










24年6月来自TX Austin和Nvidia的论文“RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots”。
人工智能 (AI) 的最新进展在很大程度上受到规模化的推动。在机器人技术中,规模化受到无法访问大量机器人数据集的阻碍。用真实的物理模拟作为规模化机器人学习方法的环境、任务和数据集的手段。RoboCasa,是一个用于在日常环境中训练通用机器人的大型模拟框架。RoboCasa 以厨房环境为重点,具有逼真而多样的场景。其提供数千个 3D 资产,涵盖 150 多个目标类别和数十种可交互的家具和电器。用生成式 AI 工具丰富模拟的真实性和多样性,例如来自文本-到- 3D 模型的目标资产和来自文本-到-图像模型的环境纹理。本文设计一组 100 个任务进行系统评估,包括由大语言模型指导生成的复合任务。为了促进学习,提供高质量的人类演示并集成自动轨迹生成方法,以最小的人力负担大幅扩大数据集。实验表明,使用合成机器人数据进行大规模模仿学习具有明显的规模化趋势,并且在利用模拟数据完成现实世界任务方面具有巨大潜力。
如图所示RoboCasa:

人工智能领域最近的突破是由在互联网规模的数据集上训练巨型神经网络模型推动的。与计算机视觉和自然语言处理领域不同,这些领域有大量来自在线来源的视觉和文本数据,而机器人数据相对稀缺。机器人技术的一个关键问题是如何获取能够捕捉现实世界巨大多样性和复杂性的机器人训练数据。最近,人们进行了几次著名的尝试,以创建用于训练通用机器人模型的大型、多样化的数据集 [2、9、5、20]。虽然这些数据集提高了机器人在狭窄领域的泛化能力,但迄今为止所实现的能力,与可以在野外可靠部署的通用机器人之间仍然存在相当大的差距。这提出了一个问题——机器人学习规模化的可行途径是什么?
由于在现实世界中收集越来越大的数据集需要不切实际的资本和劳动力,许多人转向模拟,将其作为生成大量合成数据进行模型训练有希望的替代方案。预计模拟将在规模化机器人学习方面发挥不可或缺的作用,原因如下。首先,一旦创建了功能丰富的高保真模拟器,就可以以低成本生成大量机器人数据。最近的自动数据生成方法就是一个例子,例如 MimicGen [34] 和 Optimus [6],它们利用模拟的特别信息以最少的人力生成数据。其次,生成式人工智能的快速发展促进了逼真模拟的创建。当今的生成式人工智能工具能够生成图像、合成 3D 资产和编写源代码 [38、35、42]。这些工具可用于程序化创建数百万个场景、导入新类别的目标以及编程自然的任务和奖励函数。最后,模拟使机器人学习研究民主化并加速其发展,从而能够快速对新想法进行原型设计并进行可重复的研究。
