










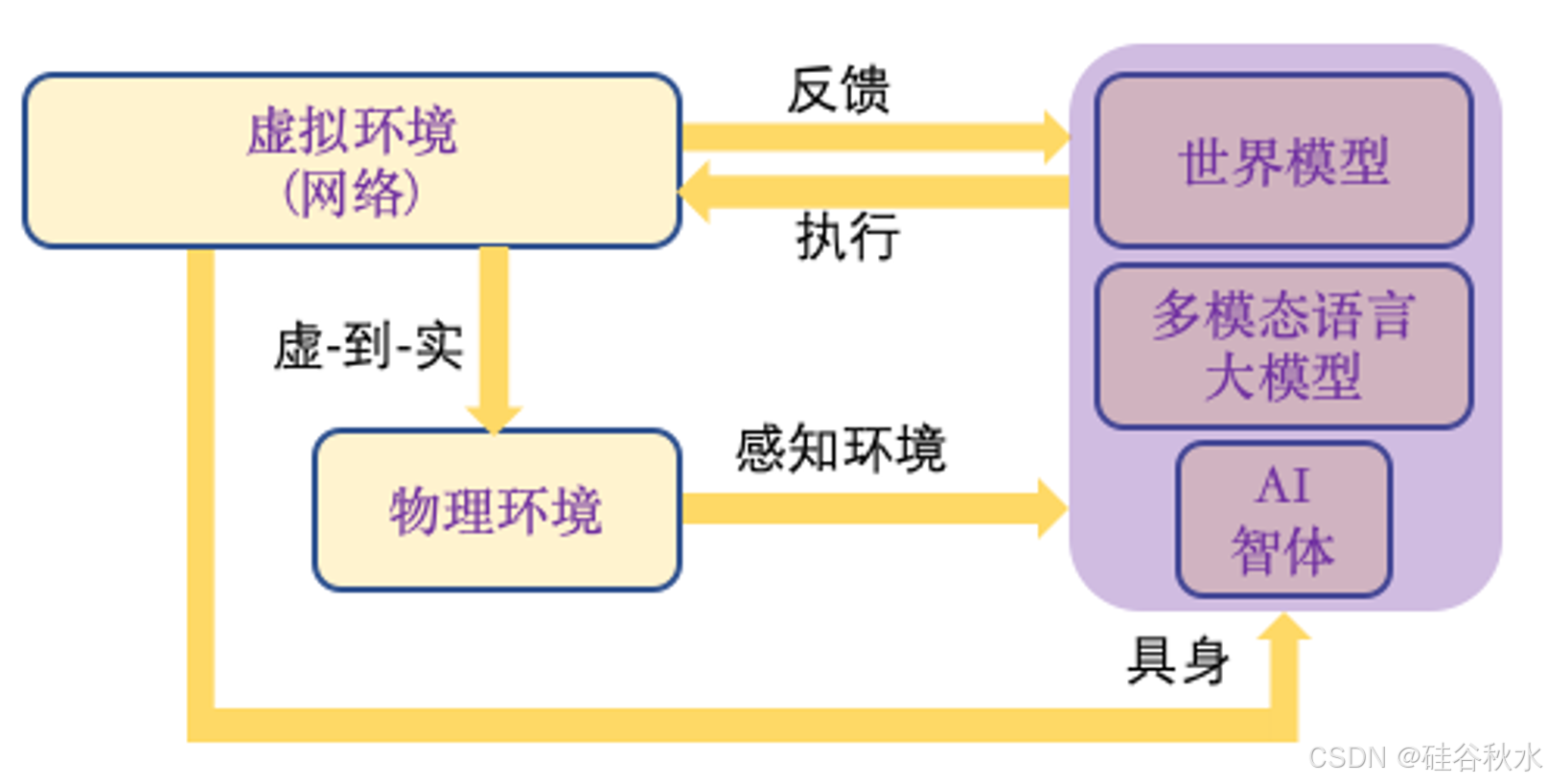
2. 空间人工智能和具身人工智能
2.1 空间人工智能
“主动感知”于 20 世纪 80 年代提出 [1, 2],是指生物体通过移动和改变视点主动收集有关其环境的信息的过程,而“被动视觉”则意味着仅仅接收视觉信息,而无需任何有意的移动或对感官输入的控制。

然而,当时主动感知的目标过于雄心勃勃,因为当时还没有一些革命性的技术,例如良好的视觉特征 (SIFT)、深度传感器 (Kinect)、深度学习模型和 LLM 带来的推理能力。
空间计算 [246] 是一项技术进步,它促进了设备与物理环境的无缝集成,从而在 VR 或 AR 中带来更自然、更直观的数字世界用户体验。

空间人工智能由李飞飞 [292] 提出,并成立了一家初创人工智能公司 World Labs [340],旨在构建大型世界模型来感知、生成和与 3D 世界交互。

可见,空间人工智能并非用于空间计算,而是旨在主动感知,全面理解和建模环境,并由智体进行推理、规划和行动。但空间人工智能并不等同于具身人工智能。
2.2 具身人工智能
具身智能(EI)的概念[310]最早由图灵在1950年建立的具身图灵测试中提出,旨在判断智体是否能够表现出不仅限于解决虚拟环境(数字空间)中抽象问题的智能。
注:人工智能智体是EI的基础,存在于数字空间和物理世界中,并体现在包括机器人和其他设备在内的各种实体中,但也能应对物理世界的复杂性和不可预测性。
因此,发展EI被视为实现AGI的根本途径。 EI 涵盖了 CV、NLP、机器人等多项关键技术,其中最具代表性的是 [238, 241, 310] 具身感知(包括视觉语言导航 [249, 336])、具身交互、具身智能(包括视觉-语言-动作模型 [288, 299])以及虚拟到现实的迁移等。
3. 动作/行为学习方法
机器人操控是指机器人如何智能地与周围的目标互动,例如抓取目标并将其从一个地方搬运到另一个地方。灵巧的操控技能使机器人能够协助人类完成各种可能过于危险或难以完成的任务。
