










23年12月来自同济大学的论文“A Survey on Robotic Manipulation of Deformable Objects: Recent Advances, Open Challenges and New Frontiers”。
机器人的可变形体操作 (DOM) 在工业、服务和医疗保健等各个领域有着广泛的应用。然而,与刚性体的操作相比,由于可变形体 (DO) 的状态空间维数无限且其动态复杂,DOM 对机器人的感知、建模和操作提出了重大挑战。计算机图形学和机器学习的发展为 DOM 带来了新技术。这些基于数据驱动范式的技术可以解决 DOM 分析方法面临的一些挑战。然而,一些现有的评论并没有涵盖 DOM 的所有方面,而一些先前的评论没有充分总结数据驱动的方法。本文调查 150 多项相关研究(主要是数据驱动方法),并总结 DO 感知、建模和操作方面的最新进展、开放挑战和新前沿。特别是总结大语言模型 (LLM) 在机器人操作方面取得的初步进展,并指出一些有价值的进一步研究方向。
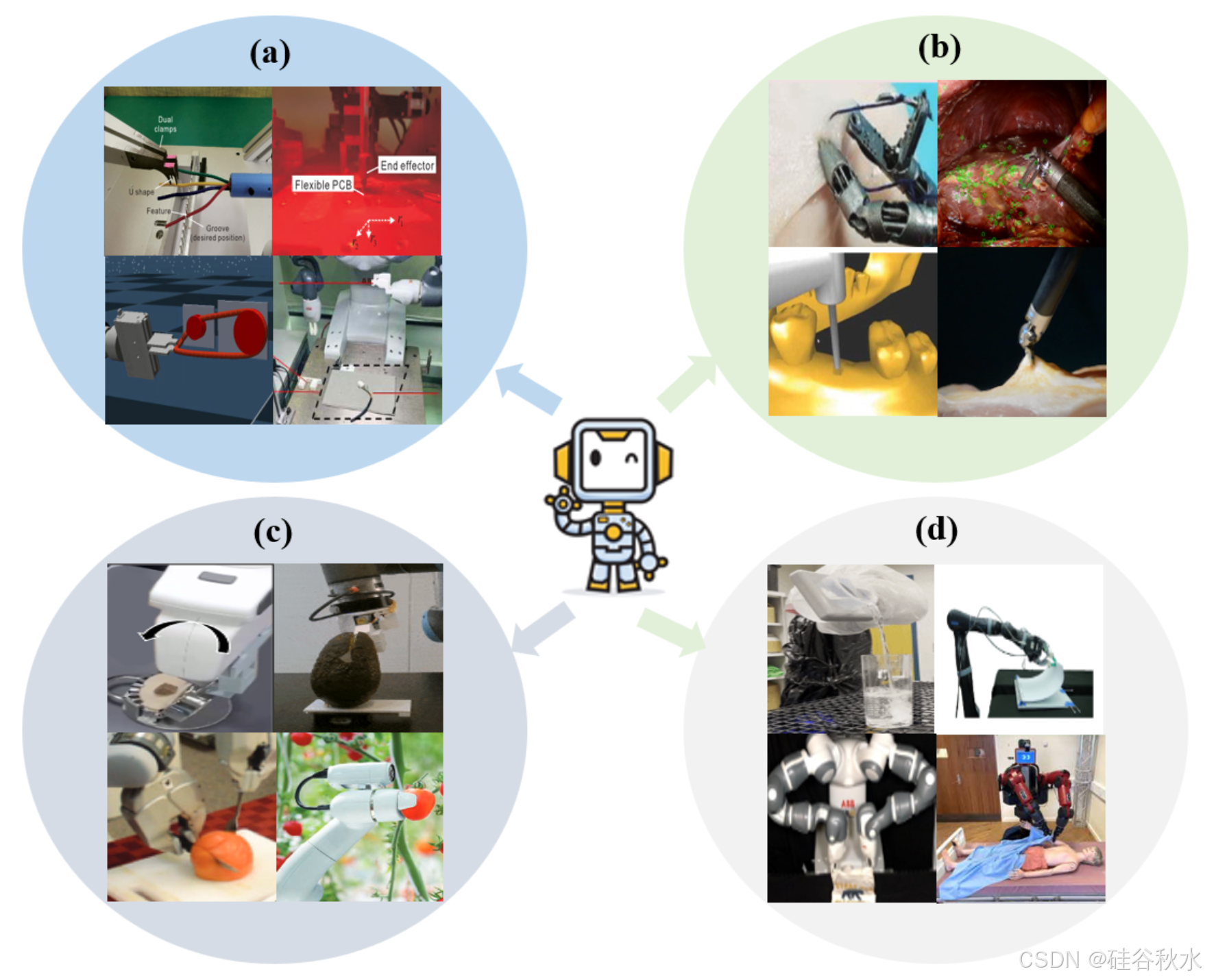
如图所示:DOM 的应用;(a)制造业 [3]–[6](b)医疗外科 [7]–[10](c)食品加工 [11]–[14](d)日常生活活动 [15]–[18]。
Kadi & Terzic [21] 的综述,仅关注使用数据驱动方法对服装进行操作。过去的一些综述 [22]–[24] 侧重于对 DO 进行建模,而不考虑感知和操作。之前的综述 [2][25] 很全面,但主要侧重于分析方法。Yin [20] 的综述,包括分析方法和数据驱动方法。
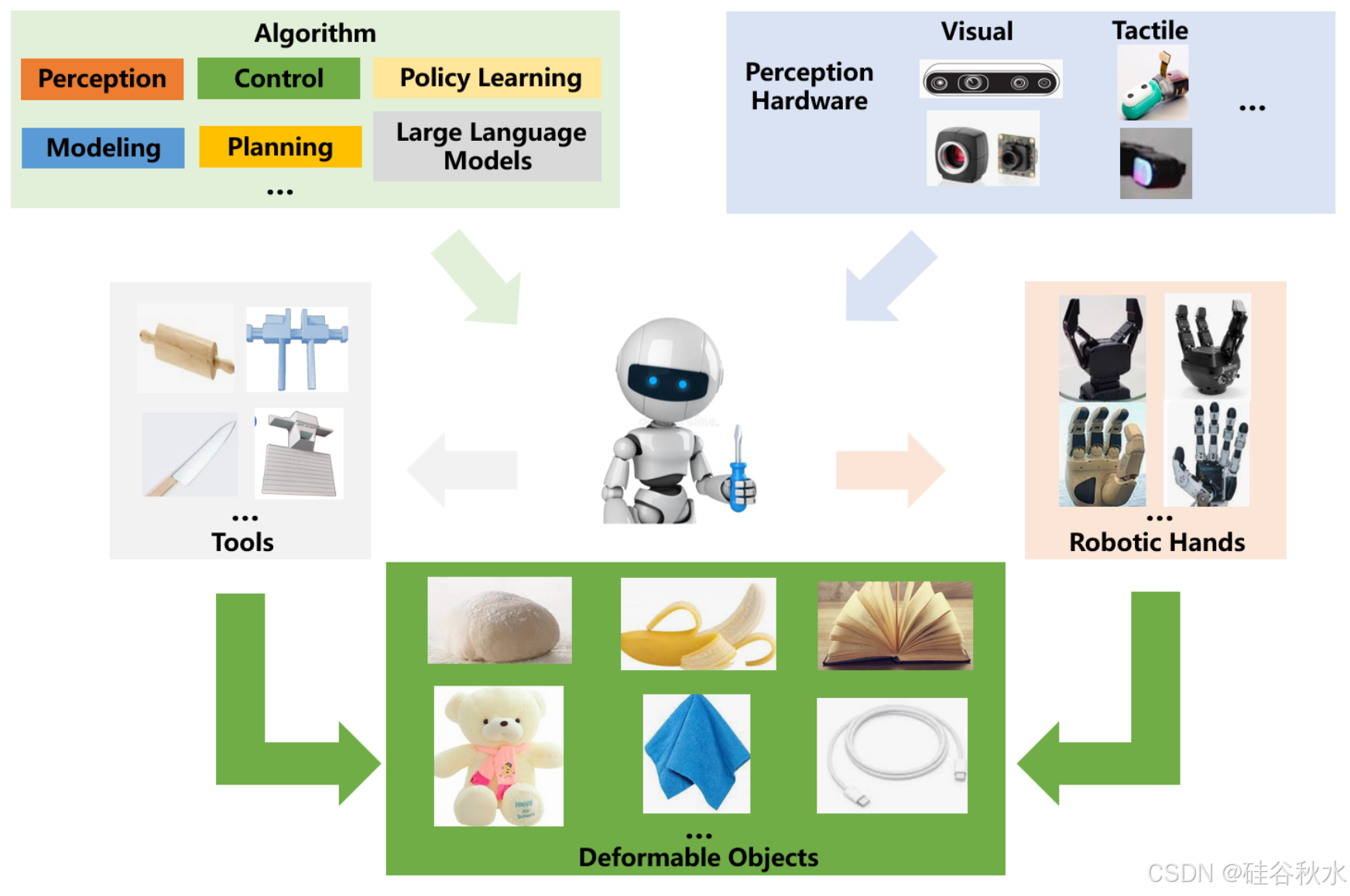
如图所示:用于处理 DO 的典型机器人系统包括机器人硬件、感知硬件、机械手、用于 DOM 的工具、各种功能的算法等。
感知
机器人需要快速、准确和多模态的感知能力来感知周围环境,这是完成复杂操作任务的先决条件 [26]。感知的目的是通过给定观测 O 和目标表示 R(·) 求解优化问题,来估计目标 X^∗ 的状态。
然而,找到可变形体 (DO) 的准确而有效的表示是一项开放的挑战,解决方案是特定于应用而定。将 DO 表示为粒子(particles)是常用的方法之一 [27]。
由于 DO 具有无限维状态空间,因此变形的感知变得极具挑战性。此外,遮挡和噪声在非结构化环境中很常见,这要求 DO 的状态估计具有很高的鲁棒性。
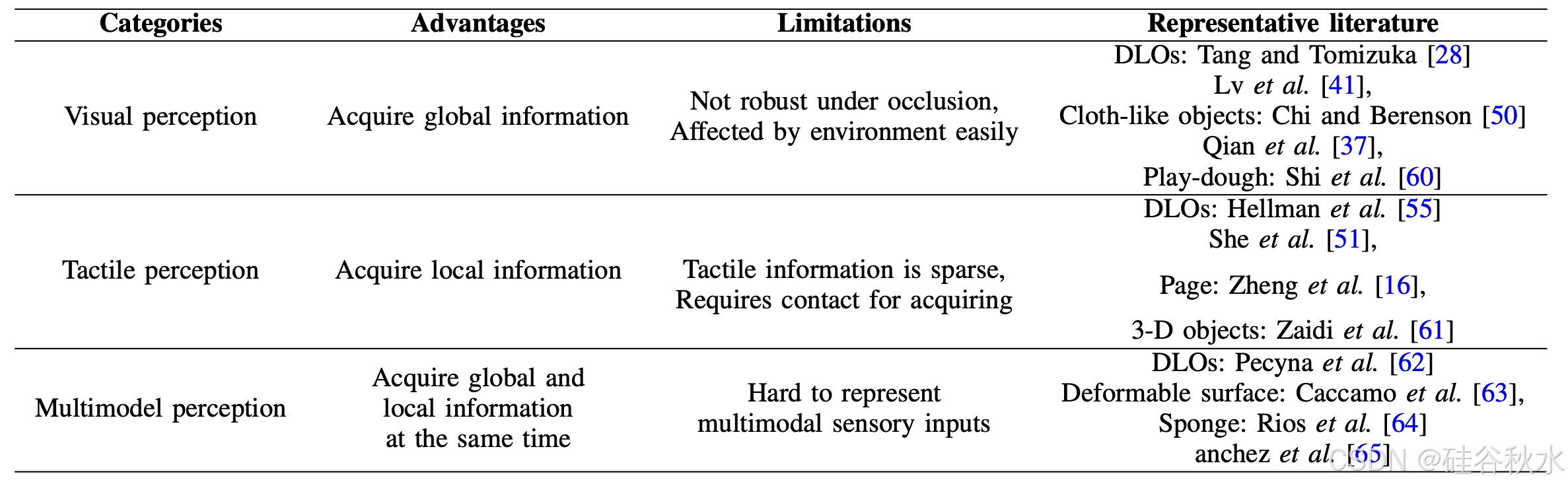
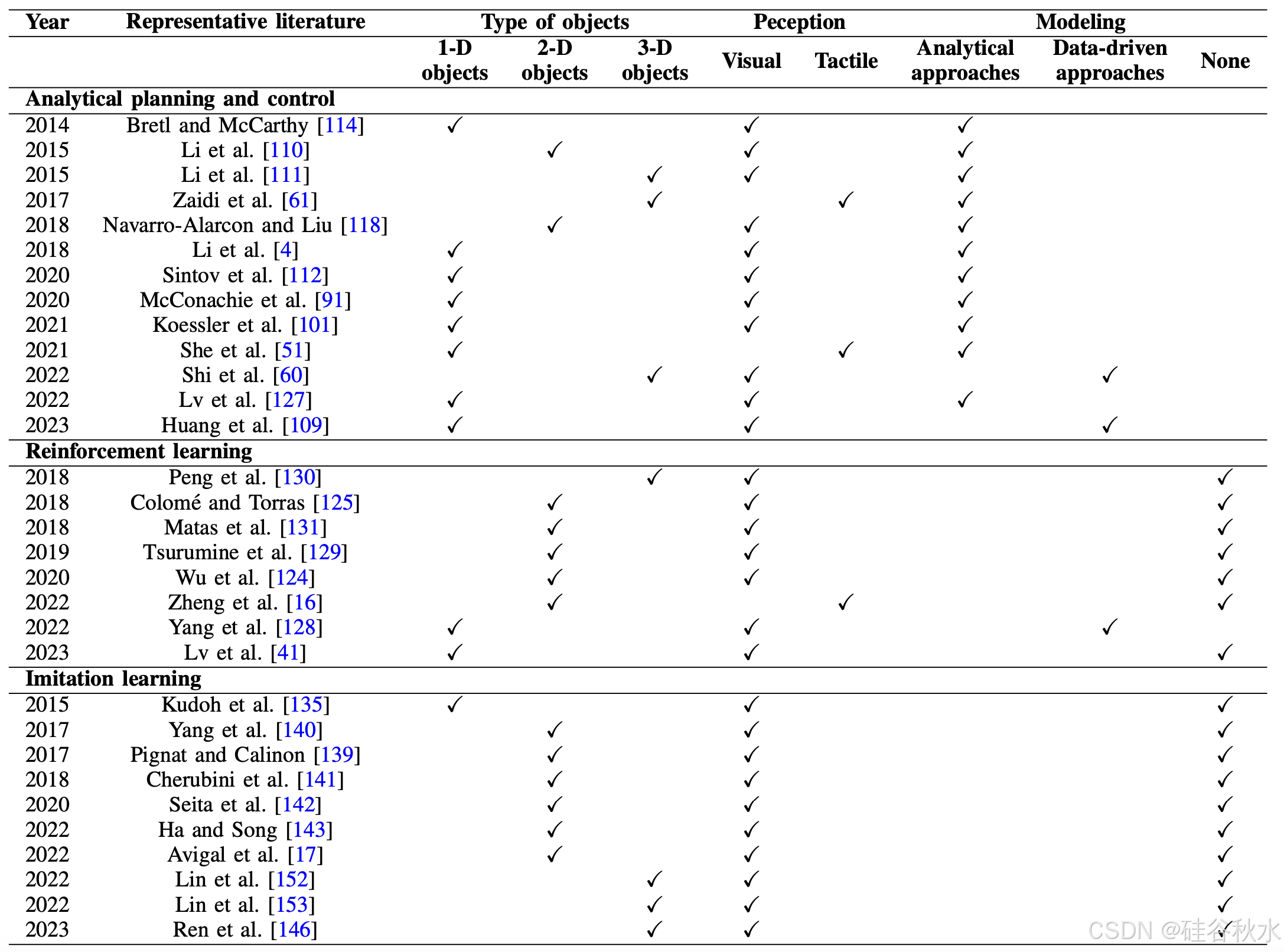
针对视觉感知和触觉感知,表一总结主要优点、局限性和代表性文献。
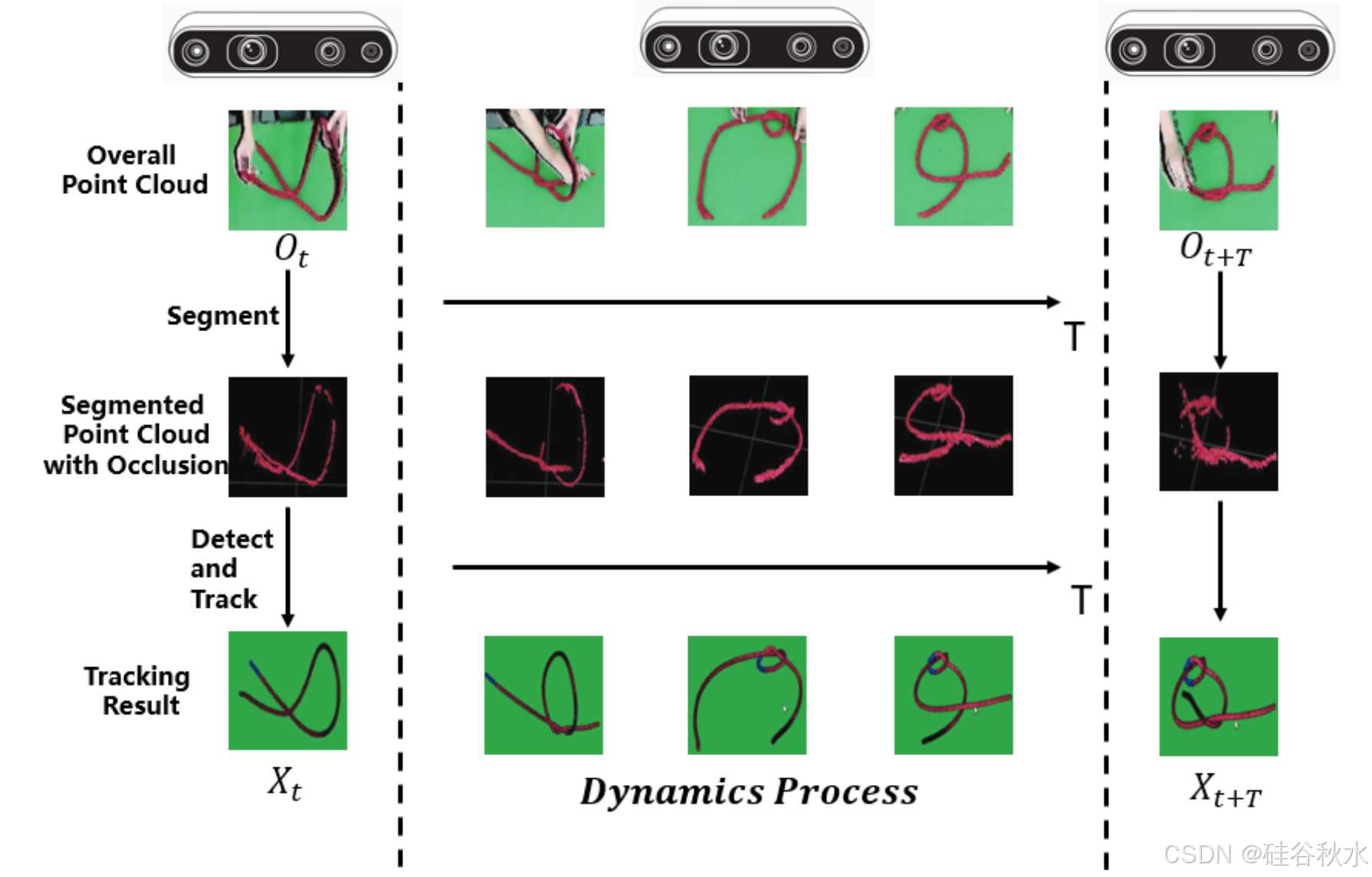
一个完整的基于视觉 DO 状态估计流程包括三个步骤,包括分割、检测和跟踪。分割旨在将 DO 与图像中的背景分开。检测是指从单个图像中估计 DO 状态的过程。跟踪是跨多帧跟踪 DO 的状态。如图显示对 DO 的实时跟踪。
触觉感知技术的进步激发了研究人员对探索触觉技术在 DOM 中应用的兴趣。视觉是一种主要获取形状和颜色等全局特征的感知方式,而触觉感知则是一种主要获取摩擦和纹理等局部特征的感知方式。触觉感知对于遮挡环境中的操控任务是一种有价值的方式,因为它可以提供有关所涉及物体的物理属性和相互作用的局部信息。
