







摘要
- 存在的问题:现有的方法无法完全利用从真实世界中采集到的3D信息,并且无法处理大规模的点云数据。
- 本文提出的VoxNet方法是Volumetric Occupancy Grid representation和 Supervised 3D Convolutional Neural Network (3D CNN) 相结合的方法。
- 本文提出的方法在LiDAR, RGBD 和 CAD都适用。
1. 引言
- 网络结构和数据表示形式很重要
- 本文提出了一种用于快速且精确的3D点云数据目标检测框架VoxNet
2. 相关工作
- Volumetric representation要比点云的信息更丰富,因为它能把free space从unknown space分离出来。
- 基于点云特征的查找邻域工作对于大规模点云而言很难完成。
- 对于2.5D的深度图和RGB图而言,直接对它们进行处理无法完全利用数据中的几何信息,并且很难整合多个视点的信息。
3. 方法
输入为点云段,可能是直接从分割方法中拿过来的,也可能是检测过程中框中的点云。
3.1 Volumetric Occupancy Grid
Occupancy grids将当前的环境表示为随机变量的3D网格(voxel),并且将它们占据的空间概率估计视为数据输入的函数和先验知识。
- Volumetric表示要比点云更丰富,它能把目标分为free, occupied 和unknown space
- 更容易存储和计算
3.2 Reference frame and resolution
在volumetric representation表示中,每个点 ( x , y , z ) (x, y, z) (x,y,z)都要被映射到离散的voxel坐标 ( i , j , k ) (i, j, k) (i,j,k)中,该映射过程会考虑voxel网格的origin, orientation和 resolution:
origin
origin就是通过分割算法或是检测框得到的点云输入。
orientation
网格方向的
z
z
z轴就是重力的方向,可以使用IUM或是使传感器垂直实现。尽管还有一个自由度没有确定,但是可以通过数据增强的方法解决。
resolution
- 对于LiDAR dataset,采用0.1×0.1×0.1m 3 ^3 3的分辨率,保证了各个目标间尺度信息的一致性。
- 其他dataset,采用32×32×32 voxel 3 ^3 3的分辨率,但是目标所占用的空间应该在24×24×24voxel 3 ^3 3内,这个可以不固定,下文中还提到了多尺度的分辨率方法。
3.3 Occupancy models
令 { z t } t = 1 T \left\{z^{t}\right\}_{t=1}^{T} {zt}t=1T表示所有体素的状态,对于一个体素 ( i , j , k ) (i, j, k) (i,j,k),hit了就是 ( z t = 1 ) \left(z^{t}=1\right) (zt=1),pass through了就是 ( z t = 0 ) \left(z^{t}=0\right) (zt=0)。
