









24年6月来自南京大学和Nvidia的论文“Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?”。
端到端自动驾驶最近成为一种有前途的研究方向,旨在从全栈视角实现自动驾驶。沿着这条思路,许多最新研究都遵循 nuScenes 上的开环评估设置来研究规划行为。本文进行彻底的分析和揭开更多细节中的谜团,深入研究这个问题。nuScenes 数据集以相对简单的驾驶场景为特征,导致在结合自我状态(例如自车的速度)的端到端模型中感知信息的利用不足。这些模型往往主要依赖自车的状态来进行未来的路径规划。除了数据集的局限性之外,还注意到,当前的指标并不能全面评估规划质量,从而导致从现有基准得出的结论可能有偏差。为了解决这个问题,引入一个新指标来评估预测的轨迹是否符合道路。进一步提出一个简单的基线,它能够在不依赖感知注释的情况下获得具有竞争力的结果。
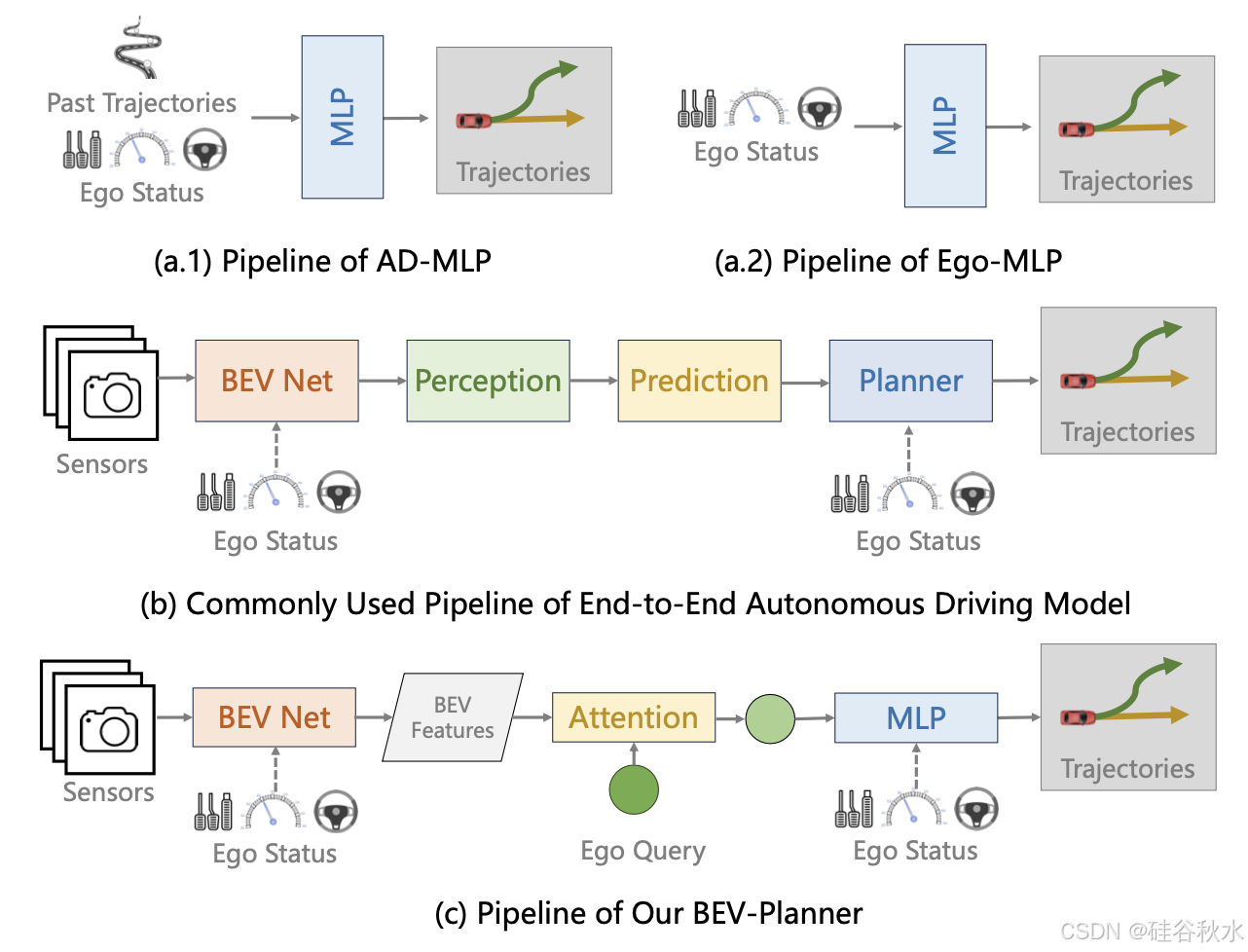
如图所示:(a)AD-MLP 使用自我状态和过去轨迹 GT 作为输入。复现版本(Ego-MLP)删除过去轨迹。(b)现有的端到端自动驾驶流水线由感知、预测和规划模块组成。自我状态可以集成到鸟瞰图 (BEV) 生成模块中或规划模块中。(c)设计一个简单的基线,BEV-Planner,用于与现有方法进行比较。简单的基线不利用感知或预测模块,而是直接根据 BEV 特征预测最终轨迹。
BEV 感知
