







 本文探讨数据敏感度在数据分析中的核心价值,指出缺乏敏感度的后果,并提供了通过理解指标定义、业务沟通和主动思考来培养数据敏感度的方法。
本文探讨数据敏感度在数据分析中的核心价值,指出缺乏敏感度的后果,并提供了通过理解指标定义、业务沟通和主动思考来培养数据敏感度的方法。
目前在数据从业者的招聘职责中都会有一项要求——对数据敏感。
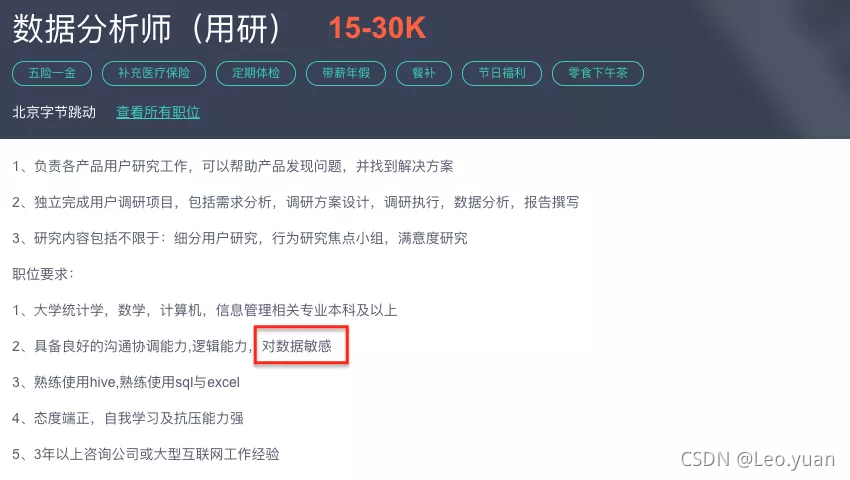
今天我们一起来聊聊数据敏感度到底是啥?数据分析师缺乏数据敏感度会怎样?数据敏感度这个东西该怎么培养?
1、数据敏感度到底是啥
讨论中,大家对于这个问题的答案基本趋于一致。
数据敏感度强,意味着对业务更熟悉;
有数据敏感度的分析师,可以将感觉拆解为可操作可执行的步骤;
看到数据指标能够了解其业务含义,能够发现数据中的异常值,知道一个数代表着“是好是坏”,“是高是低”,是否反映了业务中的某些问题
那么在定义数据敏感度到底是什么之前,我们先一起看看下面这些生活中常见的例子:
人类正常的体温在36°-37°之间,但是小明此时体温达到了38.5°;
25岁168cm的女性参考体重为55公斤,同样年龄身高的小红体重却达到了80公斤;
从上面这两个生活中的例子,你很快能想到:小明好像发烧了;小红的体重有些不健康。这种能将数字指标与实际生活之间的关联起来的能力就是数据敏感度。
类比到工作中,当看到一组业务数字的时候,我们能迅速根据已有数据结合标准判断业务状态是否正常并且能感知到指标细微变化的不同意义,就是拥有数据敏感度的体现。比如体温从36°变到36.5°可能属于正常范围。但是从37°到37.5°可能就是异常体温了。虽然变化值一样,但基于不同的情况所反映的最终结果却不同。那么在工作中也是一样,用户留存率降了5%,到底是不是正常范围内的波动,需不需要出策略进行干预?能迅速对此作出反应,是一个合格分析师的必备技能。
2、缺乏数据敏感度会怎么样
数据敏感度是基于对工作中数据指标的熟悉以及对业务的掌握所形成的。那么对于一名数据分析师而言缺乏敏感度会怎么样呢?没有数据敏感度的数据分析师,就像没有任何医学知识的医生一样。
你试想上例中的小明,去找医生看病。医生告诉他,正常人的温度是36°-37°之间,你已经38.5°了这是发热了回去吃药吧。小明绝对会认为这医生是个庸医。因为是个正常人都知道小明发热了,要吃药。但是小明想知道的是:为什么我突然发热了?我想退热应该吃什么药?如何避免以后在突然发热?
