










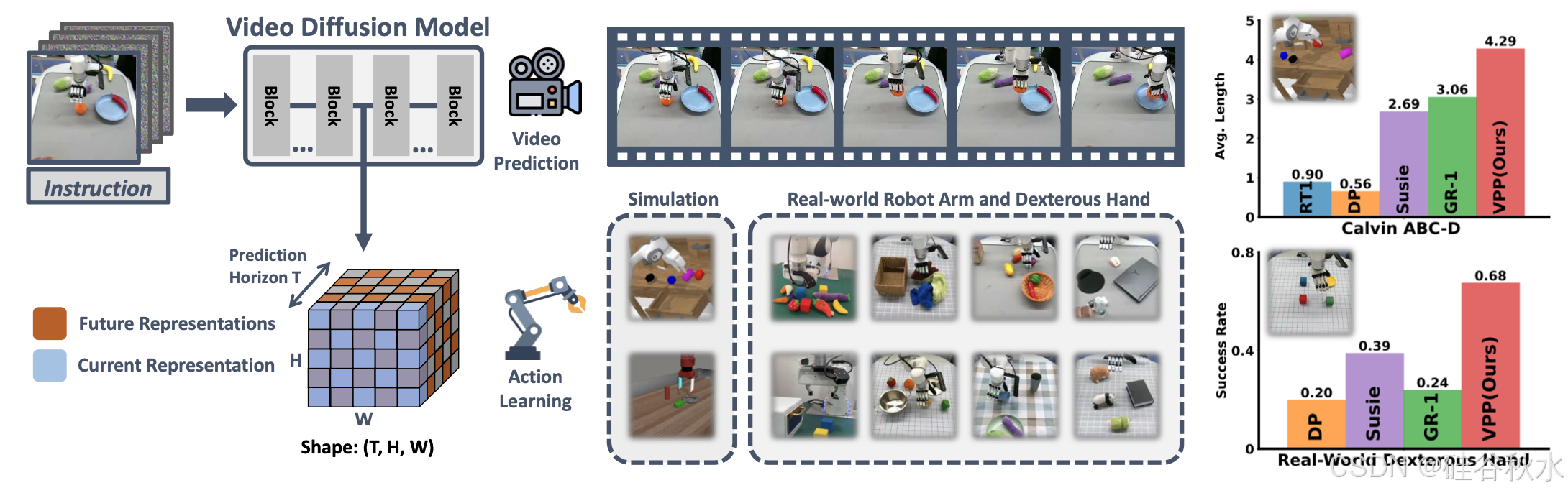
24年12月来自清华大学、UC Berkeley、上海AI实验室、上海姚期智研究院和北京星动纪元公司的论文“Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations”。
机器人技术的最新进展,集中于开发能够执行多项任务的通用策略。通常,这些策略利用预训练的视觉编码器从当前观察中捕获关键信息。然而,以前的视觉编码器采用双图像对比学习或单图像重建进行训练,无法完美地捕捉具体任务所必需的序列信息。最近,视频扩散模型 (VDM) 已展示出准确预测未来图像序列的能力,展现出对物理动态的良好理解。受 VDM 视觉预测能力的启发,假设它们本质上具有反映物理世界演变的视觉表征,称之为预测视觉表征。基于这一假设,提出视频预测策略(VPP),一种以 VDM 预测视觉表征为条件的通才机器人策略。为了进一步增强这些表现形式,结合不同的人类或机器人操作数据集,采用统一的视频生成训练目标。 VPP 在两个模拟和两个真实世界基准测试中始终优于现有方法。值得注意的是,与之前的最先进技术相比,它在 Calvin ABC-D 基准中实现 28.1% 的相对改进,并且使复杂的现实世界灵巧操作任务的成功率提高 28.8%。
如图所示:视频扩散模型中的视觉表征,明确地捕捉当前和预测的未来信息。基于这些表征构建的视频预测策略,在四个基准上实现持续的改进。
构建能够解决多项任务的通用机器人策略是一个活跃的研究领域[8,36]。构建这种通用策略的两个基本组成部分是动作网络和视觉编码器。其中一条研究路线专注于开发更先进的动作网络,例如采用视觉语言预训练模型 [7、8、28、31、58]、在不同的机器人数据集上从头开始训练 [49]、结合自回归 [ 8]或扩散架构[16],以及扩大动作网络[33]。另一项工作重点是通过对比学习[45]或图像重建[24],从以自我为中心的视频数据集[20, 21]中学习更有效的视觉表征[29, 41],以完成具身任务。