要释放模拟的潜力,它必须满足三个核心标准。首先,模拟器必须保证物理、渲染和底层模型的真实性,以便能够迁移到现实世界。其次,模拟器必须满足其提供的场景、资产和任务的多样性。生成式人工智能对于大规模实现这种多样性至关重要。最后,仅靠模拟器不足以训练出一个能力很强的通才机器人智体。模拟必须伴随着大型机器人数据集,以捕捉它所提供的场景和行为的多样性。之前创建模拟的无数尝试部分满足了这些标准中的一些,但没有一个满足了所有标准。
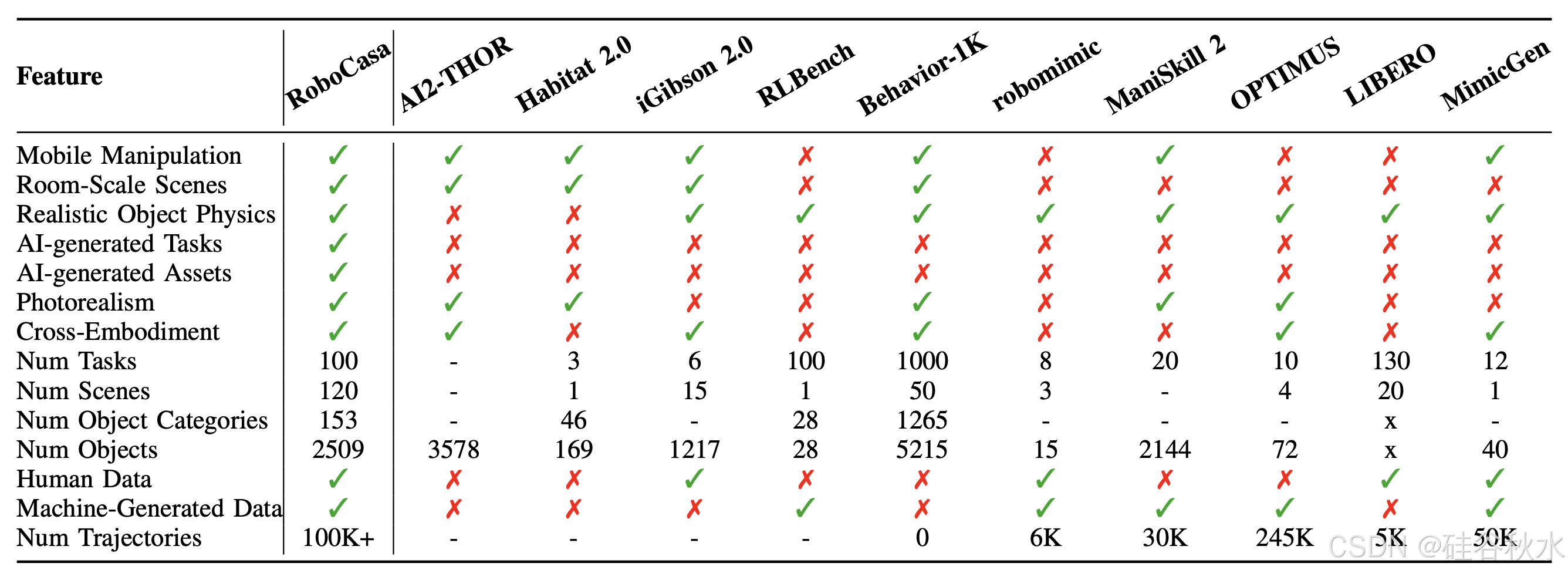
如表是和以往仿真器的比较:
采用 RoboSuite [51] 作为开发 RoboCasa 的核心模拟平台。之所以选择 RoboSuite,是因为它注重物理真实感、高速和模块化设计,这能够扩展到大规模场景。直接继承 RoboSuite 的几个核心组件,包括环境模型格式和机器人控制器。至关重要的是,为了支持房间规模的环境,扩展 RoboSuite 以适应移动机械手,包括安装在轮式底座上的机器人、人形机器人和带手臂的四足动物。从各种机器人存储库 [51, 47, 13] 获得并调整这些模型。还支持使用 NVIDIA Omniverse 进行高质量渲染,能够捕捉逼真的图像。
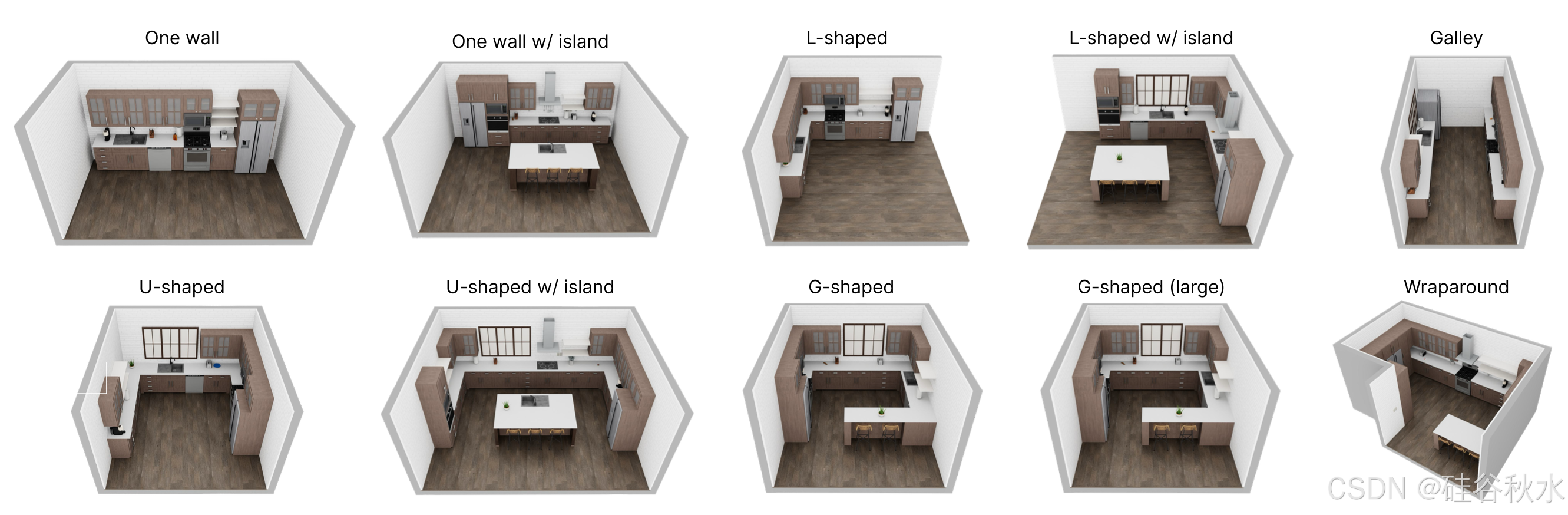
初版重点介绍以厨房活动为中心的家务。创建大量带有完全交互式橱柜、抽屉和电器的厨房场景。查阅在线家居设计和建筑杂志,编制一份多样化的厨房平面图清单。模拟 10 个平面图(如图所示),从公寓中的基本设计到高端住宅中更精致的设计。每个厨房都可以配置为采用自定义建筑风格。在查阅建筑杂志后,汇编流行的厨房风格,包括工业、斯堪的纳维亚、沿海、现代、传统、地中海、乡村等。每种风格都具有独特的设计元素组合,包括纹理、电器选择以及橱柜面板和把手。例如,斯堪的纳维亚厨房采用浅色、低对比度的纹理和简单、光滑的橱柜面板和电器。相比之下,地中海厨房使用华丽的电器、玻璃面板橱柜和彩色纹理。总共,建模 12 种厨房风格。每个平面图都可以配置为任何风格,从而产生 120 个厨房场景。每个场景都可以通过替换大量高质量 AI 生成的纹理来进一步定制。有 100 种墙壁纹理、100 种地板纹理、100 种柜台纹理和 100 种橱柜面板纹理。用流行的文本-转-图像工具 MidJourney 来生成这些图像。将这些纹理用作域随机化的一种形式,以显著增加训练数据集的视觉多样性。
