










25年5月来自 JD 集团和北京交通大学的论文“Object-Focus Actor for Data-efficient Robot Generalization Dexterous Manipulation”。
机器人操作学习从人类演示中学习提供了一种快速掌握技能的方法,但通常缺乏跨不同场景和物体位置的泛化能力。这一局限性阻碍了其在现实世界中的应用,尤其是在需要灵巧操作的复杂任务中。视觉-语言-动作 (VLA) 范式利用大规模数据来增强泛化能力。然而,由于数据稀缺,VLA 的性能仍然有限。本研究引入目标-焦点执行器 (OFA),这是一种新颖且数据高效的广义灵巧操作方法。OFA 利用在灵巧操作任务中观察的一致末端轨迹,从而实现高效的策略训练。该方法采用分层流程:目标感知和姿态估计、操作前姿态到达以及 OFA 策略执行。此流程确保即使在不同的背景和位置布局下,操作也能保持专注和高效。在七项任务中进行的全面现实世界实验表明,OFA 在位置和背景泛化测试中均显著优于基线方法。值得注意的是,OFA 仅通过 10 次演示就实现了强大的性能,突显了其数据效率。
通常,需要使用灵巧机械手的操作被称为灵巧操作 [13]。尽管近期有大量文献研究灵巧操作的遥操作和模仿学习 [14, 15, 16, 17],但很少有文献探讨灵巧操作的泛化能力。
目标操控的泛化要求机器人手臂以任意的初始姿态,在机器人运动学和动力学极限范围内,触及位于随机位置的物体。一旦问题定义明确,一个直观的思路是定位被操控的目标,然后生成可用的抓取姿态,并调用机械臂的轨迹规划算法完成抓取。在使用夹持器 [18, 19] 时,该流程已得到充分探索,但要用灵巧手复制该流程则颇具挑战性。由于利用多根手指生成合适的抓取姿势比使用机械手更为复杂,近期的大多数研究[20, 21]都试图在模拟环境中解决这个问题,而没有迁移到实际实验中。
以目标为中心的机器人操控方法。目标视觉表征广泛应用于机器人操控,通过预训练的视觉模型来提高操控成功率和泛化能力 [27, 28, 29, 30, 31]。这些研究通常提取目标掩码 [27, 29]、六维姿态 [32] 和关键点 [28, 30, 33],为策略学习提供目标先验信息,但这可能会导致策略本身无法处理复杂的图像观察,尤其是在实际场景中。GROOT [27] 利用目标分割提取掩码,主要是为了提高在变化背景下操控的成功率。ORIGIN [28] 设计一种基于图以目标为中心的表征方法,该方法可以进一步推广到各种目标位置布局。然而,这些研究仅进行图像处理以聚焦于待操控的目标,而没有将控制策略转变为以目标为中心的范式。