当然这个例子看着有些不可思议。但是,你细想下身边是不是有这样的分析师。数据下降了,他告诉你:指标平时是x,今天突然变成了y。环比变化了z,这是异常值。要赶紧出个方案解决。业务就跟小明一样,心里想着:公司从哪里招来这个人的?显然业务想知道的是:为什么指标平时是x,今天是y?哪些因素导致的?目前这个指标异常能解决吗?如果能,应该怎么解决?如何在以后避免这种指标异常波动?
所以,我们能够发现缺乏数据敏感度的分析师,通常有以下特征:
无法发现关键指标的异常状态
缺乏数据敏感度的分析师无法敏锐的对日常数据变化产生洞察。
比如:我们app的次日留存率为25%,有数据敏感性的分析师很快能判断出这个指标相比较于以往是高了还是低了?如果对数据指标的不熟悉,那么没有数据敏感性的分析师可能对这个指标毫无感觉。
无法还原指标变化所对应的业务场景
缺乏数据敏感度的数据分析师无法将数据指标的波动与真实业务场景关联起来。比如:体检的时候的各个指标,根据检查单我们可以知道各个指标是否在正常的范围内。但是如果指标有波动的话,我们无法确认这个波动是否正常?反映了我们身体存在什么问题?这正是因为我们缺乏医疗行业的业务知识和数据敏感度。
无法挖掘业务间的内在数据联系
对于企业而言,指标与指标、业务与业务之间绝不是相互独立的而是相辅相成、相互依赖的。对于缺乏数据敏感度的分析师很难发现其间的数据联系。比如:今天的退款非常多,我们会去做的第一件事情可能是去察看营销部门的数据,我看到今天UV猛增,所以退款才特别多,这是可能合理的。但是,我从客服数据中发现一些退款是少量的卖家产生出来的,那就另当别论了,因为这说明这个商业场景也有可能是作弊,此时就需要对营销、客服和风控等多组数据综合起来进行解释。
3、如何培养数据敏感度
数据方面
了解指标定义,理清指标关系,常与标准作对比——我们可以在有新业务时,尝试自己设计指标体系。指标体系可以把你从局部的点拉升到整体的面上,这样就能更深刻的理解到指标之间的相互联系。最常见的标准就是部门的KPI,如果某个指标没有定KPI,也可以跟竞品或同行业的数据标准对齐。
多看数据报表,积累感觉——可以定期的总结自己所负责业务的数据特性,了解指标存在的趋势性。这点类似于我们以前上学的时候,英语老师让我们多读文章积累语感。
对待数据波动多思考,推断业务发展状态——对待数据指标波动,不能单维度考量。就算小的数据波动也可以考虑有哪些因素可能会影响数据,多思考指标之间的关系,业务之间的关联性。
业务方面
与业务方多沟通、多交流——有条件可以参加业务方的组会,让他们抄份周报给你。保持多听,多问。
遇到不理解的问题及时问为什么,为什么我们主要监控的是A指标,不是B指标。为什么有的指标波动的很大,但是业务同学一点也不着急。很多同学不愿意问别人,就会想:哎呀这个问题会不会太简单,我问了别人会不会觉得我水平很低之类这样的想法。这种想法大可不必,术业有专攻而已。反正我们的目标都是为了让业务发展的更好。当然提问也是一门艺术,有兴趣的同学可以了解下“5 why分析法”。
把自己放在主动位上——有的时候心态也会影响我们对工作的态度。不要局限于自己数据分析师的工作。如果你给自己的定位就是数据支撑,那从一开始的定位就错了。我们可以适当的脱离数据,将自己放在业务的位置上,想一想如果要完成业务的KPI有哪些资源可以调用。这个时候再结合数据,看看我们用数据能否发现其中的隐藏点,从而获得业务上的突破。
源:数据有聊

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