创建了一个大型的复杂 3D 资产库,以适应各种厨房活动。该库包括橱柜、抽屉和各种厨房用具。从在线 3D 模型库中获取这些资产,并将其转换为 MuJoCo MJCF 模型格式。后处理操作涉及将电器分割成铰接实体,例如,分割微波炉的门和炉灶上的旋钮。它能够表示丰富的交互,例如关闭微波炉门或打开炉灶。此外,这些电器会发生状态变化,例如,当打开炉灶旋钮时,相应的燃烧器会打开以模拟加热。如图所示。

除了电器之外,还创建一个丰富的厨房常见物品库,涵盖水果和蔬菜、乳制品、家禽、饮料、容器、工具等。从两个来源收集目标资产,即 Objaverse [8] 数据集和在线文本-到- 3D 服务 Luma.ai。挖掘大量候选目标,并过滤掉有缺陷或质量低下的目标。在此过程结束时,收集 2,509 个高质量资产,涵盖 153 个独特目标类别。这些资产中的大多数(1,592 个)来自 Luma.ai。有关目标的说明,参见下图。

模拟器支持各种可能的厨房活动,用 100 项任务的综合套件来表示这些活动。
原子任务:行为的构建块
对于执行复杂任务的机器人,它必须掌握解决这些任务所需的基本技能。专注于构成大多数家庭活动基础的一组八种传感运动技能:1) 拾取和放置,2) 打开和关闭门,3) 打开和关闭抽屉,4) 扭转旋钮,5) 转动杠杆,6) 按下按钮,7) 插入,8) 导航。这些技能并不构成详尽的清单,包括以可变形操作等行为为中心的其他技能留待将来研究。为了有效地学习这些技能,提出一组 25 项任务,每项任务都涉及这八项技能中的一项。将它们称为原子任务。
使用大语言模型创建复合任务
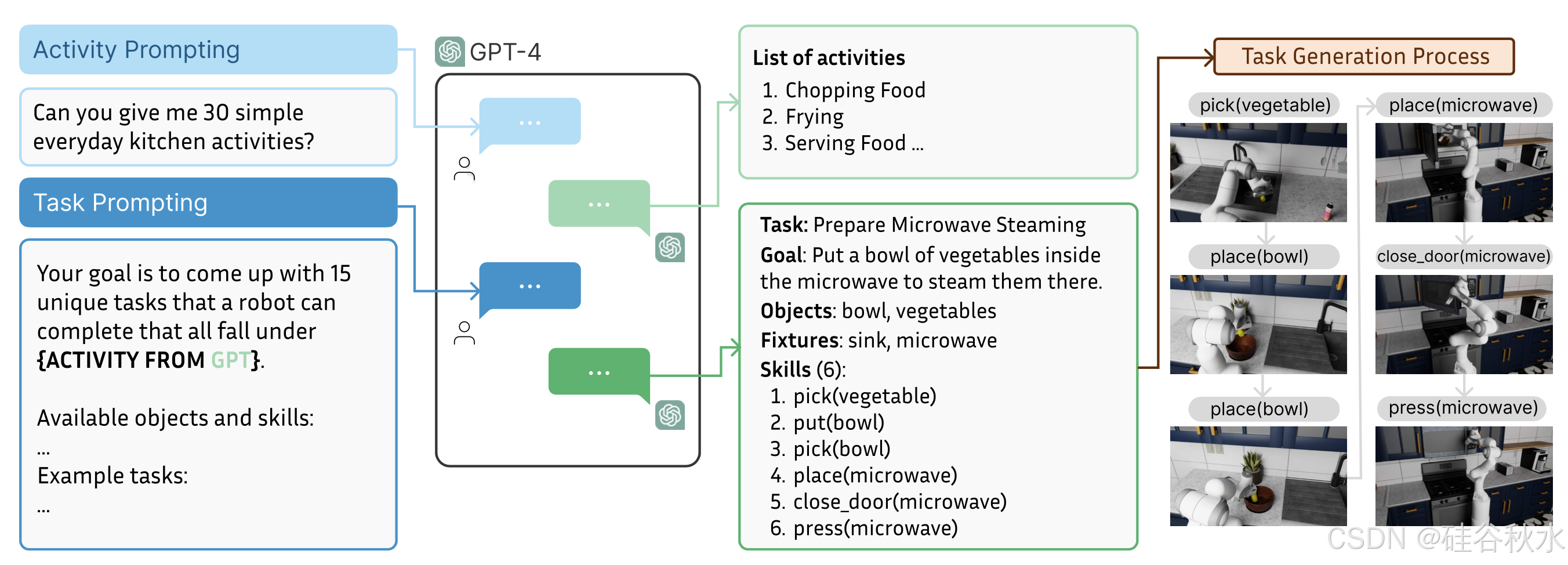
复合任务涉及排序技能,以解决语义上有意义的活动,例如烹饪和清洁。创建这些任务的目标是捕捉反映现实世界家庭活动生态统计数据的各种任务。用大语言模型 (LLM) 的指导来定义任务。这种方法有几个关键好处。首先,LLM 封装人类知识的不同来源,因此可以有效地传达基于现实世界的不同想法。此外,这些 LLM 可以大规模用于定义数千个独特的任务,从而大大减少任务定义所涉及的人力劳动。通过两个步骤生成任务(如图所示)。