近年来,基于 BEV 的自动驾驶感知方法取得长足进步。Lift-Splat-Shoot (LSS)[31] 首先提出使用潜在深度分布进行视图变换。BEVFormer [22] 将时间线索引入 BEV 感知,大大提高 3D 检测性能。一系列后续工作 [14、15、21、23、24、26-28、30、41、42] 通过获取更准确的深度信息或更好地利用时间信息获得更准确的 3D 感知结果。时间信息的结合通常需要跨不同时间步对齐特征 [14、18、22、39]。在对齐过程中,自我状态要么隐式编码在输入特征中 [39],要么显式用于转换 BEV 特征 [14]。方法 [4, 20, 25, 29, 38, 44] 探索基于 BEV 特征的地图感知。
端到端自动驾驶
现代自动驾驶系统通常分为三个主要任务:感知、预测和规划。端到端自动驾驶将学习从原始传感器数据引导到规划轨迹或驾驶命令,无需手动提取特征,从而实现高效数据利用和适应各种驾驶场景。有大量研究 [34, 37, 40] 专注于模拟器中的闭环端到端驾驶 [8, 19]。然而,模拟器环境和现实世界之间存在域差距,特别是在传感器数据和智体的运动状态方面。最近,开环端到端自动驾驶引起更多关注。涉及学习中间任务的端到端自动驾驶方法 [3、9、13、16、33、43] 声称其在提高最终规划性能方面的有效性。AD-MLP [45] 指出 nuScenes 中数据分布不平衡的问题,并尝试仅使用自我状态作为模型输入来实现艺术表现。然而,AD-MLP 受益于利用自车的历史轨迹作为输入。鉴于现有方法均未使用自车的历史轨迹信息,在开环自动驾驶中使用历史轨迹是一个有争议的主题,因为模型本身不会生成此历史轨迹,而是由实际的人类驾驶员生成。
有一个重要问题:自我状态是否是开环端到端自动驾驶所需的全部信息?
