










24年12月来自中山大学深圳分校和美团的论文“DriveMM: All-in-One Large Multimodal Model for Autonomous Driving”。
大型多模态模型 (LMM) 通过结合大语言模型,在自动驾驶 (AD) 中展现出了卓越的理解和解释能力。尽管取得了进步,但当前数据驱动的 AD 方法往往集中在单个数据集和特定任务上,而忽视了它们的整体能力和泛化能力。为了弥补这些差距,DriveMM,一个通用的大型多模态模型,处理多样化的数据输入,例如图像和多视角视频,同时执行广泛的 AD 任务,包括感知、预测和规划。
最初,该模型经过课程预训练,以处理各种视觉信号并执行基本的视觉理解和感知任务。随后,扩充和标准化各种与 AD 相关的数据集来微调模型,最终形成一个用于自动驾驶的一体化 LMM。为了评估通用能力和泛化能力,在六个公开基准上进行评估,并在一个未见过的数据集上进行零样本迁移,其中 DriveMM 在所有任务中都实现了最佳性能。
LMM 在不同任务中表现出色 [1、7、24、26、29]。最近,研究人员开始探索 LLM 在 AD 领域的潜力。在早期阶段,DiLu [51] 和 GPT-Driver [31] 尝试利用 GPT-3.5 和 GPT-4 作为驾驶规划器。随后,DriveGPT4 [53] 和 RDA-Driver [15] 引入了生成控制信号或轨迹的端到端 LMM。与通过语言处理驾驶操作的方法不同,LMDrive [42] 和 DriveMLM [50] 使用解码器从隐嵌入中预测控制信号。为了增强感知和推理能力,有几种方法旨在改进模型架构。 Reason2Drive [37] 提出了一种先验token化器来提取局部图像特征,而 BEV-InMLLM [13] 将鸟瞰图 (BEV) 表示注入 LMM。OmniDrive [49] 使用 Q-Former3D 将 2D 预训练知识与必要的 3D 空间理解相结合。ELM [59] 结合了时间-觉察token选择模块来准确查询时间线索。尽管这些方法已表现出令人满意的性能,但它们的适用性仅限于特定场景和任务,例如特定数据类型或特定于数据集的任务。鉴于此,本文提出一种一体化 LMM,旨在有效处理 AD 中的各种驾驶场景和任务。
通过整合各种数据和任务,DriveMM 可以在各种 AD 视觉语言数据上进行训练,从而实现不同数据集和任务之间的相互改进。此外,经过训练后,DriveMM 可以有效地部署在各种现实世界的 AD 场景中,例如不同的摄像头和雷达系统配置,以及各种 AD 任务。
如图所示:采用 LLaVA [26] 的架构形式,并采用不同的模型实例,处理各种视觉输入信号。设计一个透视-觉察提示,以接受 AD 场景中的多视角输入。DriveMM 配备多种 AD 多模态数据,具有在自动驾驶中完成多项任务的一体化能力。
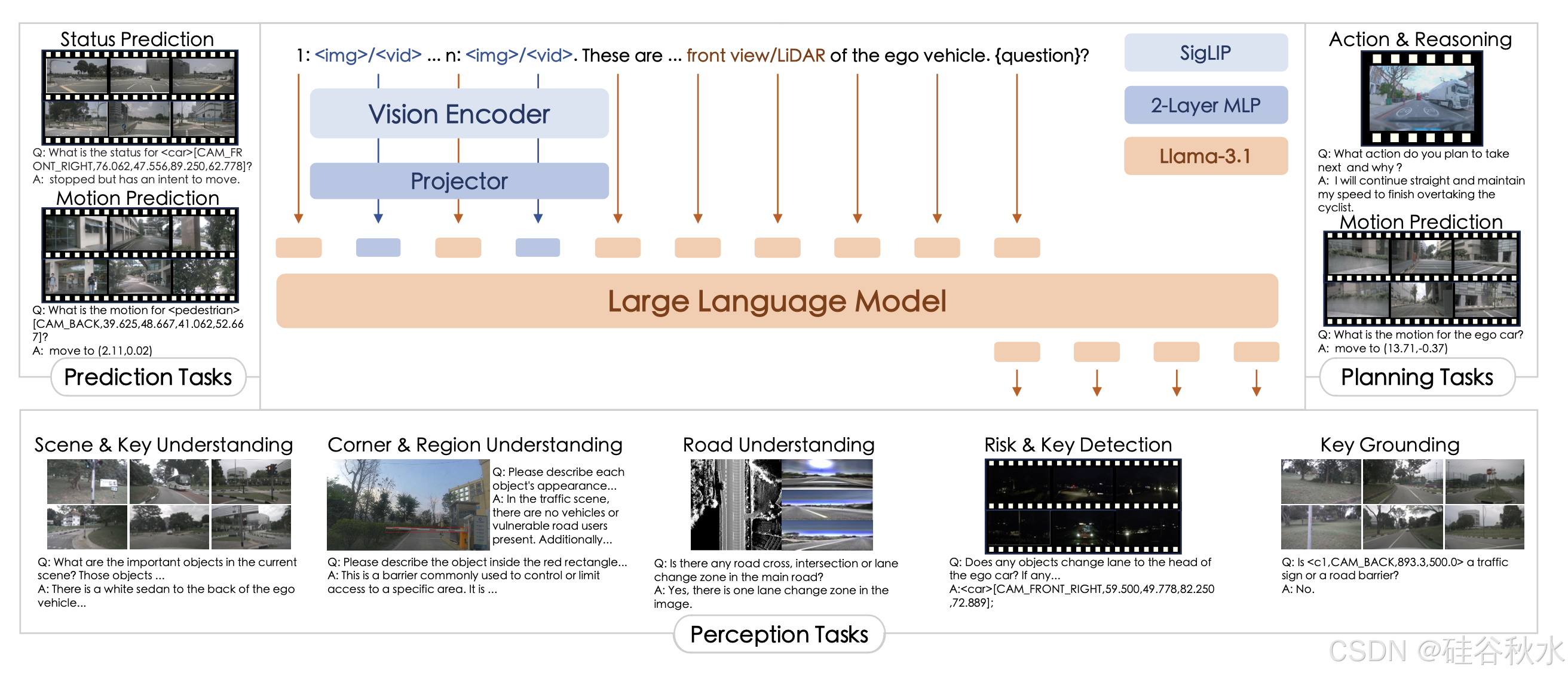
如表所示,对图像和视频输入使用不同的占位符(即 和 ),其中占位符将在输入到 LLM 之前被相应的tokens替换。还为具有不同视角的图像/视频分配数字标签,并在文本中解释每个图像/视频的特定摄像头或激光雷达。为了提高计算效率,对视频特征 Hv 应用 2×2 空间池化,然后将其展平为视觉tokens。结合视角和数据格式的信息,DriveMM 可以更好地解释复杂的交通状况,识别多个目标及其空间关系,并做出更明智的决策。

在 LMM 的训练中,数据在启用和激活 LLM 理解多模态信息的能力方面起着至关重要的作用。为了增强 DriveMM 在多模态 AD 场景中的理解和推理能力,构建了三个不同的数据集:常规多模态数据、感知数据和自动驾驶数据。
常规多模态数据
最近的研究 [2, 9] 表明,随着数据量的增加,LMM 可以实现增强的性能。然而,与网上丰富的图文数据 [41, 44] 相比,AD 图文数据明显有限。为了提高 DriveMM 的性能,用大量多模态数据预训练一个基础模型,从而能够使用单幅图像、多幅图像和视频进行推理。
