIP-ViT/H(Ilharco,2021)的文本嵌入空间进行参数化,表示为 ZCLIP。它的优势在于,嵌入可以直接从自然语言编码,也可以使用文本反转从图像中推断出来(Gal,2023)。
将所提出的场景表示应用于图像生成任务需要将场景语言 Φ(s) 渲染成图像。为此,首先,程序解释器评估 Φ(s) 以获得实体类型的数据目标。然后,图形学渲染器将实体数据目标映射到其渲染参数空间并将其渲染成最终图像。
渲染如图所示。给定 (a) 中的场景语言,程序解释器执行该程序以获取 (b) 中的数据目标。图形渲染器首先将 (b) 中的数据目标重新参数化到渲染器特定的参数空间中,然后执行渲染操作 R 以获取 (d) 中的最终图像输出。

一个示例渲染器实例化是使用分数蒸馏采样 (SDS) (Poole,2023) 指导,其中 Θ 是可微分的 3D 表示。
对于底层的 3D 表示,用 3D 高斯 splatting (Kerbl,2023),其中将一组 3D 高斯 splatting 到图像平面上来渲染图像;其他可微分的 3D 表示(例如神经场)也将适用。本文实现基于 GALA3D(Zhou,2024c),并使用 MVDream(Shi,2024)和深度调节的 ControlNet(Zhang,2023b)作为指导。
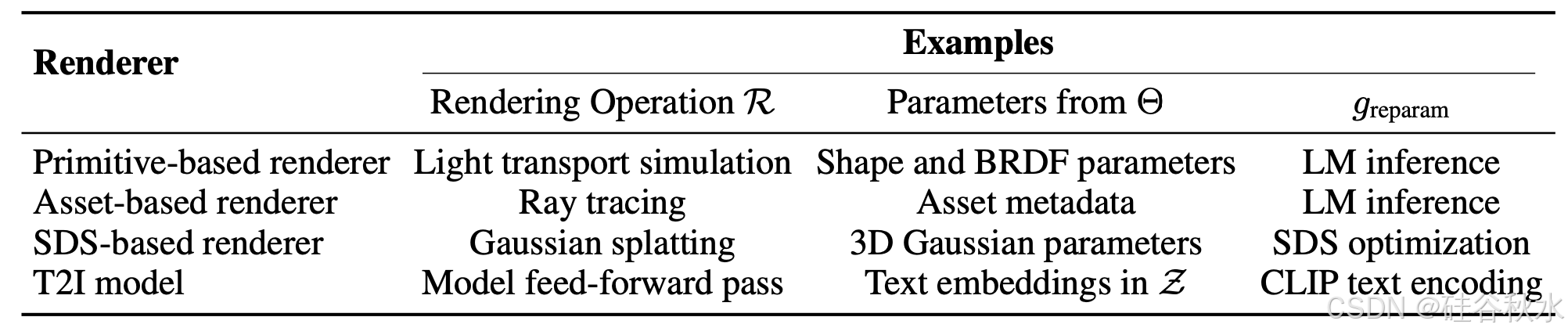
该渲染器称为高斯渲染器。其他可能的渲染器包括基于基元的渲染器,例如具有立方体、球体和圆柱体等图形学基元的 Mitsuba(Jakob,2022);基于资产的游戏引擎,例如 MineCraft(Mojang Studios,2009);以及布局为条件文本-到-图像 (T2I) 扩散模型的前馈推理,例如 MIGC (Zhou et al., 2024a),它通过控制 stable diffusion 的注意层来实现 2D 边框条件 (Rombach et al., 2022))。如表显示图形学渲染器的例子:
在预训练模型的推理中,引入一种无需训练的方法,从场景 s 的文本或图像描述中推断表示 Φ(s) = (W, P, Z)。首先提示预训练的语言模型 (LM) 生成非神经成分 (W,P),然后通过 CLIP 文本编码器从文本中获取神经嵌入 (Z),或使用预训练的文本-到-图像扩散模型从图像中获取神经嵌入 (Z)。
LM 在使用 Python 等常见编程语言的代码生成方面表现出了卓越的能力。在实现中,提示 LM 生成 Python 脚本。用输入条件提示 LM,即文本或图像中的场景描述;一个从域特定语言 (DSL) 转换的辅助函数 Python 脚本;以及使用辅助函数的示例脚本。在该方法和依赖 LM 的基线中,所有实验都使用 Claude 3.5 Sonnet (Anthropic, 2024)。
LM 生成脚本中的函数参数,是数值或字符串tokens,使用语言模板和 CLIP 文本编码器 g/CLIP 转换为来自 Z/CLIP 的嵌入。对于图像条件任务,P 执行输出中的每个原始实体,首先使用 GroundingSAM(Kirillov,2023;Ren,2024)分割出与实体相关单词定义的区域。然后用文本反转(Gal,2023)来优化嵌入,用扩散模型训练目标重建裁剪图像。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