考虑到在当前基准中使用自我状态的利弊,答案是肯定的,也是否定的:
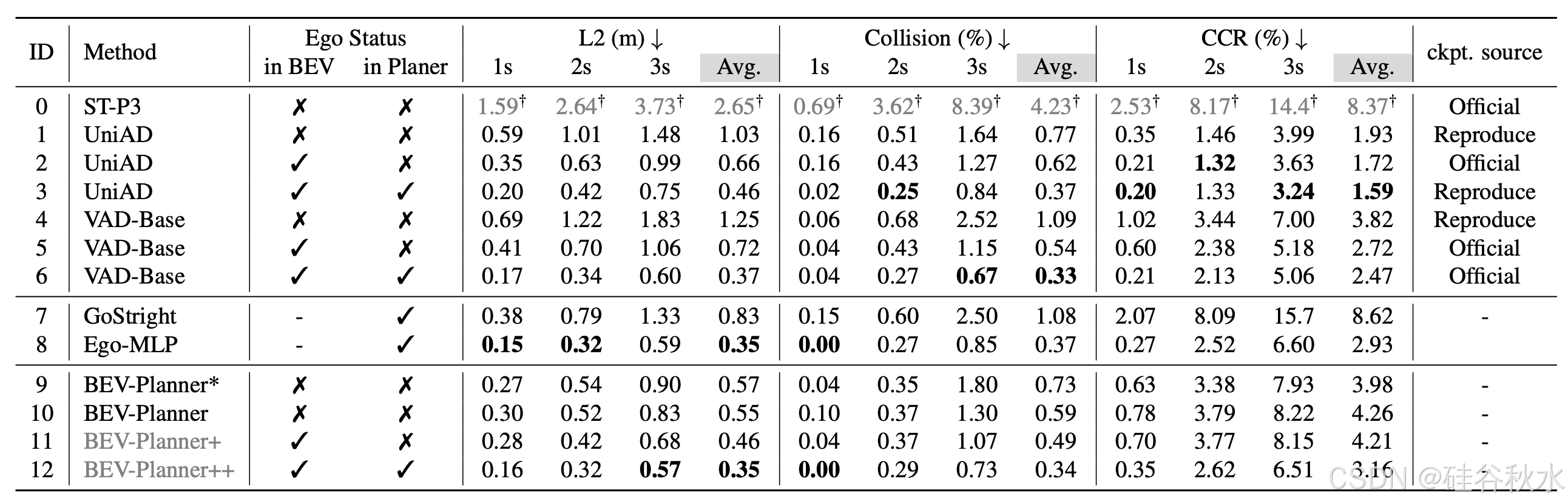
肯定。自我状态中的速度、加速度和偏航角等信息显然应该有利于规划任务。为了验证这一点,修复 AD-MLP 的一个未解决的问题,并删除历史轨迹真值 (GT) 的使用,以防止潜在的标签泄漏。复制的模型 Ego-MLP 完全依赖于自我状态,在现有的 L2 距离和碰撞率指标方面与最先进的方法相当。另一个观察结果是,只有现有方法 [13、16、43] 将自我状态信息纳入规划器模块,才能获得与 Ego-MLP 相当的结果。尽管这些方法采用额外的感知信息(跟踪、高清地图等),但与 Ego-MLP 相比,它们并没有表现出优越性。这些观察结果验证自我状态在端到端自动驾驶开环评估中的主导作用。
否定。同样明显的是,自动驾驶作为一种安全-紧要应用,不应仅依靠自我状态进行决策。那么,为什么会出现这种仅使用自我状态就能实现最佳规划结果的现象呢?为了解决这个问题,提出一套全面的分析,涵盖现有的开环端到端自动驾驶方法。确定现有研究中的主要缺点,包括与数据集、评估指标和特定模型实现相关的方面。
不平衡数据集。NuScenes 是开环评估任务的常用基准[11–13, 16, 17, 43]。然而,73.9% 的 nuScenes 数据涉及直线驾驶场景,如图中的轨迹分布所示。对于这些直线驾驶场景,大多数情况下保持当前速度、方向或转弯速率就足够了。因此,可以轻松利用自我状态信息作为捷径来完成规划任务,从而使 Ego-MLP 在 nuScenes 上表现出色。
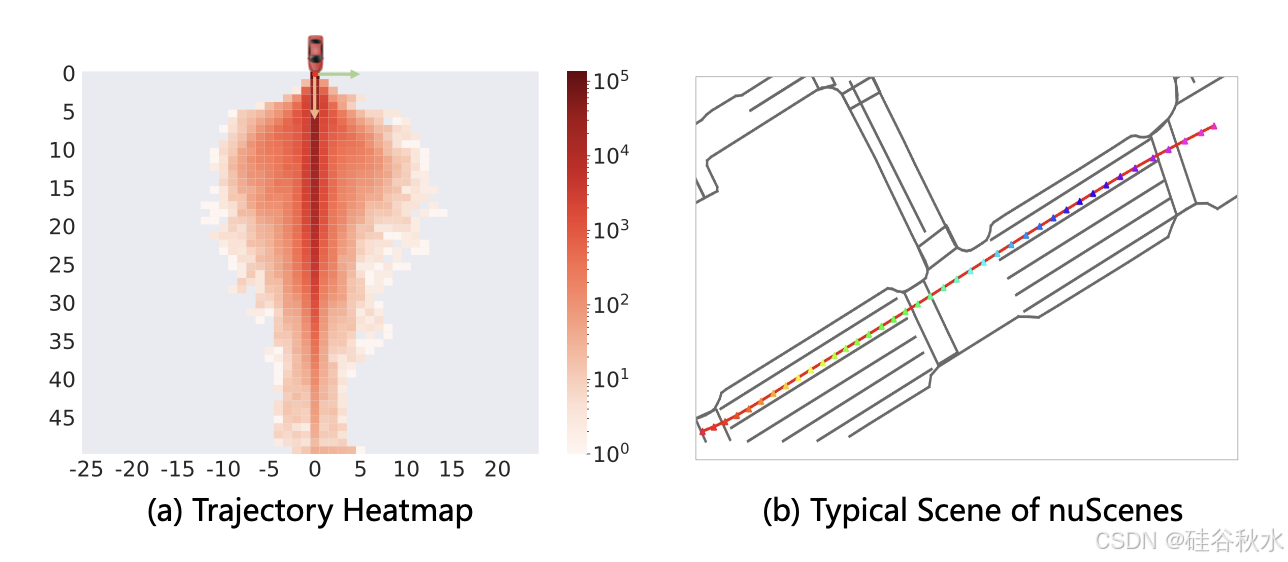