Binary occupancy grid
在该模型中,每个体素假设有两个状态,分别为occupied 或是 unoccupied。对于每一个体素,occupancy的概率估计是通过log odds来更新的:
l
i
j
k
t
=
l
i
j
k
t
−
1
+
z
t
l
o
c
c
+
(
1
−
z
t
)
l
free
l_{i j k}^{t}=l_{i j k}^{t-1}+z^{t} l_{\mathrm{occ}}+\left(1-z^{t}\right) l_{\text {free }}
lijkt=lijkt−1+ztlocc+(1−zt)lfree
在给定这个体素被hit或是被miss后,
l
o
c
c
l_{\mathrm{occ}}
locc和
l
free
l_{\text {free }}
lfree 就是这个单元的log odds,本文设置这些参数为
l
o
c
c
=
1.38
l_{\mathrm{occ}}=1.38
locc=1.38,
l
free
=
−
1.38
l_{\text {free }}=−1.38
lfree =−1.38,并且将log odds截断为
(
−
4
,
4
)
(-4,4)
(−4,4)以避免数值不稳定问题。occupancy最初被设置为0.5,
l
i
j
k
0
=
0
l_{i j k}^{0}=0
lijk0=0。
Density grid
在该模型中,每个体素都被假设有一个连续的强度,对应着传感器采集而来的概率。对于所有的体素
(
i
,
j
,
k
)
(i, j, k)
(i,j,k),设置参数
α
i
j
k
t
\alpha_{i j k}^{t}
αijkt and
β
i
j
k
t
\beta_{i j k}^{t}
βijkt,初始时
α
i
j
k
0
=
β
i
j
k
0
=
1
\alpha_{i j k}^{0}=\beta_{i j k}^{0}=1
αijk0=βijk0=1。每个体素更新时都会受到
z
t
z_{t}
zt的影响:
α
i
j
k
t
=
α
i
j
k
t
−
1
+
z
t
β
i
j
k
t
=
β
i
j
k
t
−
1
+
(
1
−
z
t
)
\begin{aligned} \alpha_{i j k}^{t} &=\alpha_{i j k}^{t-1}+z^{t} \\ \beta_{i j k}^{t} &=\beta_{i j k}^{t-1}+\left(1-z^{t}\right) \end{aligned}
αijktβijkt=αijkt−1+zt=βijkt−1+(1−zt)
最后平均值表示为:
μ
i
j
k
t
=
α
i
j
k
t
α
i
j
k
t
+
β
i
