







机器翻译的常用架构是seq2seq,可是seq2seq中的核心模型RNN是序列模型,后面的计算依赖于前面的计算,如何并行提高效率很是苦恼。最近,Facebook和Google的研究人员分别尝试用CNN与Attention代替seq2seq进行机器翻译,提高了训练效率,结构与思想也很予人启迪。
传统的seq2seq
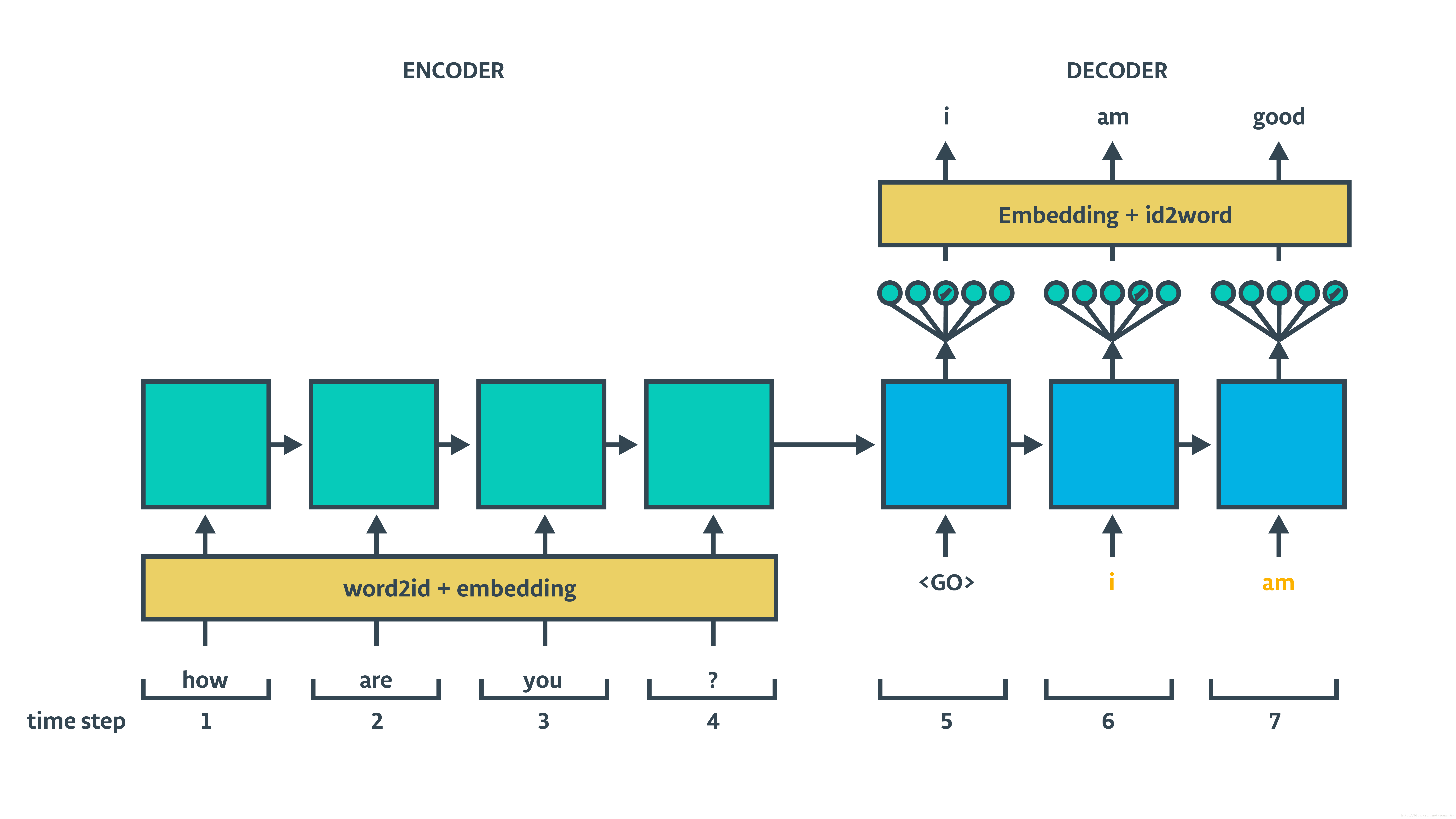
传统seq2seq训练结构如上图,采用两个RNN,分别作为encoder和decoder。seq2seq的一些改进如下:
- decoder中增加更多的信息:decoder中
ht
除了依赖
ht−1,xt
,还依赖于
enc_state。 - 使用attention机制。
facebook的cnn
结构
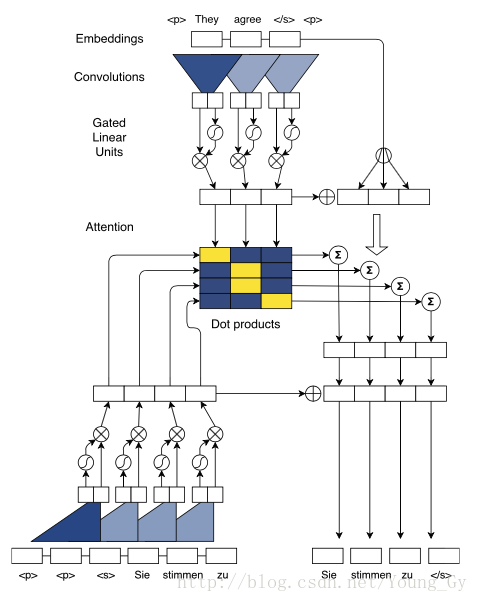
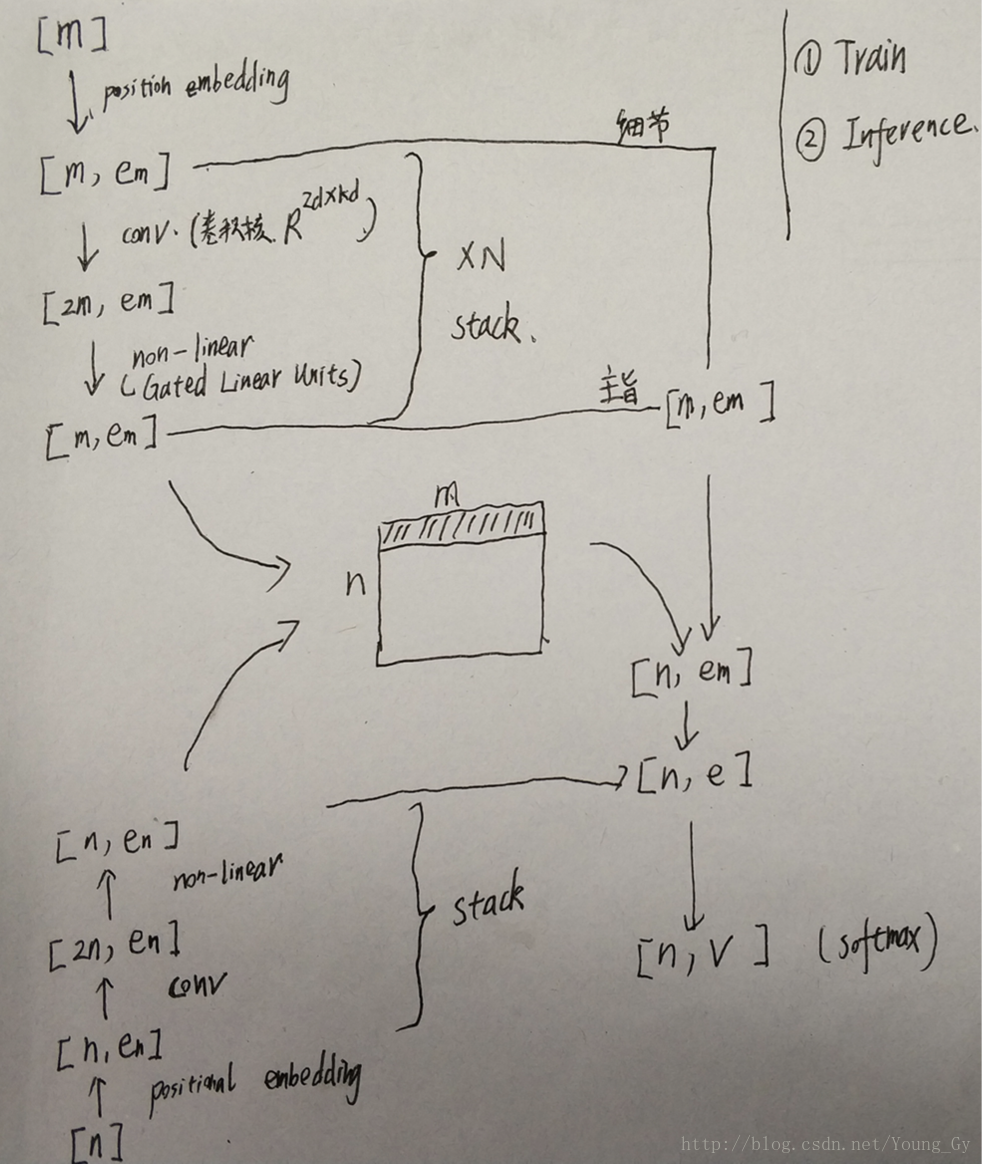
其结构如上面2图所示,具体地:
- 输入序列大小为【m】
- 对输入序列做position embedding,得到【m,e_m】
- 对position embedding做卷积,得到【2m,e_m】
