









Abstract
本文贡献:
提出GAN:
生成模型 G ,生成模型用来捕获数据的分布;
辨别模型 D ,辨别模型用来判断样本是来自于训练数据还是生成模型生成的。
在任意函数空间里,存在唯一解,G 能找出训练数据的真实分布,而 D 的预测概率为 1 2 \frac{1}{2} 21 。
结果:
该框架是可行的。
1. Introduction
生成模型问题:在最大似然估计时会遇到很多棘手的近似概率计算。
对抗网络:生成模型与判别模型相比较,学习确定样本是来自模型分布还是来自数据分布。
生成模型可以通过多层感知机来实现,输入为一些随机噪声,可以通过反向传播来训练。
2. Related work
- Boltzmann machine(玻尔兹曼机):似然函数难以处理,需要多次近似
- Generative stochastic networks(生成式随机网络):用精确的反向传播进行训练
- Markov chains(马尔可夫链):本文通过消除生成随机网络中的马尔可夫链,扩展了生成模型的概念
- variational autoencoders(VAE,变分自编码器):将可微生成网络与执行近似推理的识别模型配对
- Noise-contrastive estimation(NCE,噪声对比估计):通过学习权重来训练生成模型,使该模型有助于区分固定噪声分布中的数据,其“判别器”是由噪声分布和模型分布的概率密度之比定义
- Predictability Minimization(PM,可预测性最小化)
3. Adversarial nets
目标函数:
min
G
max
D
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
(
x
)
[
log
D
(
x
)
]
+
E
z
∼
p
z
(
z
)
[
log
(
1
−
D
(
G
(
z
)
)
)
]
(1)
\min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)} [\log D(x)] + \mathbb{E}_{z \sim p_z(z)} [\log(1 - D(G(z)))] \tag{1}
GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))](1)
p p p :先验分布(Prior Distribution),在机器学习中,尤其是在生成对抗网络(GANs)、变分自编码器(VAEs)等模型中,先验分布通常用来表示生成模型中隐藏变量(例如噪声向量或潜在变量)的分布。在 GAN 中,生成器从先验分布 p z ( z ) p_z(z) pz(z) 中采样输入(通常是高斯分布或均匀分布的随机噪声),并试图通过生成网络将这些样本映射为类似于真实数据的样本。先验分布可以看作是在没有观察到数据之前的假设,它为后续的数据更新提供了基础。