这要求机器人能够智能地规划和控制手臂的运动。目标操控是机器人完成多项任务的关键技能。然而,这也给机器人技术带来了挑战[30, 38, 109, 209, 212, 220, 221, 238, 244, 277, 278, 326]。注意:自动驾驶[210, 324]是EI中的一个特殊领域。
模仿学习(IL)[73]旨在模仿专家行为。一般来说,IL 包括三种主要方法:行为克隆 (BC)、逆向强化学习 (IRL) 和生成对抗模仿学习 (GAIL)。
行为克隆 (BC) 是一种用于机器人动作策略学习的监督学习公式。给定由一系列状态-动作对组成的专家演示数据,训练模型预测给定输入状态(例如图像)的正确动作向量。该框架已被证明非常有效,尤其是在提供足够数量的训练数据时。
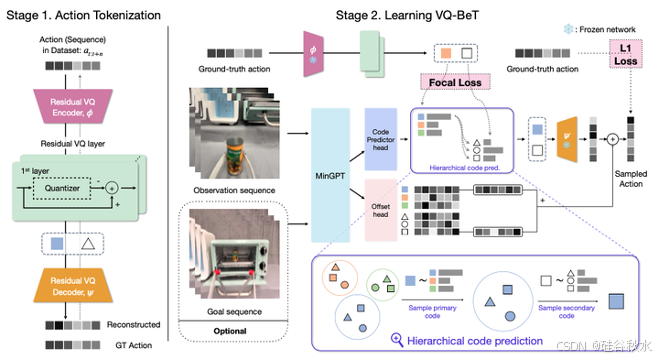
一些 IL 方法可以列如下:Transporter Networks [48]、CLiPort [69]、BC-Z [73]、Behavior transformers (BeT) [93]、WHIRL [97]、Perceiver-Actor [101]、RoboCat [159]、Vi-PRoM [176] 和 VQ-BeT [255]。
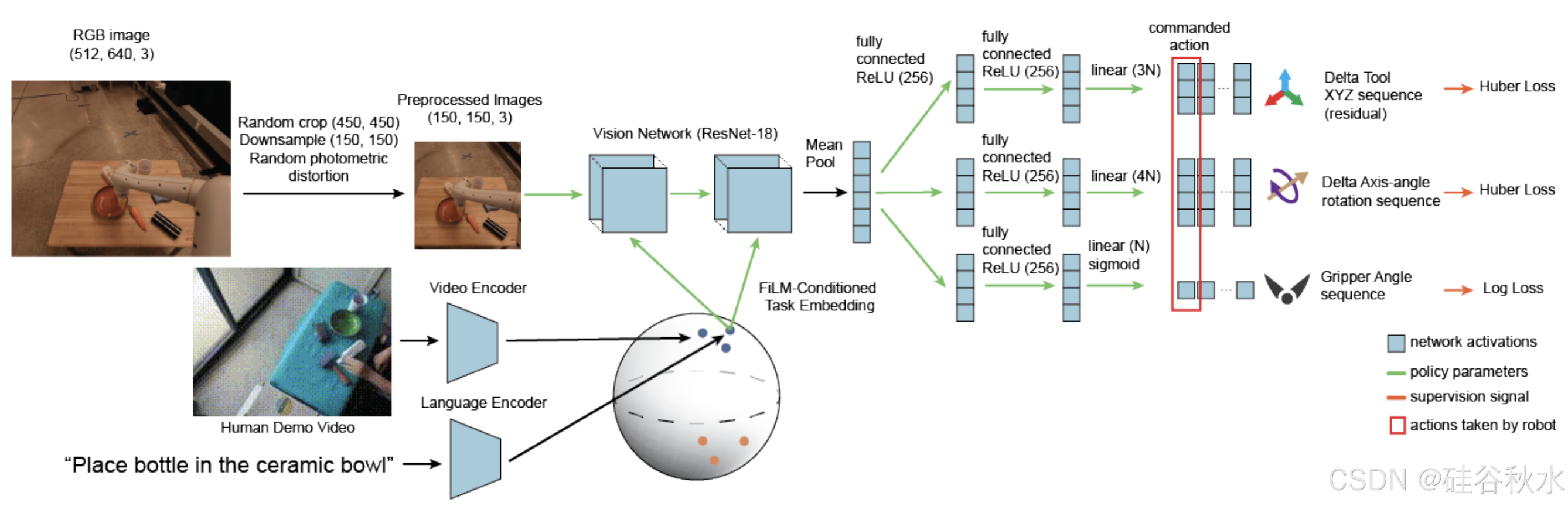
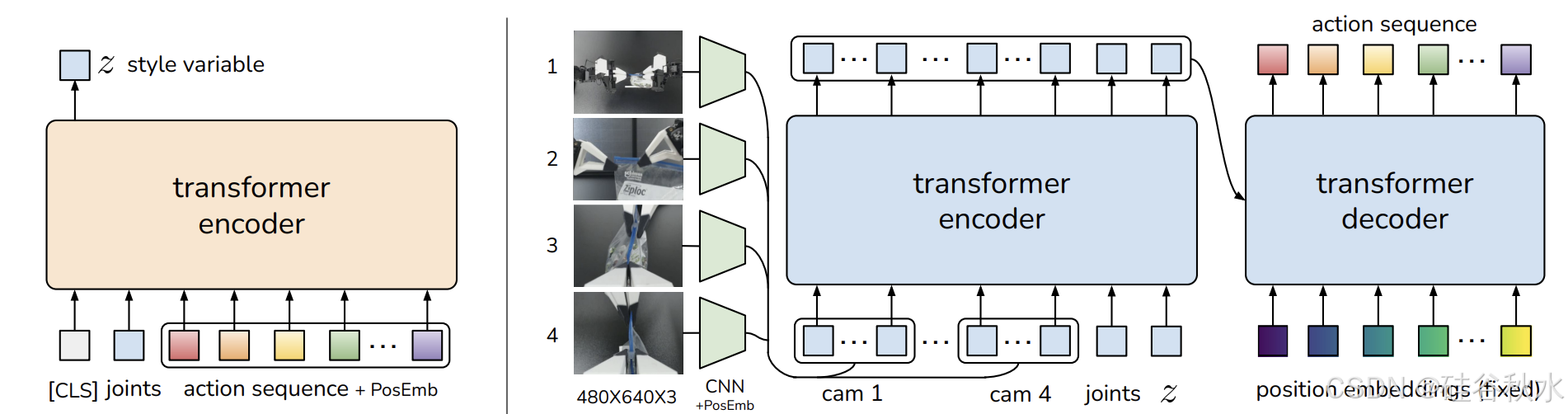
然而,IL 方法也存在自身的挑战,特别是在高精度领域。为了应对这些挑战,加州大学伯克利分校和 ALOHA 远程操作平台 [145] 提出了 Action Chunking with Transformers (ACT),它可以学习动作序列的生成模型。它们的修改版包括 RoboAgent/MT-ACT [182]、Bunny-VisionPro [309]、InterACT [313]、CrossFormer [328]、RUM [332] 和 Haptic-ACT [333]。