现有指标并不全面。其余 26.1% 的 nuScenes 数据涉及更具挑战性的驾驶场景,可能为规划行为提供更好的基准。然而,目前广泛使用的指标,例如预测和规划 GT 之间的 L2 距离以及自车与周围障碍物之间的碰撞率,无法准确衡量模型的规划行为质量。通过可视化由各种方法生成的大量预测轨迹,一些高风险轨迹(例如偏离道路)可能不会在现有指标中受到严重惩罚。针对这一问题,引入一个新指标来计算预测轨迹与道路边界的交互率。在关注与道路边界的交叉率的同时,基准将发生重大转变。就这个新指标而言,Ego-MLP 倾向于比 UniAD 更频繁地预测偏离道路的轨迹。
自我状态对驾驶逻辑的偏差。由于自我状态是导致过拟合的潜来源,出现一个有趣的现象。在某些情况下,从现有端到端自动驾驶框架中完全删除视觉输入并不会显著降低规划行为。这与基本的驾驶逻辑相矛盾,因为感知有望为规划提供有用的信息。例如,在 VAD [16] 中,当自我状态存在时,消除所有摄像头输入会导致感知模块完全失效,但规划效果会略有下降。但是,改变输入的自我速度可以显著影响最终的预测轨迹。
自我状态对当前开环端到端自动驾驶研究的潜在干扰提出另一个问题:是否可以通过从整个模型中去除自我状态来消除这种影响?然而,值得注意的是,即使排除自我状态的影响,基于 nuScenes 数据集开环自动驾驶研究的可靠性仍然存在疑问。
事实上,以前经常用作基线的方法 ST-P3 [12] 在训练和评估期间使用了部分错误的 GT 数据。因此,在将其他方法与 ST-P3 进行比较时,必须仔细评估得出结论的有效性。本文有必要重新设计一种基线方法来与现有方法进行比较。同时,为了更好地探索自我状态的影响,还需要一个相对清晰的基线方法。