










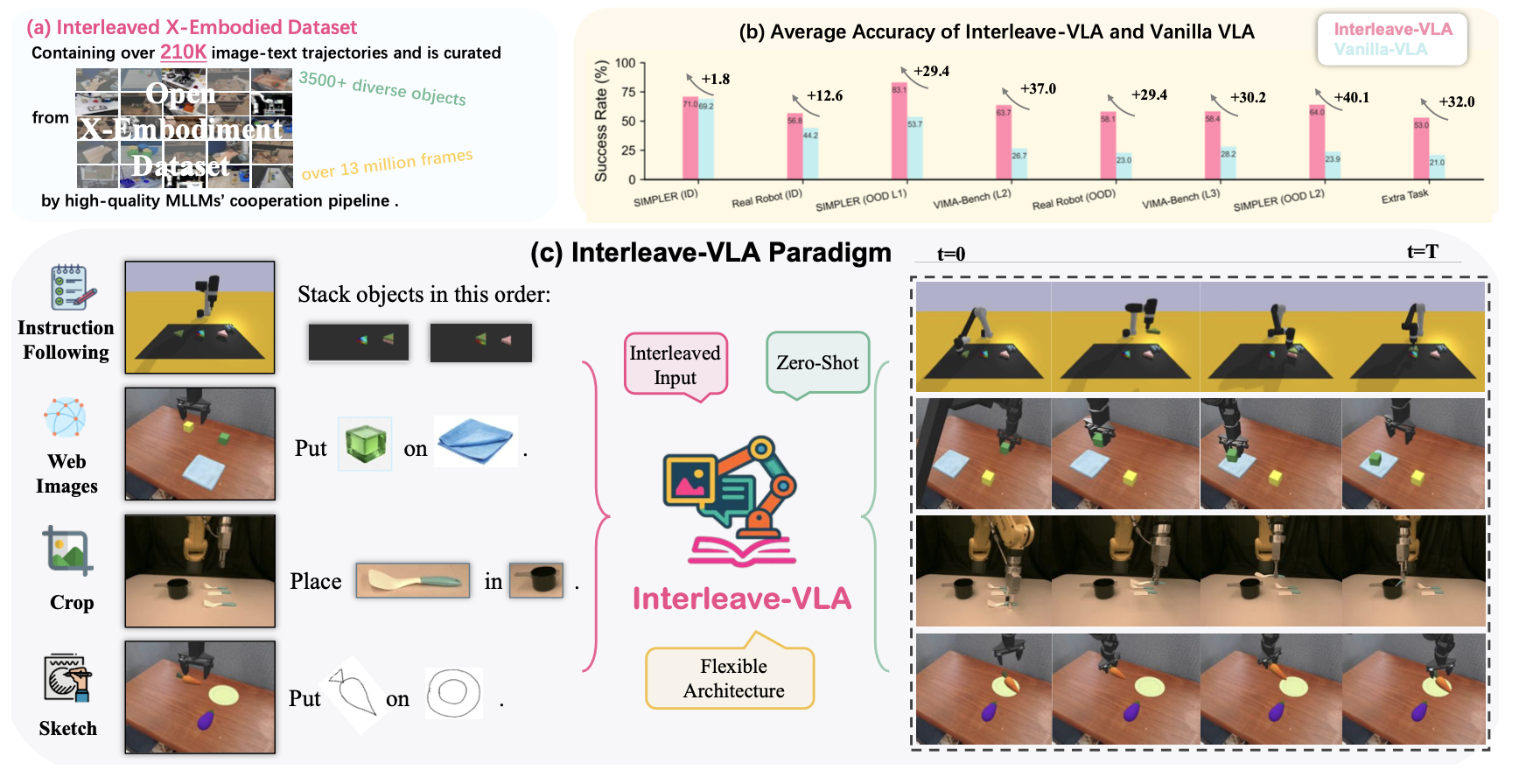
25年5月来自上海交大、UC Berkeley 和 UNC Chapel Hill 的论文“Interleave-VLA: Enhancing Robot Manipulation with Interleaved Image-Text Instructions”。
视觉-语言-动作 (VLA) 模型已展现出在物理世界中实现通用机器人操控的巨大潜力。然而,现有模型受限于机器人观测和纯文本指令,缺乏数字世界中基础模型最新进展所带来的交错多模态指令的灵活性。本文提出 Interleave-VLA,这是一个能够理解交错图像文本指令并直接在物理世界中生成连续动作序列的框架。它提供一种灵活的、与模型无关的范式,只需对最先进的 VLA 模型进行少量修改并具有强大的零样本泛化能力即可对其进行扩展。实现 Interleave-VLA 的一个关键挑战是缺乏大规模交错具身数据集。为了弥补这一差距,本文开发一个自动化流程,将 Open X-Embodiment 中真实世界数据集中的纯文本指令转换为交错的图像文本指令,从而生成第一个包含 210k 个episodes的大规模真实世界交错具身数据集。通过对模拟基准和真实机器人实验的全面评估,证明 Interleave-VLA 具有显著的优势:1)与最先进的基线相比,它将对未见过目标的域外泛化能力提高了 2 到 3 倍,2)支持灵活的任务界面,3)以零样本方式处理各种用户提供的图像指令,例如手绘草图。
大语言模型 (LLM) [1, 2, 3, 4] 和视觉-语言模型 (VLM) [5, 6, 7, 8, 9] 的巨大成功建立了数字世界中的基础模型范式,这些模型能够在广泛的任务和领域中推广。受到这一进步的启发,机器人社区正在积极开发机器人基础模型 [10, 11, 12, 13, 14, 15],以便将类似的泛化能力带入物理世界,以应对从未见过的任务和场景。然而,尽管数字基础模型中交错多模态输入已被证明是有效的,但当今大多数机器人策略仍然只接受观察图像和基于文本的指令,落后于能够无缝处理混合模态序列并跨灵活任务界面进行推广的 VLM。例如,用户可能希望机器人在指向不规则形状或颜色独特的目标的同时“捡起看起来像这样的目标”。用语言描述此类目标可能繁琐或含糊不清。相比之下,交错式图像文本指令提供了一种更直观、更精确、更通用的方式来传达此类目标。
VIMA [16] 在仿真中首次探索了机器人操作的交错指令概念,并引入 VIMA-Bench 来研究用于二维目标姿态估计的视觉-语言规划。由于采用了高级二维动作空间,VIMA 主要关注界面统一,而没有探索交错指令的更多优势,例如提升泛化能力或通过低级机器人动作实现现实世界的适用性。因此,由于缺乏现实世界的数据集和能够处理此类输入的策略,这种范式的实用价值仍未得到充分探索,如图所示。
