







 本文档详细介绍了DirectX12的初始化,包括Direct3D 12的概述、COM对象、资源、交换链、深度缓冲、命令队列、GPU交互、资源同步等关键概念。同时,它探讨了渲染管线、命令列表、多线程渲染、光栅化阶段、渲染管线对象(PSO)等核心内容,展示了如何在Direct3D中进行图形绘制,涉及了Constant Buffer的创建与更新、Shader的编译和加载。
本文档详细介绍了DirectX12的初始化,包括Direct3D 12的概述、COM对象、资源、交换链、深度缓冲、命令队列、GPU交互、资源同步等关键概念。同时,它探讨了渲染管线、命令列表、多线程渲染、光栅化阶段、渲染管线对象(PSO)等核心内容,展示了如何在Direct3D中进行图形绘制,涉及了Constant Buffer的创建与更新、Shader的编译和加载。
目录
- 资源
- 第四章 Direct3D初始化
- 第五章 渲染管线
- 第六章 在Direct3D中绘制
- 第七章 在Direct3D中绘制(二)
资源
第四章 Direct3D初始化
4.1 预备知识
4.1.1 Direct3D 12 总述
- 更底层
- 更少抽象
- 更接近GPU架构
- 大大降低CPU开销
- 提升多线程支持
4.1.2 COM(Component Object Model)
- 从COM接口中得到COM对象,而不需要使用C++的new
- 释放COM对象需调用COM对象的Release方法,而不需要使用delete
- WRL(Windows Runtime Library)提供了COM对象的智能指针Microsoft::WRL::ComPtr,这样就不再需要调用Release
- 主要需要用到的ComPtr方法为
- Get():获得Object*指针
- GetAddressOf()
- Reset():指针设置为nullptr
4.1.3 纹理格式
- 纹理可以存储颜色,也可以存储其他更通用的信息,如深度、法向、高度等
- 纹理可以表示成1维数组、2维数组、3维数组等;它还可以有mipmap层级,从而实现滤波(filter)和多重采样(multisampling)
- 纹理仅能按特定的格式存储,它们在DXGI_FORMAT这一枚举类中呈现:
- DXGI_FORMAT_R32G32B32_FLOAT:每个元素包含3个32位float
- DXGI_FOTMAT_R16G16B16A16_UNORM:包含4个16位[0,1]之间的值
- DXGI_FORMAT_R32G32_UINT: 包含2个32位unsigned integer
- DXGI_FOTMAT_R8G8B8A8_UNORM:包含4个8位[0,1]之间的值
- DXGI_FOTMAT_R8G8B8A8_SNORM:包含4个8位[-1,1]之间的值
- DXGI_FOTMAT_R8G8B8A8_SINT:包含4个8位[-127,128]之间的integer
- DXGI_FOTMAT_R8G8B8A8_UINT:包含4个8位[0,255]之间的integer
- DXGI_FORMAT_R16G16B16A16_TYPELESS:类型需interpret
4.1.4 交换链(Swap Chain)和翻页(Page Flipping)
- 为避免动画闪烁,最好先在后台绘制完整一帧,后台绘制的空间称作back buffer
- back buffer绘制完成后,整体切换到前台的front buffer进行显示(这一过程称为Present),这样,观众就不会看到绘制过程
- front buffer和back buffer组成了交换链,Direct3D中交换链表示为IDXGISwapChain接口,可以使用它来ResizeBuffers和Present
- 两个buffer称为双缓冲,三个buffer称为三缓冲
4.1.5 深度缓冲(Depth Buffering)
- 深度缓冲中每个像素的取值在0到1之间,表示在视景体(view frustrum)的近端和远端之间
- 深度缓冲的作用是多个物体之间有遮挡关系时,使用深度缓冲可以保证近物体遮挡远物体,从而使绘制结果和绘制顺序无关
- 如果仅仅从远及近地绘制,首先它消耗较大,其次无法解决互相遮挡的问题
- 深度缓冲是一种纹理,因此增加了几种纹理格式:
- DXGI_FORMAT_D32_FLOAT_S8X24_UINT:32位float深度值,8位[0,255]的integer为模板缓冲(stencil buffer)预留,24位未使用作为对齐