基于扩散的策略利用了扩散模型在计算机视觉领域的成功。其中,扩散策略 (DP) [127] 是最早使用扩散进行动作生成的策略之一。与常见的行为克隆策略相比,扩散策略在处理多模态动作分布和高维动作空间方面表现出优势。DP 的其他版本有cross diffusion [163]、3D 扩散策略 [256]、iDP3 [349]、ALOHA Unleashed [350] 和 Dex-Diffuser [361]。
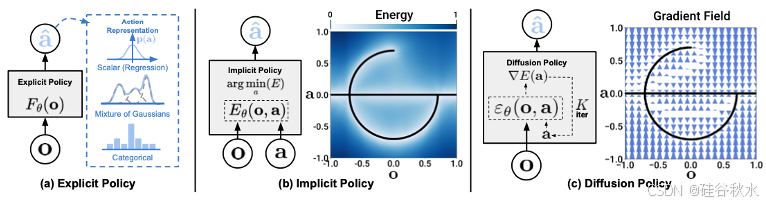
强化学习 (RL) [25, 54, 357] 是一类方法,它使机器人能够通过优化奖励函数与环境交互来优化策略。这些交互通常在模拟环境中进行,有时会使用来自物理机器人硬件的数据进行增强,以实现从模拟到现实的转移。RL 算法分为:(1) 基于模型或无模型,(2) 值函数,以及 (3) 在策略或离策略。
与模仿学习不同,RL 不需要人类的示范,并且(理论上)有可能实现超人的表现。对于 RL 问题,使用从与环境的交互中收集的部署数据来最大化策略的预期回报。以奖励信号的形式从环境中接收反馈,引导机器人了解哪些动作会带来有利结果,哪些不会。
MT-OPT [54] 是一种可扩展且可推广的多任务深度 RL 方法,由用于数据收集的多机器人集体学习系统开发。还有一些使用 Transformer 架构的 RL 方法:decision Transformer [57]、trajectory Transformer [58] 和 OCDM [356]。
注意:世界模型是具身人工智能中用于预测的特殊类别,主要由 RL 和扩散模型实现,将在第 3.1 节中讨论。
机器人操控任务具有高度层次化的结构。一个复杂的任务可以分解成子任务,然后进一步分解成更小的子任务。即使是基本的技能,如抓取或推动,也可以进一步分解成多个面向目标的动作阶段。这种层次结构将主任务分解成更小、更易处理的问题。