触觉设备。BioTac 触觉传感器是一种出色的设备,可以获得模拟人类指尖全部功能的感觉模式 [52]。它有一个包含所有传感电子设备的刚性核和一个由低成本硅胶制成的柔性皮肤,这提高了设计的耐用性和可修复性。然而,BioTac 的一个主要限制是其输出信号需要经过复杂的信号处理和数据融合,从而增加了计算工作量和延迟。
基于视觉的触觉传感器是一类传感器,它通过使用相机捕捉接触面的变形将触觉信息转换为视觉信息。这些传感器具有高空间分辨率的独特优势,已应用于各种机器人操作任务。GelSight 是一种著名的基于视觉触觉传感器,由 Yuan 于 2017 年提出 [53]。然而,GelSight 仍然有一个主要缺点,即无法模拟人类的触觉,如温度、湿度、疼痛等。
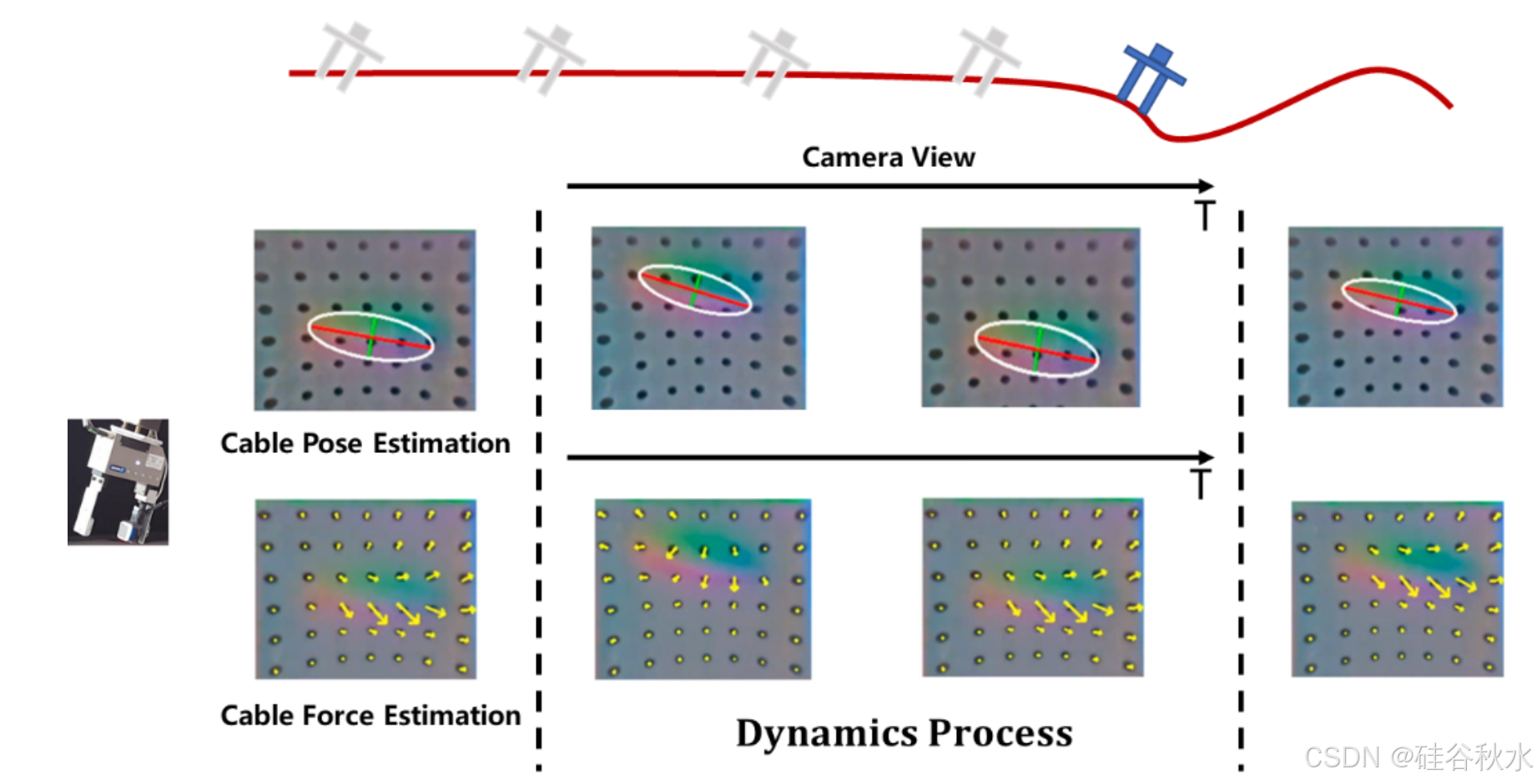
使用触觉感知的 DOM 应用。尽管触觉感知对于操作很有价值,尤其是在视觉被遮挡时,但仅依赖触觉感知的操作任务很少。其中一项任务是电缆跟踪或织物跟踪。She [51] 提出一种使用基于 GelSight 技术的触觉传感器来估计机器人所持电缆的姿态和摩擦力的方法。该过程如图所示。Hellman [55] 介绍一种使用 BioTac 进行触觉驱动轮廓跟踪任务的实时触觉感知和决策方法。Zheng [16] 提出一种通过 Biotac 捕捉翻页过程中触觉信号变化的方法。这项研究建立触觉信号与合理翻页轨迹之间的关系,使机器人能够学会合理地翻页。此外,在 [54] 中提出的高分辨率触觉手套的基础上,Zhang [56] 提出的系统可以执行涉及不同目标的多种交互任务。触觉模型结合预测模型和对比学习模块,仅根据触摸数据即可估计手和目标的三维坐标。
建模
为了执行 DOM,应该有一个能够根据当前状态预测后续时间步骤中 DO 状态的模型。此类模型需要推理 DO 的动态。下表概述主要优点、局限性和代表性文献。
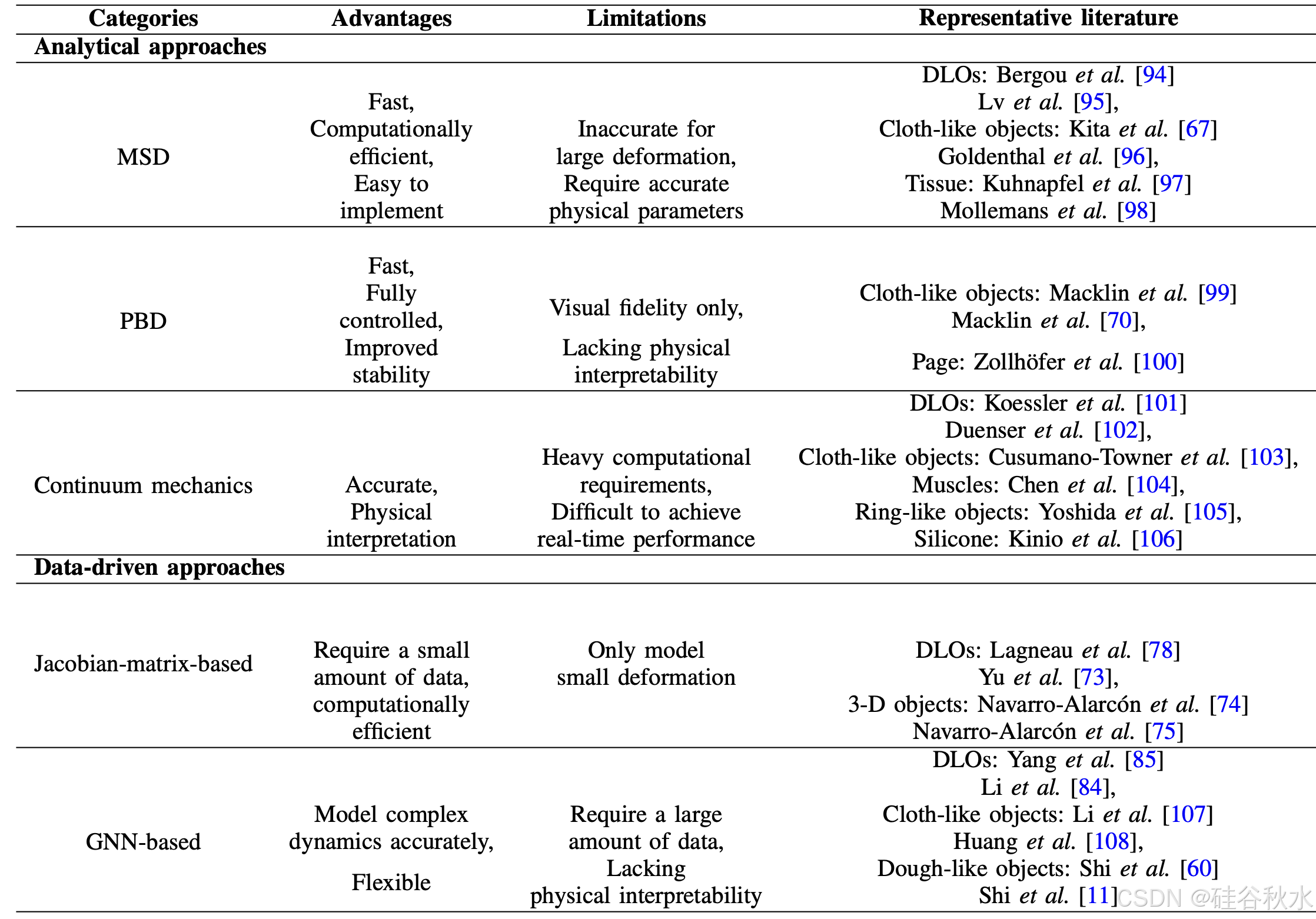
分析建模方法
分析建模方法遵循牛顿第二定律。包括质量-弹簧-阻尼器 (MSD) 系统、基于位置的动力学 (PBD) 和连续力学。
质量-弹簧-阻尼器系统。如图(a)所示,MSD系统将可变形材料建模为网络结构。网络中的每个粒子都具有质量属性,粒子之间的连接由弹簧和阻尼器建模。
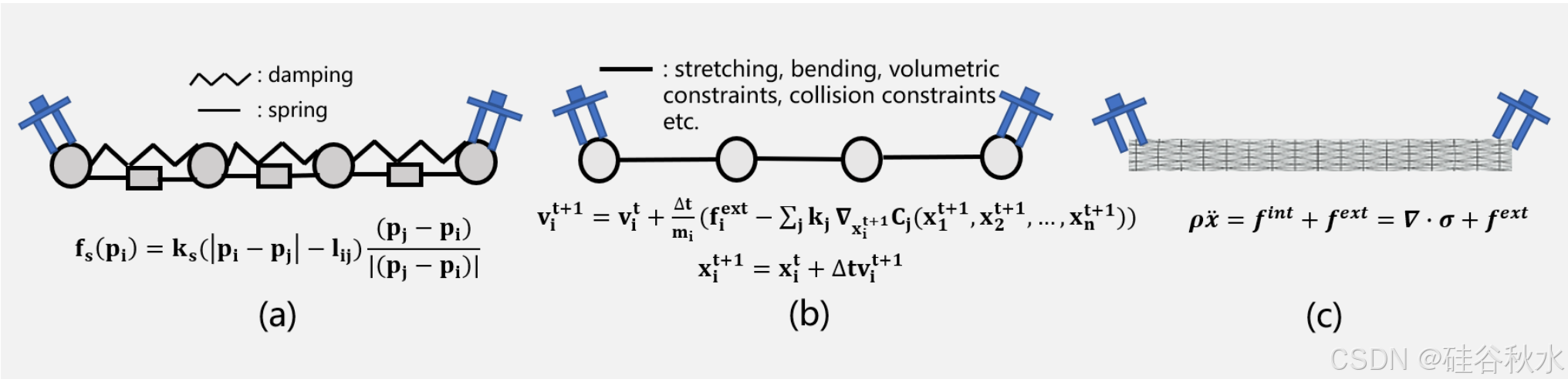
MSD 系统为模拟 DO 提供了多种优势,例如直观性、易于实现和计算效率高,这有助于实现实时动画。MSD 模型适用于需要在物理精度和计算速度之间进行折衷的应用。它们已被用于模拟各种类型的 DO,例如 DLO 模拟 [66] 和服装模拟 [67]。
基于位置的动力学。如上图 (b) 所示的 PBD 是一个基于粒子的模型,它结合了内部和碰撞约束。约束包括拉伸、弯曲、体约束、碰撞约束等。根据牛顿第二运动定律,目标的加速度由内力和外力之和决定。采用时间积分法更新目标的速度和位置。一组约束由利用高斯-赛德尔方法的迭代求解器循环求解,直到满足收敛标准或超过最大迭代次数。
PBD 是一种可以实现快速、完全可控模拟并提高稳定性的技术。该方法可以轻松地将各种约束纳入系统,并通过设置边界条件来驱动系统。一些流行的物理引擎(如 PhysX、Bullet 和 Havok)已在其系统中实施 PBD 来模拟 DO 的动态。
连续力学。DO通常被建模为如上图(c)所示的连续目标。位移、应变和应力是影响 DO 行为特征理解的关键量。通过将梯度算子应用于应力张量,应力项可以捕捉内部弹性效应。
