










25年3月来自上海交大和重庆长安汽车公司的论文“DriveGen: Towards Infinite Diverse Traffic Scenarios with Large Models”。
微观交通模拟已成为自动驾驶训练和测试的重要工具。尽管近期数据驱动的方法推进逼真行为的生成,但它们的学习仍然主要依赖于单一的真实世界数据集,这限制其多样性,从而阻碍下游算法的优化。本文提出 DriveGen,一个交通模拟框架,它拥有大模型,可以生成更多样化的交通数据,并支持进一步的定制化设计。DriveGen 包含两个内部阶段:初始化阶段使用大语言模型和检索技术生成地图和车辆资产;部署阶段从视觉语言模型和专门设计的扩散规划器中输出具有选定航点目标的轨迹。通过这两个阶段的过程,DriveGen 充分利用大模型对驾驶行为的高级认知和推理能力,在保持高度逼真度的同时,获得超越数据集的更大多样性。为了支持有效的下游优化,还开发了 DriveGen-CS,这是一个自动极端情况生成流程,它将驾驶算法的故障作为大模型的额外提示知识,而无需重新训练或微调。实验表明,生成的场景和极端情况相比最先进的基线模型具有更优的性能。下游实验进一步验证 DriveGen 的合成流量能够更好地优化典型驾驶算法的性能,从而证明框架的有效性。
DriveGen 是一个微观交通模拟框架,它利用最新基础模型的生成能力来生成多样化且逼真的交通场景。如图展示整个流程,它由两个内部阶段组成:场景初始化和场景展开,而 DriveGen-CS 则在展开阶段双竖线右侧进行进一步说明。
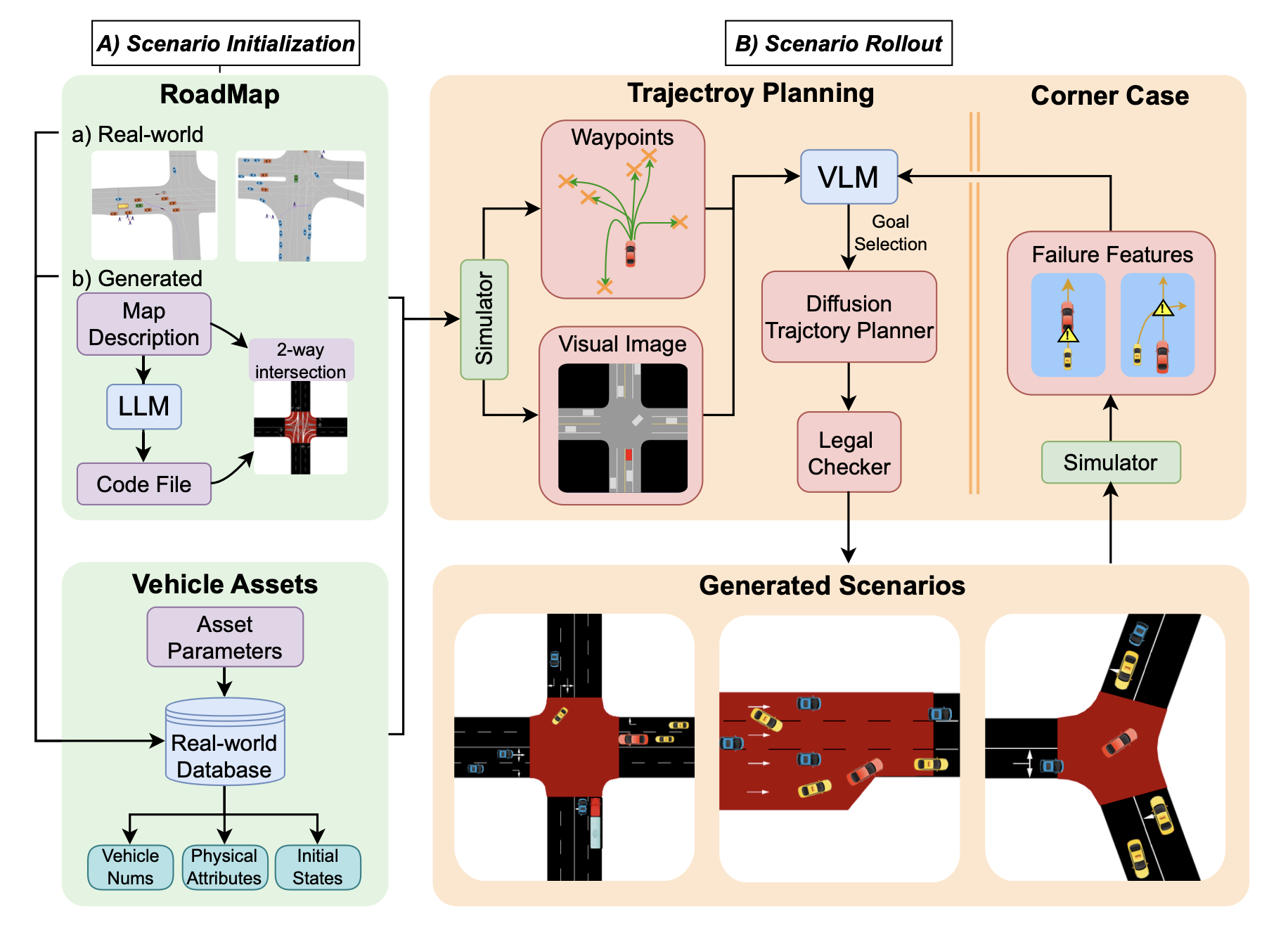