同时训练生成模型 G 和判别模型 D 。
对于判别模型 D ,通过最大化将正确标签分配给训练样本和生成器生成样本的概率来训练;
对于生成模型 G ,通过最小化
log
(
1
−
D
(
G
(
z
)
)
)
\log (1-D(G(\boldsymbol{z})))
log(1−D(G(z))) 来训练,总结为:
- D ( x ) D(x) D(x) 概率越大,判别器训练越好, log D ( x ) \log D(\boldsymbol{x}) logD(x) 越大;
- D ( G ( z ) ) D(G(\boldsymbol{z})) D(G(z)) 概率越小,判别器训练越好, log ( 1 − D ( G ( z ) ) ) \log (1-D(G(\boldsymbol{z}))) log(1−D(G(z))) 越大;
- D ( G ( z ) ) D(G(\boldsymbol{z})) D(G(z)) 概率越大,生成器训练越好, log ( 1 − D ( G ( z ) ) ) \log (1-D(G(\boldsymbol{z}))) log(1−D(G(z))) 越小;
公式(1)往往不能提供足够的梯度让生成器去学习。因为在学习的早期阶段,生成器 G 性能很差,判别器 D 有着很高的置信度判别数据来源。
在这种情况,
log
(
1
−
D
(
G
(
z
)
)
)
\log (1-D(G(\boldsymbol{z})))
log(1−D(G(z))) 存在饱和现象。因此在这个时候,通过最大化
log
D
(
G
(
z
)
)
\log D(G(\boldsymbol{z}))
logD(G(z)) 来训练生成器 G 。
4. Theoretical Results
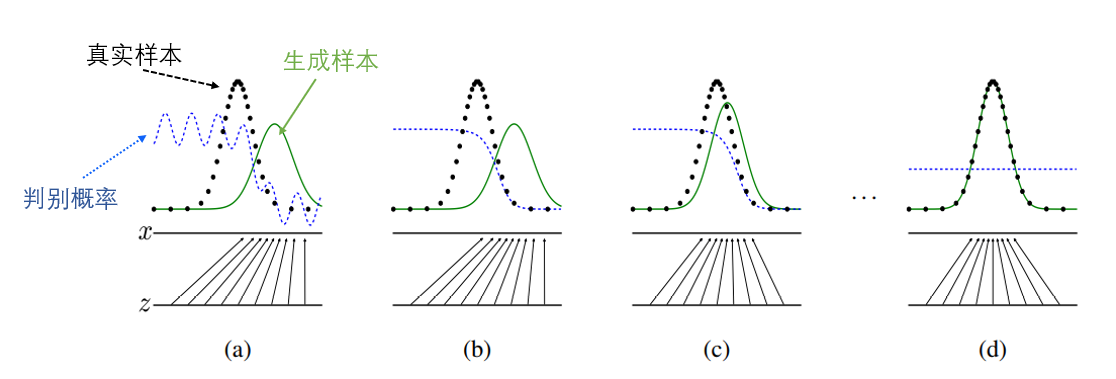
在 (a) 阶段,真实样本和生成样本分布不一致,此时判别器能够正确区分真实样本和生成样本。到 (d) 阶段,真实样本和生成样本分布几乎一致,此时判别器很难再区分二者,此时判别器输出概率为
1
2
\frac{1}{2}
21 。
判别概率:判别器预测x为真实数据的概率。
伪代码:

对于判别器,通过梯度上升来训练;对于生成器,通过梯度下降来训练。
4.1 Global Optimality of p g = p d a t a p_g = p_{data} pg=pdata
对于任意给定的生成器 G ,则最优的判别器 D 为
D
∗
(
x
)
=
p
data
(
x
)
p
data
(
x
)
+
p
g
(
x
)
