







目录
2.中间卷积层(Convolution middle layers)
论文地址:https://arxiv.org/abs/1711.06396
代码地址:GitHub - RPFey/voxelnet_pytorch: modification of voxelnet
一、论文动机
1.传统的点云特征手工提取具有很大的局限性,不能适应点云检测场景的多变性。
2.pointnet和++都是处理的小规模数量点云,一般都是几千个点左右。而lidar点云一般都是几万级别的。
二、论文方法
1.提出了一种端到端的点云检测框架,直接在稀疏点云上运行,避免了手动特征工程的信息瓶颈
2.提出了VFE体素特征编码网络,可以有效的提取体素特征
3.引入RPN区域提议网络,用于高效的目标检测
具体来说,VoxelNet 将点云划分为等间距的 3D 体素,通过堆叠 VFE 层对每个体素进行编码,然后 3D 卷积进一步聚合这些局部体素的特征,将三维特征的点云转换为高维特征表示。最后, 使用RPN产生检测结果。这种高效的算法受益于稀疏点结构和体素网格上的高效并行处理。
三、网络结构
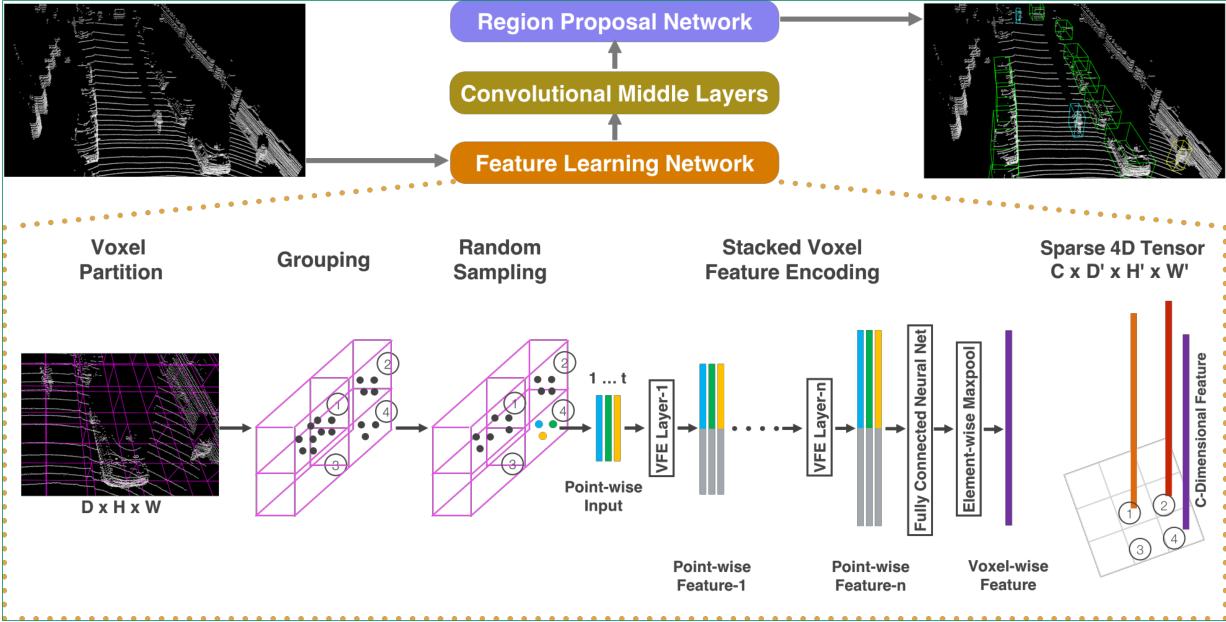
1.Feature Learning Network
1.1Voxel划分
将点云在空间上划分为许多体素,设定体素的长宽高,并对点云裁剪,太边缘的不要,因为很稀疏没啥用。论文中划分后为[352,400,10]个voxel
1.2Grouping(将每个点分配给对应的Voxel)和Sampling(voxel中点云的采样)
体素化后,有好多网格里面没有点,有些点又过多,这时我们对非空的voxel进行降采样,每个里面随机采样T个点,不足的用0补充。因此在grouping之后,得到的数据为[N,T,C],N为非空体素的个数,T为每个体素里面采样的点,C为特征。论文里T为35,C为7, [xi , yi , zi , ri, xi_offset,yi_offset,zi_offset],先求出每个体素里面35个点的均值,每个点xyz都减去均值,得到xyz偏移。
1.3VFE堆叠
将每个voxel中的点通过全连接层转换为高维空间(每个全连接层包括FC,RELU,BN),维度也从(N,35,7)变成了(N,35,C1),然后maxpooling得到voxel的聚合特征,将聚合特征拼接到每个高维点云特征中,得到(N,35,2*C1),我们将这个过程称之为VFE模块。原论文中有两个VFE模块,得到(N,35,32),(N,35,128),得到这个特征之后需要再进行一个FC来融合点特征和聚合特征,这个FC保持输入输出维度不变,还是(N,35,128),再maxpooling一下,得到(N,128)
1.4稀疏特征表示
前面的操作都是对非空体素的操作,这些voxel仅仅对应3D空间中很小一部分,现在将那些非空的体素还原到3D空间中,得到一个稀疏的4D张量(128,10,400,352)
2.中间卷积层(Convolution middle layers)
得到稀疏张量之后,我们使用三维卷积来聚合voxel之间的局部关系,扩大感受野获取更丰富的形状信息,方便RPN预测。论文里使用了三个三维卷积(cin,cout,K,S,P)
Conv3D(128, 64, 3, (2,1,1), (1,1,1)),
Conv3D(64, 64, 3, (1,1,1), (0,1,1)),
Conv3D(64, 64, 3, (2,1,1), (1,1,1))
最终得到的张量为 (64,2,400,352),将数据整理成RPN网络需要的特征体,reshape成(64*2,400,352),这样维度就变成了C,Y,X,不考虑Z的原因是kitti的3D空间在高度上没有堆叠,这样也减少了网络后期RPN的设计难度和anchor数量。
3.RPN层
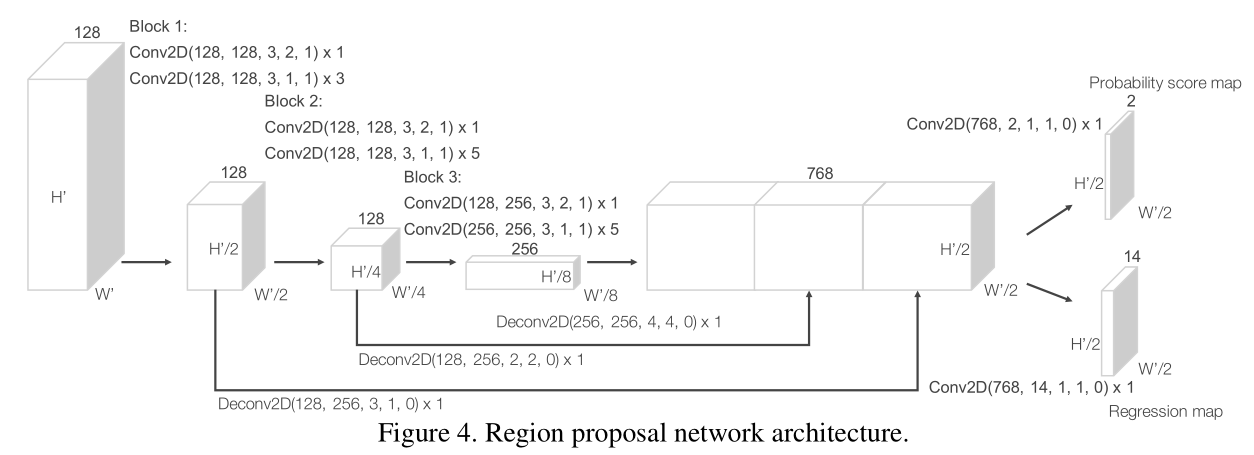
这里每一层卷积都是二维的卷积操作,每个卷积后面都接一个BN和RELU层。最终的预测结果只针对一类,两个角度的预测,所以是(B,2,200,176)和(B,14,200,176),anchor沿着xy间隔放置。
四、损失函数及其余创新点
4.1损失函数
正负样本匹配:在BEV视角进行2D IOU匹配,大于0.6为正样本,小于0.45为负样本,中间不计。分类损失正负样本都记,使用交叉熵损失函数,回归损失只记正样本的,使用smoothL1函数。
4.2点云的数据增强
1.由于标注的时候一个GTbox已经标注出来了有哪些点,所以可以同时移动或者旋转这些点来创造大量的变化数据,移动后还要进行碰撞检测,删掉碰撞的那些GT。
2.对所有的GTbox进行放大或者缩小,放大缩小尺度在[0.95,1.05]之间,引入缩放可以使得网络在检测不同大小物体上有更好的泛化性能。
3.对所有的GT box进行随机的旋转操作,角度在[-45,45]均匀分布中抽取,旋转物体的偏航角可以模拟其转了一个弯。
4.3高效实现堆叠VFE
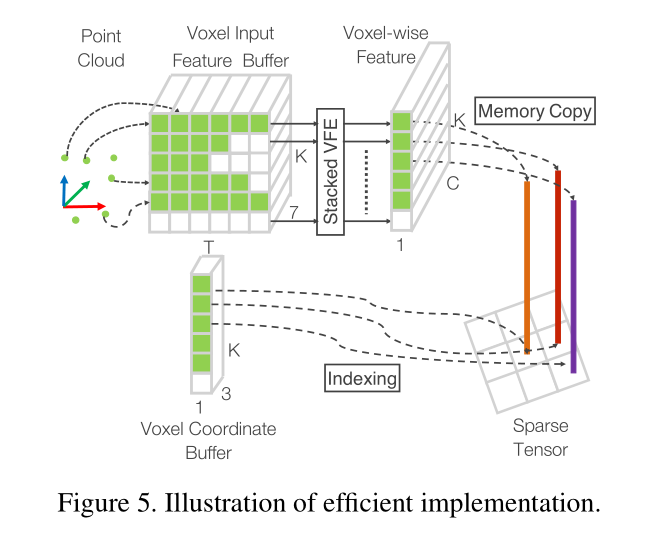
由于每个voxel中包含的点个数不一样,所以作者将所有点云数据转换成了一种密集的数据结构,使得后面堆叠VFE可以在所有点和voxel的特征上平行处理。
1、首先创建一个K*T*7的张量(voxel input feature buffer)用来存储每个点或者中间的voxel特征数据,K是最大的非空voxel数量,T是每个voxel中最大的点数,7是每个点的编码特征。所有的点都是被随机处理的。