机器人可以学习技能策略来执行最低级别的任务,然后以这些技能为动作基础来执行下一级任务。因此,机器人可以逐渐学习技能的分层策略,而由此产生的策略层次反映了任务的层次。
基于LLM的机器人显示出新的方向[209, 212, 220, 221, 238]:LLM为机器人提供了与自然语言交互的能力,使用户能够以直观、便捷的方式与机器人交流;LLM使机器人能够适应不同的任务和环境;LLM使机器人能够更好地与人类协作。因此,机器人可以通过与语言模型的交互来共同解决问题、制定计划和执行任务。
机器人学习方法的粗略分类如下:
• 作为任务规划和执行系统一部分的预训练语言模型:T-LM [76]、Socratic Model [84]、GATO [89]、LATTE [98]、ProgPrompt [102]、LLM-planner [111]、DEPS [121]、Reflexion (LLM + RL) [134]、Self-Refine [136]、Beam search [146]、Embodied-GPT (LLM + Transformer) [149]、SwiftSage [152]、ChatGPT for Robotics [161]、EUREKA [198]、RoboGPT [213]、LAP [265]、Socratic Planner [274];
• 将语言模型应用于机器人控制,并通过动作对模型进行微调,获得可泛化的控制策略:SayCan [85]、Inner Monologue [96]、CaP [99]、Perceiver-Actor (LLM + Transformer) [101]、ReAct [106]、GA [142]、VOYAGER [150]、DoReMi [162]、SayPlan [166]、SUDD (LLM + Diffusion) [171]、PSL (LLM + RL) [280]、Octo [287]、ReAd [289]、Grounding-RL [296];