一个完整的微观交通场景由静态和动态元素组成。静态元素包括语义地图 M_s 和 N 个交通参与者的属性 P = {p_0,··· ,p_N}。车辆的属性包括其类型、三维尺寸和模拟第一帧的初始状态(位置、速度、航向)。动态元素包括地图中的交通信号 M_d 和车辆轨迹 T = {τ0,τ1,··· ,τN}。我们将交通的总持续时间定义为 T_s。第 i 辆车的轨迹由其在所有时间步长 τi = {si_0, si_1, ···, si_T_s} 中的状态序列组成。用场景级坐标来实现轨迹的一致表示。假设交通信号 M_d 由模拟器控制,则交通场景 S 的关键组成部分可以描述为 S = {M_s, P, T}。然后可以通过在生成的场景中替换目标车辆来训练和评估自动驾驶算法。
在初始化阶段,描述语义地图 M_s 和车辆资产 P 的生成过程。
路线图生成。大多数先前的数据驱动方法仅对驾驶行为进行建模,而忽略对语义地图的研究。当研究人员想要优化特定道路结构下的策略性能时,从数据集中筛选出此类地图通常非常耗时(地图没有标签),而且数量也不足。DriveGen 通过精心设计的知识提示,即使对于非专业人士也能实现地图定制,并且生成的地图可以直接加载到流行的模拟器中。
为此,选择流行的 XML 格式 SUMO 网络定义来构建地图。地图代码由三部分组成:Lane 表示车道;Junction 表示车道之间的连接;Connection 定义车辆的合法路线。为 LLM 配备基于规则的知识先验和典型示例(例如交叉路口、环岛、高速公路),使其能够基于文本描述以高成功率生成地图文件。地图还可以通过人工反馈进行 LLM 的完善。例如,修改匝道与主干道的汇合位置。该框架也接受真实世界地图。
车辆资产生成。静态地图是该方法进行条件设定的基础,随后可在交通场景中放置动态车辆。生成过程按顺序定义以下内容:车辆数量、车辆的物理属性以及车辆的初始状态 s_0。在这里,从真实世界数据集中收集车辆信息以构建数据库。确定车辆数量和类型后,从数据库中检索相应的车辆。第一辆用作目标车辆,其余用作社交车辆。为了确定初始状态,首先根据地图将目标车辆随机放置在可行区域内,并赋予其沿车道的正确航向和初始速度。然后将社交车辆放置在目标车辆周围,并以相似的速度行驶,以创建丰富的交互。