2、遍历整个点云数据,如果一个点对应的voxel在voxel coordinate buffer中,并且与之对应的voxel input feature buffer中点的数量少于T个,直接将这个点插入其中,否则直接抛弃。如果一个点对应的voxel不在voxel coordinate buffer中,需要在voxel coordinate buffer中直接使用这个voxel的坐标初始化这个voxel,并储存这个点到voxel input feature buffer中。这整个操作都是用哈希表完成,因此时间复杂度都是O(1)。整个Voxel Input Feature Buffer和voxel coordinate buffer的创建只需要遍历一次点云数据就可以,时间复杂度只有O(N),同时为了进一步提高内存和计算资源,对voxel中点的数量少于m数量的voxel直接忽略该voxel的创建。
3、在创建完Voxel Input Feature Buffer和voxel coordinate buffer后Stacked Voxel Feature Encoding就可以直接在点的基础上或者voxel的基础上进行平行计算。再经过VFE模块的concat操作后,就将之前为空的点的特征置0,保证了voxel的特征和点的特征的一致性。最后,使用存储在voxel coordinate buffer的内容恢复出稀疏的4D张量数据,完成后续的中间特征提取和RPN层。
五、代码阅读
数据预处理:先使用crop.py程序把图像坐标之外的点云剪裁掉便于后期可视化验证,在运行crop.py之前,需要先在training和testing文件夹下新建crop文件夹,运行完的数据存在里面。
根据标签数据构建3D框,在KITTIDatset里面,加载标签数据得到gt_box3d_corner(N,8,3), gt_box3d(N,7)
加载点云数据同时进行data_augment,然后utils.get_filtered_lidar筛选出指定空间范围内的点云和真实检测框顶点的坐标。self.preprocess(lidar)点云体素化返回体素特征voxel_features(Nx35x7)和体素坐标voxel_coords(Nx3),这两个送入网络得到预测输出,然后真实框和锚框送入dataset.cal_target计算真实偏移。然后求这两者的损失
5.1网络结构
import torch.nn as nn
import torch.nn.functional as F
import torch
from torch.autograd import Variable
from config import config as cfg
# conv2d + bn + relu
class Conv2d(nn.Module):
def __init__(self,in_channels,out_channels,k,s,p, activation=True, batch_norm=True):
super(Conv2d, self).__init__()
self.conv = nn.Conv2d(in_channels,out_channels,kernel_size=k,stride=s,padding=p)
if batch_norm:
self.bn = nn.BatchNorm2d(out_channels)
else:
self.bn = None
self.activation = activation
def forward(self,x):
x = self.conv(x)
if self.bn is not None:
x=self.bn(x)
if self.activation:
return F.relu(x,inplace=True)
else:
return x
# conv3d + bn + relu
class Conv3d(nn.Module):
def __init__(self, in_channels, out_channels, k, s, p, batch_norm=True):
super(Conv3d, self).__init__()
self.conv = nn.Conv3d(in_channels, out_channels, kernel_size=k, stride=s, padding=p)
if batch_norm:
self.bn = nn.BatchNorm3d(out_channels)
else:
self.bn = None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
return F.relu(x, inplace=True)
# Fully Connected Network
class FCN(nn.Module):
def __init__(self,cin,cout):
super(FCN, self).__init__()
self.cout = cout
self.linear = nn.Linear(cin, cout)
self.bn = nn.BatchNorm1d(cout)
def forward(self,x):
# KK is the stacked k across batch
kk, t, _ = x.shape
x = self.linear(x.view(kk*t,-1))
x = F.relu(self.bn(x))
return x.view(kk,t,-1)
# Voxel Feature Encoding layer
class VFE(nn.Module):
def __init__(self,cin,cout):
super(VFE, self).__init__()
assert cout % 2 == 0
self.units = cout // 2
self.fcn = FCN(cin,self.units)
def forward(self, x, mask):
# point-wise feauture
pwf = self.fcn(x)