具体来说,从 [18] 中构建一个多模态数据集,其中包含图-文对和多样化的视觉指令调整数据。图像-文本对的目的是使视觉编码器和 LLM 对齐,使模型能够对图像形成基础理解。用了多个数据集,包括 LCS-558K [26]、COCO118K [18]、CC3M [44]。为了增强模型处理各种传感器配置(例如单视角和多视角相机)中视觉数据的能力,用 OneVision 数据 [19] 中的视觉指令调整数据,包括图像、多图像和视频。
感知数据
为了使 DriveMM 具备 AD 感知能力,创建一个包含各种数据格式的综合基础数据集。对于单图像数据,用 COCO [23] 和 Object365 [43] 数据集。从图像中随机选择一个类别,并使用基础提示(例如,“检测图像中的所有 <类别>。”)提示模型检测该类别中的所有目标。用边框 [x/min , y/min , x/max , y/max ] 或区域中心 [x/center, y/center ] 表示目标的位置。x 和 y 值根据图像大小在 0 到 100 的范围内标准化。对于多视角图像和多视角视频,采用 nuScenes [3] 数据集。为了使模型具有空间感知能力,希望它不仅能预测目标边框,还能估计相机视角。因此,用 [cam, x/min, y/min, x/max, y/max ] 或 [cam, x/center, y/center ] 表示目标的位置,其中 cam 表示相机视角,例如“CAM BACK”。如图左下方展示了感知数据的一个示例。

自动驾驶数据
收集了不同的数据集来训练一个一体化的 LMM,它可以同步处理不同场景中的各种 AD 任务。具体来说,使用六个自动驾驶数据集:CODA-LM [22]、MAPLM [4]、DriveLM [45]、LingoQA [34]、OmniDrive [49] 和 NuInstruct [13]。这些数据集包含各种传感器配置,例如摄像头和激光雷达,以及不同的 AD 任务,包括感知、预测和规划。值得注意的是,不同的数据集可能表现出不同的问题模式。为了促进协作增强,按如下方式扩充和标准化问答对。
问答扩充。一些数据集仅限于一组固定的模板。例如,CODA-LM 仅包含三个问题模板,而 MAPLM 使用了五个。这阻碍了模型的泛化潜力。为了克服这一限制,用 GPT-4o-mini 来扩充问答对并增加其多样性。此外,很大一部分问题是开放式的。为了进一步增强多样性,随机将一些开放式问题转换为多项选择题格式。上图右下角展示了扩充的示例。
问答标准化。不同的数据集可能表现出问答风格的不一致。例如,DriveLM 使用“<c6, CAM BACK, 1088.3, 497.5>”来表示目标,其中“c6”表示类 ID。相反,NuInstruct 采用“[c6, 139, 343, 1511, 900]”的格式,其中“c6”表示摄像头 ID。为了确保跨数据集的兼容性,标准化目标的表示并明确指定表示格式。此外,为了适应不同大小图像中的边框,根据图像的大小将边框的坐标标准化为 0 到 100 的范围。例如,对于 NuInstruct 数据集,将目标重新表示为“[CAM BACK RIGHT, 8.688, 38.111, 94.438, 100.000]”,并在问题末尾添加格式化说明,如上图右下角所示。
训练
采用一种课程学习方法,逐步提高模型在各种 AD 数据和任务上的性能,从而形成一体化自动驾驶模型 DriveMM。具体来说,逐渐增加数据的复杂性,从单个图像发展到多个视频,并增加任务的复杂性,从图像字幕过渡到驾驶推理,以训练 DriveMM。如上图所示,训练过程分为四个步骤:
阶段 1:语言-图像对齐。此阶段的目标是为预训练的 LLM 配备多模态理解的基础能力。为了实现这一点,训练投影器,与 LLM 的字嵌入空间对齐。冻结视觉编码器和 LLM,并且仅在 LCS-558K [26] 上优化投影器。