基于这些考虑,本文设计一个非常简单的基线,名为 BEV-Planner。对于流程,首先生成 BEV 特征并将其与历史 BEV 特征连接起来,主要遵循以前的方法 [12, 14, 21]。请注意,在连接来自不同时间步的 BEV 特征时,没有执行特征对齐。在获得 BEV 特征后,直接在 BEV 特征和自我查询(一种可学习的嵌入)之间执行交叉注意 [36]。根据 MLP 细化后的自我查询进行最终轨迹的预测。
为了与现有方法保持一致,还设计将自我状态纳入 BEV 或规划器模块的基线方法。将自我状态纳入 BEV 的策略与以前的方法 [13、16、22] 一致。将自我状态纳入规划器的策略,是直接将自我查询与包含自我状态的向量连接起来。
与现有方法相比,这种简单的方法不需要任何人工标记的数据,包括边框、跟踪 ID、高清地图等。对于这个提出的基线,只使用一个 L1 损失进行轨迹监督。提出的基线方法不适用于现实世界的部署,因为它在提供足够的约束和互操作性方面存在不足。
ST-P3 使用了部分错误的训练和评估数据。按照惯例,未来的 GT 规划轨迹是根据随后 3 秒内样本的自我位置生成的。然而,由于一个 nuScenes 剪辑通常是 20 秒的视频,这意味着视频尾部(17 秒到 20 秒内)的样本无法产生完整的未来轨迹,常规方法 [13, 16] 会使用掩码对这些特殊样本进行特殊处理,但 ST-P3 [12] 没有这样做。ST-P3 在生成这些尾部样本的 GT 时错误地使用了来自其他场景的样本,因此在训练和测试期间出现错误。