#在35个点中求max,再unsqueeze在指定位置增加一个维度,得到voxel局部特征
laf = torch.max(pwf,1)[0].unsqueeze(1).repeat(1,cfg.T,1)
# 将点特征和voxel局部特征在特征维度进行相加
pwcf = torch.cat((pwf,laf),dim=2)
# 因为有些点是填充零的,需要把这些点去掉
mask = mask.unsqueeze(2).repeat(1, 1, self.units * 2)
pwcf = pwcf * mask.float()
return pwcf
# Stacked Voxel Feature Encoding
class SVFE(nn.Module):
def __init__(self):
super(SVFE, self).__init__()
self.vfe_1 = VFE(7,32)
self.vfe_2 = VFE(32,128)
self.fcn = FCN(128,128)
def forward(self, x):
#torch.ne用来判断是否不相等,不等于0的赋值1,表明这个点存在,等于零的赋值0,表示是填充的点
mask = torch.ne(torch.max(x,2)[0], 0)
x = self.vfe_1(x, mask)
x = self.vfe_2(x, mask)
x = self.fcn(x)
# 在第二个维度35中求max,后面加[0]表示获取最大的数据而不是数据和下标,这里得到voxel全局特征
x = torch.max(x,1)[0]
return x
# Convolutional Middle Layer
#输入维度(2,128,10,400,352)
#输出维度(2,64,2,400,352)
class CML(nn.Module):
def __init__(self):
super(CML, self).__init__()
self.conv3d_1 = Conv3d(128, 64, 3, s=(2, 1, 1), p=(1, 1, 1))
self.conv3d_2 = Conv3d(64, 64, 3, s=(1, 1, 1), p=(0, 1, 1))
self.conv3d_3 = Conv3d(64, 64, 3, s=(2, 1, 1), p=(1, 1, 1))
def forward(self, x):
x = self.conv3d_1(x)
x = self.conv3d_2(x)
x = self.conv3d_3(x)
return x
#nn.Modulelist和nn.Sequential里面的module是会自动注册到整个网络上的,同时module的parameters也会自动添加到整个网络中,但如果使用list存储则不会添加,也就无法训练
#而且nn.Modulelist里面可以像数组一样调用,也就是可与不按照顺序运行,而nn.Sequential里面的顺序的固定的
# Region Proposal Network
class RPN(nn.Module):
def __init__(self):
super(RPN, self).__init__()
self.block_1 = [Conv2d(128, 128, 3, 2, 1)]
self.block_1 += [Conv2d(128, 128, 3, 1, 1) for _ in range(3)]
self.block_1 = nn.Sequential(*self.block_1)
self.block_2 = [Conv2d(128, 128, 3, 2, 1)]
self.block_2 += [Conv2d(128, 128, 3, 1, 1) for _ in range(5)]
self.block_2 = nn.Sequential(*self.block_2)
self.block_3 = [Conv2d(128, 256, 3, 2, 1)]
self.block_3 += [nn.Conv2d(256, 256, 3, 1, 1) for _ in range(5)]
self.block_3 = nn.Sequential(*self.block_3)
self.deconv_1 = nn.Sequential(nn.ConvTranspose2d(256, 256, 4, 4, 0),nn.BatchNorm2d(256))
self.deconv_2 = nn.Sequential(nn.ConvTranspose2d(128, 256, 2, 2, 0),nn.BatchNorm2d(256))
self.deconv_3 = nn.Sequential(nn.ConvTranspose2d(128, 256, 1, 1, 0),nn.BatchNorm2d(256))
self.score_head = Conv2d(768, cfg.anchors_per_position, 1, 1, 0, activation=False, batch_norm=False)
self.reg_head = Conv2d(768, 7 * cfg.anchors_per_position, 1, 1, 0, activation=False, batch_norm=False)
def forward(self,x):
#输入维度(128,400,352)
x = self.block_1(x)
x_skip_1 = x
x = self.block_2(x)
x_skip_2 = x
x = self.block_3(x)
x_0 = self.deconv_1(x)
x_1 = self.deconv_2(x_skip_2)
x_2 = self.deconv_3(x_skip_1)