j
k
t
\mu_{i j k}^{t}=\frac{\alpha_{i j k}^{t}}{\alpha_{i j k}^{t}+\beta_{i j k}^{t}}
μijkt=αijkt+βijktαijkt
μ
i
j
k
\mu_{i j k}
μijk被作为输入。
Hit grid
在此模型中仅考虑hit,初始状态下 l i j k 0 = 0 l_{i j k}^{0}=0 lijk0=0,更新过程如下:
h
i
j
k
t
=
min
(
h
i
j
k
t
−
1
+
z
t
,
1
)
h_{i j k}^{t}=\min \left(h_{i j k}^{t-1}+z^{t}, 1\right)
hijkt=min(hijkt−1+zt,1)
尽管该模型丢掉了一些潜在的变量信息,不需要raycasting,但是实验证明其性能很好。
3.4 3D Convolutional Network Layers
- 卷积网络可以提取目标的空间特征
- 多层的结构使得网络可以构造更大区域空间的特征,最后生成输入occupancy的全局特征。
- 推理可以使用前馈神经网络实现,很快很简单
首先对上一节更新到的数据进行归一化(减0.5,乘以2),范围为(-1, 1)。
卷积层 C ( f , d , s ) C(f,d,s) C(f,d,s)
f f f表示特征维度, d d d表示核的大小, s s sb表示stride
Pooling Layers P ( m ) P(m) P(m)
起到下采样的作用,对m×m×m不重叠范围内的voxel取最大值
Fully Connected Layer F C ( n ) FC(n) FC(n)
全连接层有n个输出
3.5 Proposed architecture

VoxelNet的结构很简单, C ( 32 , 5 , 2 ) − C ( 32 , 3 , 1 ) − P ( 2 ) − F C ( 128 ) − F C ( K ) C(32, 5, 2)−C(32, 3, 1)−P(2)−FC(128)−FC(K) C(32,5,2)−C(32,3,1)−P(2)−FC(128)−FC(K),其中 K K K 表示类别的数量。该模型有921736个参数,其中大多数都集中在第一层。
3.6 Rotation Augmentation and Voting
为了解决旋转不变性问题,在训练时使用数据增强的方法解决。在这里,旋转的角度是全面取得的,并不是随机得到的。把每个模型旋转360°/n度,多增加了n倍的数据。在测试的时候,每个目标的输入的角度也不同,输出层的维度也要增加n倍,最后采取投票的方式确定到底属于哪一类。可以避免过拟合现象。
3.7 Multiresolution Input