• 预训练的视觉语言模型被集成用于机器人表征学习,作为任务规划和执行模块化系统的组件:VoxPoser [165]、Concept-Graphs [191]、VLP [197]、Robo-Flamingo [204]、ViLa [215]、SpatialVLM [232]、AutoRT [233]、RoboMamba [294]、RDT-1B (DiT) [345]、DiT-Block Policy [348];
• 端到端学习视觉-语言-动作 (VLA) 模型是该领域最有前途的类别,在第 3.2 节中单独讨论。
3.1 世界模型
通用世界模型 [282, 306] 是实现通用人工智能 (AGI) 的重要方式,是从虚拟环境到决策系统的各种应用的基石。
在与现实世界非常相似的模拟环境中创建世界模型,可以帮助算法在迁移过程中更好地泛化。世界模型方法是构建一个端到端的模型,通过预测下一个状态、将视觉映射到动作,甚至任何映射关系,以生成式或预测式的方式做出决策。
这个世界模型和VLA模型最大的区别在于,VLA模型首先在大规模互联网数据集上进行训练,以实现高级突发能力,然后用现实世界的机器人数据进行微调。相比之下,世界模型是在物理世界数据上从头开始训练的,并随着数据量的增加逐渐发展出高级能力。
这样的世界模型仍然是低级的物理世界模型,在某种程度上类似于人类神经反射系统的机制。这使得它们更适合输入和输出都相对结构化的场景,例如自动驾驶(输入:视觉,输出:油门、刹车、方向盘)或物体分类(输入:视觉、指令、数字传感器,输出:抓取目标物体并放置在目标位置)。它们不太适合推广到非结构化的、复杂的特定任务。
学习世界模型在物理仿真领域有着广泛的应用前景。与传统的仿真方法相比,它具有显著的优势,比如能够推理信息不完全的交互、满足实时计算要求、随着时间的推移提高预测精度等。
这种世界模型的预测能力至关重要,使机器人能够发展出在人类世界中操纵所需的物理直觉。根据世界环境的学习流程,它们可以分为基于生成的方法、基于预测的方法和知识驱动的方法。
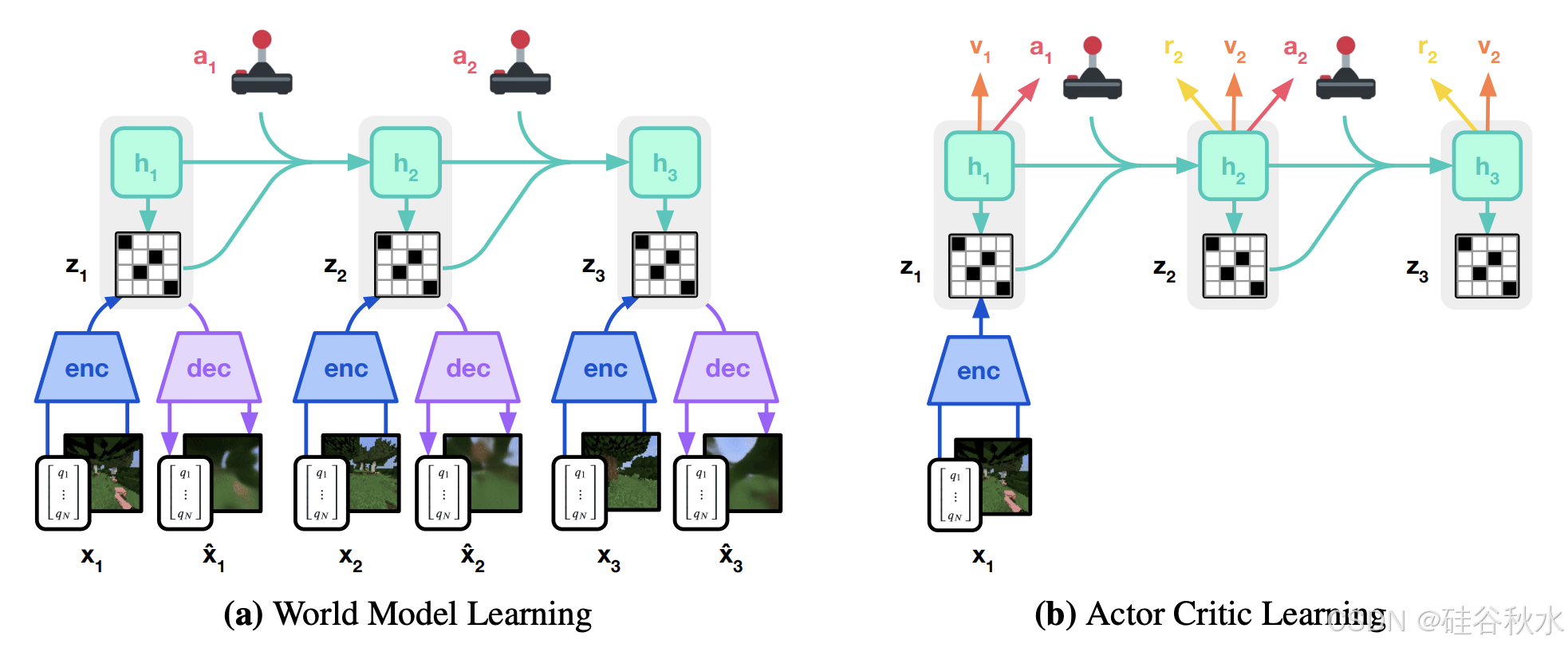