自我状态起着关键作用。与之前的 L2 距离和碰撞率指标相比,简单策略 (ID-7)(仅以当前速度继续直行)取得了令人惊讶的好结果。没有利用感知线索的 Ego-MLP 模型实际上与使用更复杂流水线的 UniAD 和 VAD 不相上下。从另一个角度来看,现有方法只有在将自车的状态纳入规划器时才能匹配 Ego-MLP 的性能。相比之下,仅依赖摄像头输入会导致结果明显不如 Ego-MLP 所实现的结果。考虑到这些观察结果,可以暂时推断出一个有趣的结论:利用感官信息和自我状态的组合似乎可以产生与单独使用自我状态相当的结果。因此,在集成自车状态和感知信息的模型中,一个相关的问题出现了:从摄像头输入获得的感知信息在最终规划模块中扮演什么具体角色?
自我状态与感知信息毫无疑问,感知信息是所有自动驾驶系统不可或缺的基础,自我状态还提供车辆速度和加速度等关键数据,以帮助系统的决策过程。在端到端自动驾驶系统中,将感知信息和自我状态结合起来进行最终规划确实应该是一个明智的策略。然而,如表所示(开环规划的性能),仅依靠自我状态就可以产生与以前的 L2 或整理率指标上同时利用自我状态和感知模块的方法相当甚至更好的规划结果。
为了确定感知信息和自我状态在最终规划过程中所扮演的角色,对图像和自我状态引入不同程度的扰动,如下表所示(基于 VAD 的模型鲁棒性)。
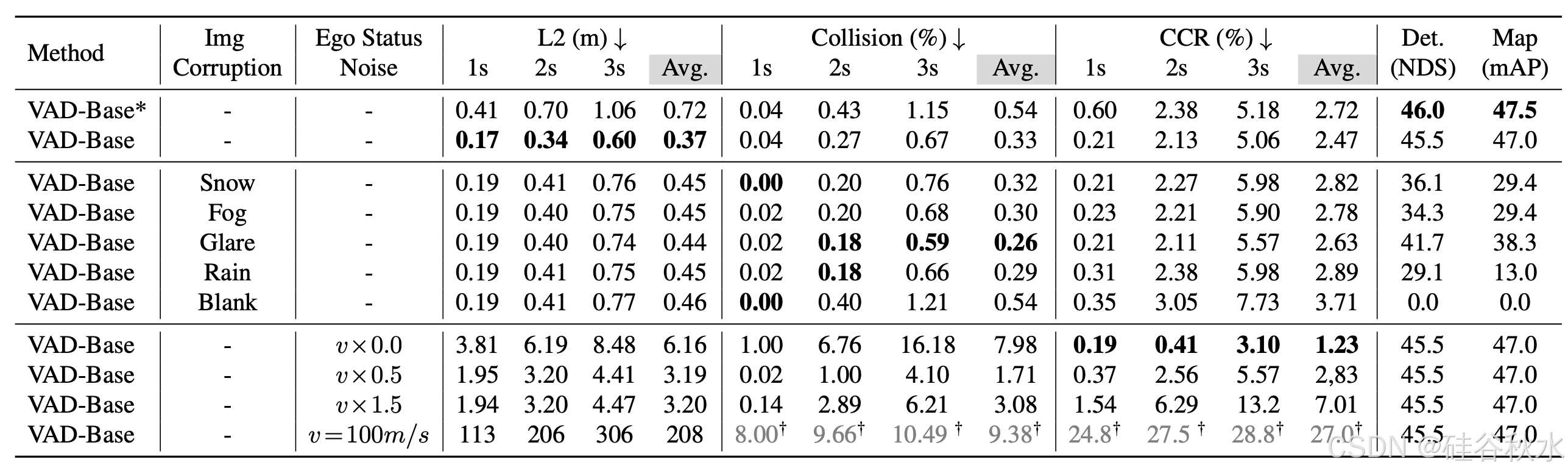
用官方的 VAD 模型(该模型在规划器模块中利用自我状态)作为基础模型。当在图像中添加干扰时,规划结果会略有下降,甚至可能会有所改善,而感知性能则显著下降。令人惊讶的是,即使使用空白图像作为输入,导致感知模块彻底崩溃,模型的规划能力仍然基本不受影响。相应的可视化结果如图所示(不同图像污染情况下的 VAD 模型预测轨迹)。与模型对图像输入变化的显著稳健性相比,它对自我状态表现出相当大的敏感性。
