







数据仓库概念、基本特征、数据仓库数据与数据库数据之间的关系
数据仓库概念
数据仓库是一个用于集成和存储企业中各种来源的数据,并支持数据分析和决策制定的关键工具。它为用户提供了一个统一的、一致的视图,用于深入理解业务状况和趋势。
基本特征
-
集成性(Integration):数据仓库集成了多个来源的数据,包括操作型数据库、文件系统等,通过ETL过程(抽取、转换、加载)将数据统一导入数据仓库中。
-
主题导向(Subject-Oriented):数据仓库以业务过程或主题为中心组织数据,而不是按照应用程序或操作系统的结构来组织。
-
时间性(Time-Variant):数据仓库存储历史数据,可以支持时间序列分析和趋势分析,帮助企业了解数据随时间的变化。
-
非易失性(Non-Volatile):一旦数据进入数据仓库,一般不会被频繁地修改或删除,保持数据的稳定性和一致性,适合长期分析和报告。
数据仓库数据与数据库数据之间的关系
-
用途不同:数据库主要用于日常事务处理,支持业务应用的实时数据操作和管理,数据更新频繁。数据仓库则专注于数据分析和决策支持,数据更新频率较低,主要用于历史数据的存储和分析。
-
数据结构不同:数据库通常使用面向应用的数据模型(如关系模型),以支持特定应用的操作需求。数据仓库则采用主题建模(如星型或雪花模型),以支持复杂的分析查询和多维度分析。
-
数据粒度不同:数据库通常存储详细的原子级数据,适合事务处理。数据仓库则通常存储汇总和聚合的数据,适合分析和报告。
-
数据流向:ETL过程负责将数据库中的数据抽取到数据仓库中,确保数据仓库中的数据是经过处理和整合的,以支持更高层次的分析和决策需求。
综上所述,数据库和数据仓库在数据管理和使用的目标、方法以及数据结构上有显著区别,各自服务于不同的业务需求和用户群体。数据仓库在企业中的应用,可以有效支持从战略到操作层面的决策制定和业务分析。
体系结构
数据仓库的体系结构通常包括以下几个关键组成部分,每个部分都有特定的功能和角色,整体构成一个支持数据集成、存储、管理和分析的完整系统:
1. 数据源(Data Sources)
数据源是数据仓库的起点,包括各种不同的数据来源,例如:
-
操作性数据库:包括企业的交易处理系统(OLTP系统),如客户关系管理系统(CRM)、供应链管理系统(SCM)等。
-
文件系统:包括各种结构化和非结构化数据文件,如日志文件、文档、电子表格等。
-
外部数据:来自外部提供商或第三方数据提供者的数据,如市场调研数据、公共数据集等。
2. ETL过程(Extraction, Transformation, Loading)
ETL过程是数据仓库的核心组成部分,负责将来自各个数据源的数据抽取、转换和加载到数据仓库中:
-
抽取(Extraction):从不同的数据源中提取数据,并将其暂存于中间存储区域。
-
转换(Transformation):对抽取的数据进行清洗、转换和整合,确保数据的一致性和质量。
-
加载(Loading):将经过转换的数据加载到数据仓库的目标数据结构中,如维度模型或事实表。
3. 数据存储(Data Storage)
数据存储是数据仓库中实际存储数据的地方,通常包括以下两种存储方式:
-
维度模型(Dimensional Model):用于支持多维数据分析的数据结构,通常以星型或雪花模型表示,包括维度表和事实表。
-
数据存储区域(Data Mart):面向特定部门或功能的数据子集,可以是数据仓库的一部分或独立存在,以满足特定业务需求。
4. 元数据(Metadata)
元数据是描述数据仓库中各个数据对象和过程的数据,包括数据源、数据定义、数据转换规则、数据质量规则等信息,是数据仓库管理和数据分析的关键支持。