连续材料适合对需要高精度模拟的 DO 进行建模,因为它们可以更准确地捕捉变形效应。模型参数具有独特的物理意义,可以借助 FEM 等灵活的计算框架有效地应用于各种场景。然而,与 PBD 相比,连续材料的计算和实现更为复杂。线性 FEM 在变形保持在较小范围内的机器人情况下很常见。然而,除非采用显式积分方案或硬件加速实现,否则非线性模型通常缺乏实现实时性能所需的速度。
数据驱动建模方法
数据驱动模型通过直接分析数据获得对复杂动态的广泛洞察 [71],[72]。因此,该方法在规划和控制应用中非常有用。其包括基于雅可比矩阵的模型和基于 GNN 的模型。
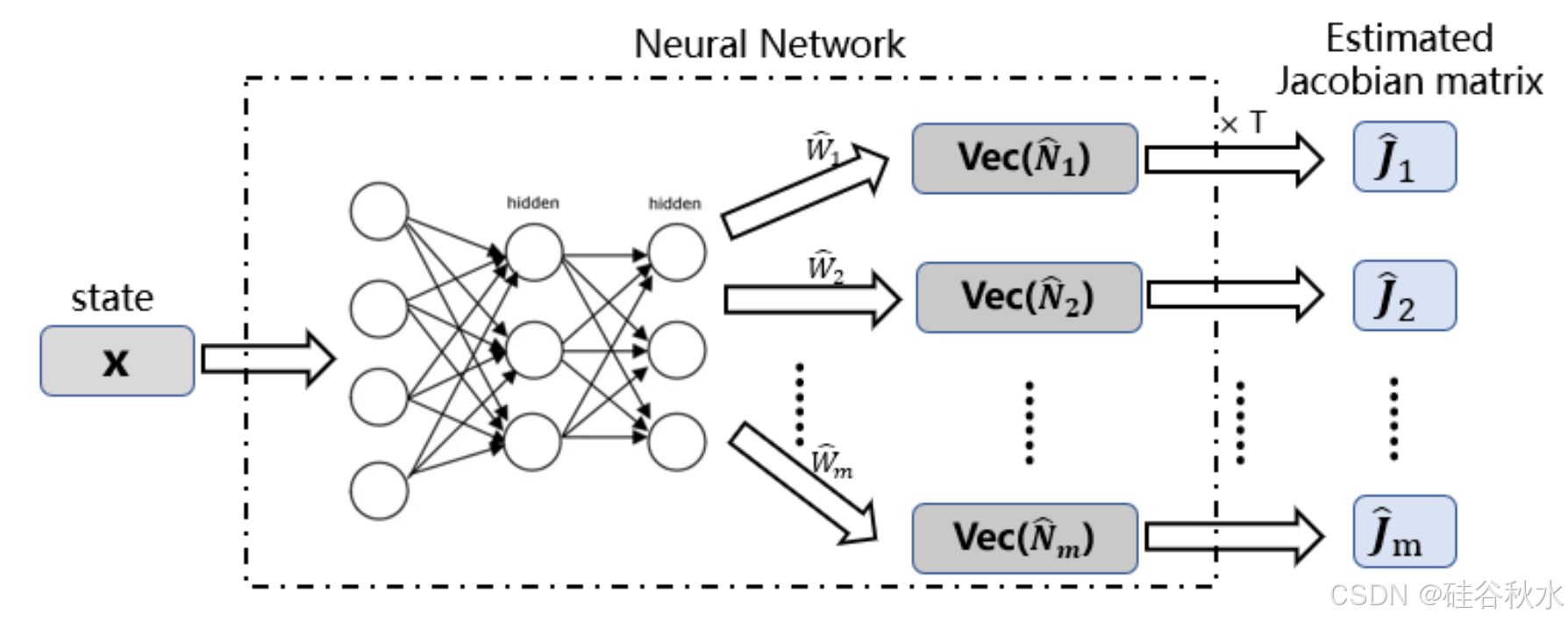
基于雅可比矩阵的模型。DO 的状态可以用一组描述其形状和配置的特征来表征。对 DO 进行建模可以看作是研究末端执行器的状态与 DO 特征的状态之间的映射。雅可比矩阵可用于局部近似此映射。
这些模型具有线性结构,可以用少量数据实时计算。与直接使用深度神经网络 (DNN) 建模相比,基于雅可比矩阵的建模方法可以更有效地利用数据。
一些研究人员已经采用专门的在线技术来估计雅可比矩阵,以建立 DO 的局部线性变形模型 [74]–[79]。由于这些模型可以在线执行,因此可以很容易地应用于各种新目标。然而,这些估计模型中使用有限量的局部数据会影响其准确性,从而限制其对局部配置的有效性。因此,这种方法只能处理具有小幅和局部变形的任务。对于 DO 的全局建模和控制,Yu [73] 开发一种通过整合离线学习和在线自适应来有效学习 DO 全局变形模型的方法。他们采用径向基函数神经网络 (RBFN) 来近似从 DO 的当前状态到当前线性变形模型的非线性映射,如图所示。
基于 GNN 的模型。基于 DNN 的方法比基于雅可比矩阵的方法具有更强的表示能力,从而提高了其准确性和鲁棒性 [80]。此外,它们可以集成物理模型并推断目标如何相互作用 [27]。这些模型可以应对非常复杂的系统,并在更广泛的情况下表现良好,在一定程度上克服了线性模型受局部条件约束的缺点。然而,这种方法需要大量的数据集,而这些数据集在某些情况下可能无法获得。
DO 的特征很复杂,因此对于 MLP、CNN 和 LSTM 等通用网络结构来说,捕捉各种 DO 的行为具有挑战性。对 GNN 的研究 [83] 为 DO 建模带来了新的结构。Battaglia [27] 提出交互网络 (IN),这是一种通用的可学习物理引擎,可以实现以目标和关系为中心的物理推理。IN 将目标的粒子表示为图的节点,将节点对之间的交互表示为图的边。IN 使用目标函数和关系函数以组合的方式对目标及其关系进行建模。IN 可以学习 DO 不同部分之间成对的局部交互。如图显示 IN 的预测过程。
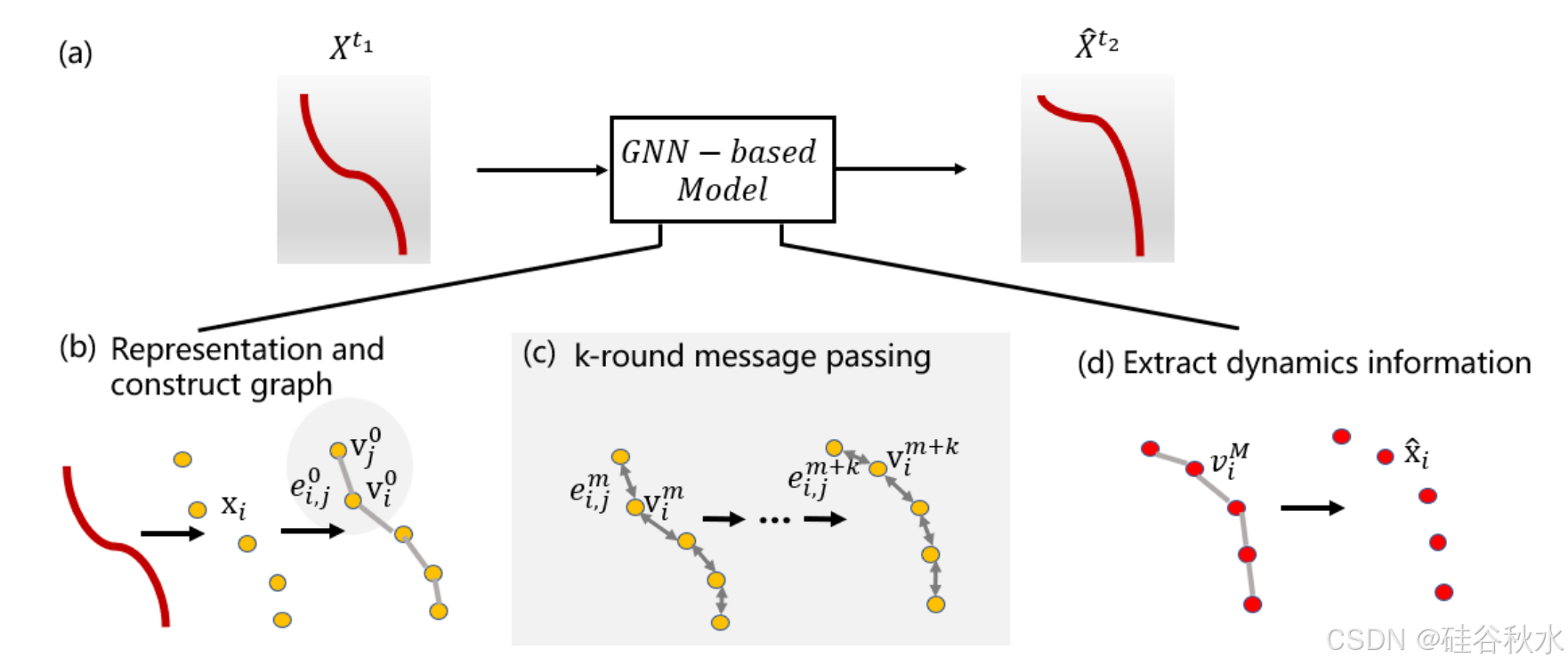
假设有两个目标和一个有向关系,例如,一个固定目标通过弹簧连接到一个可移动的质量,第一个目标(发送者 o/1 )通过它们的相互作用影响第二个目标(接收者 o/2 )。这种相互作用 e/t+1 的影响可以通过关系中心函数 f/R 来估计。f/R 将 o/1、o/2 及其关系 r 的属性(例如弹簧常数)作为输入。f/O 适合将 e/t+1 和接收者的当前状态 o/1,t 作为输入,从而允许交互影响其后续的状态 o/2,t+1。
基于 GNN 的方法是一种表示结构信息的有效方法,但它们也有一些局限性。除非做出特定假设(例如使用抽象语法树),否则通过图表达递归、控制流和条件迭代等概念可能会带来挑战。程序和更“类似计算机”的处理可以对这些概念具有更强的表达能力和灵活性,一些研究人员认为它们是人类认知的重要组成部分(Tenenbaum [87];Lake [88];Goodman [89])。
