







随机森林算法(Random Forest,简称RF)在时间序列预测中可以应用于两种情况:回归问题和分类问题。
在时间序列回归预测中,可以使用随机森林算法进行预测。基于随机森林的时间序列预测步骤如下:
1. 数据准备:将时间序列数据转化为具有输入和输出特征的训练样本。类似于其他机器学习算法,需要将时间序列数据进行特征工程,提取合适的特征。
2. 构建随机森林:随机森林由多个决策树组成,每个决策树都在随机选择的样本和特征子集上进行拟合。构建随机森林时,可以选择树的数量和树的深度等参数。
3. 训练模型:使用训练数据对随机森林进行训练。每个决策树都会学习对应的子样本和特征子集,并生成预测模型。
4. 预测结果:将测试数据输入到每个决策树中,得到每个决策树的预测结果。对于回归问题,可以使用决策树的平均值作为最终的预测结果。
在时间序列分类预测中,同样可以使用随机森林算法进行预测。基本步骤与基于回归的预测类似,只是在训练模型时使用的样本和特征可能有所不同。另外,在预测结果时,可以通过投票或概率平均等方法,根据决策树的投票结果来确定最终的类别预测。
需要注意的是,随机森林算法在处理时间序列预测时可能存在一些挑战,例如处理序列相关性和变化的趋势等问题。因此,在应用随机森林进行时间序列预测时,可能需要结合一些时间序列特定的方法,如滞后观察、滑动窗口等,以帮助提高预测性能。另外,对于周期性和季节性趋势明显的时间序列,可以考虑使用具有时间序列特性的算法,如季节性随机森林等。
代码效果见:
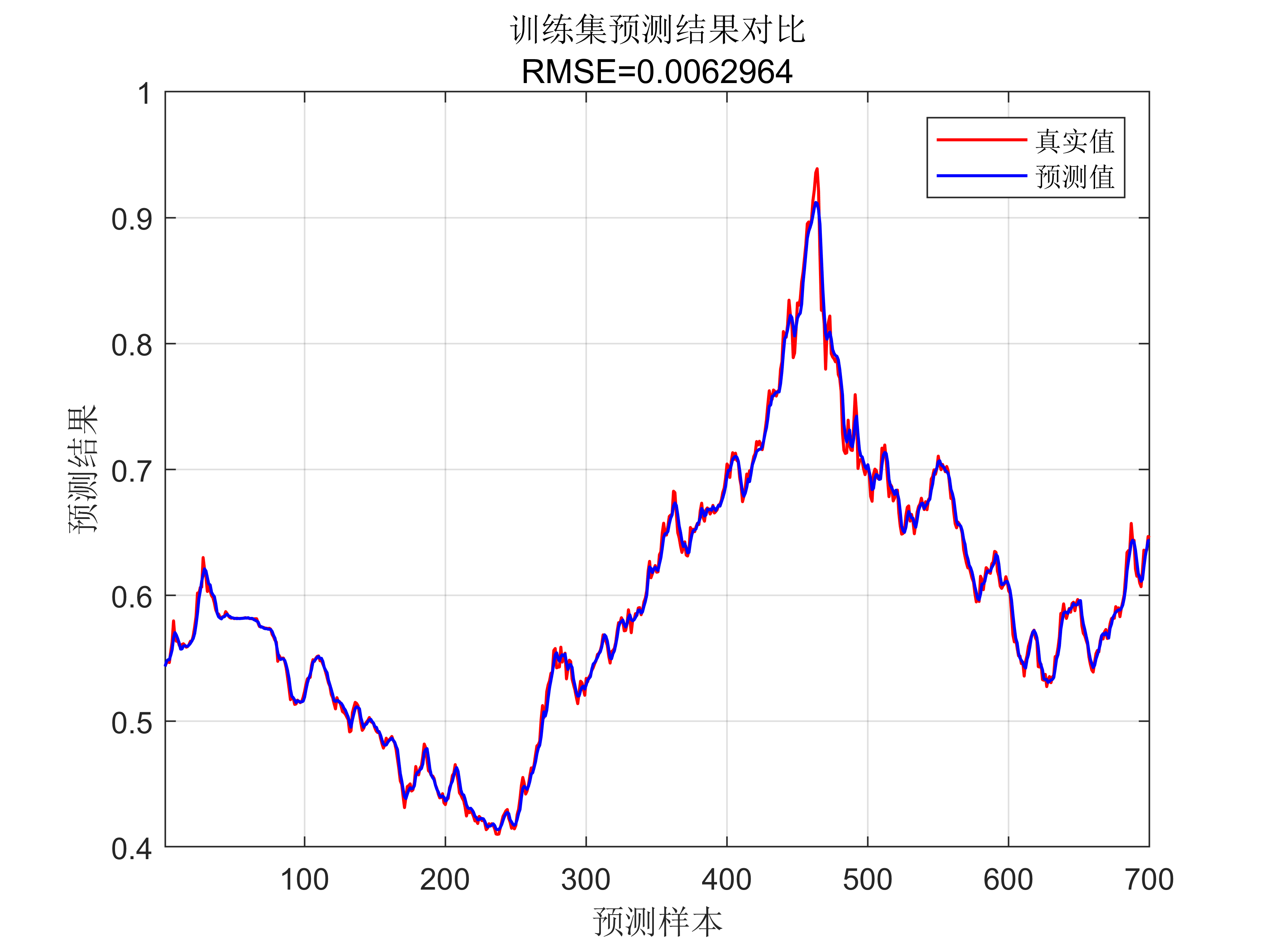
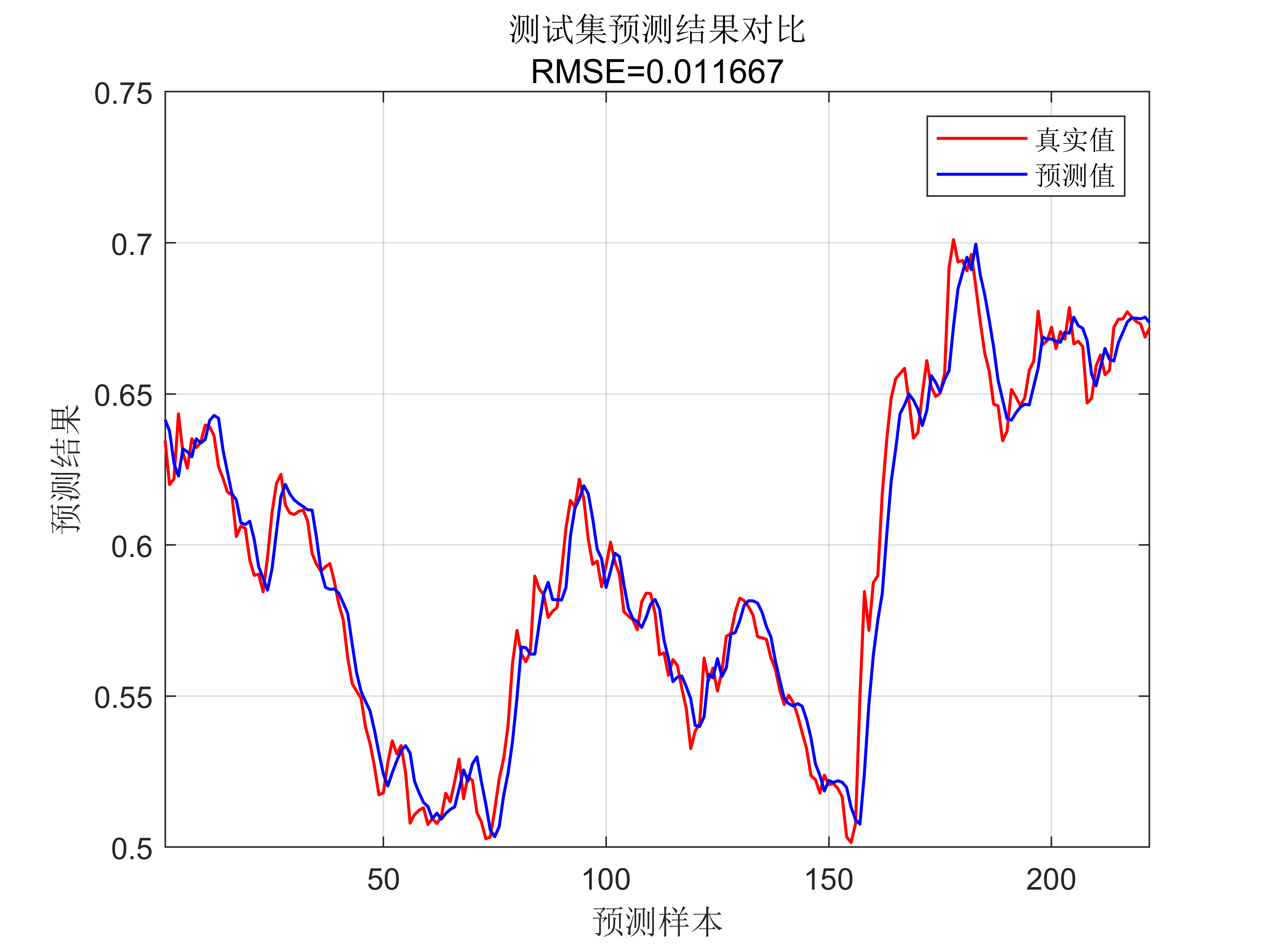
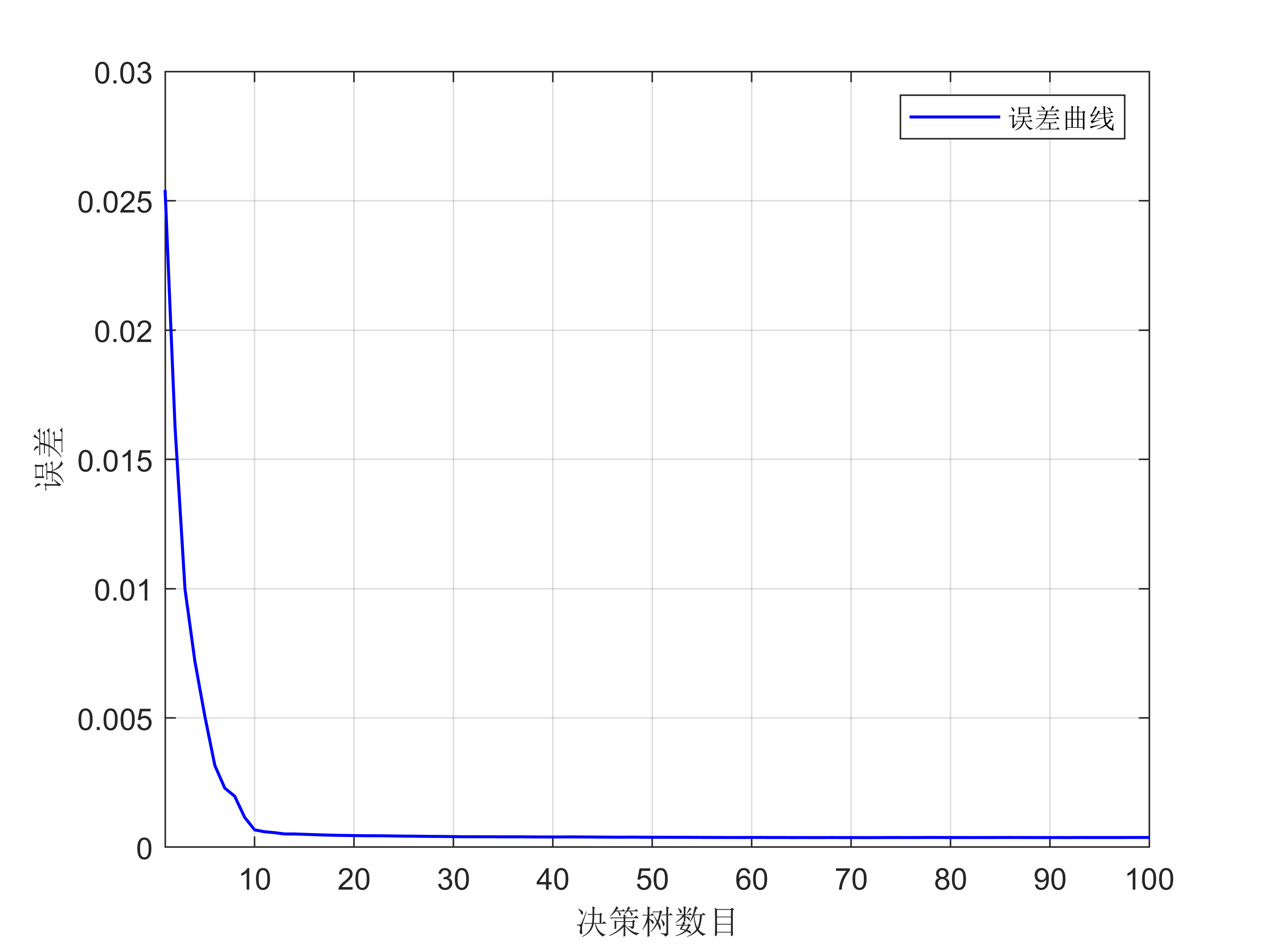