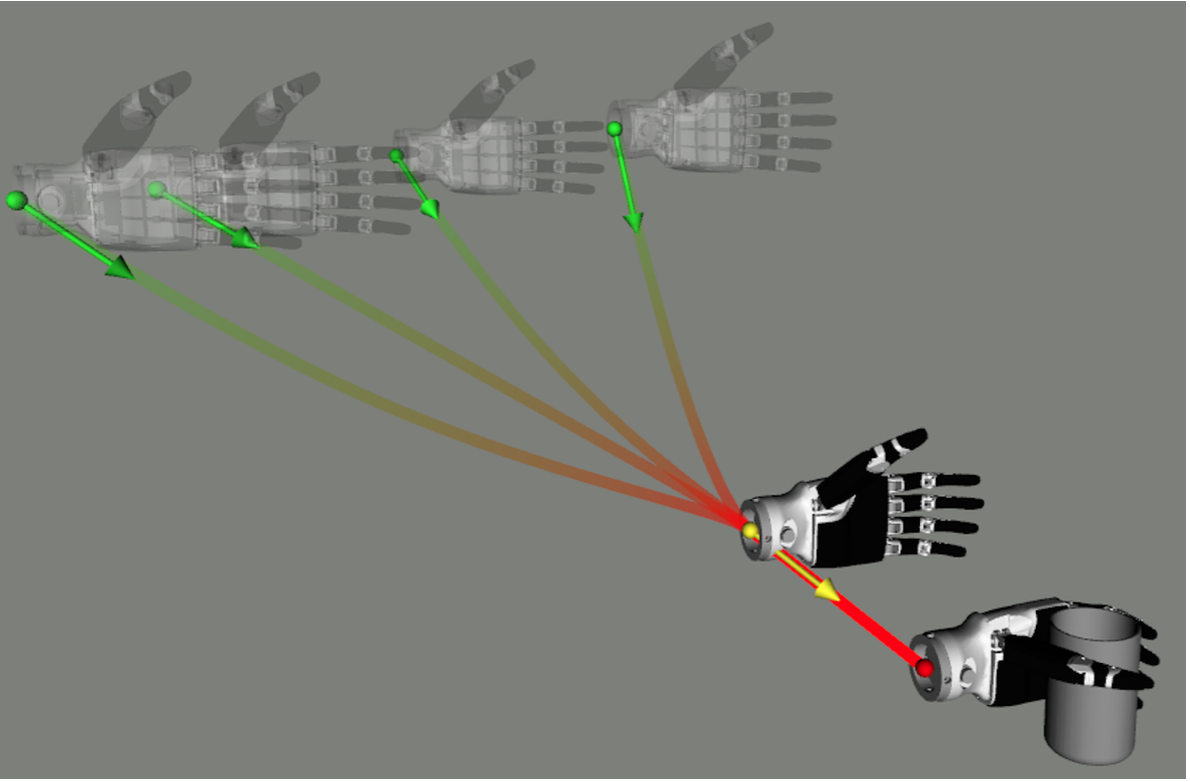
本研究 OFA(Object-Focus Actor),用于泛化灵巧操作,而无需大规模数据。其原理是,当多次执行一个灵巧操作时,无论待操作目标的位置如何,最终的轨迹都非常相似。如图所示:使用机械手左手抓取杯子时,由于初始相对位置的变化,机械手的起始轨迹也随之变化(图中的绿点表示不同的初始相对位置)。当机械手足够接近物体时,轨迹收敛到一个均匀的位姿,称为预操作位姿,此后的最终轨迹相同。在此过程中,不仅手腕运动保持一致,而且每个手指的轨迹也保持一致。这种一致的轨迹称为目标-焦点末端轨迹。它在每个特定任务中都不会有太大的变化。
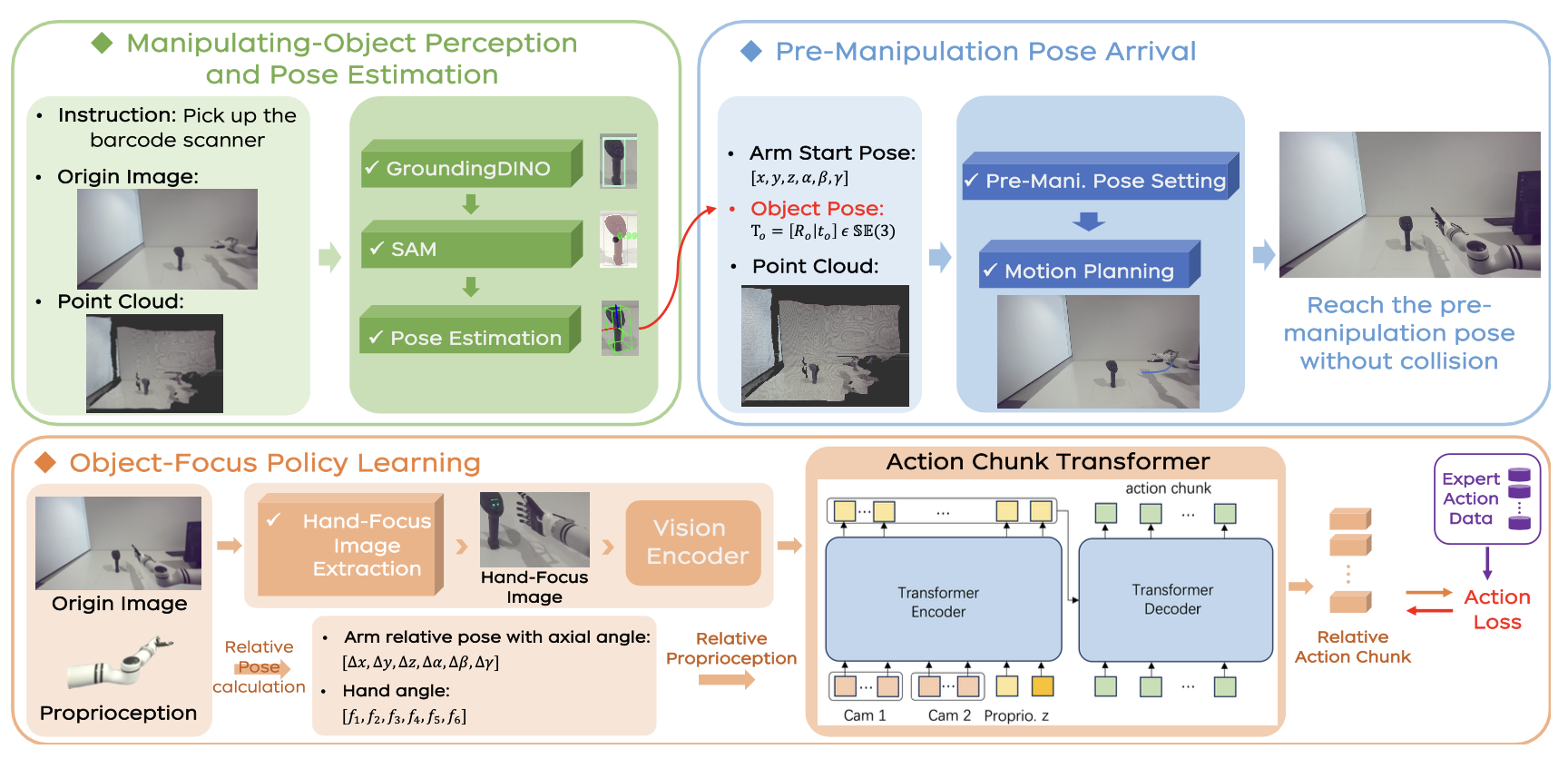
OFA 的总体设计
如图所示,所提出的 OFA 的总体结构主要包含以下三个模块:1)操作目标感知与姿态估计;2)预操作姿态到达;3)目标-焦点策略学习。具体而言,OFA 首先根据用户指令识别待操作目标的名称,例如杯子。随后,利用原始图像和点云数据,通过感知和姿态估计算法模块(例如 GroundingDINO [36]、SAM [37]、FoundationPose [22] 等)提取操作目标的姿态。基于该姿态,设置机械手的预操作姿态,并采用运动规划算法(例如 cuRobo [23])引导机械手到达预操作姿态。最后,进行目标-焦点策略学习,使机械手能够学习并执行最终的灵巧操作,例如拿起杯子。具体来说,OFA 旨在利用手部-焦点图像,预测核心操作轨迹。此外,为了增强模型对目标位置的泛化能力,模型使用相对本体感觉信息和相对动作块。
操作目标感知与姿态估计
目标定位:为了方便地从原始图像中提取感兴趣的目标,采用了开放集落地目标检测器 GroundingDINO [36]。它将目标先送入后续分割模型 SAM [37],以实现目标的像素级定位。
姿态估计:机器人手的操作前姿态取决于与目标的相对位移和旋转。因此,精确且一致地估计目标的六维姿态至关重要。FoundationPose [22] 是一种统一的姿态估计方法。它采用目标的多视图图像进行无模型姿态估计,或采用单视图图像结合 CAD 模型进行基于模型的姿态估计。在机器人操作场景中,由于仅提供单视图图像,因此采用基于模型的方法。