数据驱动方法依赖于模拟器来生成数据。因此,模拟和真实场景之间的差距仍然是将模型应用于现实世界中的机器人操作任务的主要障碍。一些研究[18]、[60]、[90]提出了不同的方法来解决模拟与现实之间的差距问题。Wang [90]使用GNN从合成数据中学习动力学模型。然后,学习在线线性残差模型以缩小模拟与现实之间的差距。Zhang&Demiris[18]提出的工作,比较了真实和模拟的目标观测对,以了解它们的物理相似性,这使得模拟器能够更好地适应现实世界目标的物理特性。Shi[60]介绍的研究直接从真实观测中获取数据,并使用GNN学习基于粒子的动力学模型来对Play-Doh执行变形操作。上述三种方法对于模拟与现实之间的差距问题都是有效的(在一定程度上)。
建模讨论
获得 DO 的精确变形模型是一项艰巨的任务,因为它们在理论上很难计算。由于 DO 的状态维度无限,并且在现实世界中难以获取 DO 的参数,因此分析建模方法无法准确地对 DO 进行建模。如果有足够的高质量数据,数据驱动方法可以从数据中学习一个相当准确的模型,而无需了解复杂的物理动力学。由于不同 DO 的长度、厚度、材料等不同,变形模型可能存在很大差异。为每个 DOM 任务花费大量时间收集新数据是不切实际的。
分析模型和学习模型的预测能力都是有限的。这些模型仅对某些类型的任务有效。因此,研究人员提出了评估方法 [91]–[93] 来评估模型在操作任务中的可靠性。在模型表现出不可靠性的情况下,应考虑重新规划或恢复策略。
操纵
操纵 DO 的目的是确定驱动点的最佳力或运动,以实现给定的任务目标。下表全面概述操纵,并总结代表性文献。
DOM 规划
规划是为机器人或目标找到最佳配置序列以实现预期目标的过程。考虑一个任务,例如将绳子弯曲成某种形状。解决这个问题的常用方法是将其表述为一个优化问题。
1)在动作空间中发射:上述问题的一个可能解决方案是应用样本动作序列,然后根据预测轨迹的计算成本对其进行更新。如图(a)说明在动作空间中发射的过程。一般来说,动作空间的维数比目标状态空间低得多,这有助于在动作空间中进行搜索。精确的动力学建模和有效的后向梯度评估对于这种规划方法至关重要。
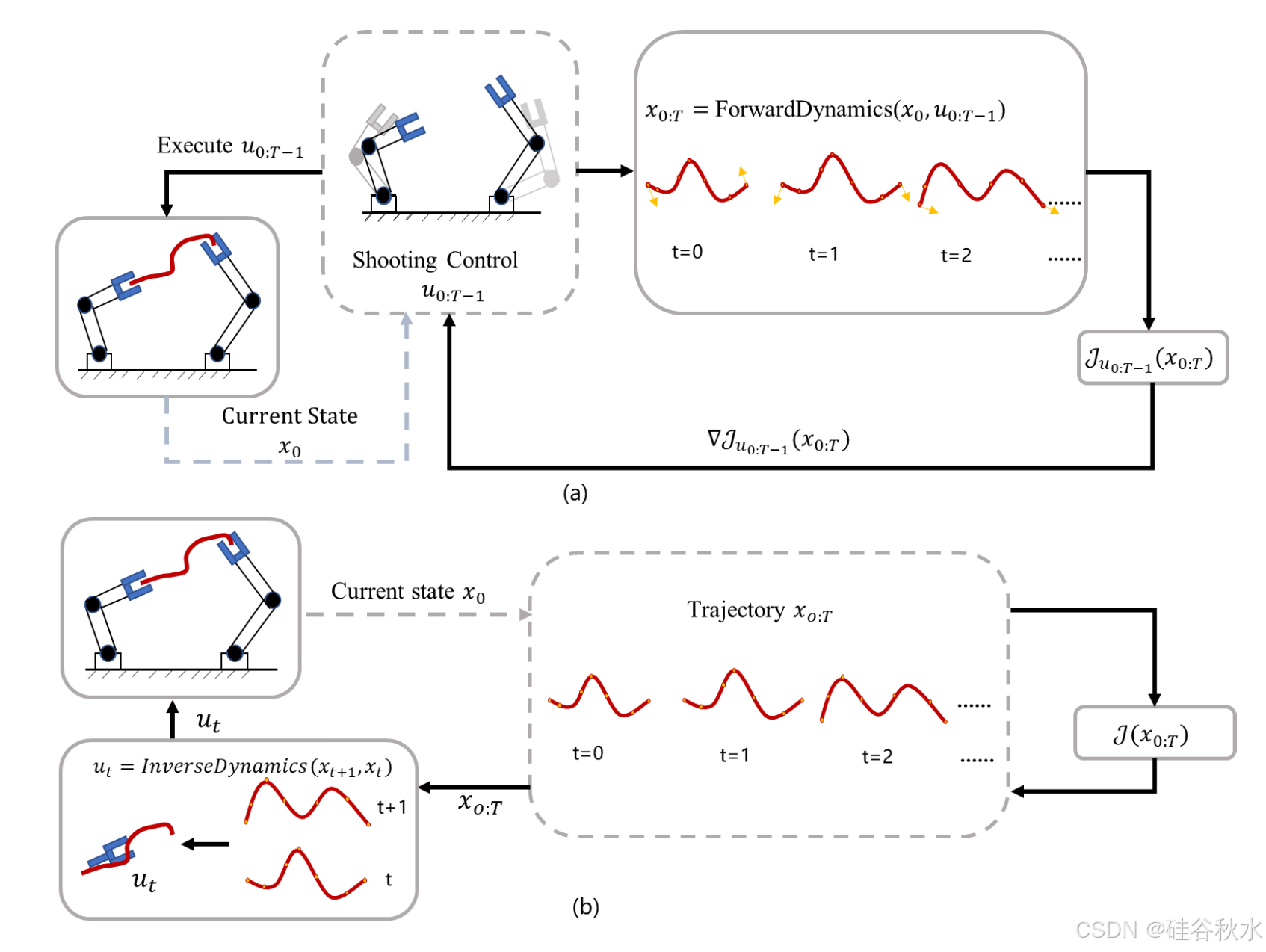
Huang[109]提出一种使用双臂机器人系统通过在动作空间中搜索动作对DLO进行形状控制操作的方法。Shi[60]提出一种使用这种规划方法将Play-Doh变形为各种字母形状的方法,其能力与人类相当。其他研究[61],[110],[111]也专注于依靠动作空间发射生成操纵动作。
- 搜索状态轨迹:规划操作动作的一种可能方法是在目标状态空间中进行探索,例如,找到 x/t 的低成本路径,然后为每个时间转换生成相应的动作。搜索状态轨迹的过程如图 (b) 所示。这里的挑战是有效地搜索或采样在大型状态空间中动态可行的配置。因此,相关研究的重点是如何有效地定义状态表示或转换模型。
Sintov [112] 证明,弹性杆的配置空间(表示杆的所有可能位置和方向的集合)是一个有限维的光滑流形。他们还提出一种基于图的该流形参数化方法和一种基于采样的算法来计算任意两个稳定杆配置之间的无碰撞和运动学上可行的路径。 Lui & Saxena [113] 提出的研究,通过使用简单但有效的 DLO 能量模型来计算保证任务可实现性的粗略路径,提高 DLO 塑造任务的规划效率。他们还设计一个局部控制器,该控制器遵循此路径并通过闭环反馈对其进行调整,以补偿规划误差并实现任务准确性。其他研究 [91]、[114]、[115] 也侧重于定义状态表示或转换模型以有效地搜索状态轨迹。