#这里的x维度是(768,200,176)
x = torch.cat((x_0,x_1,x_2),1)
return self.score_head(x),self.reg_head(x)
class VoxelNet(nn.Module):
def __init__(self):
super(VoxelNet, self).__init__()
self.svfe = SVFE()
self.cml = CML()
self.rpn = RPN()
#sparse_features(2,N,128)
def voxel_indexing(self, sparse_features, coords):
dim = sparse_features.shape[-1]
#(128,2,10,400,352)
dense_feature = Variable(torch.zeros(dim, cfg.N, cfg.D, cfg.H, cfg.W).cuda())
dense_feature[:, coords[:,0], coords[:,1], coords[:,2], coords[:,3]]= sparse_features
#transpose维度交换 (2,128,10,400,352)
return dense_feature.transpose(0, 1)
def forward(self, voxel_features, voxel_coords):
# feature learning network
vwfs = self.svfe(voxel_features)#(2,N,35,7)-----(2,N,128)
vwfs = self.voxel_indexing(vwfs,voxel_coords) #(2,N,128)----(2,128,10,400,352)
# convolutional middle network
cml_out = self.cml(vwfs) #(2,128,10,400,352)----(2,64,2,200,176)
# region proposal network
# merge the depth and feature dim into one, output probability score map and regression map
psm,rm = self.rpn(cml_out.view(cfg.N,-1,cfg.H, cfg.W)) #(2,128,200,176)----(2,2,200,176)and(2,14,200,176)
return psm, rm
5.2损失函数
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
#(1)生成200x176x2=70400个anchor,每个anchor有0和90度朝向,所以乘以两倍。后续特征图大小为(200x176),相当于每个特征生成两个anchor。anchor的属性包括x、y、z、h、w、l、rz,即70400x7。
# 2)通过计算anchor和目标框在xoy平面内外接矩形的iou来判断anchor是正样本还是负样本。正样本的iou 阈值为0.6,负样本iou阈值为0.45。正样本还必须包括iou最大的anchor,负样本必须不包含iou最大的anchor。
#(3)由于anchors的维度表示为200x176x2,用维度为200x176x2矩阵pos_equal_one来表示正样本anchor,取值为1的位置表示anchor为正样本,否则为0。
#(4)同样地,用维度为200x176x2矩阵neg_equal_one来表示负样本anchor,取值为1的位置表示anchor为负样本,否则为0
#(5)用targets来表示anchor与真实检测框之间的差异,包含x、y、z、h、w、l、rz等7个属性之间的差值,这跟后续损失函数直接相关。targets维度为200x176x14,最后一个维度的前7维表示rz=0的情况,后7维表示rz=pi/2的情况。
class VoxelLoss(nn.Module):
def __init__(self, alpha, beta, gamma):
super(VoxelLoss, self).__init__()
self.smoothl1loss = nn.SmoothL1Loss(reduction='sum')
self.alpha = alpha
self.beta = beta
self.gamma = gamma
def forward(self, reg, p_pos, pos_equal_one, neg_equal_one, targets, tag='train'):
# reg (B * A*7 * H * W) , score (B * A * H * W),
# pos_equal_one, neg_equal_one(B,H,W,A),这里存放的正样本和负样本的标签,是就是1,不是这个位置就是0
# A表示每个位置放置的anchor数,这里是2一个0度一个90度
reg = reg.permute(0,2,3,1).contiguous()
reg = reg.view(reg.size(0),reg.size(1),reg.size(2),-1,7) # (B * H * W * A * 7)
targets = targets.view(targets.size(0),targets.size(1),targets.size(2),-1,7) # (B * H * W * A * 7)
pos_equal_one_for_reg = pos_equal_one.unsqueeze(pos_equal_one.dim()).expand(-1,-1,-1,-1,7)#(B,H,W,A,7)