机器人的视觉表征学习。自监督学习(SSL)技术,例如对比式[13, 15]、基于蒸馏的[2, 11]和重构式[3, 24],在视觉表征学习方面取得重大进步。先前的研究表明,这些 SSL 技术使视觉编码器能够为具体化的 AI 任务产生有效的表示 [12、43、46、54、55],捕获高级语义和低级空间信息。值得注意的是,R3M [41]、vip [37]、VC-1 [38] 和 Voltron [29] 等方法通过人类操作视频数据集上的预训练方法,专门专注于具身任务 [20, 21]。然而,无论训练目标是什么,学习的视觉编码器主要侧重于从当前观察中提取相关信息,而不是明确预测未来状态。
具身控制任务的未来预测。现有研究还探索利用未来预测来增强策略学习[4, 5, 18, 51]。例如,SuSIE [5] 根据 InstructPix2Pix [9] 生成预测的未来关键帧,设定其控制策略,而 UniPi [18] 则学习两个生成帧之间的逆动力学。这些方法通常依赖单个未来预测步骤来确定动作,这可能无法准确捕捉物理动力学的复杂性。此外,它们通常在原始像素空间中操作,其中包含许多不相关的信息。 GR-1 [51]以自回归方式生成后续帧和动作。然而,它每次前向传递仅生成一张图像,并且其预测质量落后于基于扩散的方法。此外,GR-1 不利用预训练的视频基础模型。
扩散模型中的视觉表示。扩散模型在图像和视频生成任务中取得显著的成功[6,48]。扩散模型通常被训练为去噪器,可以根据噪声输入预测原始图像 [25]。研究表明,图像扩散模型也可以有效地用作视觉编码器[23, 34, 53],生成有意义的视觉表征。这些表示已经被证明对于辨别任务是线性可分的[53],对于语义分割非常有用[34],并且对于具身任务来说是多功能的[23]。然而,视频扩散模型中的表示能力尚未得到广泛探索。
VDM 中的视觉表征具有形状 (T, H, W),明确表示 1 个当前步骤和 (T-1) 个预测未来步骤,其中 H 和 W 对应于单个图像的高度和宽度表示。相比之下,以前的视觉编码器并没有明确地捕捉未来的表示。如图显示比较结果。基于这种区别,视频扩散模型中的这些潜变量称为“预测视觉表征”。
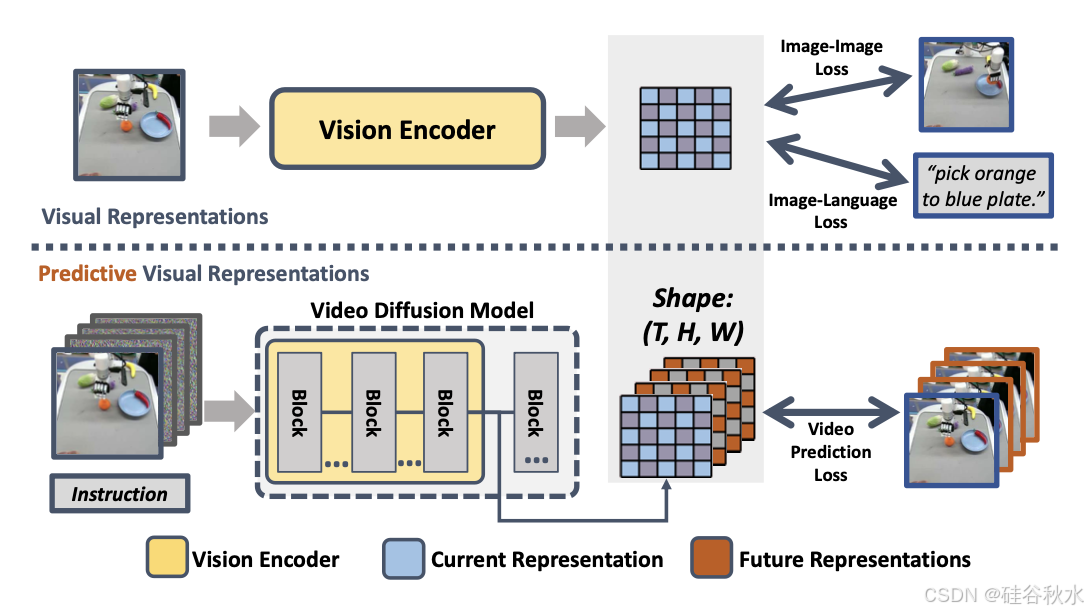
预测性视觉表征对于下游行动学习具有很高的信息量,因为它们捕捉目标(包括机器人本身)的运动。此外,可以使用一致的视频生成损失从互联网规模视频数据集和各种机器人数据集中学习预测能力,能够将物理知识从大规模互联网数据集迁移到特定的机器人系统。
