







1、简介
在这篇文章中,我们试图从一系列较长的,关于将Transformer理解为物理系统的文章里提出的想法中,提炼出一个统一的观点:
-
深度隐式注意力:注意力机制的平均场理论视角
-
自旋模型的Transformer:近似自由能最小化
我们主张,原型Transformer模块的神经网络架构蓝图可以从经典统计力学中熟悉的物理自旋系统的结构中导出。更具体地说,我们认为Transformer模块的正向传递,可映射为矢量自旋模型中的计算磁化,作为对输入数据的响应。我们将Transformer想象成可微自旋系统的集合,其行为可以通过训练来塑造。
2、Transformer架构从何而来?
纵观自然语言处理和计算视觉中不断增长的 Transformer 架构可以看出,Attention is All You Need(Vaswani 等人,2017)1中引入的设计模式仍然占主导地位。过去四年发布的几乎所有 transformer 模块的架构变体都坚持了一个成功组合:残差连接、类注意力的操作(标记混合)、归一化层和类前馈的操作(通道混合) .
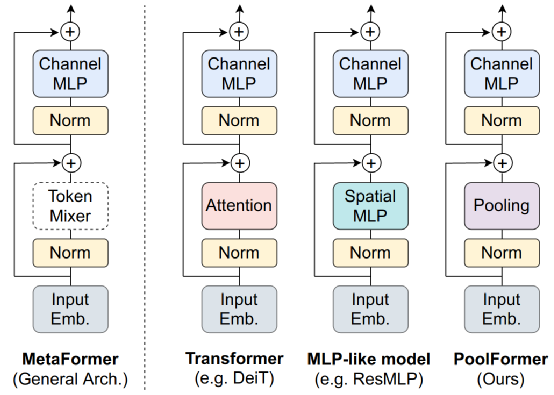
最近的工作,如MetaFormer is Actually What You Need for Vision (Yu et al., 2021) 2适当地将焦点转移到 transformer 模块的高级架构上,并认为其完整结构,而不仅仅是标记混合注意力操作,对Transformer实现具有竞争力的性能至关重要。
那么这个原型设计模式从何而来呢?为什么它似乎一直存在?它的结构背后有什么物理直觉吗?
3. 从能量函数中获得注意力只会让你到此为止
Hopfield Networks is All You Need(Ramsauer 等人,2020 年)3和Large Associative Memory Problem in Neurobiology and Machine Learning(Krotov 和 Hopfield,2020 年)4等近期论文使用基于能量的视角寻找注意力机制背后的物理直觉,用现代连续 Hopfield 网络来表达。主要思路是推导softmax-attention更新规则
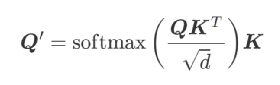
(1)
通过使用一些精心选择的能量函数,对输入查询Q的导数进行大的梯度下降更新步骤
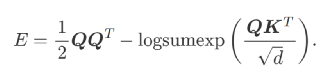
(2)
这样,可以采用大梯度步长对普通的softmax attention进行重构。方程式(2)定义的能量形式,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2960
2960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