DOM 的控制策略
控制旨在设计机器人执行所需动作的输入。利用传感反馈的闭环控制可以应对 DOM 中的各种不确定性。然而,由于 DO 的复杂动态,无法综合具有理论保证的全局控制策略。因此,采用局部控制器在指定的操作点施加力或速度。控制最小化当前状态 x/i 和目标(target)状态 x/g 之间的不匹配,可能在特征空间 φ(·) 中。由于实时约束,u(·) 通常使用简单方法计算,例如操作点和特征点之间的线性函数 [116]–[118] 或具有单步范围的数值优化程序 [119][120]。如图显示 DOM 的简单控制框架。
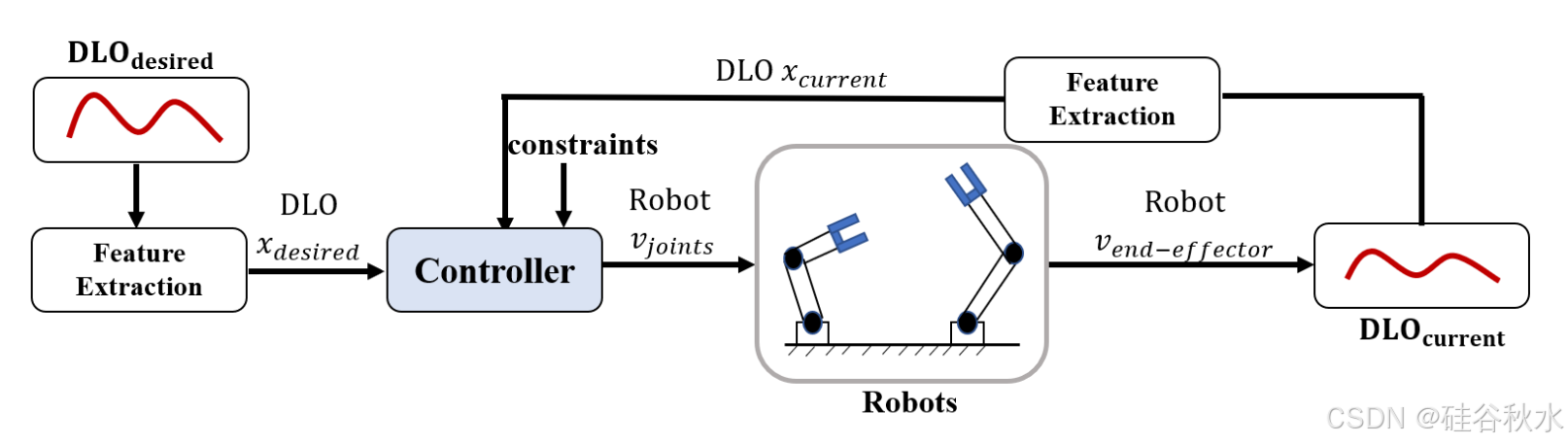
一些示例使用纯视觉伺服框架来调节速度,例如布置布料 [119],[121]、操纵 DLO [4],[101],[114],[122],[123]。另一方面,触觉特征用于调整操纵动作,例如电缆操纵 [51]。
基于学习的方法
各种 DOM 任务都可以通过基于学习的方法实现。本文主要关注 RL 和 IL。基于学习的方法的优势在于无需 DO 的动态模型,而许多 DO 很难获得该模型。
DOM 的强化学习(RL)。RL 是一种通过与环境的反复试验交互来学习最佳控制策略的范例。学习目标是最大化交互过程中获得的累积奖励。如图显示了 RL 的流程。
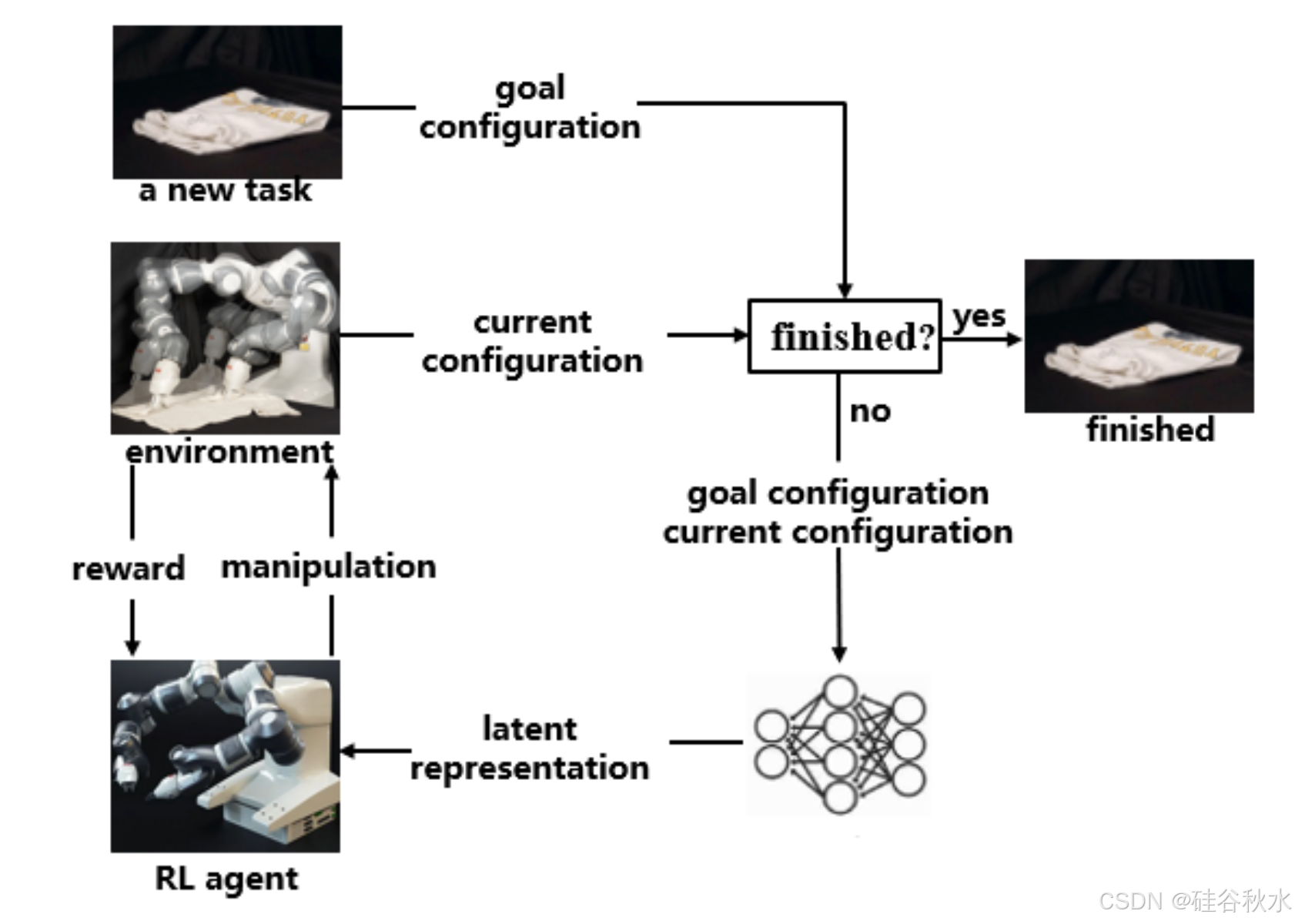
RL 旨在通过最大化预期的未来累积奖励来找到最佳策略 π。通常,在无模型 RL 中不需要 DO 的显式动力学模型。尽管如此,RL 仍面临着一系列挑战。其中一个挑战是探索过程通常样本效率低下,尤其是对于具有无限维度的 DO。另一个挑战来自于在真实环境中进行数以万计反复试验交互的固有危险。模拟器的发展促进了模拟环境中的训练。然而,主要的挑战在于将学习的策略迁移到真实的机器人身上。
可以在策略设计中嵌入结构或降低特征的维数,以提高 RL 效率。Wu [124] 提出了一个迭代的拾取和放置动作空间,其中考虑 DO 上的拾取和放置动作之间的条件关系。这种方法采用显式结构编码来促进学习和 DO 的组织技能。Colome [125] 研究使用线性降维同时学习 DMP 特征化的机器人运动及其底层关节耦合。这种方法提供宝贵的定性信息,从而可以对运动进行简洁直观的代数描述。此外,该方法有效地减少强化学习算法需要探索的参数数量。
广泛用于深度强化学习算法的无模型强化学习方法,对数据的需求很高,这阻碍了它们在现实世界的机器人问题中的适用性。相反,基于模型的强化学习方法预计会比无模型强化学习方法实现更好的数据效率,前提是模型是可访问的 [126]。Lv 开发一种结合传感信息的基于模型强化学习系统,名为 SAM-RL [127]。SAM-RL 利用基于差分物理的模拟和渲染来动态更新模型。此过程涉及将渲染的图像与真实的原始图像进行比较,从而高效地生成策略。该系统在穿针引线任务中表现出色,大大减少训练时间,并显著提高成功率。此外,Yang [128] 提出一种基于模型的强化学习系统,该系统结合传感信息。SAM-RL 利用基于差分物理的模拟和渲染来动态更新模型。此过程涉及将渲染的图像与真实的原始图像进行比较,从而高效地生成策略。该系统在穿针引线任务中表现出色,大大减少训练时间,并显著提高成功率。 [128] 采用基于模型的 RL 框架,将学习与探索交织在一起,以解决 DLO 的 3-D 形状控制任务。与最先进的无模型 RL 方法相比,该方法展示卓越的电缆形状控制性能,同时使用的交互样本明显更少。