如图所示视频预测策略的两阶段学习过程。首先,在不同的操作数据集上训练文本引导的视频预测(TVP)模型,以利用来自互联网数据中的物理知识;随后,设计网络来聚合 TVP 模型中的预测视觉表征并输出最终的机器人动作。
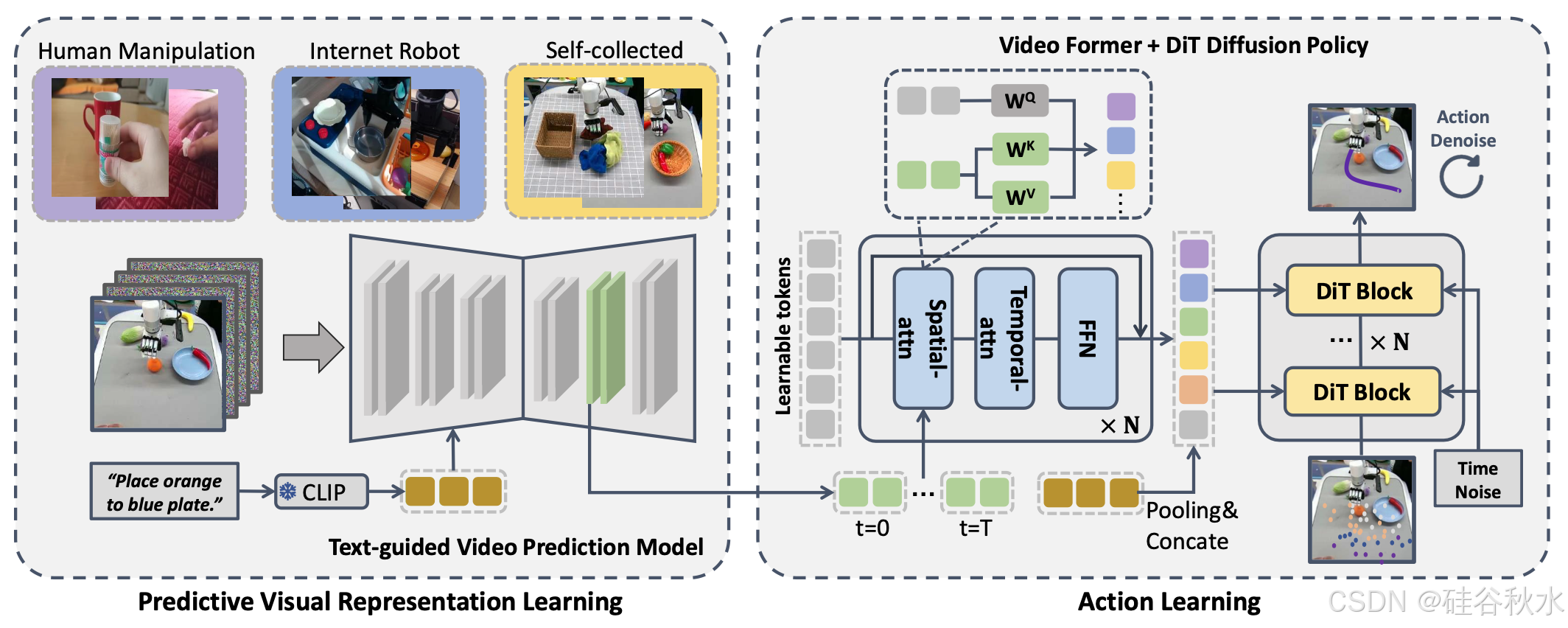
用于机器人操作的文本引导视频预测 (TVP) 模型
最近的进展集中在使用大量在线视频数据集训练通用视频生成模型,这些数据集编码有关物理世界动态的丰富先验知识。然而,这些模型并不是完全可控的,并且无法在机器人操作等专业领域产生最佳结果。为了解决这个问题,将通用视频生成模型微调为专门的“操作 TVP 模型”,以提高预测准确性。
选择具有 15 亿个参数的开源 SVD 模型 [6] 作为基础。开源 SVD 模型仅以初始帧图像 s/0 为条件,而不包含语言指令 l。利用交叉注意层对模型进行扩充,以纳入 CLIP [45] 语言特征 l/emb。此外,将输出视频分辨率调整为16×256×256,以优化训练和推理效率。尽管进行这些修改,仍保留原始预训练 SVD 框架的其他组件,以维持其核心功能。这个修改版本表示为V/θ。在这种设置中,初始观测 s/0 作为条件与每个预测帧按通道连接。然后使用一个扩散目标去训练模型 V/θ,即从噪声样本 x/t 重建数据集 D 中的完整视频序列 x/0 = s/0:T。
这个视频预测目标提供一个统一的界面,可直接生成未来的视觉序列,使 TVP 模型能够利用来自不同数据集的物理知识。其中包括基于互联网的人类操作数据集 D/H、公开的机器人操作数据 D/R,以及自收集的数据集 D/C。鉴于这些数据集的质量和规模各不相同,引入特定系数 λ 来适当平衡不同数据集类型的影响。
然后,在下游行动学习中冻结微调的操纵 TVP 模型。
基于预测视觉表征的动作学习
TVP 模型作为视觉编码器。在针对操作任务专门训练 TVP 模型后,它可以根据图像观察和指令准确预测未来序列。然而,对整个视频序列进行去噪非常耗时,并且可能导致开环控制问题,如[18]中讨论的那样。此外,原始像素格式的视频,通常包含过多、不相关的信息,会干扰有效的决策。