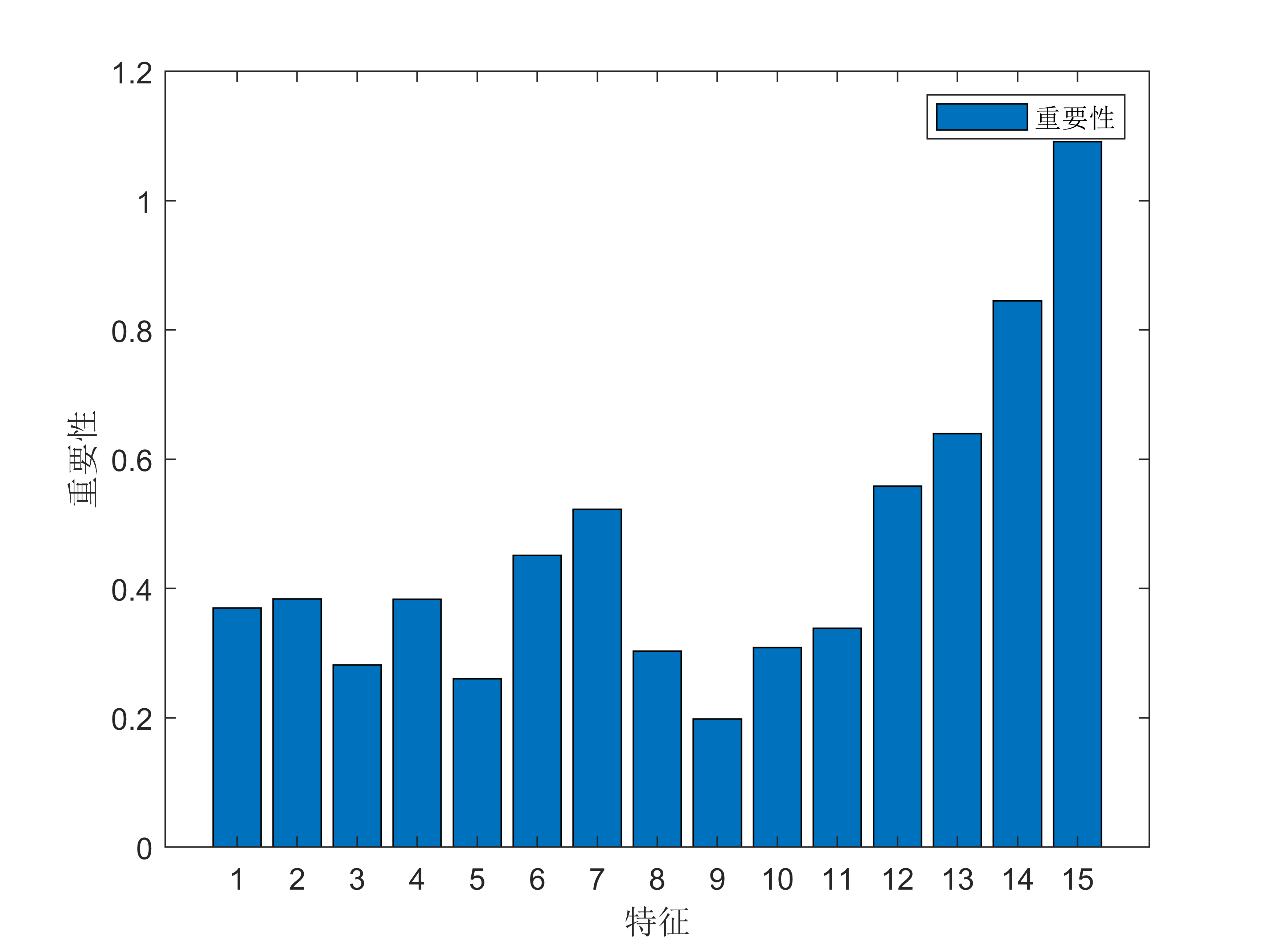
获取代码请关注MATLAB科研小白的个人公众号(即文章下方二维码),公众号致力于解决找代码难,写代码怵。各位有什么急需的代码,欢迎后台留言~不定时更新科研技巧类推文,可以一起探讨科研,写作,文献,代码等诸多学术问题,我们一起进步。


















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