分辨率较高的Volumetric Occupancy Grid会得到更精细的特征,分辨率较低的Volumetric Occupancy Grid能够获得全局特征。本文中使用两个相同的框架处理两个分辨率不一样的Volumetric Occupancy Grid,为了让这两个模型进行融合,直接将两个 F C ( 128 ) FC(128) FC(128)拼接,连接到softmax输出层。
3.8 Network training details
Optimizer:SGD
Momentum:0.9
Objective function:多项式负对数似然加上0.001倍的 L 2 L_2 L2范数,用于正则化。
lr :0.01 for LiDAR dataset, 0.001 for the other datasets
Batch_size:32
Dropout:fc
Initial para:zero-mean Gaussian with σ = 0.01
Data augment: rotation,shift,mirror
4. 实验
4.1 数据集

- LiDAR data - Sydney Urban Objects
- CAD data - ModelNet
- RGBD data - NYUv2
4.2 可视化结果
Learned filters
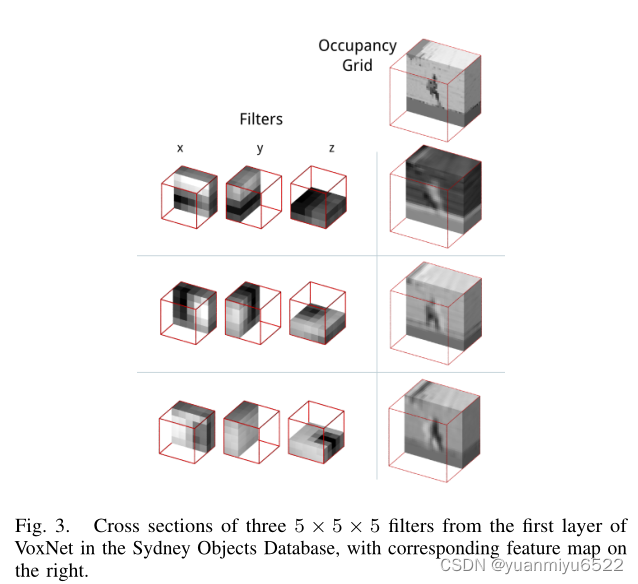
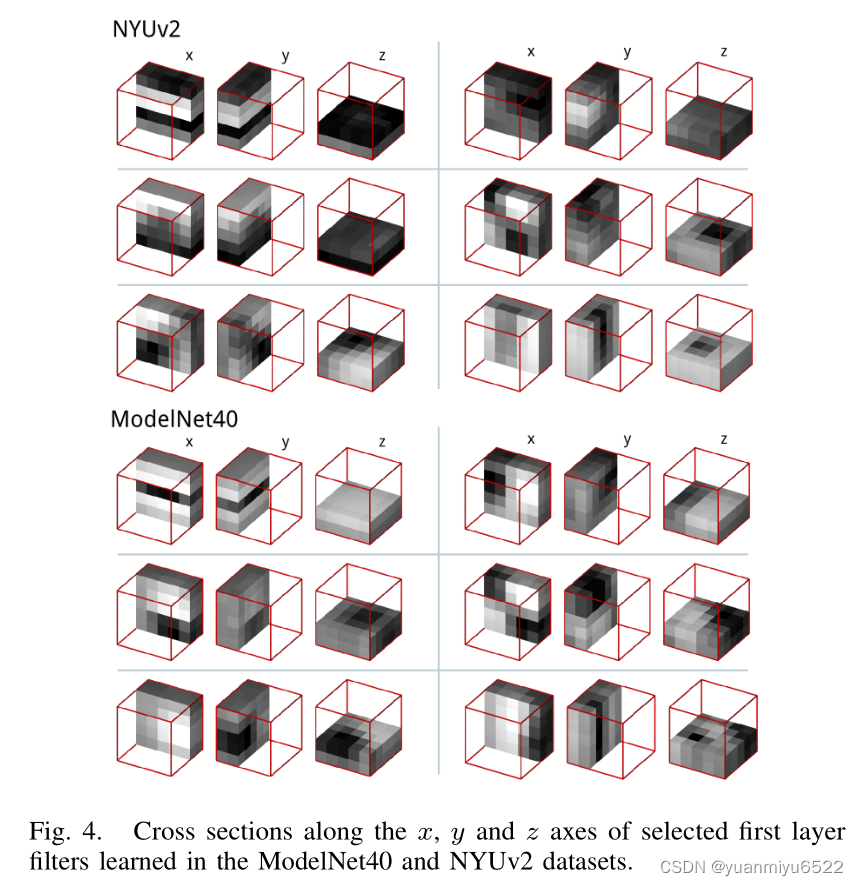
Rotational invariance
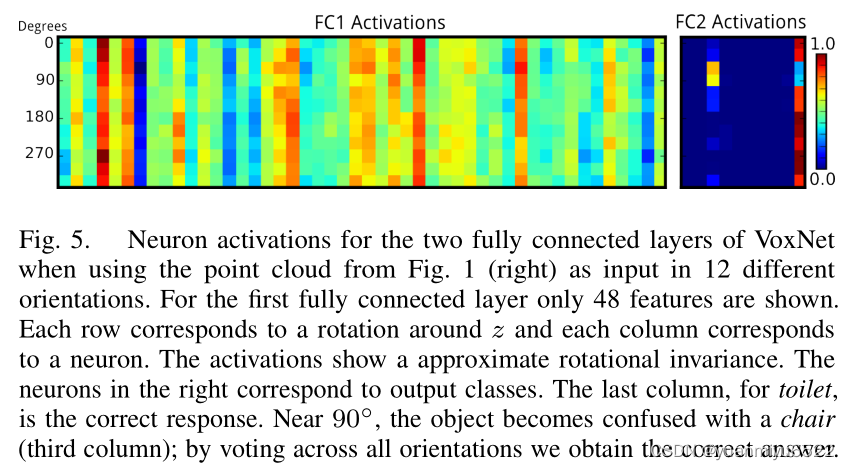
4.2 VoxNet variations
Rotation Augmentation
- no training time augmentation is performed——ModelNet40 in a canonical pose
- no training time augmentation is performed——Sydney Objects unmodified orientation

训练时进行data augment很重要。
Occupancy grid
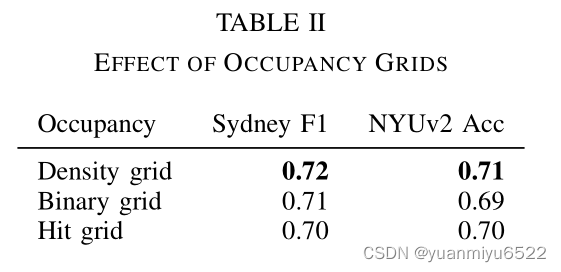
Comparison to other approaches

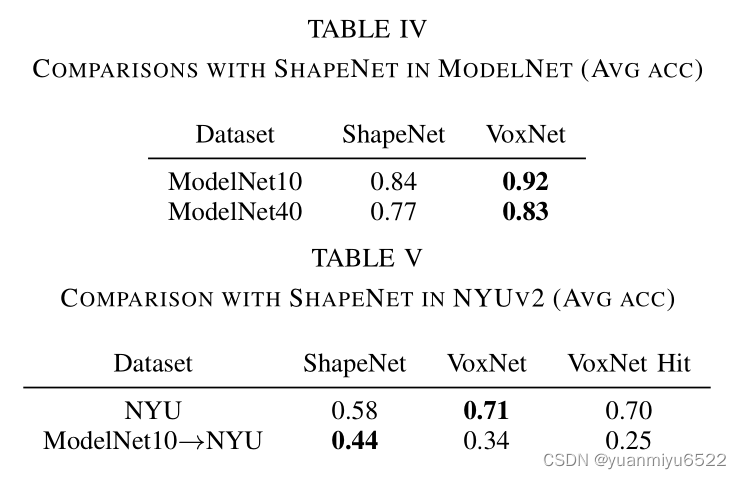
ShapeNet的结构相对而言很大,有一千二百四十多万个参数,而本文只是用了一百万个参数。
Timing
我们提出的最复杂的模型分类仅需6ms,当batch size为32时,平均时长为1ms。2ms可以处理2k个点,处理200k个点用0.5s。使用Hit Grids,或是raytracing优化策略会更快。
5. 结论
生词
- clutter adj. 嘈杂的
- supersede v. 取代,替换















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