给定地图和车辆的初始状态,利用模拟器和 VLM 模拟的图像信息生成多样化且逼真的轨迹,从而构建高质量的场景。直接查询低级连续轨迹会导致性能不佳,因为它无法充分利用 LM 的高级认知和推理能力。相反,让 VLM 基于结构良好的信息做出离散决策。具体来说,实施一种基于规则的路径检索方法,该方法处理模拟器生成的航点。它首先搜索所有可行路线,然后考虑车辆的初始速度和航向来采样合理的目标。这些候选路线在以车辆为中心的 200m×200m 鸟瞰图中用数字标记,该图像显示周围的道路结构和车辆。然后,将图像与场景描述一起发送到 VLM。在给出提示引导的情况下,VLM 会为每辆车输出按可能性排序的合理目标 s_T_s。有关详细示例,参见下图。利用从大模型中获得的对驾驶行为高级理解,这种方法在现实中远远优于随机选择,并确保通过不同路线下的各种航点实现更大的多样性。

为了填充与人类驾驶员相似的逼真轨迹,实现一种数据驱动扩散轨迹规划器,以捕捉人类的驾驶风格。扩散模型学习 T_d 步骤的逆向去噪过程,从纯高斯噪声 τ_T_d 中恢复原始轨迹分布 τ_0。详细网络如图所示。在 Transformer 的自注意模块和前馈网络(FFN)之间添加一个融合模块,该模块通过深度仿射变换将扩散噪声嵌入 X_t_d 与地图信息 m 和扩散时间步长 t_d 结合起来。
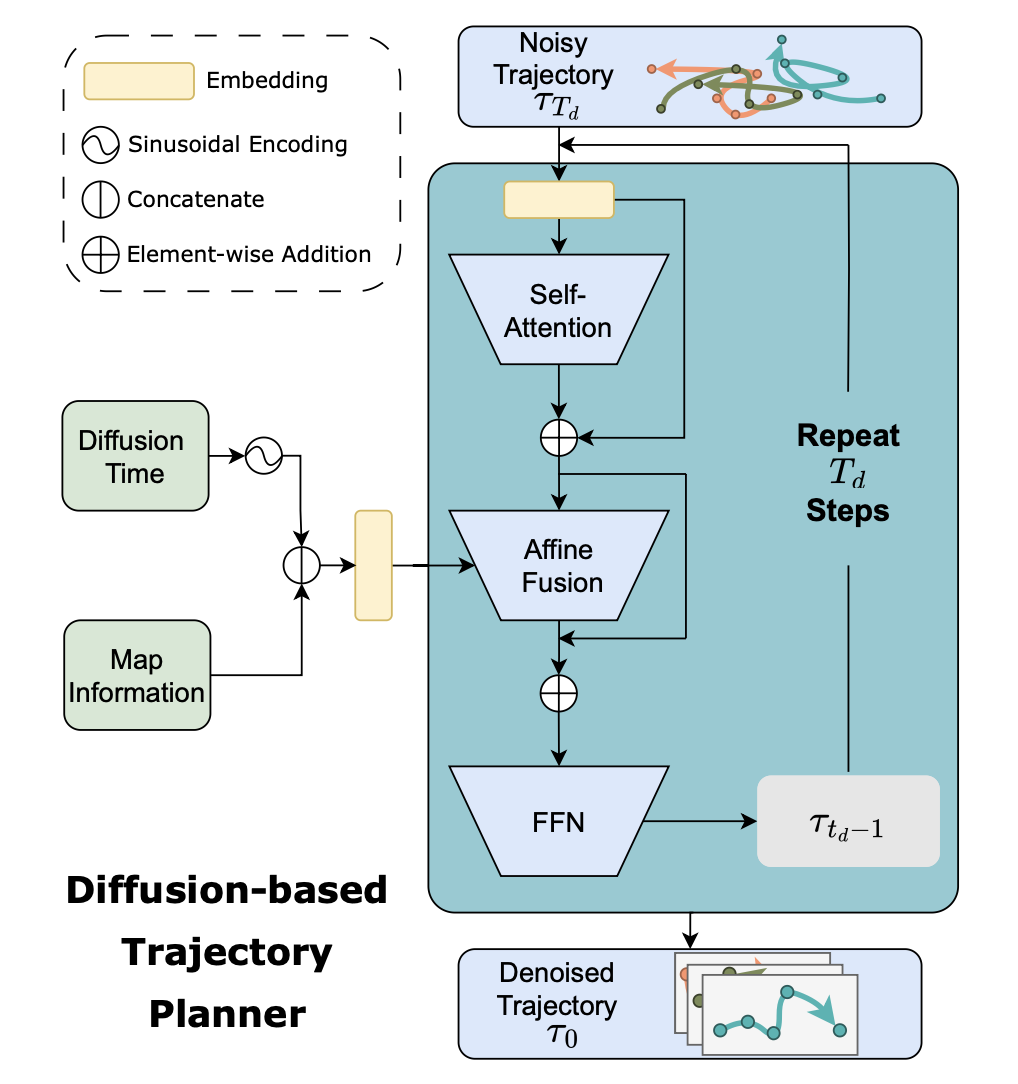
这种结合使模型能够捕捉时间和多模态驾驶行为特征,从而恢复真实的轨迹。
按照与车辆资产相同的顺序生成轨迹。每条轨迹都会经过合法性检查器检查,以判断其是否符合交通规则、是否避免与其他车辆碰撞,以及是否在动态约束条件下可行。不合格的轨迹将由规划器重新生成。最终,所有轨迹的集合和地图构成完整的交通场景。