首先,提示 ChatGPT (GPT-4 [35]) 列出常见的高级厨房活动。列出 20 项活动:泡咖啡或茶、洗碗、补充厨房用品、切菜、烤面包、解冻食物、烧水、准备肉类、摆桌子、清理桌子、消毒、准备零食、整理橱柜和抽屉、洗水果和蔬菜、煎炸、重新加热食物、搅拌和混合、烘烤、上菜和蒸蔬菜。然后,提示 GPT-4 和 Gemini 1.5 [42] 为每个活动标签提出代表性任务。LLM 偶尔会出现逻辑缺陷,因此会过滤或修改它们的一些输出。从 LLM 中总共汇编 75 个任务蓝图,并继续为它们编写代码实现。除了设计用于特定环境的少数复合任务外,所有任务都可以在任何厨房场景中模拟。
RoboCasa 数据集
概述一套全面的 100 项任务,其中包括 25 项原子任务和 75 项使用 LLM 创建的复合任务。首先使用人工遥控操作收集一组基本演示,然后使用自动轨迹生成方法将其扩展为更大的演示集。
通过人工遥控操作收集一组基本演示。一个由四名人工操作员组成的团队使用 3D SpaceMouse 为每个原子任务收集 50 个高质量演示 [50, 51]。每个任务演示都是在随机厨房场景中收集的(随机厨房平面图、随机厨房风格和随机 AI 生成的纹理)。这通过人工遥控产生了大量多样化的模拟数据集(1,250 次演示)。然而,实验表明,即使是这种规模的人工数据也不足以解决大多数任务。这可能是由于任务和场景的范围和多样性。因此,选择使用数据生成工具来扩展数据量。
利用自动轨迹生成方法来合成演示。为了以最少的人力进一步扩大数据集的大小,采用 MimicGen [34],这是一种最近开发的轨迹生成方法。MimicGen 可以通过将人类演示的种子集调整到新设置来自动合成丰富的数据集。核心生成机制,首先将每个人类演示分解为一系列以目标为中心的操作片段。然后,对于一个新场景,它根据相关目标的当前姿势转换每个以目标为中心的片段,将片段拼接在一起,并让机器人遵循新的轨迹来收集新的任务演示。
MimicGen 需要对模拟做出一些基本假设。在 RoboCasa 中如下轻松满足这些假设:MimicGen 假设任务由已知的以目标为中心子任务序列组成——必须为每个新任务指定此序列。幸运的是,原子任务由八项核心技能组成。与技能相对应的所有任务,都具有相同或相似的以目标为中心的子任务序列,主要区别在于参考目标的身份。例如,对于拾取和放置任务,第一阶段是具有一个参考目标的拾取子任务,第二阶段是具有第二个参考目标的放置子任务。因此,指定子任务序列所需的人力最少。此外,提供给 MimicGen 的每个人工演示还必须用与每个以目标为中心的子任务相对应的片段进行注释。这可以通过检测每个子任务结束的自动指标来完成——这些功能只需要为八个核心技能中的每一个实现一次,并且可以在整个演示集中重复使用。