rm_pos = reg * pos_equal_one_for_reg
targets_pos = targets * pos_equal_one_for_reg
#这里是正样本的分类损失
cls_pos_loss = -pos_equal_one * torch.log(p_pos + 1e-6)
cls_pos_loss = cls_pos_loss.sum() / (pos_equal_one.sum() + 1e-6)
#这里是负样本的分类损失
cls_neg_loss = -neg_equal_one * torch.log(1 - p_pos + 1e-6)
cls_neg_loss = cls_neg_loss.sum() / (neg_equal_one.sum() + 1e-6)
#只计算正样本的回归损失
reg_loss = self.smoothl1loss(rm_pos, targets_pos)
reg_loss = reg_loss / (pos_equal_one.sum() + 1e-6)
conf_loss = self.alpha * cls_pos_loss + self.beta * cls_neg_loss
if tag == 'val':
xyz_loss = self.smoothl1loss(rm_pos[..., [0,1,2]], targets_pos[..., [0,1,2]]) / (pos_equal_one.sum() + 1e-6)
whl_loss = self.smoothl1loss(rm_pos[..., [3,4,5]], targets_pos[..., [3,4,5]]) / (pos_equal_one.sum() + 1e-6)
r_loss = self.smoothl1loss(rm_pos[..., [6]], targets_pos[..., [6]]) / (pos_equal_one.sum() + 1e-6)
return conf_loss, reg_loss, xyz_loss, whl_loss, r_loss
return conf_loss, reg_loss, None, None, None
5.3 train.py
import torch.nn as nn
import torch
from torch.autograd import Variable
from config import config as cfg
from data.kitti import KittiDataset
import torch.utils.data as data
import time
from loss import VoxelLoss
from voxelnet import VoxelNet
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.nn.init as init
# from nms.pth_nms import pth_nms
import numpy as np
import torch.backends.cudnn
from test_utils import draw_boxes
from torch.utils.tensorboard import SummaryWriter
import torchvision
import os
from utils import plot_grad
import cv2
import argparse
parser = argparse.ArgumentParser(description='arg parser')
parser.add_argument('--ckpt', type=str, default=None, help='pre_load_ckpt')
parser.add_argument('--index', type=int, default=None, help='hyper_tag')
parser.add_argument('--epoch', type=int , default=160, help="training epoch")
args = parser.parse_args()
def weights_init(m):
if isinstance(m, nn.Conv2d):
#调用torch.nn.init里面的初始化方法对权重和偏置进行初始化
init.xavier_normal_(m.weight.data)
m.bias.data.zero_()
def detection_collate(batch):
#这里的batch是自定义dataset里面__getitem__方法的返回值,batch里面有batch——size个样本
voxel_features = []
voxel_coords = []
gt_box3d_corner = []
gt_box3d = []
images = []
calibs = []
ids = []
for i, sample in enumerate(batch):
voxel_features.append(sample[0])
voxel_coords.append(
np.pad(sample[1], ((0, 0), (1, 0)),
mode='constant', constant_values=i))
gt_box3d_corner.append(sample[2])
gt_box3d.append(sample[3])
images.append(sample[4])
calibs.append(sample[5])
ids.append(sample[6])