为了解决这些问题,主要将视频扩散模型用作“视觉编码器”而不是“去噪器”,仅执行单个前向步骤。虽然迈出的第一步没有产生清晰的视频,但仍然提供未来状态的粗略轨迹和宝贵的指导。如图所示。具体来说,将当前图像 s/0 与最终的噪声潜向量 q(x/t′|x/0)(通常是白噪声)连接起来,并将该组合输入到 TVP 模型中。然后,直接利用视频扩散模型 V/θ 第 m 层中的潜特征 F/m。
对于具有多个摄像机视图的机器人,例如第三视角和腕式摄像机,独立预测每个视图的未来,表示为 Fstatic/m,F^wrist/m。
视频生成。视频扩散模型中的这些预测表示仍然是高维的,因为它们表达一系列图像特征。为了有效地聚合空间、时间和多视图维度的表示,使用一个 Video Former 将这些信息合并为固定数量的 tokens。Video Former 初始化 T × L 个可学习tokens Q/[0:T,0:L],对预测表示中每个相应帧执行时空注意,然后是前馈层。
动作生成。 Video Former 将预测特征聚合成可学习的 token Q′′ 后,采用扩散策略作为动作头,基于 Q′′ 生成动作序列 a/0。使用交叉注意层将聚合表示 Q′′ 集成到扩散 Transformer 块中。扩散策略旨在从噪声动作 a/k 重建原始动作 a/0。此步骤可解释为学习去噪器 D/ψ 来近似噪声 ε 并最小化一个给定的损失函数。
在现实世界的灵巧手操作任务中,其中 a = {a/xyz, a/rot, a/finger},使用系数来平衡末端执行器动作、旋转动作和手指动作造成的损失。
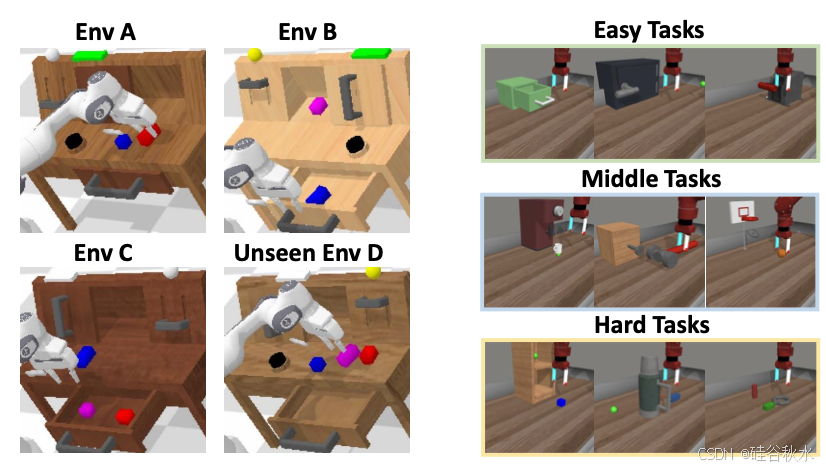
考虑 CALVIN [39] 和 MetaWorld [57] 模拟环境。 CALVIN 是一个具有挑战性的基准,专注于评估机器人策略对长期操作的指令遵循能力。如图左侧所示,它包含四个环境,记为 ABCD。利用最具挑战性的 ABC→D 设置,其中机器人使用从环境 ABC 收集的标准数据集进行训练,并在未见过环境 D 中进行测试。MetaWorld 以 Sawyer 机器人为特色,可执行各种操作任务,并广泛用于评估精度和灵活性机器人政策。如图右侧所示,它包含 50 个任务,操作目标丰富,难度各异[46]。使用官方 Oracle 策略作为训练数据集,为每个任务收集 50 条轨迹。
