






1.pivot
原文:https://blog.csdn.net/qq_29118049/article/details/78804768
在做学生成绩信息统计的时候,我们从学生各科考试成绩文件(.csv或.xls等)中把数据抽取上来。样本模拟数据(data_df)如下。
In [13]: print data_df
userNum score subjectCode subjectName userName
0 001 90 01 语文 张三
1 002 96 01 语文 李四
2 003 93 01 语文 王五
3 001 87 02 数学 张三
4 002 82 02 数学 李四
5 003 80 02 数学 王五
pivot有三个参数,第一个index是重塑的新表的索引名称是什么,第二个columns是重塑的新表的列名称是什么,一般来说就是被统计列的分组,第三个values就是生成新列的值应该是多少,如果没有,则会对data_df剩下未统计的列进行重新排列放到columns的上层。
In [20]: pivot_df = data_df.pivot(index='userNum', columns='subjectCode', values='score')
我们给能标识每个学生的学籍号userNum作为索引,因为我们是要统计每个学生,所以每个学生的信息作为一行。要生成语文成绩,数学成绩等,那么可以用标识学科的subjectCode作为每一列,最后,值,当然就是score给每个科目赋成绩值了!
以下是生成的结果:
In [21]: print pivot_df
subjectCode 01 02
userNum
001 90 87
002 96 82
003 93 802. rename
.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None)
参数:
mapper, index, columns : 映射的规则。
axis:指定轴,可以是轴名称('index','columns')或数字(0,1),默认为index。
copy:布尔值,默认为True,复制底层数据。
inplace:布尔值,默认为False。指定是否返回新的DataFrame。如果为True,则在原df上修改,返回值为None。
level:int或level name,默认为None。如果是MultiIndex,只重命名指定级别的标签。
3. set_index
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)- keys: 将keys列设置为index(可设置单级索引和多级索引)
用于设置索引或者多级索引
In [307]: data
Out[307]:
a b c d
0 bar one z 1.0
1 bar two y 2.0
2 foo one x 3.0
3 foo two w 4.0
In [308]: indexed1 = data.set_index('c')
In [309]: indexed1
Out[309]:
a b d
c
z bar one 1.0
y bar two 2.0
x foo one 3.0
w foo two 4.0
In [310]: indexed2 = data.set_index(['a', 'b'])
In [311]: indexed2
Out[311]:
c d
a b
bar one z 1.0
two y 2.0
foo one x 3.0
two w 4.0
4. set_index
- 原文:https://blog.csdn.net/brucewong0516/article/details/82707492
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
参数如下:
- left: 拼接的左侧DataFrame对象
- right: 拼接的右侧DataFrame对象
- on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
- left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
- right_on: 右侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
- left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。
- right_index: 与left_index功能相似。
- how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
- sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。
- suffixes: 用于重叠列的字符串后缀元组。 默认为(‘x’,’ y’)。
- copy: 始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。
- indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。 _merge是分类类型,并且对于其合并键仅出现在“左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在“右”DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
5. iloc 和 loc
pandas以类似字典的方式来获取某一列的值
import pandas as pd
import numpy as np
table = pd.DataFrame(np.zeros((4,2)), index=['a','b','c','d'], columns=['left', 'right'])
print(table)
得到:
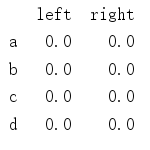
如果我们此时需要得到table列的值
例如:table['left']
即可得到:

如果我们对于行感兴趣,这时候有两种方法,即 iloc 和 loc 方法
loc是指location的意思,iloc中的i是指integer。这两者的区别如下:
loc works on labels in the index. iloc works on the positions in the index (so it only takes integers)
print(table.iloc[0])
print(table.loc['a'])也就是说loc是根据index来索引,
如上table定义了一个index,那么loc就根据这个index来索引对应的行。
iloc是根据行号来索引,行号从0开始,逐次加1。
例如:
print(table.iloc[0])
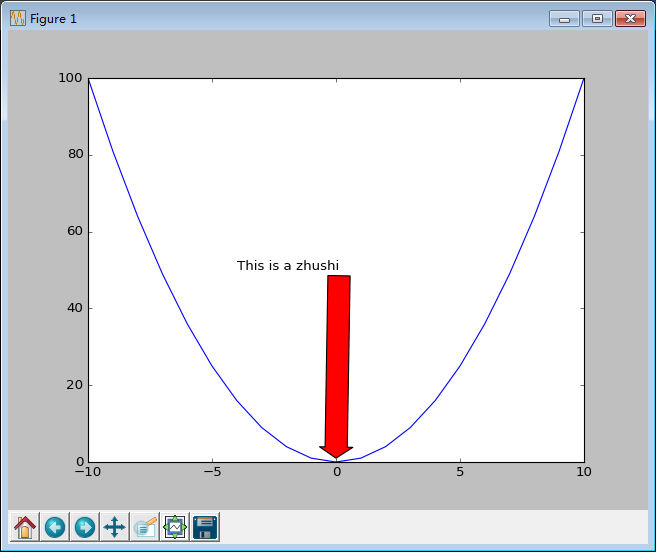
print(table.loc['a'])5. matplotlib.pyplot.annotate
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-10, 11, 1)
y = x * x
plt.plot(x, y)
# 添加注释
# 第一个参数是注释的内容
# xy设置箭头尖的坐标
# xytext设置注释内容显示的起始位置
# arrowprops 用来设置箭头
# facecolor 设置箭头的颜色
# headlength 箭头的头的长度
# headwidth 箭头的宽度
# width 箭身的宽度
plt.annotate(u"This is a zhushi", xy = (0, 1), xytext = (-4, 50),\
arrowprops = dict(facecolor = "r", headlength = 10, headwidth = 30, width = 20))
# 可以通过设置xy和xytext中坐标的值来设置箭身是否倾斜
matplotlib.rcParams
你可以在python脚本或者python交互式环境里动态的改变默认rc配置。所有的rc配置变量称为matplotlib.rcParams 使用字典格式存储,它在matplotlib中是全局可见的。rcParams可以直接修改,如:
import matplotlib as mpl
mpl.rcParams['lines.linewidth'] = 2
mpl.rcParams['lines.color'] = 'r'
6. sklearn中的Pipeline类
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
poly_reg = Pipeline([
('poly',PolynomialFeatures(degree=2)),
('std_scaler',StandardScaler()),
('lin_reg',LinearRegression())
])说明一下Pipeline如何使用:Pipeline里面需要一个列表,列表里元素是一个个元组,每个元组代表对数据的处理,元组的第一个参数是处理的别名,随便取,第二个参数是处理的函数,如本例就是第一步构造高次项,第二步归一化,第三步使用线性回归,然后调用的时候sklearn会顺序执行这些步骤,这是sklearn的Pipeline的思想,
1 poly_reg.fit(X,y)
2 y_predict = poly_reg.predict(X)
3 plt.scatter(x,y)
4 plt.plot(np.sort(x),y_predict[np.argsort(x)],color='r')
5 plt.show()
















 583
583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