- 卷积后通过Gated Linear Units,得到【m,e_m】
- 重复3-4,stack起来,得到【m,e_m】
- 对输出序列重复2-5,得到【n,e_n】
- 对5,6中的数据做点乘,得到中间的矩阵【m,n】,代表了attention的分数信息
- 上文信息,通过卷积前(细节信息)和卷积后(主旨信息)的信息和获得【m,e_m】。
- 有了上文信息【m,e_m】和attention【m,n】信息,便可以获得输出序列中每个词对应的上文特征【n,e_m】
- 将输出序列的上文特征【n,e_m】与输出序列的卷积特征【n,e_n】组合,加入全连接,加入softmax层即可构建损失函数进行训练。
特点
position embedding
position embedding,在词向量中潜入了位置信息。
卷积的引入
首先,简单描述下文中的卷积,假设原数据大小 X∈ℝk∗d (k个数据,embeding的维度是d),每个卷积核参数化 W∈ℝ2d∗kd ,卷积后得到的结果是 ℝ2d 。padding合适的化,最后得到 ℝ2k∗d 。
卷积的引入,有以下几个优点:
- 使计算可以做并行化
- 卷积层可以stack起来,不同的层的可视域不同,底层的是细节信息,高层的是全局信息。
- 效率高,对序列长度n的序列建模,rnn的操作是 O(n) ,CNN的操作是 O(log(n) 。
GLU控制信息的流动
GLU的公式如下:
卷积出来的数据【2m,e_m】对应【A,B】,通过GLU便恢复了原数据形状【m,e_m】。同时GLU中的A控制信息,B相当于开关控制着有效信息的流动。
attention
attention的分数矩阵,是输入、输出序列通过多个卷积stack起来获得的,每个词的可视域通过CNN自然地扩增了。
attention的上文信息,通过低层的CNN和高层的CNN组合获得, 反映了词的细节信息和全局主旨信息。
google的attention
结构
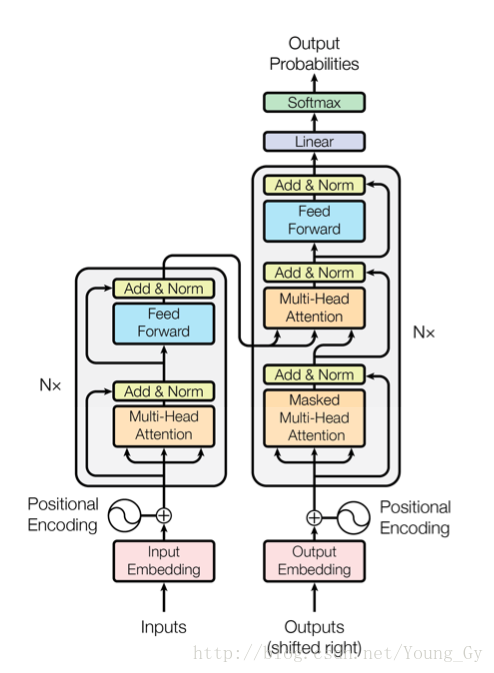
特点
K,V,Q的思维架构
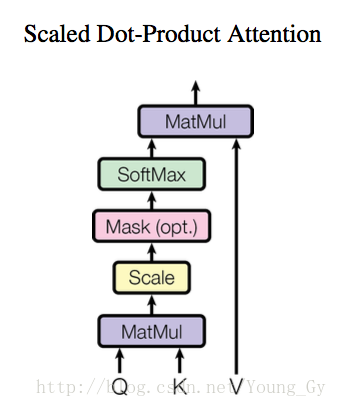
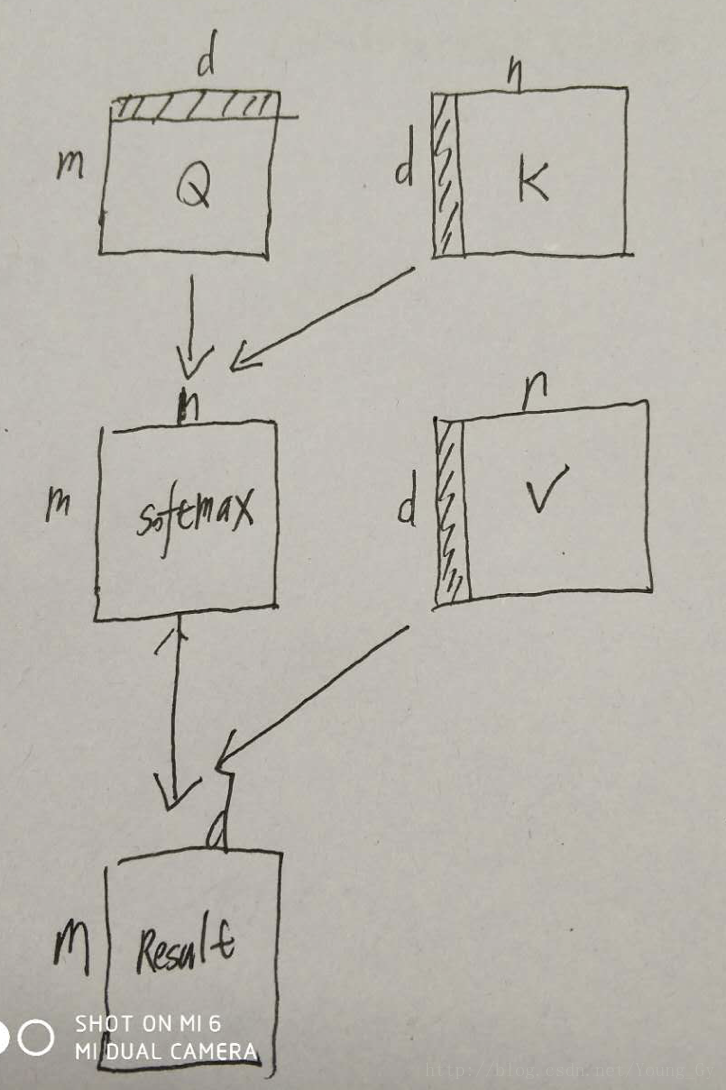
本文提出了一种key、value、pair的计算attention的架构,结构与思路如上图所示。首先,通过Query和Key矩阵计算每个quiry对应的key的匹配程度,然后根据匹配程度将Value矩阵中的元素组合起来。