为了开发一种能够对现实世界中交错的图像-文本指令采取行动的通用实用机器人策略,一种直接的解决方案是以 VLA [11, 12, 17, 10, 13, 18] 模型为基础,该模型通过结合动作理解和生成功能自然地扩展了 VLM,使其非常适合机器人任务。然而,现有的 VLA [10, 11, 13] 主要使用纯文本指令进行训练。这限制了它们从多模态指令信号中获益的能力,而多模态指令信号已被证明可以增强视觉语言学习的泛化能力 [1, 18]。这种限制不仅降低了指令的灵活性,也阻止了这些模型利用交错多模态信号所提供的更丰富的语义和更好的基础。
交错视觉-语言模型。在数字领域,视觉-语言模型的最新进展已从处理简单的图像-文本对 [7, 19, 20, 21] 发展到处理任意交错的图像和文本序列 [22, 5, 6, 23, 8, 24, 9, 25]。这种交错格式使模型能够利用大规模多模态网络语料库(例如新闻文章和博客),其中图像和文本自然地以混合序列出现。此类模型已展现出更高的灵活性和泛化能力,能够跨不同任务和模态迁移 [23]。尽管在数字世界中取得了这些成功,但现实世界中的机器人基础模型尚未充分利用交错图像-文本指令的优势。
视觉-语言-动作模型。视觉-语言-动作 (VLA) 模型通过启用基于视觉观察和语言指令的策略,推动了机器人操控的进步 [11, 12, 17, 10, 13, 18, 26, 27]。之前的大多数 VLA 模型使用纯文本指令处理单个 [11] 或多个 [10, 13] 观察图像,其中一些模型正在探索其他模式,例如 3D [28] 和音频 [29]。
为了突破限制,本文提出一个名为 Interleave-VLA 的范式,这是一个简单且与模型无关的扩展,使 VLA 模型能够处理和推理交错的图像文本指令。
高质量的图像-文本交错数据集对于训练 Interleave-VLA 至关重要。为了弥补机器人操作中图像-文本交错数据集的不足,本文开发了一个流程,可以从现有数据集自动构建交错指令。该流程能够从真实世界数据集 Open X-Embodiment [12] 自动且准确地生成交错指令。生成的交错数据集包含超过 21 万个场景和 1300 万帧,使其成为一个大规模的真实世界交错具身数据集。这样能够使用真实世界的交互数据和多种视觉指令类型来训练 Interleave-VLA。
如图所示:a) Interleaved X-Embodiment 数据集具有从真实世界机器人演示中自动生成的多样化、高质量、以目标为中心的图像。b) 与模拟和真实机器人实验中的纯文本 VLA 模型相比,Interleave-VLA 实现 2-3 倍更强的域外泛化。c) 它可以通过用户提供的、网络图像和手绘草图实现灵活的零样本指令跟踪,从而实现实用且直观的人机交互。