世界模型的架构旨在模拟人类大脑一致的思考和决策过程,集成以下关键组件[306]:感知模块、记忆模块、控制/动作模块,并以世界模型模块为核心。
世界模型能够模拟类似于人类的认知过程和决策。通过整合这些模块,世界模型可以实现对其环境的全面和预测性理解。
世界模型的类别大致分为以下几种:
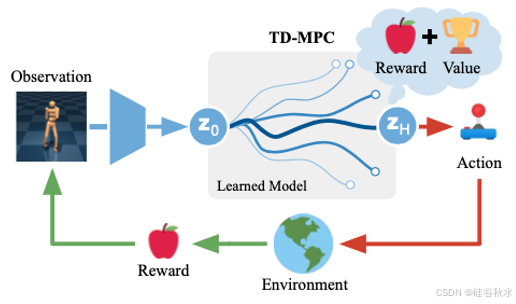
a) RL:Dreamer 1/2/3 [37, 47, 116], DayDreamer [94], TD-MPC 1/2 [81, 201], FOWM [200], PWM [308];
b) 基于Transformer:TWM [130], STORM [196], WHALE [358];
c) 基于RL + Transformer:MWM [95];
d) 基于Diffusion 模型:UniPi [120],;
e) 基于LLM:DEKARD [118], Surfer [157],Google Gemini [223], 3D-VLA [261];
f) Transformer + Diffusion模型:Sora [252];
g) LLM + RL: DynaLang [175],GenRL [303],
h) LLM + Diffusion模型: RoboDreamer [270]。
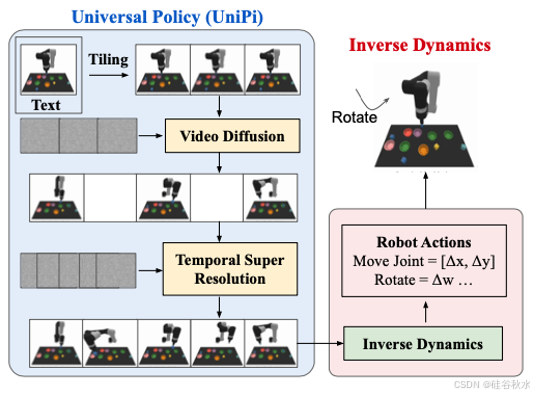
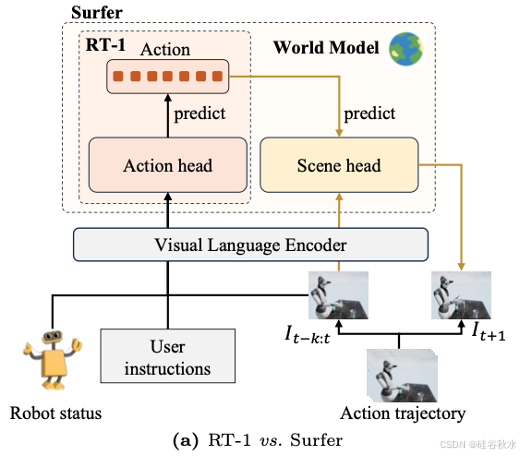
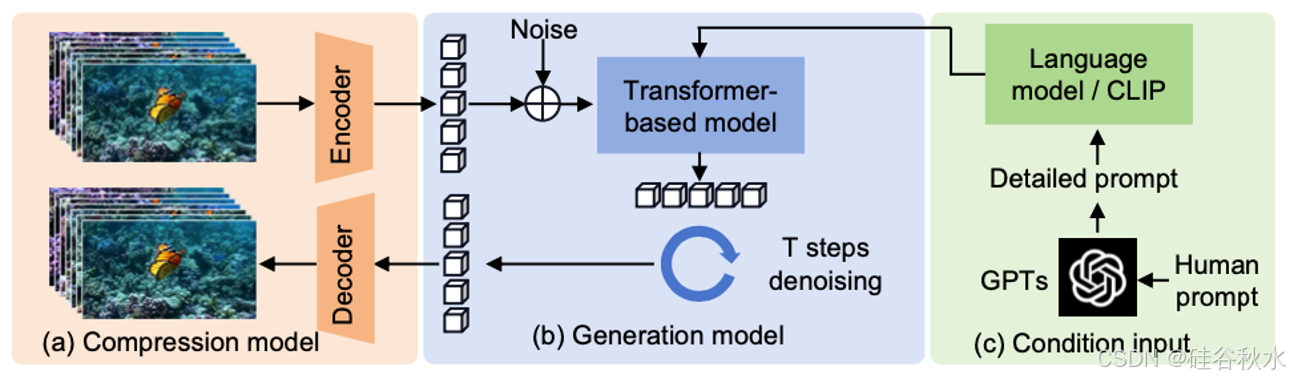

3.2 VLA 模型
视觉-语言-动作 (VLA) 模型 [288] 代表一类旨在处理多模态输入的模型,结合了视觉、语言和动作模态的信息。它们是处理视觉和语言多模态输入并输出机器人动作以完成具体任务的模型。它们是机器人策略指令遵循领域 EI 的基石。
VLA 模型是为了解决 EI 中的指令遵循任务而开发的。这些模型依赖于强大的视觉编码器、语言编码器和动作解码器。