- DXGI_FORMAT_D32_FLOAT:32位float深度值
- DXGI_FORMAT_D24_UNORM_S8_UINT:24位[0,1]float深度值,8位[0,255]的integer为模板缓冲(stencil buffer)预留
- DXGI_FORMAT_D16_UNORM:16位[0,1]float深度值
- 由于深度缓冲和模板缓冲经常放到一起,因此也常合并称为深度/模板缓冲
4.1.6 资源(Resources)和描述符(Descriptors)
- GPU从一些资源中读取(如纹理贴图、顶点坐标等),再写到一些资源中(如back buffer、depth/stencil buffer等),因此在执行绘制命令(draw command)前,我们需要将这些资源和渲染管线(rendering pipeline)相绑定。如果资源发生变化,则需要更新资源的绑定。
- 但是,资源不是直接绑定的,而是通过一个描述资源的轻量描述符来进行绑定。
- 这么做的原因:
- 资源往往是一大块通用空间,这些通用空间可能被用来表示不同的资源(如render target、depth/stencil buffer、shader resource等等),但是资源不会声称自己是哪种类型的资源
- 有时可能只想将资源的部分内容绑定到渲染管线(rendering pipeline)中
- 资源可以以无类型(typeless)的方式创建
- 因此,描述符用来定义这些资源,并告诉渲染管线相应的信息
- 这么做的原因:
- View是Descriptor的同义词,在DirectX老版本中使用,但也延续到了DirectX 12中
- CBV / SRV / UAV分别表示constant buffer / shader resources / unordered access的描述符
- RTV表示render target描述符
- DSV表示depth/stencil描述符
- 描述符堆(descriptor heap)是描述符被排列到一个数组中,同类的描述符可以放到一个描述符堆中,不同类的描述符需放到不同的描述符堆中。
- 我们可以用多个描述符指向同一个资源,比如
- 用多个描述符指向同一资源的不同区域
- 同一资源在不同渲染阶段都被使用,因此每个阶段都有一个描述符指向它
- 对于无类型资源,可能有多个描述子对它进行了不同的interpret
- 描述符需要在初始化阶段创建,从而可以进行一些类型检测来确保没有bug
4.1.7 多重采样(Multisampling)
- 不同的采样算法用来解决锯齿走样(stair-step aliasing)的问题
- 超级采样(Super Sampling)将front buffer和back buffer都扩展到实际屏幕的4倍(面积),且计算每个子像素的颜色,并对4个子像素的颜色进行平均
- 超级采样代价太高,复杂度直接提升了4倍,多重采样可以作为一种折中。多重采样也将front buffer和back buffer扩展到实际屏幕的4倍,但它不计算每个子像素的颜色,而只计算像素中心点的颜色,再根据子像素中心的可见性,决定子像素的颜色。例如,在下图中,像素中间点的颜色为灰色,4个子像素中,3个落在灰色正方形内,因此也取灰色;1个落在正方形外,因此取白色,再对这4个子像素取平均
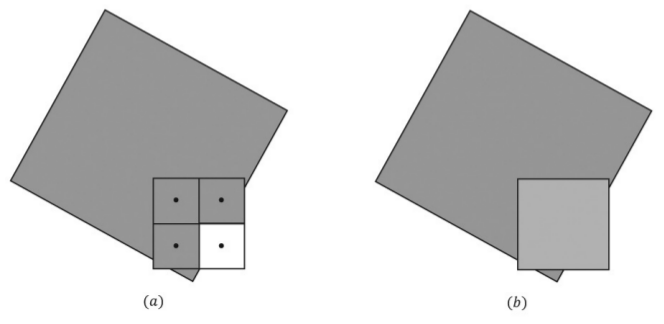
4.1.8 Direct3D中的多重采样
- 多重采样要填充DXGI_SAMPLE_DESC这一数据结构,其内容如下:
typedef struct DXGI_SAMPLE_DESC {
UINT Count;
UINT Quality;
} DXGI_SAMPLE_DESC;
- Count表示一个像素被分成了几个子像素,Quality表示每个子像素绘制复杂度
- 可以使用ID3D12Device::CheckFeatureSupport来查询给定纹理种类(如back buffer)和采样数,设备支持的Quality等级
- 如果不想使用多重采样,将Count设置为1,将Quality设置为0即可
4.1.9 功能等级
- DirectX12对应了D3D_FEATURE_LEVEL::D3D_FEATURE_LEVEL_11_0
4.1.10 DirectX图形基础设施(DXGI)
- Direct3D的一些基础API
- IDXGIFactory
- 生成IDXGISwapChain
- 遍历各个IDXGIAdapter(显卡适配器)