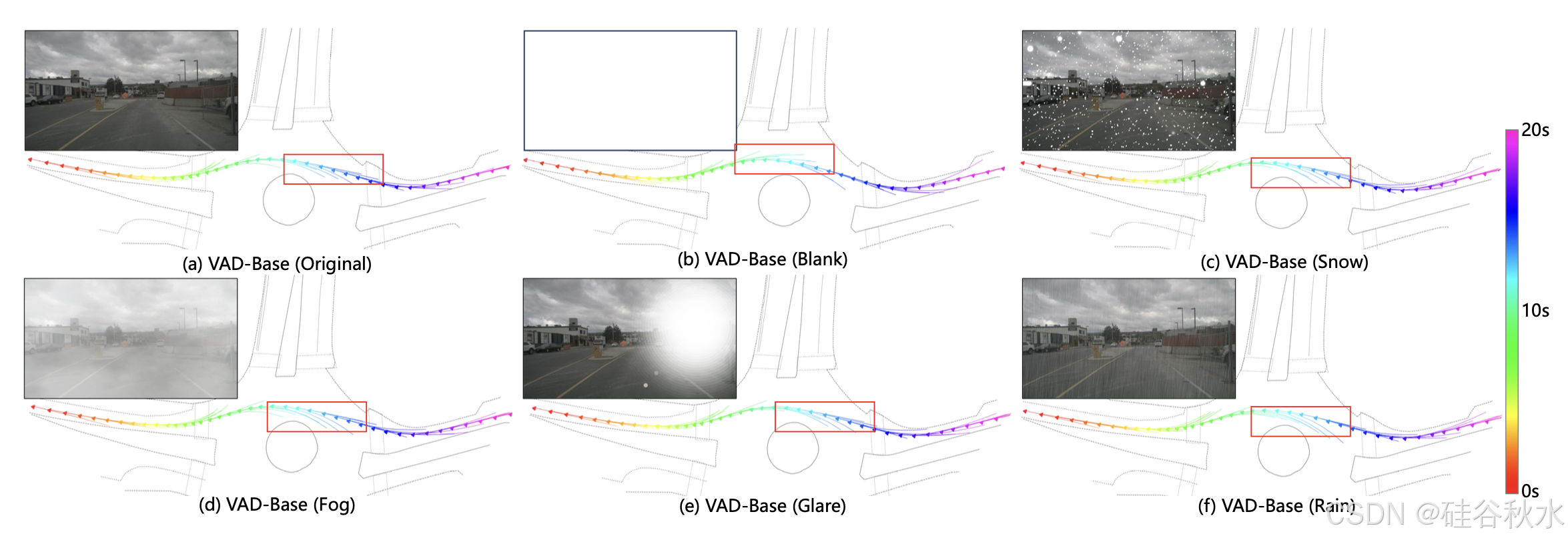
当改变自车的速度时,VAD 模型的规划结果受到显著影响,如图所示。将自车的速度设置为 100 米/秒会导致模型生成极不切实际的规划轨迹。对自我状态信息如此敏感的自动驾驶系统会带来相当大的安全风险。此外,由于规划结果主要由自我状态决定,模型中其他模块的功能无法体现。例如,在比较 VAD(ID-6)和 BEV-Planner++(ID-12)时,它们在 L2 和碰撞率方面获得的结果基本相似。
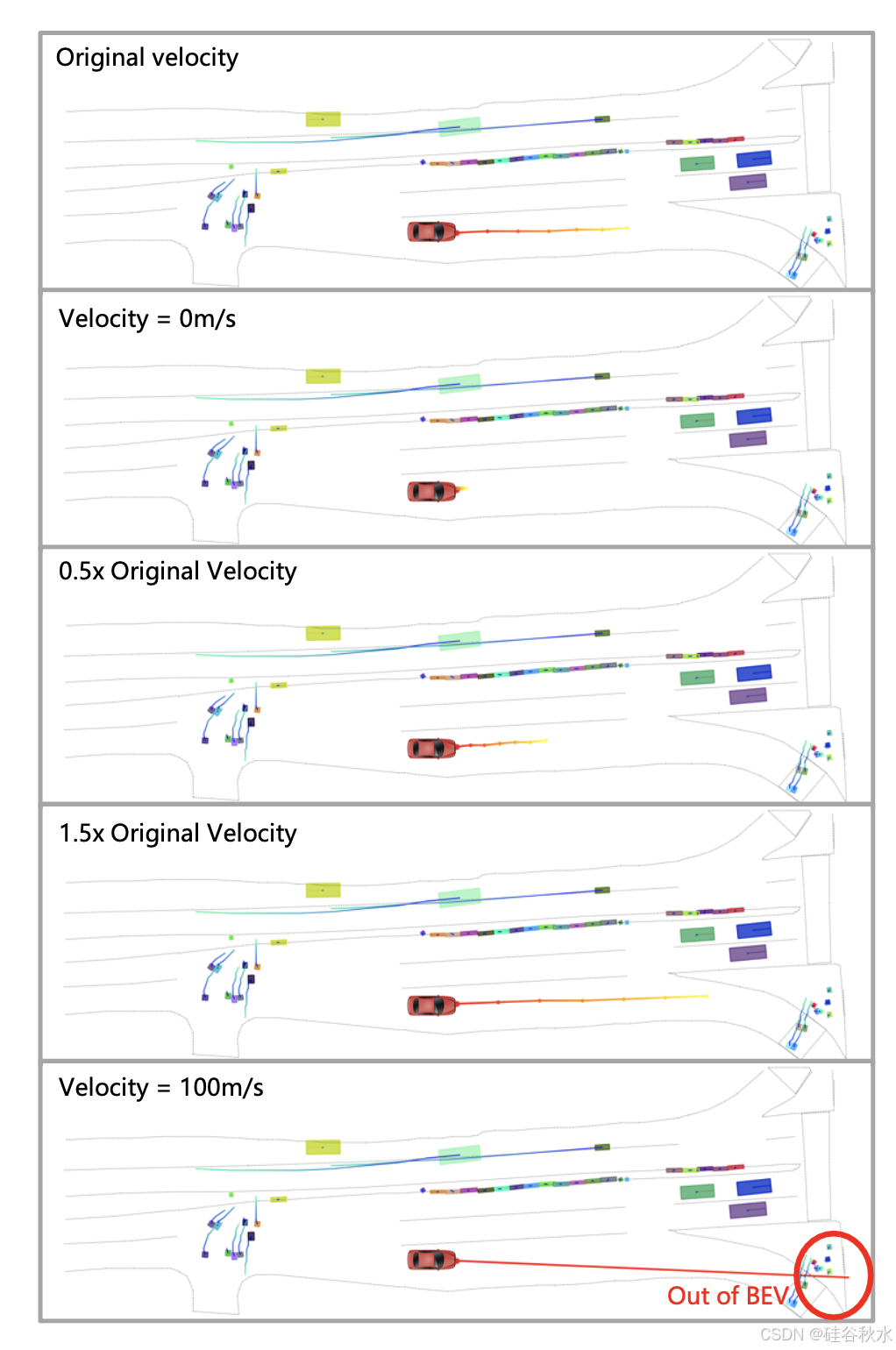
是否可以断言,**BEV-Planner++ 设计简单有效,即使在没有利用感知数据的情况下,也能获得与其他更复杂的方法相当的结果?**事实上,由于最终规划模块的性能主要受自车状态的影响,其他组件的设计不会显著影响规划结果。因此,利用自我状态的方法无法直接比较,不应从这种比较中得出结论。
**不使用自我状态怎么样?**鉴于自车状态对规划结果产生主导影响,这引发了一个重要的问题:在开环端到端研究中排除自我状态是否可行且有益?
在感知阶段忽略自我状态。事实上,现有方法 [16, 43] 忽略在 BEV 编码器中使用自我状态对规划的影响。
**没有自我状态,越简单越好?**为什么 BEV-Planner 在不使用额外感知任务(包括深度、高清地图、跟踪等)和自我状态的情况下,在 L2 距离和碰撞率方面取得比其他方法(ID-1 和 ID-4)更好的结果。既然 BEV-Planner 在路沿相撞率 (CCR) 方面表现不佳,那么如果在基线中添加地图感知任务会发生什么?