5. 数据访问与分析(Data Access and Analysis)
数据访问与分析是数据仓库的最终目的,用户可以通过以下方式进行数据访问和分析:
-
查询和报告:通过查询工具或报表工具访问数据仓库中的数据,进行即席查询或生成预定义的报表。
-
在线分析处理(OLAP):支持多维数据分析,包括切片、钻取、旋转等操作,帮助用户发现数据中的趋势和模式。
-
数据挖掘:应用数据挖掘技术和算法,发现隐藏在数据中的模式、关联和趋势,支持更深入的分析和预测。
6. 元数据管理与管理工具(Metadata Management and Administration Tools)
元数据管理工具帮助管理员和数据管理者管理和维护元数据信息,确保数据仓库的结构和内容的一致性和完整性。管理工具包括数据备份、恢复、安全管理等功能,确保数据仓库的高可用性和安全性。
总结
数据仓库的体系结构是一个复杂的系统,通过有效的数据集成、清洗、存储和分析,支持企业从历史数据中提取有价值的信息,并帮助决策者做出基于数据的决策。每个组成部分在整个体系结构中都有其独特的角色和功能,协同工作以实现数据驱动的业务目标。
数据集市及其结构
数据集市(Data Mart)是数据仓库的一个子集,通常面向特定的业务部门或业务功能,旨在满足特定的业务需求和分析需求。数据集市与整体的数据仓库体系结构紧密相关,但其规模更小、范围更窄,更专注于特定的业务领域或功能需求。
数据集市的结构
数据集市的结构可以根据其设计和使用情况的不同而有所变化,但通常包括以下几个关键组成部分:
-
数据源(Data Sources):
- 数据集市的数据通常来自于整体数据仓库或外部数据源,也可能直接从操作性系统抽取。数据源可以是各种形式的数据,包括结构化数据、半结构化数据和非结构化数据。
-
数据存储(Data Storage):
- 数据集市中的数据存储结构通常依据特定的业务需求和分析模式。常见的数据存储结构包括星型模型(Star Schema)和雪花模型(Snowflake Schema),这些模型有助于支持多维分析(OLAP)和即席查询。
-
ETL过程(Extraction, Transformation, Loading):
- 与整体数据仓库类似,数据集市的数据也需要经历ETL过程。在这一过程中,数据从源系统中抽取出来,经过清洗、转换和整合,然后加载到数据集市的目标数据结构中。ETL过程确保数据的质量和一致性,以支持后续的分析和报告。
-
元数据(Metadata):
- 元数据在数据集市中同样很重要,它描述了数据集市中的各种数据对象、数据定义、数据来源以及数据转换规则。元数据帮助管理者和分析师理解和管理数据集市的内容和结构,确保数据的正确使用和解释。
-
数据访问与分析(Data Access and Analysis):
- 数据集市的最终目的是为业务用户提供数据访问和分析能力。通过数据集市,用户可以进行查询、生成报表、进行多维分析(OLAP)以及应用数据挖掘技术来发现业务中的关键趋势和模式。
-
安全性和权限管理(Security and Access Control):
- 数据集市需要有严格的安全性控制和权限管理机制,以保护敏感数据免受未经授权的访问。安全控制涵盖数据的访问权限、数据传输加密、数据审计和合规性等方面。
数据集市的优势
- 专业化:数据集市能够更专注地满足特定业务部门的需求,提供更精确、更定制的数据分析能力。
- 快速响应:由于规模较小,数据集市能够更快速地响应业务需求变化,支持快速的决策制定和业务分析。
- 成本效益:相比整体数据仓库,数据集市的建设和维护成本通常更低,因为其范围和复杂性较小。
总体来说,数据集市作为数据仓库架构的一部分,通过其专业化和灵活性,帮助企业更有效地利用数据资源,支持业务决策和战略发展。