return np.concatenate(voxel_features), \
np.concatenate(voxel_coords), \
gt_box3d_corner,\
gt_box3d,\
images,\
calibs, ids
torch.backends.cudnn.enabled=True
def train(net, model_name, hyper, cfg, writer, optimizer):
dataset=KittiDataset(cfg=cfg,root='/data/cxg1/VoxelNet_pro/Data',set='train')
#在创建DataLoader类的对象时,collate_fn函数会将batch_size个样本整理成一个batch样本,便于批量训练。
data_loader = data.DataLoader(dataset, batch_size=cfg.N, num_workers=4, collate_fn=detection_collate, shuffle=True, \
pin_memory=False)
# 网络设为train模式,可以不断更新权重
net.train()
# define optimizer
# define loss function
criterion = VoxelLoss(alpha=hyper['alpha'], beta=hyper['beta'], gamma=hyper['gamma'])
running_loss = 0.0
running_reg_loss = 0.0
running_conf_loss = 0.0
# training process
# batch_iterator = None
#有几个epoch
epoch_size = len(dataset) // cfg.N
print('Epoch size', epoch_size)
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[round(args.epoch*x) for x in (0.7, 0.9)], gamma=0.1)
scheduler.last_epoch = cfg.last_epoch + 1
optimizer.zero_grad()
epoch = cfg.last_epoch
while epoch < args.epoch :
iteration = 0
for voxel_features, voxel_coords, gt_box3d_corner, gt_box3d, images, calibs, ids in data_loader:
# voxel_features[B,N1,35,7],非空体素每个有35个点,其余voxel_coords[B,N1,3],每个非空体素的xyz位置用于还原回来用
# wrapper to variable
voxel_features = torch.tensor(voxel_features).to(cfg.device)
# 正样本框
pos_equal_one = []
# 负样本框
neg_equal_one = []
# 正样本框相对于gt的偏移量
targets = []
with torch.no_grad():
for i in range(len(gt_box3d)):
pos_equal_one_, neg_equal_one_, targets_ = dataset.cal_target(gt_box3d_corner[i], gt_box3d[i], cfg)
pos_equal_one.append(pos_equal_one_)
neg_equal_one.append(neg_equal_one_)
targets.append(targets_)
#对张量进行扩维拼接(B,H,W,2)
pos_equal_one = torch.stack(pos_equal_one, dim=0)
#(B,H,W,2)
neg_equal_one = torch.stack(neg_equal_one, dim=0)
#(B,H,W,14)
targets = torch.stack(targets, dim=0)
# zero the parameter gradients
# forward
# 体素特征和体素的对应网格坐标一起送入网络
score, reg = net(voxel_features, voxel_coords)
# calculate loss
conf_loss, reg_loss, _, _, _ = criterion(reg, score, pos_equal_one, neg_equal_one, targets)
loss = hyper['lambda'] * conf_loss + reg_loss
running_conf_loss += conf_loss.item()
running_reg_loss += reg_loss.item()
running_loss += (reg_loss.item() + conf_loss.item())
# backward
loss.backward()
# visualize gradient
if iteration == 0 and epoch % 30 == 0:
plot_grad(net.svfe.vfe_1.fcn.linear.weight.grad.view(-1), epoch, "vfe_1_grad_%d"%(epoch))
plot_grad(net.svfe.vfe_2.fcn.linear.weight.grad.view(-1), epoch,"vfe_2_grad_%d"%(epoch))