数字基础模型 [22, 30] 可以处理以任意交错的图像、视频帧和文本作为输入的多模态提示,并输出文本作为输出。对于机器人基础模型,这种范式可以自然延伸:模型接收多模态提示,并在机器人的动作空间中输出一个动作。例如:
常规: 将 [微波炉旁的蓝色勺子] 放入 [毛巾上的银锅] 中。
交错: 将 [image1] 放入 [image2] 中。
其中 是观察图像,[image1] 和 [image2] 分别代表目标物体和目的地。
Interleave-VLA 框架基于观测值 o_t = (I_t, I, q) 对动作分布 P(A_t|o_t) 进行建模。其中,I_t 为观测图像,q 为机器人的本体感受状态,I 为图文交错指令。指令 I 是一个混合文本片段 l_i 和图像 I_i 的序列,即 I = (l_1, I_1, l_2, I_2, . . .)。现有的使用文本指令的 VLA 是一种特殊情况,其中 I = (l) 仅包含单个文本片段。
Interleave-VLA 是对现有 VLA 模型的一种简单而有效的改编。它修改了输入格式以接受交错的图像和文本tokens,而无需更改核心模型架构。改编两个最先进的视觉-语言-动作 (VLA) 模型来演示这种方法。对于 OpenVLA [11],用 InternVL2.5 [24] 替换原有的 Prismatic [31] VLM 主干,后者原生支持图文交错输入。对于 π_0 [13],保留原有架构,仅调整输入流水线以处理交错tokens。值得注意的是,即使底层 Paligemma [32] VLM 未使用交错数据进行训练,Interleave-π_0 仍然可以训练并有效处理交错指令。这种与模型无关的调整只需对架构进行少量修改,并显著增强了基础模型的零样本泛化能力,正如实验所示。
正如 OpenVLA [11] 和 π0 [13] 所指出的,大规模预训练数据集对于视觉-语言-动作 (VLA) 模型学习动作和进行泛化至关重要,Interleave-VLA 也是如此。然而,目前大多数真实数据集仅提供基于文本的指令,因此不支持直接训练 interleave-VLA 模型。因此,设计一个统一的流水线,用于自动重新标记和生成跨不同数据集的交错数据。
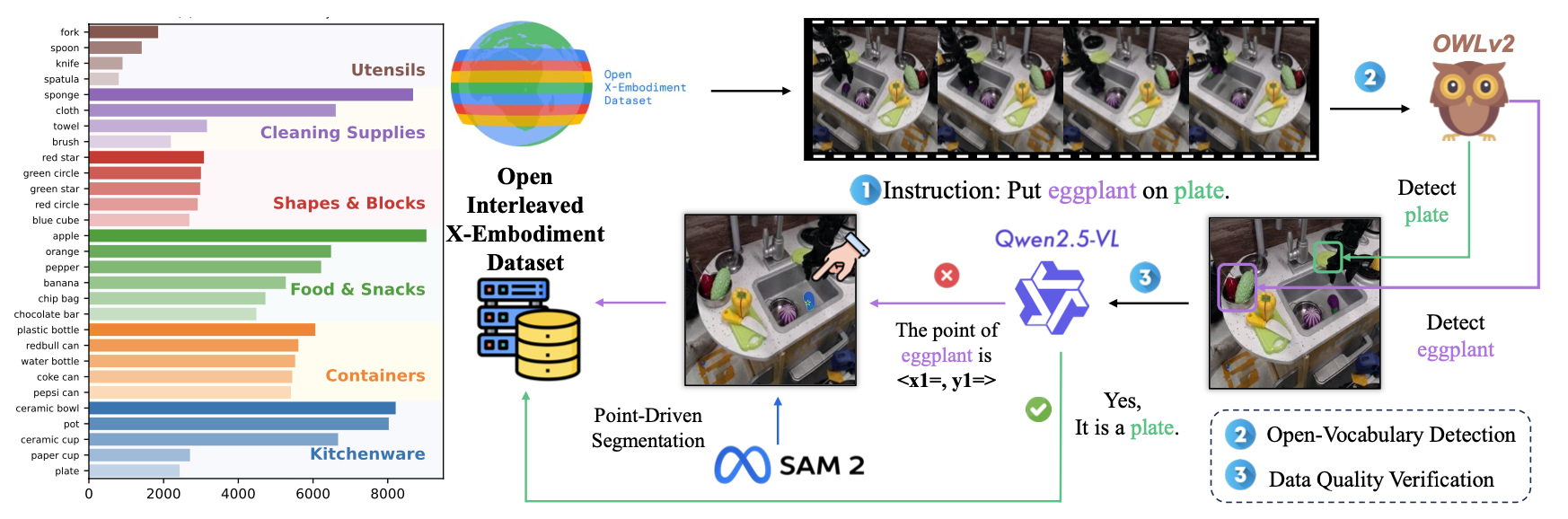