MimicGen 数据生成尝试并不总是成功的。在实践中,它采用拒绝采样方案仅保留导致任务成功的生成尝试。利用 RoboCasa 模拟,在多个模拟过程中并行化 MimicGen 数据生成,以加快数据生成过程。
BC-Transformer 策略将过去 10 次观察的历史记录以及文本的语言目标作为输入,并输出机器人要执行的接下来十个动作。智体在执行第一个动作后重规划。修改策略以支持语言调节,方法是使用 CLIP 句子编码器对语言目标进行编码。对于输入中的每个观察,该策略都会对本体感受信息(末端执行器姿势和移动基座姿势)和来自三个摄像头的图像进行编码:手眼摄像头、左工作区摄像头和右工作区摄像头。它使用专用的 ResNet-18 编码器堆栈对这些图像中的每一个进行编码,并使用 FiLM 层融合视觉表示。编码后的观察结果被传递给具有 ∼ 20M 个可训练参数的 6 层 Transformer。以 1e − 4 的学习率对模型进行 500k 梯度步的训练,并带有一个学习率预热。
还尝试扩散策略 [4]。在 RoboMimic 中实现扩散策略,以便与现有的 BC-Transformer 方法进行公平比较。扩散策略使用与 BC-Transformer 相同的观察编码器(ResNet、FiLM 条件)。用官方实现中推荐的所有超参数:观察历史的 2 个时间步长、16 个步骤的预测范围和 8 个步骤的行动范围。用 DDIM [39],其中包含 100 个训练时间步长和 10 个推理时间步长,这是扩散策略[4]推荐的。扩散策略的表现远远低于 BC-Transformer 实现。在单阶段 PickPlaceCounterToSink 任务中,BC-Transformer 的成功率为 56%,而扩散策略的成功率仅为 12%。对此的一个可能解释是,BC-Transformer 实现使用了更长的 10 个观测历史长度,而扩散策略使用了 2 个观测历史长度(这是默认选择)。纳入更长的观测历史可能对任务至关重要。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