对于操作任务,首先使用 3D 扫描仪构建操作目标的 3D 模型。在推理阶段,首先采集RGB图像和对齐的深度图像。然后,生成上一步分割目标物体的掩码图像。所有图像与CAD模型一起被送入姿态估计模型,以估计目标的6D姿态。
预操作姿势的确定
机械手预操作姿势的设置:对于机械手来说,一个目标可能具有多个合适的预操作姿势。例如,一个圆柱形的杯子可以从左侧、右侧、前方或后方抓取。为每个目标分配一个唯一的预操作姿势效率低下且耗费人力。可以对目标进行分类,并为每个类别提取一个统一的预操作姿势,从而无需为每个特定目标配置一个姿势。直观地讲,机械手操作目标的方式与目标的形状和大小密切相关。例如,一个圆柱形的杯子可以用右手从右侧抓取,而一个带把手的杯子则需要抓住把手,一支笔则需要从上方抓取。因此,可以根据目标的形状和大小对其进行分类,并为每个类别设置一个统一的预操作姿势。
将操作目标的六维姿态表示为 To = [Ro|to],其中 Ro 是表示方向的旋转矩阵,to 是表示平移的旋转矩阵。操作前姿态相对于 To 具有静态方向偏移 ∆R0 和平移偏移 ∆to。因此,计算操作前姿态:Tm = [Rm|tm] = [Ro ⊕ ∆R | to + ∆t],其中 ⊕ 表示旋转更新。
运动规划:获得机械手的操作前姿态后,机械手必须无碰撞地达到该姿态。利用 NVIDIA 的 CuRobo [23] 规划器,为机械手生成无碰撞的运动轨迹。该规划器采用多 GPU 并行优化方法来加速运动轨迹的生成。特别地,使用大量球体作为机械臂和手的碰撞表示。随后,根据预操作的目标姿态和环境的实时点云信息,CuRobo 可以为机械手生成一条无碰撞的路径。
目标-焦点策略学习
手部-焦点图像。手部-焦点图像由机械臂和手的前向动力学构建而成。腕关节在手臂基坐标系下的姿态 aT_w = [aR_w | at_w] 由机械臂的本体感觉获取。手指关节 J_h =[j_1, j_2,···, j_6] 类似地由机械手的反馈获取。根据机械手的 URDF 文件和本体感觉 aT_w 和 J_h 构建完整的数字机械手。然后将其转换为相机坐标系,并利用外部参数 eT_a : eT_w = eT_a * aT_w。随后,将机械手的三维点投影到相机图像中,并用所有投影点的外接矩形表示机械手的区域。如前所述,由于预操作点距离待操作物体较近,因此将手部区域放大至其两倍(如图所示),并将目标纳入局部区域。最后,将该区域调整为统一大小,作为最终的手部-焦点图像。