- IDXGIFactory
void LogAdapters(IDXGIFactory *mdxgiFactory) {
IDXGIAdapter* adapter = nullptr;
vector<IDXGIAdapter*> adapterList;
while (mdxgiFactory->EnumAdapters(i, &adapter) != DXGI_ERROR_NOT_FOUND) {
DXGI_ADAPTER_DESC desc;
adapter->GetDesc(&desc);
wstring text = L"Adapter: " + desc.Description + L"\n";
OutputDebugString(text.c_str());
adapterList.push_back(adapter);
}
for (size_t i=0; i<adapterList.size(); ++i) {
LogAdapterOutputs(adapterList[i]); // 见下一段
ReleaseCom(adapterList[i]);
}
}
* IDXGIOutput(输出,如显示屏)
void LogAdapterOutputs(IDXGIAdapter* adapter) {
IDXGIOutput* output = nullptr;
while (adpater->EnumOutputs(i, &output) != DXGI_ERROR_NOT_FOUND) {
DXGI_OUTPUT_DESC desc;
output->GetDesc(&desc);
wstring text = L"Output: " + desc.DeviceName + L"\n";
OutputDebugString(text.c_str());
LogOutputDisplayModes(output, DXGI_FORMAT_B8G8R8A8_UNORM);
ReleaseCom(output);
}
}
- 每个输出支持一系列输出模式,一个输出模式由DXGI_MODE_DESC的结构来刻画
4.1.11 检查功能支持
- ID3D12Device::CheckFeatureSupport()可以检查不同功能的支持情况,它的格式如下:
HRESULT ID3D12Device::CheckFeatureSupport(
D2D12_FEATURE Feature,
void *pFeatureSupportData,
UINT FeatureSupportDataSize);
* Feature可以是:
* D3D12_FEATURE_D3D12_OPTIONS:检查是否支持Direct3D 12功能
* D3D12_FEATURE_ARCHITECTURE:硬件架构支持情况
* D3D12_FEATURE_FEATURE_LEVELES:功能版本支持情况(见4.1.9)
* D3D12_FEATURE_FORMAT_SUPPORT:给定纹理格式的功能支持情况(如某格式是否可以用来做render target,某格式是否可以用来做blending)
* D3D12_FEATURE_MULTISAMPLE_QUALITY_LEVELS:多重采样质量支持情况(见4.1.8)
* pFeatureSupportData和FeatureSupportDataSize输入对应的实例和实例大小
4.1.12 资源保留
- 复杂场景中往往有大量资源(包括网格和纹理),但它们不是总被需要。比如森林里有个山洞,在森林里时,山洞中的资源实际上是不需要加载到GPU中的;在山洞中时,森林里的资源也是不需要加载到GPU中的。
- DirectX12中,应用自己管理资源的加载和卸载,良好的加载和卸载,应该是加载后在一段时间后才会被用到,这样避免进入场景时突然需要加载大量的资源
- 默认状态中,资源在创建时加载,在删除时卸载,但应用也可以通过以下方法ID3D12Device::MakeResident()和ID3D12Device::Evict自行决定加载和卸载
4.2 CPU/GPU交互
4.2.1 命令队列(Command Queue)和命令表(Command List)
- GPU中有一个命令队列,CPU向它提交命令,GPU按顺序执行。如果命令队列空了,GPU就会停下等待;如果命令队列满了,CPU就会停下等待。
- 命令队列由ID3D12CommandQueue来表示,它由ID3D12Device::CreateCommandQueue()生成