整体数据集生成流水线包含三个主要步骤:指令解析、开放词汇检测和数据质量验证,如上图所示。首先,对于指令解析,使用 Qwen2.5 [33] 从语言指令中提取关键目标。与 SPaCy [34] 等基于规则的 NLP 工具相比,LLM 提示更加健壮,并且能够适应不同的指令格式。它还可以对复杂或冗长的指令进行简洁的概括,就像 Shah [35] 的数据集中提到的那样。其次,对于开放词汇检测,用最先进的开放词汇检测器 OWLv2 [36],根据解析后的指令关键词从轨迹帧中定位和裁剪目标物体,在大多数情况下可以达到 99% 以上的准确率。最后,针对 OWLv2 无法胜任的复杂情况引入数据质量验证:Qwen2.5-VL [5] 会验证检测的目标,并在需要时提供关键点,以便使用 Segment Anything(SAM)[37] 进行更精确的分割。这种组合方法将挑战性目标(例如茄子)的裁剪准确率从不到 50% 提高到 95%,从而确保为下游任务提供高质量的交错数据。
将数据集生成流程应用于 Open X-Embodiment [12] 中的 11 个数据集:RT-1 [17]、Berkeley Autolab UR5 [38]、IAMLab CMU Pickup Insert [39]、Stanford Hydra [40]、UTAustin Sirius [41]、Bridge [42]、Jaco Play [43]、UCSD Kitchen [44]、BC-Z [45]、Langugae Table [46] 和 UTAustin Mutex [35],从而形成现实世界中一个大规模交叉化身数据集。该数据集包含 21 万个事件和 1300 万帧图像,涵盖 3500 个独特目标和各种任务类型。
实验环境。在基于模拟器的评估和真实机器人评估中,对交错式 VLA 与纯文本 VLA 进行全面的实验。使用 SIMPLER [47] 和 VIMA-Bench [16] 作为模拟环境。SIMPLER 旨在紧密贴合现实世界任务,弥合真实与模拟之间的差距。调整 SIMPLER 以支持交错式图像文本指令,从而能够在真实环境中评估 Interleave-VLA 模型的性能。交错式指令由流水线自动生成。VIMA-Bench 旨在实验交错式指令,其主要功能是评估基于规划器的任务,其中模型的评估基于目标识别和多任务理解。还在配备 SMC 夹持器的 FANUC LRMate 200iD/7L 机械臂上进行真实机器人实验。
如图所示:左图:SIMPLER 中泛化设置。(a) 视觉泛化:未见过的环境、桌布和光照条件。(b) 使用已知类别中的新目标进行语义泛化。© 使用训练期间未见过全新类别中的目标进行语义泛化。右图:真实世界泛化实验。在 FANUC LRMate 200iD/7L 机械臂上进行真实世界中的域内和域外设置。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