EI 需要控制物理实体并与环境交互。机器人技术是 EI 最突出的领域。在语言调节的机器人任务中,策略必须具备理解语言指令、视觉感知环境并生成适当动作的能力,这需要 VLA 的多模态能力。
预训练的视觉表征强调了视觉编码器的重要性,因为视觉观察在感知环境当前状态方面起着至关重要的作用。因此,它为整个模型的性能设置了上限。在 VLA 中,通用视觉模型使用机器人或人类数据进行预训练,以增强其在物体检测、可供性图提取甚至视觉语言对齐等任务中的能力,这些任务对于机器人任务至关重要。
与早期的深度 RL 方法相比,基于 VLA 的策略在复杂环境中表现出卓越的多样性、灵活性和泛化能力。这使得 VLA 不仅适用于工厂等受控环境,也适用于日常生活任务(家庭)。
为了提高各种机器人任务的性能,一些 VLA 优先获得高质量的预训练视觉表征;另一些 VLA 则专注于改进低级控制策略,这些策略擅长接收短期任务指令并生成可通过机器人运动规划执行的动作;此外,一些 VLA 专注于将长期任务分解为可由低级控制策略执行的子任务。
低级控制策略和高级任务规划器的组合可以看作是一种分层策略。高级任务规划器根据用户指令生成规划,然后由低级控制策略逐步执行。
大多数低级控制策略会预测末端执行器姿势的运动,同时抽象出使用逆运动学(IK)控制各个关节运动的运动规划模块。虽然这种抽象有助于更好地推广到不同的具体机器人,但它也限制了灵活性。
虽然基于 LLM 的控制策略可以大大增强命令遵循能力,因为 LLM 可以更好地解释用户意图,但人们担心它们的训练成本和部署速度。推理速度慢会严重影响动态环境中的性能,因为 LLM 推理期间可能会发生环境变化。
PaLM-E [124] 是一种视觉语言通才模型,它将图像和文本视为由潜向量表示的多模态输入。PaLM-E 的输出分为两部分:在处理文本生成任务时,模型直接生成最终输出。相反,当用于特定的规划和控制任务时,PaLM-E 会生成低级指令文本(例如用于机器人控制的指令)。
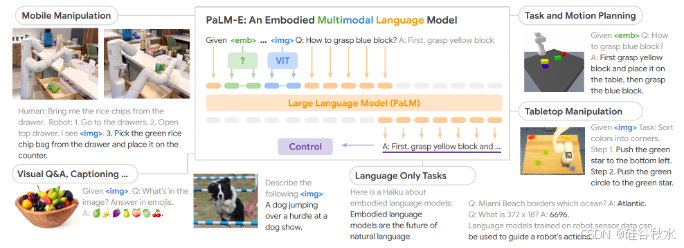