为了降低策略迭代的成本,通过手动演示初始化 RL 已成为一种可行的方法。Zheng [16] 在真实机器人中手动初始化翻页轨迹。然后,通过使用触觉传感器的反馈作为奖励,进一步学习翻页轨迹,让真实机器人仅通过 200 次反复试验就能学会如何翻书。此外,Tsurumine 提出的工作 [129] 已经证明仅使用 80 个样本进行策略初始化和 100 个样本进行 RL 就能学习洗衣折叠的能力。
模拟器的出现使得在模拟环境中执行学习迭代成为可能。然而,在将学习的策略迁移到现实世界时,模拟和现实之间往往会存在差异。域随机化 (DR) 是一种旨在通过随机增强模拟的视觉参数(如纹理和光照)来缓解视觉模拟与现实之间差异的技术。这种方法使该策略能够学习通用的和与任务相关的视觉特征。尽管 DR 方法在实现跨域泛化方面取得成功 [130],但它们在任务特异性和适应性方面仍然面临挑战。Matas 提出的工作 [131] 使用基于像素级域自适应的视觉 RL 流水线来弥合模拟与现实之间的差距,并在器官回缩医疗操作任务中证明其有效性。此外,学习残差策略来弥合现实与模拟之间的差距是另一种重要方法。例如,Lv 提出的工作 [127] 通过学习残差策略成功地完成现实世界中的穿针引线任务。这表明学习残差策略有助于缓解模拟与现实之间的差距。
DOM 的模仿学习(IL)。IL 是一种控制技术,它利用来自专家演示的数据来学习将原始输入映射到动作的策略。IL 已成功应用于各种操作领域 [132]–[134]。如图显示 IL 的流程。IL 的目标是获得一种能够准确模仿专家演示者行为的策略。
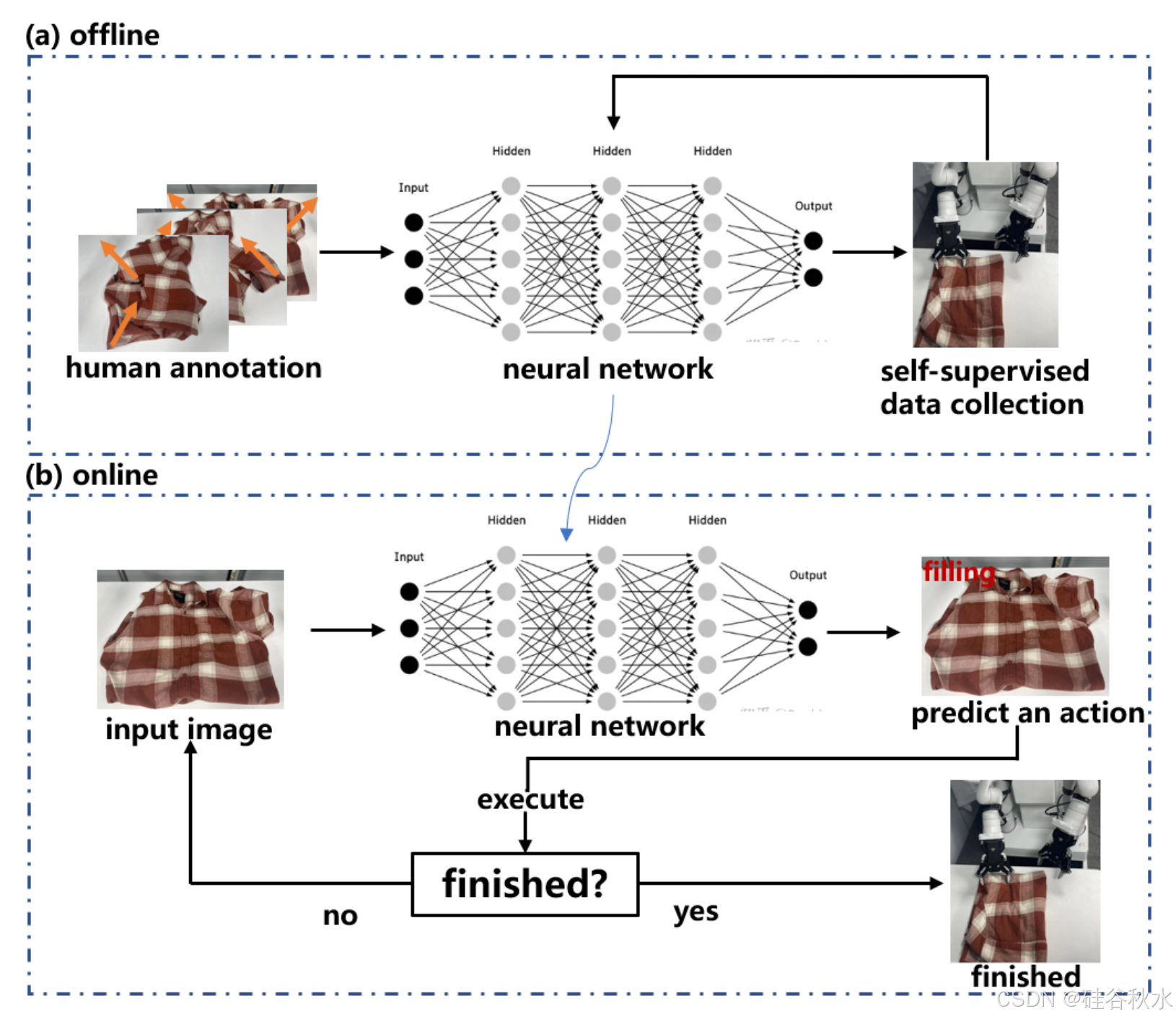
IL 和 RL 之间的一个主要区别是 IL 不需要奖励函数,因此无需在许多机器人应用中难以实现的奖励工程。然而,这种方法有一些局限性,比如需要大量的演示和较差的泛化能力。IL 的早期工作侧重于提取原始动作,并使机器人能够通过动觉教学(kinesthetic teaching)学习 DOM 的原始动作。例如,Kudoh 提出一种由双臂多指机器人进行空中打结的方法 [135]。打结任务分解为六个基本动作,即抓取、释放、双抓、缠绕、扭转和滑动。机器人通过人类演示学习这六个基本动作,并将它们组合起来执行各种打结任务。除了空中打结外,该方法及其变体还可以实现绳索打结 [136]、织物折叠 [137] 和缝纫 [138]。进一步的扩展是将任务参数合并到模型中以增强模型的通用性。例如,通过使用任务参数化模型 [139],穿衣动作可以适应不同的手臂姿势。最近的研究使得根据当前观察来规划动作成为可能。这是通过收集和注释大量演示数据并提取特征来实现的 [17][140]–[143]。例如,一系列用于折叠衣服的双臂动作基元首先被参数化 [17]。在从 4,300 个人类标记的动作中学习后,该系统可以根据视觉信息预测成对的钳口夹紧姿势。它能够在平均 120 秒内以 93% 的成功率折叠随机放置的服装。