multi-head attention
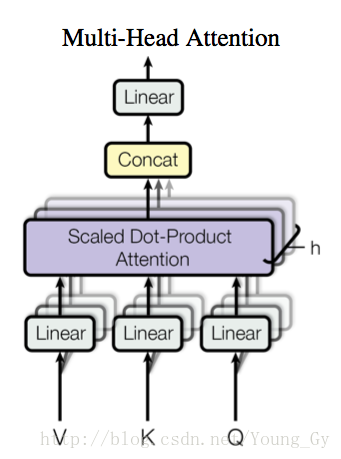
通过一个全连接层,可以将K、V、Q映射到维度较低的子空间,然后在不同的子空间进行attention的计算。这样做有如下优点:
- 子空间维度较低,不增加计算量
- 有利于并行化
- 不同的子空间捕获不同的特征
attention的多种应用
结构中共出现了3出attention:
- encoder-decoder attention,K、V来自encoder,Q来自decoder,作用与传统的seq2seq相似,decoder根据不同的位置捕获encoder不同位置的信息。
- encoder self-attention。K、V、Q来自同一位置,encoder的每一个位置都捕获所有位置的信息。
- decoder self-attention,K、V、Q来自同一位置,decoder的每一个位置都捕获该位置前所有位置的信息(通过mask实现)。















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