数据模型(星型图)
数据模型中的星型图(Star Schema)是数据仓库设计中常见的一种结构,用于支持多维分析(OLAP)。星型图由一个中心事实表(Fact Table)和多个周围的维度表(Dimension Tables)组成,形成了类似于星星的结构,因而得名。
用一下别人的图:
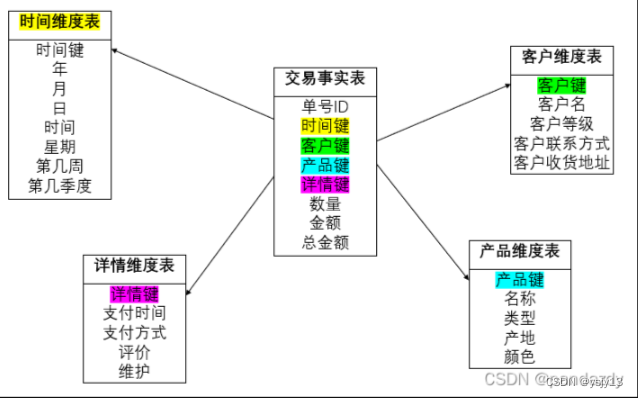
主要组成部分:
-
事实表(Fact Table):
- 事实表包含了业务过程中所发生的事实事件的数据,通常是数值性的数据,如销售金额、库存数量、订单数量等。事实表通常包含大量的记录,每条记录通常与一个特定的业务事件或交易相关联。
- 事实表通常包含少量的外键列,用于连接到一个或多个维度表。
-
维度表(Dimension Tables):
- 维度表是用来描述事实表中数据的上下文信息的表格。维度表包含了与事实表中数据行相关的描述性数据,如时间、地理位置、产品、客户等。
- 每个维度表通常包含一个主键(用于唯一标识每个维度记录)和与事实表外键关联的列。
特点和优势:
- 简单直观:星型图的结构相对简单,易于理解和管理,有助于快速的查询和分析。
- 性能高效:星型图通常具有较好的性能,特别适合于基于维度的查询和报表生成。
- 灵活性:由于维度表和事实表之间的松散耦合关系,星型图支持灵活的数据查询和分析需求。
设计考虑:
- 维度设计:确保维度表具备足够的描述性信息,能够满足多样化的查询需求。
- 事实表设计:选择合适的粒度和度量,并考虑事实表的扩展性和性能优化。
- 查询优化:在设计星型图时,考虑最频繁和最重要的查询类型,以优化数据库设计和索引策略。
星型图在数据仓库设计中被广泛应用,尤其适用于需要快速响应和灵活分析的业务场景,如销售分析、客户关系管理、财务报表等。
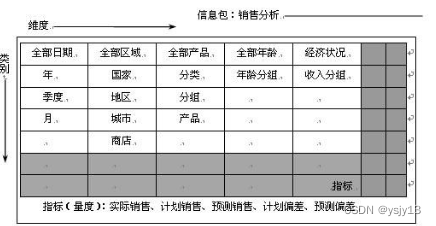
信息包图,事实分类
信息包图(Information Package Diagram)通常用于描述和组织数据仓库中的信息和数据流。它是一种高层次的模型,帮助理解数据仓库中的信息流动和数据处理过程。而“事实分类”可能指的是数据仓库中事实表中的事实类型分类。让我为你详细解释一下这两个概念:
信息包图(Information Package Diagram)
信息包图
信息包图是一种图形化表示方法,用于描述数据仓库中的信息流、数据源、数据转换和目标数据存储等元素。它通常包括以下几个关键元素:
-
数据源(Data Sources):标识数据仓库中来源的各种数据源,如操作性数据库、外部数据源等。
-
数据转换(Data Transformation):显示数据从数据源到数据仓库的转换过程,包括数据清洗、数据整合、数据转换等步骤。
-
目标数据存储(Target Data Stores):展示数据最终存储在数据仓库中的位置,包括事实表和维度表等。
-
信息流(Information Flow):描绘数据如何从不同的数据源通过转换流程最终加载到数据仓库中的过程。
信息包图帮助数据仓库设计者和利益相关者理解整个数据处理流程,确保数据的正确性和一致性,同时也有助于优化数据流程和提升数据质量。
信息包图:
事实分类(Fact Classification)
在数据仓库中,事实表中的事实通常可以按照不同的分类方式进行分类。这些分类有助于理解和分析数据,以及优化查询和报表生成。常见的事实分类包括:
-
周期性事实 vs 累积事实:
- 周期性事实是在特定时间段内发生的事实,如每月的销售额、每周的访问量等。
- 累积事实是从数据源中累积而来的事实,如总销售额、总访问量等。
-
可度量事实 vs 非可度量事实:
- 可度量事实可以直接用数值进行度量,如销售额、数量等。