IL 方法需要重新训练,以将学习的技能从已知实例迁移到类似/新实例。在戴帽子任务中,在模拟和现实环境中,训练阶段需要重复戴帽子步骤数千次。然而,为了处理一顶新帽子,需要收集新数据并重新训练模型,因为新帽子的形状和变形会发生变化。因此,这些步骤会产生大量的计算和时间成本,这阻碍这种方法在现实场景中的可行性。最近,一些研究 [144]、[145] 探索 IL 对刚体进行类别级操作。然而,这些方法不能应用于 DO。与姿势可以用低维向量完全表示的刚体不同,DO 具有无限的配置空间,容易出现严重的自遮挡。这些特点对不同 DO 之间的技能泛化提出了挑战。最近,Ren [146] 提出一种在类别级别操纵可变形三维体的新框架,只需一次演示就可以将学到的技能迁移到类似目标的新实例上。具体来说,该框架由两个模块组成。第一个模块 Nocs 状态转换 (NST),将观察到的目标点云转换为预定义的统一姿势状态(即 Nocs 状态),作为类别级技能学习的基础。第二个模块神经空间编码 (NSE) 通过对类别级空间信息进行编码,从而无需重新训练即可推断出最佳抓握点,从而使学习的技能适应新实例。
操作讨论
目前,DOM 的短期任务已经取得了重大进展。然而,现实世界的操作任务通常需要一系列具有不同特征和目标的子任务。这些长期而复杂的任务需要灵巧的手或多种工具来执行不同的子任务。子技能的组合泛化被认为是长期任务的关键挑战。
灵巧的手具有适应性和多功能性,可以在不依赖外部工具的情况下实现各种功能模式之间的平稳过渡。然而,灵巧手的高维动作空间带来了挑战。一些研究表明,灵巧的手可以用来操纵刚体。Chen [147] 提出一个综合系统,利用 RL 链接多个灵巧策略来实现复杂的任务目标。然而,他们的系统只处理刚体的操作。灵巧手在 DOM 的长期任务中的应用仍然是一个需要进一步研究的领域。
除了灵巧的双手,使用多种工具也是解决长期任务的一种有前途的方法。人类通过灵活使用工具,在执行复杂和长期操作任务方面表现出非凡的熟练程度。然而,机器人工具的使用仍然受到理解工具-目标交互困难的限制。Shi [11] 提出的 RoboCook 使用多种工具来操纵面团等弹塑性目标,以完成长期任务。然而,面团粘在工具上等故障经常发生。使用多种工具完成长期任务值得进一步研究。
子技能的组合泛化,对于长期任务来说是一项重大挑战。规划具有大搜索空间的技能序列,本质上很困难,但运动规划社区在制定规划骨架方面取得显著进展 [148],[149]。例如,Garrett [148] 提出两种方法。第一种方法涉及在搜索技能序列和执行低级优化之间交替进行。第二种方法对某些技能使用惰性占位符。后续研究还研究了使用预训练的 LLM 来发现技能序列 [150],[151]。子技能的组合泛化是一个具有挑战性的问题,需要进一步研究。
LLM 最近在各种自然语言处理 (NLP) 任务中取得了令人印象深刻的表现 [154], [155]。因此,人们对它们在机器人操作领域的潜在应用产生了浓厚的兴趣。如何在机器人操作中利用 LLM 丰富的内化知识?
最近利用 LLM 的研究在操作、规划、奖励函数设计和不确定性对齐的任务定义方面取得了初步进展。LLM 现在主要用于刚性目标操作。对于涉及 DOM 的更复杂任务,需要进一步研究。
任务定义
为了完成机器人操作任务,首先需要在语义层面定义任务。例如,折叠一件衣服是什么意思?现有方法倾向于设计一种配置作为任务目标。然而,手动指定 DO 的所有配置作为此类任务的目标是不切实际的。相反,需要一种方法来获取概念的语义知识,例如折叠或包裹,以便可以评估目标配置的目标状态的有效性。 LLM 表现出令人惊讶的泛化能力,为在语义层面实现 DOM 的任务定义提供一种可能的方法。
此外,最近的研究在使用 LLM 学习人类偏好方面取得进展。Wu 开发的系统 [156] 展示通过使用有限数量的示例与个人互动来学习人类偏好的能力。这一发现表明,机器人可以有效地利用基于语言的规划和感知以及 LLM 的总结能力来推断可广泛应用于未来交互的通用用户偏好。广义的用户偏好可能作为定义操作任务的先验知识。因此,利用 LLM 探索结合人类偏好的任务定义是值得的。