plot_grad(net.cml.conv3d_1.conv.weight.grad.view(-1), epoch,"conv3d_1_grad_%d"%(epoch))
plot_grad(net.rpn.reg_head.conv.weight.grad.view(-1), epoch,"reghead_grad_%d"%(epoch))
plot_grad(net.rpn.score_head.conv.weight.grad.view(-1), epoch,"scorehead_grad_%d"%(epoch))
# update
if iteration%10 == 9:
for param in net.parameters():
param.grad /= 10
optimizer.step()
optimizer.zero_grad()
if iteration % 50 == 49:
writer.add_scalar('total_loss', running_loss/50.0, epoch * epoch_size + iteration)
writer.add_scalar('reg_loss', running_reg_loss/50.0, epoch * epoch_size + iteration)
writer.add_scalar('conf_loss',running_conf_loss/50.0, epoch * epoch_size + iteration)
print("epoch : " + repr(epoch) + ' || iter ' + repr(iteration) + ' || Loss: %.4f || Loc Loss: %.4f || Conf Loss: %.4f' % \
( running_loss/50.0, running_reg_loss/50.0, running_conf_loss/50.0))
running_conf_loss = 0.0
running_loss = 0.0
running_reg_loss = 0.0
# visualization
if iteration == 2000:
reg_de = reg.detach()
score_de = score.detach()
with torch.no_grad():
pre_image = draw_boxes(reg_de, score_de, images, calibs, ids, 'pred')
gt_image = draw_boxes(targets.float(), pos_equal_one.float(), images, calibs, ids, 'true')
try :
writer.add_image("gt_image_box {}".format(epoch), gt_image, global_step=epoch * epoch_size + iteration, dataformats='NHWC')
writer.add_image("predict_image_box {}".format(epoch), pre_image, global_step=epoch * epoch_size + iteration, dataformats='NHWC')
except :
pass
iteration += 1
scheduler.step()
epoch += 1
if epoch % 30 == 0:
torch.save({
"epoch": epoch,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, os.path.join('./model', model_name+str(epoch)+'.pt'))
hyper = {'alpha': 1.0,
'beta': 10.0,
'pos': 0.75,
'neg': 0.5,
'lr':0.005,
'momentum': 0.9,
'lambda': 2.0,
'gamma':2,
'weight_decay':0.00001}
if __name__ == '__main__':
pre_model = args.ckpt
cfg.pos_threshold = hyper['pos']
cfg.neg_threshold = hyper['neg']
model_name = "model_%d"%(args.index+1)
## 构建TensorBoard,方便模型训练过程的可视化
writer = SummaryWriter('runs/%s'%(model_name[:-4]))
net = VoxelNet()
net.to(cfg.device)
optimizer = optim.SGD(net.parameters(), lr=hyper['lr'], momentum = hyper['momentum'], weight_decay=hyper['weight_decay'])
if pre_model is not None and os.path.exists(os.path.join('./model',pre_model)) :
ckpt = torch.load(os.path.join('./model',pre_model), map_location=cfg.device)
net.load_state_dict(ckpt['model_state_dict'])
cfg.last_epoch = ckpt['epoch']
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
else :
#如果没有预训练权重,直接初始化,运用apply()调用weight_init函数.