- 非可度量事实通常是一些描述性的属性或指标,如订单状态、产品类别等。
-
直接事实 vs 派生事实:
- 直接事实是直接从业务过程中获取的事实数据。
- 派生事实是通过计算或加工得到的事实数据,如平均销售单价、利润率等。
事实分类有助于数据仓库管理员和分析师更好地理解和利用事实表中的数据,从而支持更精确的数据分析和决策制定。
综上所述,信息包图和事实分类是数据仓库设计和管理中重要的概念,它们帮助理解数据流和数据内容,从而有效地支持企业的决策和业务需求。
数据仓库设计步骤 ETL概念、基本方法(合并、拆分概念及举例)、与数据预处理的关系
数据仓库设计涉及多个重要步骤,其中包括ETL过程(提取、转换、加载),以及数据预处理。让我逐步解释这些概念及其关系:
1. ETL过程
ETL是数据仓库中非常重要的一环,它包括三个主要步骤:
-
提取(Extract):从不同的数据源中提取数据。这些数据源可以是关系数据库、文件(如CSV文件)、API接口等。提取的数据可以是结构化的、半结构化的或非结构化的数据。
-
转换(Transform):在数据提取后,进行数据转换以满足数据仓库的需求和标准。转换过程包括清洗数据、去重、过滤、数据格式转换、数据合并等操作。转换确保数据在加载到数据仓库之前是高质量和一致的。
-
加载(Load):将转换后的数据加载到数据仓库的目标数据存储(如事实表和维度表)中。加载过程可能涉及数据分区、索引创建等优化步骤,以提高数据查询和报表生成的效率。
2. 合并与拆分的概念及举例
在ETL过程中,合并(Merge)和拆分(Split)是常见的数据转换操作:
-
合并:将多个数据源或多个数据集合并成一个。例如,合并来自不同地区销售的数据,以创建一个包含所有销售记录的整体数据集。
-
拆分:将一个数据源或数据集拆分成多个部分。例如,拆分包含产品和订单信息的单个数据集,以分别加载到产品维度表和订单事实表中。
举例:
-
合并:假设有两个数据源,一个包含客户信息,另一个包含客户的订单信息。在ETL过程中,可以合并这两个数据源,创建一个包含客户和订单信息的完整数据集,以便进一步分析客户的购买行为。
-
拆分:假设一个数据源包含了销售订单的详细信息,包括产品名称、数量、单价等。在ETL过程中,可以拆分这个数据源,将产品相关的信息加载到产品维度表中,将订单相关的信息加载到订单事实表中,以支持分析产品销售情况。
3. 与数据预处理的关系
数据预处理是数据分析的前期工作,旨在准备数据以便进一步分析和建模。它通常包括数据清洗、缺失值处理、异常值处理、数据转换等步骤,以确保数据质量和一致性。与ETL过程相比,数据预处理更侧重于单个数据集的优化和准备,而ETL过程则更关注从多个数据源提取、转换和加载数据到数据仓库中的流程。
关系:
-
数据预处理是ETL过程的一部分:在ETL中的数据转换阶段,通常也包括对数据进行预处理的步骤,例如清洗数据、处理缺失值等。这些预处理步骤有助于确保ETL过程中的数据质量和一致性。
-
ETL过程支持数据预处理:ETL过程提供了一个框架和工具,用于从不同数据源中提取、转换和加载数据。在ETL的转换阶段,可以实现数据预处理的多种操作,以准备数据仓库中的数据供后续分析使用。
综上所述,ETL过程是数据仓库设计中的核心环节,负责将原始数据提取、转换和加载到数据仓库中,而数据预处理则是在分析前对单个数据集进行优化和准备的步骤,二者共同确保数据仓库中的数据质量和可用性。
OLAP:概念、基本操作(切片、钻取)
OLAP(联机分析处理)是一种多维数据分析技术,旨在支持复杂的分析和决策支持。以下是关于OLAP的概念及其基本操作的解释:
概念
OLAP是一种用于多维数据集的分析技术,它允许用户从不同的角度(维度)分析数据,并进行交互式的数据探索。OLAP系统通常构建在数据仓库或数据立方体之上,提供快速的查询和分析能力。
