







1. 前言
GAN(Generative Adversarial Networks),是生成对抗网络于2014年由Ian Good fellow在他的论文Generative Adversarial Nets提出。
在GAN被提出之后,立刻在机器学习领域得到了巨大反响,并且被科学工作者们应用在许多领域,且取得了令人印象深刻的成果。在2016NIPS会议上,Goodfellow对GAN做了一次长达2个小时的报告,将GAN的原理,训练tips,以及一些影响比较大的GAN变体等等综合在一起,信息量比较大。
2. 参考资料
3. 研究背景
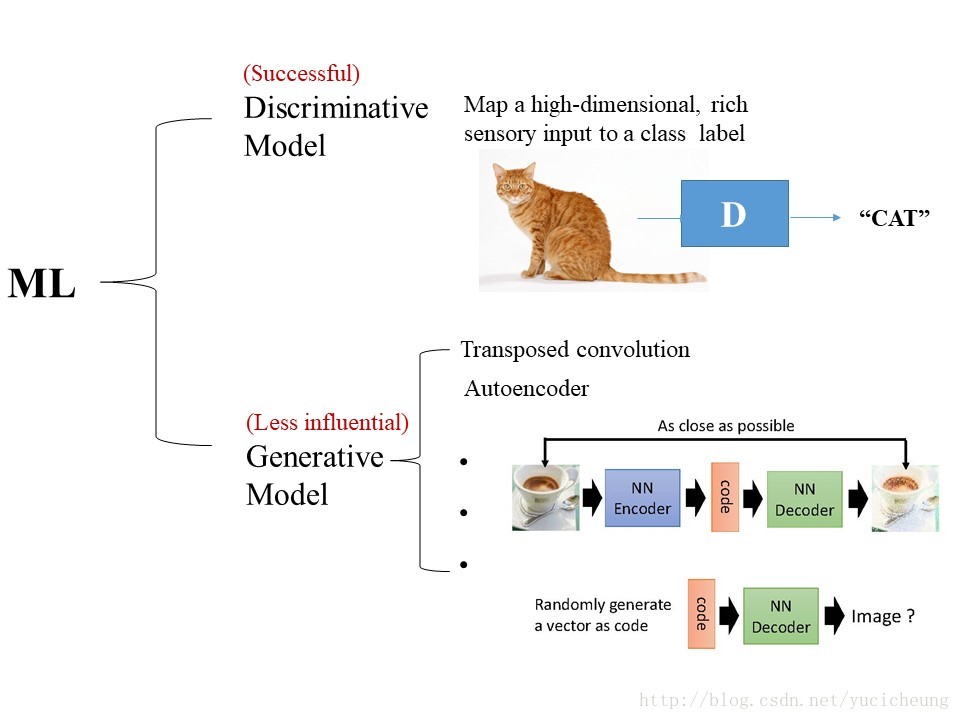
其实在机器学习中主要分为两类模型:
1. 判别模型(Discriminative model)
实现高维的、人可以感知的信息(如声音、图片等)到一个标签(可以是语义,类别)的映射,如上图,我们向判别模型输入一张猫的图片,就能输出”cat”的标签。
2. 生成模型(Generative model)
学习的是真实数据的概率分布,并且模拟真实数据的生成。对大家来说可能较为常见的例子就是自动编码器(Autoencoder)和反卷积(Transposed convolution),对这两者我稍微解释一下。
- 自动编码器:见上图,自动编码器分为encoder(编码器)和decoder(解码器)。将图片输入自动编码器时,编码器首先对图像进行编码,然后通过解码器恢复成原图。在整个网络训练好以后,如果我们将编码器去掉,留下从code通过解码器的一个结构,那这个就是生成真实数据的过程,因此code通过decoder这部分结构这属于一种生成模型。