net.apply(weights_init)
train(net, model_name, hyper, cfg, writer, optimizer)
writer.close()
5.4 数据增强
import numpy as np
from config import config as cfg
import cv2
import matplotlib.pyplot as plt
def draw_polygon(img, box_corner, color = (255, 255, 255),thickness = 1):
tup0 = (box_corner[0, 1],box_corner[0, 0])
tup1 = (box_corner[1, 1],box_corner[1, 0])
tup2 = (box_corner[2, 1],box_corner[2, 0])
tup3 = (box_corner[3, 1],box_corner[3, 0])
cv2.line(img, tup0, tup1, color, thickness, cv2.LINE_AA)
cv2.line(img, tup1, tup2, color, thickness, cv2.LINE_AA)
cv2.line(img, tup2, tup3, color, thickness, cv2.LINE_AA)
cv2.line(img, tup3, tup0, color, thickness, cv2.LINE_AA)
return img
def point_transform(points, tx, ty, tz, rx=0, ry=0, rz=0):
# Input:
# points: (N, 3)
# rx/y/z: in radians
# Output:
# points: (N, 3)
N = points.shape[0]
points = np.hstack([points, np.ones((N, 1))])
mat1 = np.eye(4)
mat1[3, 0:3] = tx, ty, tz
points = np.matmul(points, mat1)
if rx != 0:
mat = np.zeros((4, 4))
mat[0, 0] = 1
mat[3, 3] = 1
mat[1, 1] = np.cos(rx)
mat[1, 2] = -np.sin(rx)
mat[2, 1] = np.sin(rx)
mat[2, 2] = np.cos(rx)
points = np.matmul(points, mat)
if ry != 0:
mat = np.zeros((4, 4))
mat[1, 1] = 1
mat[3, 3] = 1
mat[0, 0] = np.cos(ry)
mat[0, 2] = np.sin(ry)
mat[2, 0] = -np.sin(ry)
mat[2, 2] = np.cos(ry)
points = np.matmul(points, mat)
if rz != 0:
mat = np.zeros((4, 4))
mat[2, 2] = 1
mat[3, 3] = 1
mat[0, 0] = np.cos(rz)
mat[0, 1] = -np.sin(rz)
mat[1, 0] = np.sin(rz)
mat[1, 1] = np.cos(rz)
points = np.matmul(points, mat)
return points[:, 0:3]
def box_transform(boxes_corner, tx, ty, tz, r=0):
# boxes_corner (N, 8, 3)
for idx in range(len(boxes_corner)):
boxes_corner[idx] = point_transform(boxes_corner[idx], tx, ty, tz, rz=r)
return boxes_corner
def cal_iou2d(box1_corner, box2_corner):
box1_corner = np.reshape(box1_corner, [4, 2])
box2_corner = np.reshape(box2_corner, [4, 2])
box1_corner = ((cfg.W, cfg.H)-(box1_corner - (cfg.xrange[0], cfg.yrange[0])) / (cfg.vw, cfg.vh)).astype(np.int32)
box2_corner = ((cfg.W, cfg.H)-(box2_corner - (cfg.xrange[0], cfg.yrange[0])) / (cfg.vw, cfg.vh)).astype(np.int32)
buf1 = np.zeros((cfg.H, cfg.W, 3))
buf2 = np.zeros((cfg.H, cfg.W, 3))
buf1 = cv2.fillConvexPoly(buf1, box1_corner, color=(1,1,1))[..., 0]
buf2 = cv2.fillConvexPoly(buf2, box2_corner, color=(1,1,1))[..., 0]
indiv = np.sum(np.absolute(buf1-buf2))
share = np.sum((buf1 + buf2) == 2)
if indiv == 0:
return 0.0 # when target is out of bound
return share / (indiv + share)
def aug_data(lidar, gt_box3d_corner):
np.random.seed()
choice = np.random.randint(1, 10)
if choice >= 7:
for idx in range(len(gt_box3d_corner)):
# TODO: precisely gather the point
is_collision = True
_count = 0
while is_collision and _count < 100:
t_rz = np.random.uniform(-np.pi / 10, np.pi / 10)
t_x = np.random.normal()
t_y = np.random.normal()
t_z = np.random.normal()
# check collision
tmp = box_transform(
gt_box3d_corner[[idx]], t_x, t_y, t_z, t_rz)
is_collision = False
for idy in range(idx):
iou = cal_iou2d(tmp[0,:4,:2],gt_box3d_corner[idy,:4,:2])
if iou > 0:
is_collision = True
_count += 1
break
if not is_collision:
box_corner = gt_box3d_corner[idx]
minx = np.min(box_corner[:, 0])
miny = np.min(box_corner[:, 1])
minz = np.min(box_corner[:, 2])
maxx = np.max(box_corner[:, 0])
maxy = np.max(box_corner[:, 1])
maxz = np.max(box_corner[:, 2])
bound_x = np.logical_and(
lidar[:, 0] >= minx, lidar[:, 0] <= maxx)
bound_y = np.logical_and(
lidar[:, 1] >= miny, lidar[:, 1] <= maxy)
bound_z = np.logical_and(
lidar[:, 2] >= minz, lidar[:, 2] <= maxz)
bound_box = np.logical_and(
np.logical_and(bound_x, bound_y), bound_z)
lidar[bound_box, 0:3] = point_transform(
lidar[bound_box, 0:3], t_x, t_y, t_z, rz=t_rz)
gt_box3d_corner[idx] = box_transform(
gt_box3d_corner[[idx]], t_x, t_y, t_z, t_rz)
gt_box3d = gt_box3d_corner
elif choice < 7 and choice >= 4:
# global rotation
angle = np.random.uniform(-np.pi / 4, np.pi / 4)
lidar[:, 0:3] = point_transform(lidar[:, 0:3], 0, 0, 0, rz=angle)
gt_box3d = box_transform(gt_box3d_corner, 0, 0, 0, r=angle)
else:
# global scaling
factor = np.random.uniform(0.95, 1.05)
lidar[:, 0:3] = lidar[:, 0:3] * factor
gt_box3d = gt_box3d_corner * factor
return lidar, gt_box3d

















 9234
9234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