首先在各种数据集上训练一个可控的文本引导视频预测模型,用于操作域。实验包括来自 Something-Something-V2 数据集 [20] 的 193,690 条人类操作轨迹和来自互联网的 179,074 条高质量轨迹机器人操作数据集[7, 17, 19, 28, 40, 42]。此阶段还包括下游任务数据集,例如官方的Calvin ABC数据集和Metaworld数据集,以及在现实世界机器人上自行收集的数据集。考虑到不同机器人数据集的规模和质量各不相同,应用与[49]中方法类似的不同采样概率。视频模型训练过程在 8 块 NVIDIA A100 GPU上需要两天时间。每个机器人的后续动作学习在四块 NVIDIA A100 GPU 上大约需要 6-12 小时。
为了增强机器人的控制频率,将大部分参数分配给视频的前部,该部分约有 300M 个参数,而扩散策略头仅包含 20M 个参数。策略执行涉及运行 VDM 和 Video Former 前向一步,轻量级扩散Transformer策略根据可学习的tokens 对 10 步的动作进行去噪。这种设计能够在配备 NVIDIA RTX-4090 GPU 的本地机器上以 7-10 Hz 的速度运行整个视频预测策略过程。按照原始扩散策略论文[16],还在一个 VPP 前向步骤中输出 6∼10 个动作步骤,进一步提高控制频率。
除了模拟实验,进一步在两个实际硬件平台上验证视频预测策略:
• Franka Panda 机械臂。收集拾取、放置、按下、布线、打开和关闭等 6 个类别 30 多个任务的 2000 条轨迹。
• 配有 12 自由度 Xhand 灵巧手的机器臂 Xarm。在灵巧手平台采集取物、放置、杯体直立、移动、堆垛、传递、按压、拔塞、打开、关闭、倒出、吸吮、敲击等 13 个类别 100+ 任务的 3000 条轨迹。值得注意的是,还成功地解决了具有挑战性的工具使用任务,例如在化学实验中使用锤子敲钉子、抓取电钻和使用移液器(pipette)转移液体。
采用与模拟实验相同的文本引导视频预测 (TVP) 模型,在互联网数据集和自己收集的真实世界数据上进行训练。分别为 Franka Panda 和 Xhand 灵巧手训练多任务通才策略,以解决该领域的所有任务。如图显示硬件平台和一些选定任务的可视化效果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