D^*(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)}
D∗(x)=pdata(x)+pg(x)pdata(x)
- 当 p d a t a ( x ) p_{data}(x) pdata(x) 很大,且 p g ( x ) p_g(x) pg(x) 很小(即数据来自真实分布的概率远高于来自生成器的概率),那么 D ∗ ( x ) ≈ 1 D^*(x) \approx 1 D∗(x)≈1,表示判别器认为该数据几乎是100%来自真实数据。
- 当 p g ( x ) p_g(x) pg(x) 很大,且 p d a t a ( x ) p_{data}(x) pdata(x) 很小(即数据更可能来自生成器),则 D ∗ ( x ) ≈ 0 D^*(x) \approx 0 D∗(x)≈0,表示判别器认为该数据几乎是100%来自生成器。
经过证明,当且仅当 p g = p d a t a p_g=p_{data} pg=pdata 时,达到虚拟训练准则C(G)的全局最小值。此时,C(G)达到值,最大期望值 − log 4 -\log4 −log4 。
4.2 Convergence of Algorithm 1
如果 G 和 D 有足够的容量,在算法1的每一步,允许判别器达到给定 G 的最优值,并且更新 p g p_g pg 以改进准则,然后 p g p_g pg 收敛到 p d a t a p_{data} pdata 。
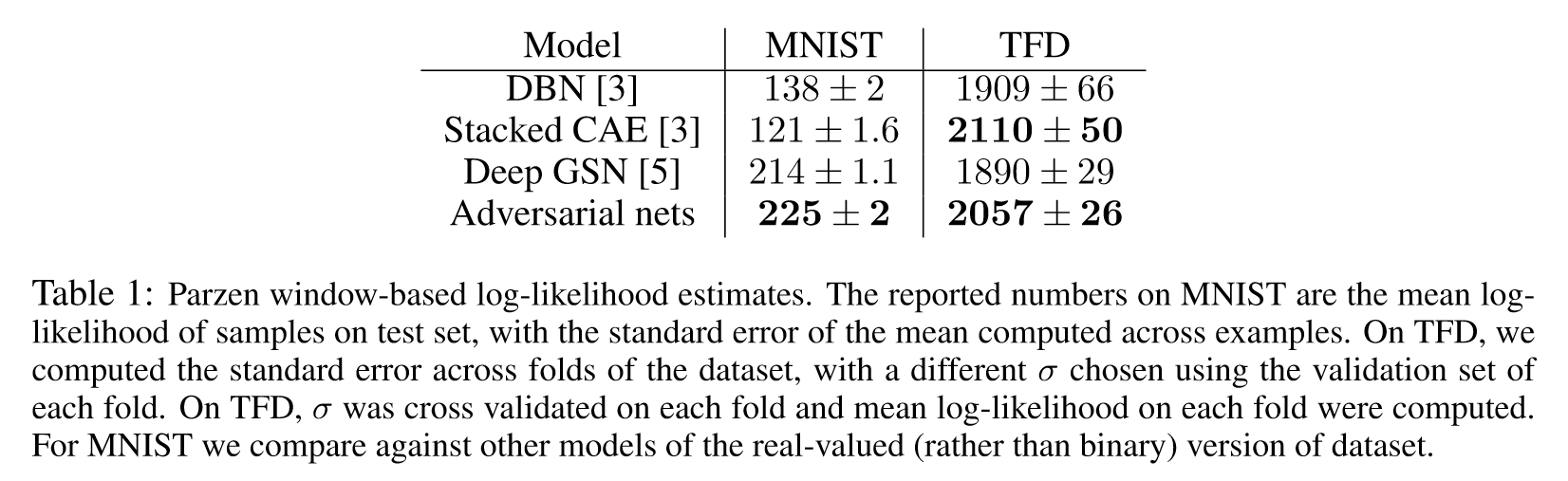
5. Experiments
6. Advantages and disadvantages
缺点:没有真正的拟合出原始数据的概率分布;必须进行同步的训练。
优点:不需要马尔可夫链,只需要进行反向传播可以进行训练,可以将多种优化函数合并到模型中。生成器不是直接用原始数据来进行训练,而通过欺骗判别器来进行训练,这种方式阻碍了过拟合的产生。可以表示非常尖锐甚至退化的分布。
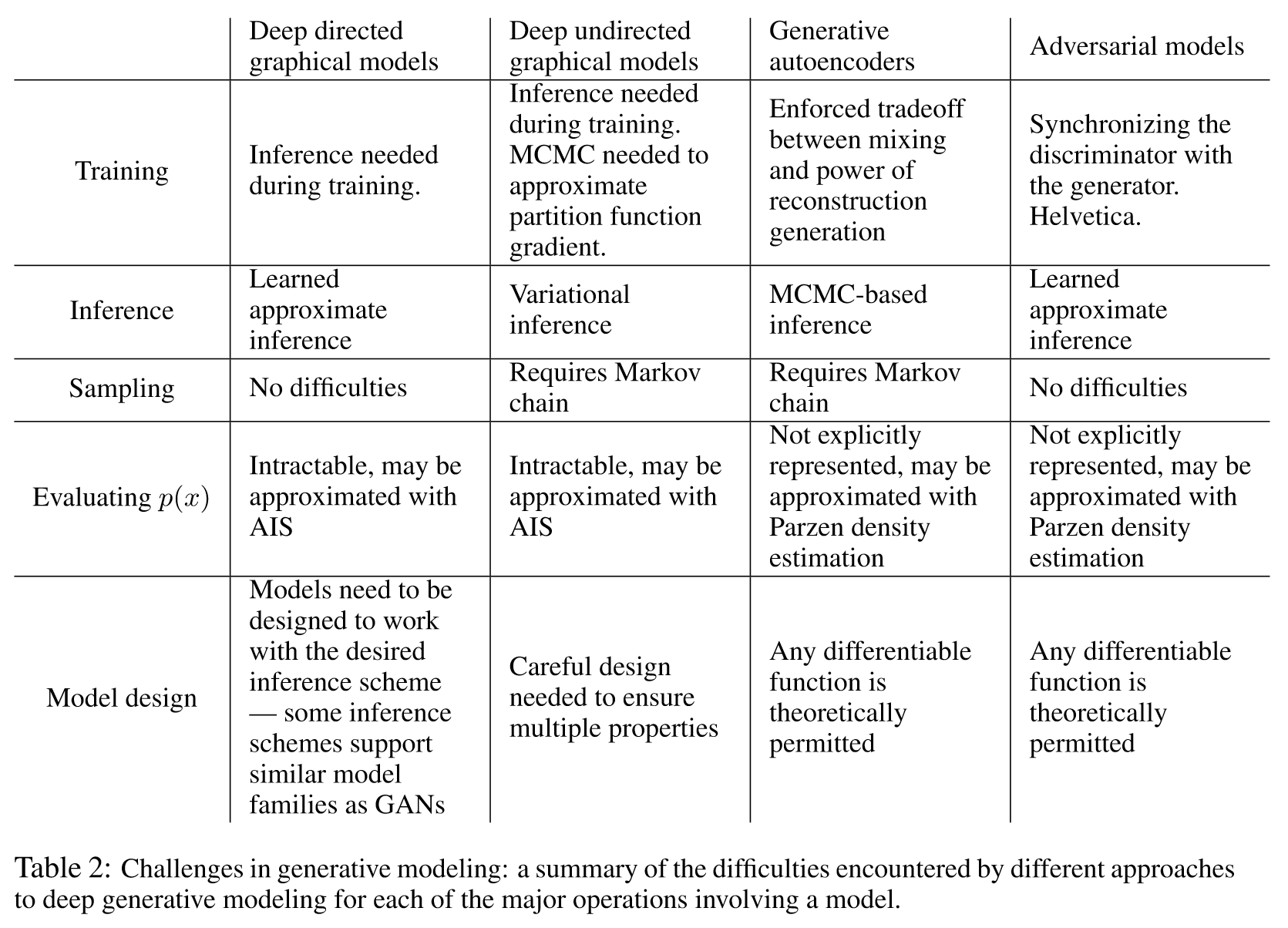
GAN与其他生成方法比较:
7. Conclusions and future work
该框架允许许多扩展:
- CGAN
- 学习近似推理
- 图像填充和超分辨率
- 半监督学习
- 效率提高
参考资料
重读经典:《Generative Adversarial Nets》
深度学习之生成对抗网络GAN(一)Generative Adversarial Nets/生成对抗网络(一)















 2456
2456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