OLAP的特点包括:
- 多维数据视图:数据可以按照多个维度(如时间、地理位置、产品类别等)进行组织和分析。
- 交互性:用户可以动态地探索和分析数据,通过选择不同的维度和指标来获取所需的信息。
- 复杂的分析功能:支持切片(Slice)、切块(Dice)、钻取(Drill Down/Up)、旋转(Rotate)等操作,帮助用户深入分析数据。
基本操作
在OLAP中,有几种基本的操作可以帮助用户以不同的方式分析和查看数据:
-
切片(Slice):
- 定义:在一个固定的维度上选择一个切片,从而查看该维度上的一个特定子集。
- 示例:假设有一个销售数据立方体,包括时间、产品和地区等维度。通过切片操作,可以选择特定的时间段(如一个季度)、特定的产品类型(如电子产品)或特定的地区(如亚太地区),从而查看数据的一个子集。
-
钻取(Drill Down/Up):
- 钻取下钻:从一个概览级别的数据细分到更详细的级别,通过增加一个或多个维度。
- 钻取上钻:从详细级别汇总回到概览级别,减少一个或多个维度。
- 示例:在销售数据立方体中,从年度销售总额(概览级别)钻取到季度销售额或月度销售额(详细级别),或者反之。
-
切块(Dice):
- 定义:在多个维度上进行切片操作,同时选择多个维度的子集,从而查看一个更具体的数据子集。
- 示例:在销售数据立方体中,同时选择特定的时间范围和产品类型,以查看这个特定时间段内不同产品类型的销售情况。
这些基本操作使用户能够以多种方式交互和分析数据,从而快速获取所需的见解和信息,支持决策制定和业务分析
实验:SQLSERVER20112 DATA TOOLS 时间维度概念、部署概念、钻取概念、维度层次 结构概念。
在SQL Server 2012 Data Tools(SSDT)中,以下是与时间维度、部署、钻取和维度层次结构相关的概念的解释:
时间维度概念
时间维度在数据仓库中是一个重要的维度,通常用于分析和报告时间相关的数据,如销售数据按年、季度、月份等时间单位的汇总。在SQL Server 2012中,可以使用维度设计向导或手动创建时间维度表。时间维度表包含各种时间单位的数据(年、月、日等),并与事实表关联,使用户能够按时间进行分析和钻取。
部署概念
在SQL Server 2012中,部署指将数据库项目或分析服务项目部署到目标环境(如生产服务器)。SQL Server Data Tools(SSDT)提供了项目部署向导和脚本生成工具,使开发人员能够轻松地将数据库模式和数据移动到不同环境中,保持数据一致性和应用程序的稳定性。
钻取概念
钻取(Drill Down/Up)是OLAP分析中常见的操作,用于在数据的维度层次结构中导航。在SQL Server Analysis Services(SSAS)中,可以定义多层次的维度结构,如日期维度可以包含年、季度、月等层次。通过钻取操作,用户可以从较高层次(如年度总结)逐步扩展到更详细的层次(如季度或月份),或反之。
维度层次结构概念
维度层次结构定义了维度内部数据的组织方式,通常包括多个层次(如父级、子级)。在SQL Server 2012中,可以使用维度设计向导或自定义维度属性定义维度的层次结构。例如,产品维度可以按产品类别、子类别、产品名称等层次进行组织。层次结构不仅定义了维度数据的组织方式,还支持用户通过钻取操作从汇总级别到详细级别的导航和分析。
这些概念在SQL Server 2012及其相关工具中是数据仓库设计和分析的核心组成部分,帮助用户管理和分析复杂的数据。















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