为了解决这些问题,设计一个“BEV-Planner+Map”模型,在流水线中引入地图感知任务,主要遵循 UniAD 的设计。如表所示,当引入地图感知时,该模型在 L2 距离和碰撞率指标方面表现出较差的结果。唯一符合预期的方面是,引入地图感知显著降低了CCR。

通过对 BEV-Planner 与 BEV-Planner (init*) 进行比较,使用地图预训练权重可以提高性能。这意味着在“BEV-Planner+Map”中集成 MapFormer 后 L2 和碰撞率的下降并不是由于预训练权重造成的。假设在大多数直线驾驶场景中,添加车道信息可能不会产生明显有效的信息,并且确实会引入一定程度的干扰。为了验证假设,在不同的驾驶命令下评估这些方法的性能。如下两个表所示(L2-ST和L2-LR, Collision- ST和Collision- LR),添加地图信息会显著增加直行命令下的 L2 距离误差和碰撞率。相反,对于转弯场景,加入地图信息可有效降低碰撞率。


基于以上观察,可以初步得出以下结论:
在简单直接的驾驶场景中,添加感知信息似乎不会提高模型在 L2 距离和碰撞率方面的性能。相反,实施更复杂的多任务学习范例实际上可能会导致模型整体效能的下降。
在转弯等更复杂的场景中,结合感知信息可能有利于规划目的。然而,鉴于现有评估数据集中转弯场景的比例相对较小(13%),引入感知信息往往会对最终分析的平均性能指标(L2 距离和碰撞率)产生不利影响。
必须开发更强大、更具代表性的评估数据集。从当前评估数据集得出的指标并不完全具有说服力,无法准确反映模型的真实能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