为了支持高效的算法优化,本文进一步提出 DriveGen-CS,它是 DriveGen 与极端情况生成技术的结合。该范式利用目标算法的碰撞场景作为语言模型(LM)的额外领域知识,从而为目标算法选择更具威胁性的社会车辆轨迹。
处理失败示例。如上所述,极端情况对自动驾驶汽车的安全性构成重大挑战。因此,驾驶算法的碰撞场景是最佳的 极端情况。首先,通过评估 DriveGen 生成的场景(其中算法控制的目标车辆与一个社会车辆发生碰撞)来收集碰撞场景。然后,提取碰撞发生时的相对速度、航向和驾驶行为作为特征。通过统计,可以找到碰撞概率最高的特征值,并将相应的信息和视觉轨迹碰撞图像作为额外的知识提示发送到 VLM 进行生成。
极端情况生成。与 DriveGen 不同的是,对于社会车辆,目标车辆(由算法控制)的初始位置需要在给定的 RGB 图像中额外识别,并且要求 VLM 根据给定的知识选择更有可能使目标算法失败的目标。由于候选航点遵循交通规则,且轨迹规划器根据人工分布进行学习,因此生成的极端案例能够保持真实性和合理性。
使用 Claude-3-opus [41] 作为 LLM 生成地图代码文件,并使用 GPT-4-turbo [55] 作为 VLM 为车辆选择合适的目标。对于扩散轨迹规划器,用 4 层 CNN 将 256×256 以车辆为中心的栅格化地图编码为地图信息。对于主干网络,克隆一个嵌入维度为 256 且有 4 个 head 的 3 层 Transformer,然后插入一个带有两个 2 层 MLP 的仿射融合块,如上图所示。以 1e-4 的学习率、32 的批次大小和 100 的扩散模型步长,对模型进行 90 个 epoch 的训练。

















 3857
3857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