阶段 2:单图像预训练。在此阶段,通过集体优化整个模型来进一步增强模型理解单幅图像的能力。用图像-文本对,并优化模型的所有参数以增强 LLM 对多模态任务的适用性。
阶段 3:多-功能预训练。为了获得用于训练 AD 系统的强大基础模型,增强模型在不同场景中的推理和感知能力。为此,利用视觉指令调整数据来增强模型对基本视觉元素的推理能力。此外,用感知数据来促进模型的感知能力。值得注意的是,训练数据包含多种数据格式,包括单幅图像、单视频、多视图图像和多视图视频。通过为模型配备处理各种数据和任务的能力,为训练一体化 AD 模型奠定基础。
阶段 4:驾驶微调。为了使 DriveMM 能够处理广泛的 AD 任务,进一步在不同的驾驶数据集上微调模型。具体来说,用六个增强和标准化自动驾驶数据集。在此阶段,优化模型的所有参数。经过训练后,提出的一体化 DriveMM 可以有效地部署在广泛的 AD 场景中,例如不同的摄像头和雷达系统配置,以及各种 AD 任务。
模型架构。采用 SigLIP [55] 作为视觉编码器,该编码器在 WebLI [8] 上进行了预训练,分辨率为 384×384。使用 2 层 MLP [25] 作为投影器,将图像特征投影到词嵌入空间中。对于语言模型,选择 Llama-3.1 [35] 8B,它使用带有 128K 个tokens的词汇表的token化器。模型在 8,192 个tokens序列上进行训练。
实验设置。给出 DriveMM 的训练细节。采用课程学习方法逐步训练 DriveMM。
• 第 1 阶段。用 LCS-558K [26] 将视觉块特征对齐到词嵌入空间。在此阶段,仅训练投影器,同时保持其他组件冻结。学习率设置为 1×10−3,训练进行 1 个 epoch,批处理大小为 512。
• 第 2 阶段。利用重标注的 BLIP558K [26]、COCO118K [18] 和 CC3M [44] 数据集来改进模型。同时,用语言数据 Evo-Instruct [5] 来平衡模型的语言理解能力。在此阶段,数据集包含 3M 单幅图像数据和 143K 语言数据。用批处理大小为 256 的批处理对整个模型进行 1 个 epoch 的微调。视觉编码器的学习率设置为 2×10−6,而投影器和 LLM 的学习率均为 1×10−5。
• 第 3 阶段。用各种多模态数据和感知数据,包括 1.5M 单幅图像、760K 多视角图像、501K 单视频和 145K 多视角视频。具体而言,单图像数据由来自 [18] 的多模态数据和来自 COCO [23] 和 Object365 [43] 的感知数据组成。多视角图像数据包括多模态数据 LLaVA-NeXT-Interleave [20] 和感知数据 nuScenes [3]。单视角视频数据来自方法 [20, 57]。鉴于可用数据中多视角视频的稀缺性,用 nuScenes [3] 生成多视角感知数据,每个视角由 5 帧组成。对整个模型进行微调,批处理大小为 256,持续 1 个 epoch,保持与阶段 2 相同的学习率。
• 第 4 阶段。编制六个公共 AD 数据集,包括单图像 (CODA-LM)、多视图图像 (MAPLM、DriveLM)、单视频 (LingoQA) 和多视图视频 (OmniDrive、NuInstruct),总计 1.5M。具体来说,扩充 CODA-LM 数据集,将其从 36,896 个样本扩展到 184,480 个样本,将 MAPLM 数据集从 47,485 个样本扩展到 94,970 个样本。此外,还标准化 DriveLM 和 NuInstruct 数据集,以确保整个数据的一致性。在此阶段,用与阶段 2 相同的批处理大小和学习率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