规划
将抽象的语言指令(例如折叠衬衫)与机器人动作相结合,是完成机器人操作任务的重要步骤。先前的研究已经利用词汇分析来解析指令 [157]–[159]。最近的研究利用语言模型将指令分解为一系列文字步骤 [150],[151],[160]。为了根据处理后的指令实现机器人与环境之间的物理交互,现有方法通常依赖于手动设计或预训练的基元(即技能)。例如,一系列原始动作(如抓取、滚动、推动、拉动、倾斜、关闭、打开)都是手动预先设计或训练的。这些基元可以由 LLM 或规划器调用来完成相应的任务。
Liang [161] 表明,LLM 表现出可用于底层控制的行为常识。尽管有一些有希望的迹象,但仍然需要手动设计运动基元。由于缺乏大规模机器人操作数据,这种对个人技能获取的依赖通常被认为是系统的一个重大瓶颈。如何利用 LLM 丰富的内化知识为机器人提供更细粒度的动作,而无需为每个单独的原语进行费力的数据收集或手动设计?这个研究方向具有巨大的价值。
奖励函数设计
RL 中的奖励设计具有挑战性,因为通过奖励函数指定期望的人类行为概念,可能很困难或需要大量专家论证。因此,出现了一个有趣的问题:可以使用自然语言界面设计奖励吗?Kwon [162] 探讨如何通过提示 LLM 来简化奖励设计。在这种方法中,用户提供包含所需行为的几个示例或描述的文本提示。该方法在 RL 框架内利用了此智体奖励功能。具体而言,用户在训练开始时指定一次提示。
在训练期间,LLM 根据提示描述的期望行为评估 RL 智体行为并输出相应的奖励信号。然后,RL 智体使用该奖励更新其行为。该框架的局限性在于 LLM 只能指定二元奖励。值得研究的是,在未来的研究中,如何将 LLM 为每个单词生成的似然值用作非二元奖励信号。类似的研究 [163]、[164] 也建议使用预训练的基础模型来为新的机器人操作任务生成奖励函数。然而,应该进行进一步的研究来探索涉及 DOM 的更复杂的任务。
语言指导机器人的不确定性对齐
大规模语言建模已经展示了广泛的能力,从逐步规划到常识推理,这些对机器人很有用。然而,这些模型仍然容易产生自信的幻觉预测。在这方面,Yu [165] 提出一个框架,用于测量和调整基于语言模型规划器中的不确定性。这个框架使机器人能够识别它们何时缺乏知识并在必要时寻求帮助。该框架任务完成保证的一个关键假设,是环境(目标)完全基于语言模型的文本输入。此外,它假设语言模型规划器提出的操作可以成功执行。未来的研究需要将不确定性纳入感知模块(例如,视觉语言模型)和底层行动策略(例如,语言条件下的affordance预测)。
可变形体操控在工业或日常生活中非常常见。可变形体操控在工业中的应用可以创造巨大的经济效益,在日常生活中的应用可以改善生活质量,尤其是对残疾人和老年人。机器人操控任务(例如食物处理、辅助穿衣或衣服折叠)需要解决可变形体的感知、建模和操控方面的开放问题。机器学习的最新进展解决了传统方法的一些局限性。结合分析方法和数据驱动方法有可能使机器人的操控能力接近人类。本文系统地回顾机器人操控可变形体的各种方法,为不同领域的研究人员和从业者提供快速参考。此外,本文还对该领域的开放研究领域提供见解,并指出有前途的未来研究,例如机器人操控的 LLM。

















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