相对本体感觉:手部相对本体感觉由相对姿态 T_rel =[∆p, ∆ω] 和手指角度 J_h = [j_1, j_2, · · · , j_6] 组成。具体而言,Trel 是相对于预操作姿态的姿态,其中 ∆p 表示位置的相对值,∆ω 表示以轴角形式表示的相对方向。
相对动作组块:本文为了减轻模仿学习 [38] 中的复合误差和因果混淆问题,训练策略预测动作组块,而不是单个动作。具体来说,为了使模型能够有效地学习位置泛化能力,训练动作数据采用相对动作块 aˆ_t:t+k =[aˆ_t, …, aˆ_t+k],其中 aˆ_t = [pa_rel, fa] 表示机器人手在时刻 t 的相对动作;pa_rel 表示机器人动作在时刻 t 相对于操作前姿态的相对姿态,以轴角形式表示;fa 表示机器人手的手指角度。
模型架构:类似于使用 Transformers 进行动作分块 (ACT) [1],其构建一个手部-焦点模型,作为条件变分自编码器 (CVAE) [39],用于根据当前手部-焦点观察 o_t = [Images, T_rel, J_h] 生成相对动作块。
训练损失:参考 CVAE,该模型的训练损失定义为两个项的组合:第一项是重建损失,第二项将编码器正则化为高斯先验,η 是超参数,o ̄_t 表示没有图像观测的 o_t。
硬件
实验在如图所示的 Realman Embodied 双臂平台上进行,该平台配备了两个 6 自由度机械臂和一辆移动车辆。由于本实验不涉及移动操作,因此未展示该平台的移动能力。实验中安装 Inspire 公司生产的具有 6 个主动关节的灵巧机械手作为末端执行器。头部安装 ZED2 立体摄像机,其视场为 110 (H) × 70 (V),用于捕捉 RGB 图像并处理深度信息。

任务设置
为了全面评估所提方法的有效性,实验中设计了 7 个具有挑战性的灵巧操作任务,包括 6 个单手任务和 1 个双手任务。单手任务包括:抓取杯子、拿取马克杯、握住条码扫描器、抓取毛圈、捏取玩具和抓取消毒液。双手任务包括用双手提起托盘。
数据收集
对于上述七项任务,需要收集用于策略模仿学习的人体演示数据。具体来说,用拉紧估计手套和定位摄像头作为遥操作设备来控制灵巧手进行数据收集。在收集每个任务的演示数据时,操作目标的位置并非固定,而是随机放置在一个矩形区域内。此外,灵巧手的初始位置是固定的。
最后是训练和推理的算法总结:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