- 反卷积:卷积实际上会对图片进行下采样,而反卷积的过程会对图像进行上采样,这个上采样的过程也是一种生成的过程,因此也属于生成模型。在讨论的时候,学长提到反卷积可以被归为自动编码器,因为卷积和反卷积的kernel是互为转置的关系,与解码器与编码器之间的关系一致,但是我表示不同意啦,因为在训练时,自动编码器的编码器和解码器是一起训练的,但是反卷积的核是利用训练好的卷积核进行变换的,即不是联合训练得到的。(Update:17.9.14,还没研究过反卷积,日后可能需要修改。)

生成模型的任务是学习概率密度并且生成数据,但在求解真实数据的概率密度分布的过程中有很大难度,常用的方法有最大似然估计(Maximum likelihood estimation)等,要求解概率几乎无法进行。
而Goodfellow就想到一种超奇妙的方法,利用判别网络(D)和生成网络(G)两个网络一起训练,成功绕开以上的难点,模拟真实数据的生成。
4. GAN的框架
论文提出了一个新的网络,通过一个对抗的过程来估计生成模型。在这个过程中会同时训练两个模型:一个生成模型 G G 用于估计数据分布,一个判别模型
来预测一个样本是来自训练集(真实数据集)而非 G G 的概率。对于
来说训练过程就是要使 D D 判断错误的可能性最大化。
形象一点说,生成模型
是一个造假币的人,而辨别模型 D D 是一个鉴别真假币的人,
的目标是造出能够以假乱真的假币,而 D D 的目标是正确判别真假,俩人最开始都是新手,
鉴别能力如果变强,则 G G 的造假能力也必须变强才能蒙蔽
的双眼; G G 造假能力变强之后,
也必须提高自己的鉴别能力才能做一个合格的鉴别师。于是 D D 和
在相互博弈的过程当中不断提高各自的能力,理论上来说,最终 G G 则能够造出接近和真币一样的假币。
4.1 对抗框架(Adeversarial Nets)
将这个框架应用到图像生成上,就有了下面这个框架:
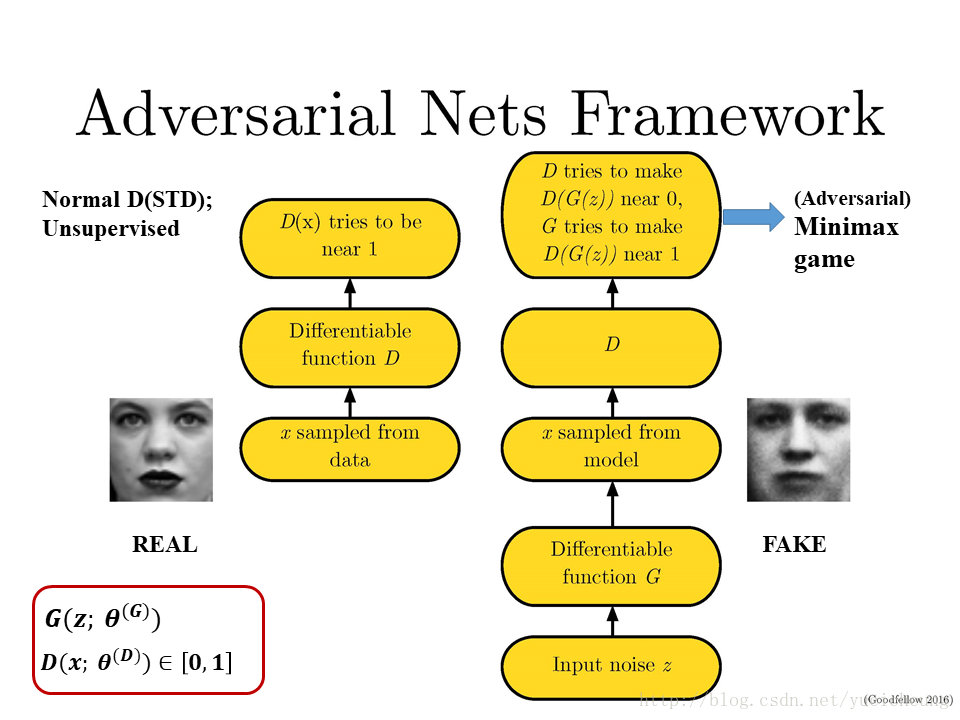
同样,框架中涉及到两个网络
和 D
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