Robot Transformer 1 (RT-1) [113] 能够将高维输入和输出数据(包括图像和指令)编码为紧凑的 token,以便 Transformer 高效处理。它不是一个端到端模型。类似的工作有 RT-trajectory [206]、LEO [211]、SARA-RT [219]、GR-1[224]、ATM [227]、RT-H [254]、SRT [272] 和 RVT 1/2 [160, 297] 等。
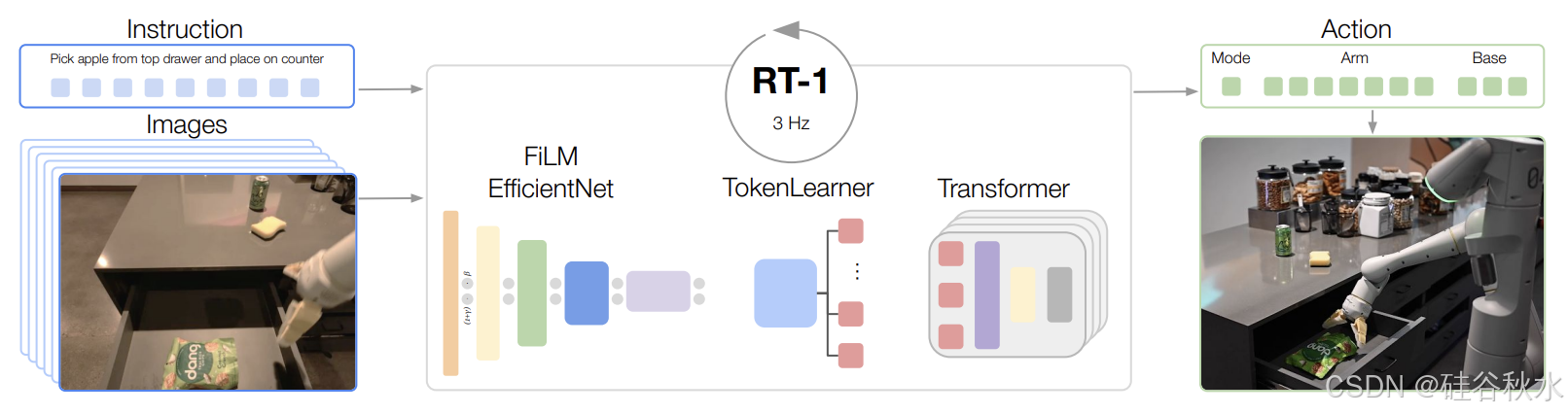
之后提出的 Robotics Transformer 2 (RT-2) [172] 在网络规模数据集上进行训练,以实现对新任务的泛化能力和直接拥有语义感知。通过微调 VLM,它可以基于文本编码生成动作,即 VLA 模型。

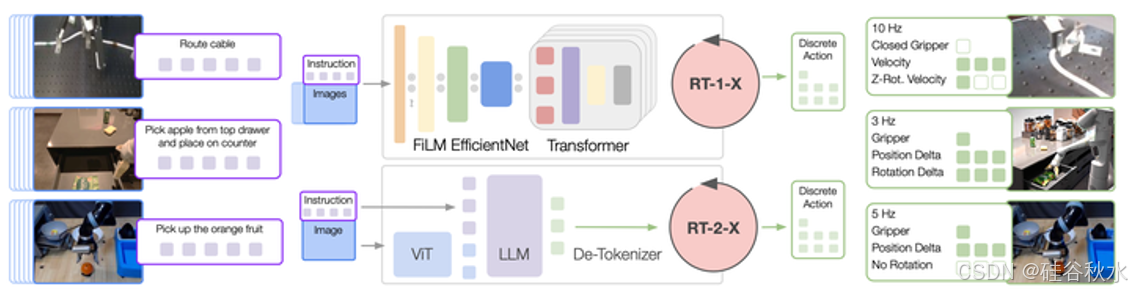
在合作中,Open X-Embodiment 推广了“通用”机器人策略的理念,并主张可训练模型可以适应不同的机器人、任务和环境 [195]。Robot Transformer X (RT-X) 分为两个分支:RT-1-X 和 RT-2-X。RT-1-X 采用 RT-1 架构,使用 Open-X-embodiment 数据集进行训练,而 RT-2-X 采用 RT-2 的策略架构,并在同一数据集上进行训练。
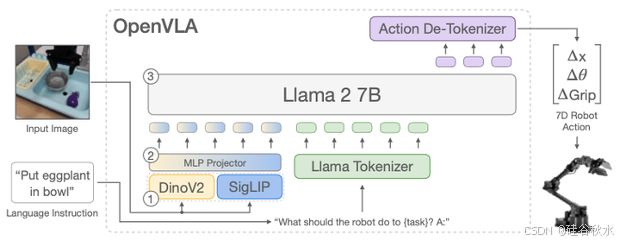
目前已经提出了许多 VLA 模型,例如 QUAR-VLA [225]、3D VLA [261]、Bi-VLA [284]、OpenVLA [299]、LLARVA [302]、CoVLA [324]、TinyVLA [335]、GR-2 [341]、DP-VLA [352] 和 DeeR-VLA [354] 等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