ComPtr<ID3D12CommandQueue> mCommandQueue;
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
ThrowIfFailed(md2dDevice->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&mCommandQueue)));
- 命令队列的一个主要方法为ID3D12CommandQueue::ExecuteCommandLists(),它可以按顺序执行命令表中的命令
- 命令表由ID3D12CommandLists来表示,它可以向命令表中添加命令,如ID3D12CommandLists::RSSetViewports()、ID3D12CommandLists::ClearRenderTargetView()、ID3D12CommandLists::DrawIndexedInstanced()等等。这些方法看起来像被马上执行了,但实际上它们仅仅被添加到命令表中,再被添加到命令队列里等待执行
- 在添加命令表到命令队列之前,需要调用ID3D12CommandLists::Close()方法
- 和命令表搭配使用的,实际占用空间的类是ID3D12CommandAllocator。当ID3D12CommandLists记录一个个命令时,这些命令实际上被存储在ID3D12CommandAllocator中。ID3D12CommandAllocator由ID3D12Device::CreateCommandAllocator()生成。
- 同一个Command Allocator可以对应多个Command List,但同一时间只允许一个Command List记录命令,即其他Command List都需要处于Close的状态。而每个Command List一创建就是Open的,因此对于同一Allocator的Command List,需先创建第一个,关闭,再创建第二个
- 再调用完ID3D12CommandQueue::ExecuteCommandLists(),Command List算是完成了使命,因此可以调用ID3D12CommandLists::Reset()方法进行重置。但此时还不能重置Command Allocator,因为这些命令可能尚未被执行。只有在确定了命令已经被执行完毕(见4.2.2),才可以调用ID3D12CommandAllocator::Reset()方法。此方法和vector::clear()类似,仅仅重置了大小为0,但申请的空间并没有释放
4.2.2 CPU/GPU同步
- 假设CPU将模型的位置修改为p1,然后将绘制命令加入到命令队列中;如果CPU没有被阻塞,它将继续把模型位置修改为p2,这就造成了错误。我们希望CPU等待GPU执行完某一时刻前的所有命令,再进行计算。这一时刻点就像一道篱笆一样,将CPU拦了下来,因此我们称之为Fence。Fence由ID3D12Fence结构进行表示。
- Fence包含一个UINT64的值,这个值从0开始,然后逐渐增加,通过比较这个值,我们可以判断篱笆是否打开了
UINT64 mCurrentFence = 0;
void FlushCommandQueue() {
mCurrentFence++;
// 在命令队列中增加一个命令,这个命令将Fence的value设置为mCurrentFence(也就是加1)
// 由于这个命令在队列末尾,因此需要之前的命令全部执行完毕,Fence的值才能得到更新
ThrowIfFailed(mCommandQueue->Signal(mFence.Get(), mCurrentFence));
// 如果GPU未到达Fence点,则等待,直到GPU到达Fence点
if (mFence->GetCompleteValue() < mCurrentFence) {
HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS);
// 当GPU到达Fence点时,执行event
ThrowIfFailed(mFence->SetEventOnCompletion(mCurrentFence, eventHandle));
// 等待GPU到达Fence点
WaitForSingleObject(eventHandle, INFINITE);
CloseHandle(eventHandle);
}
}
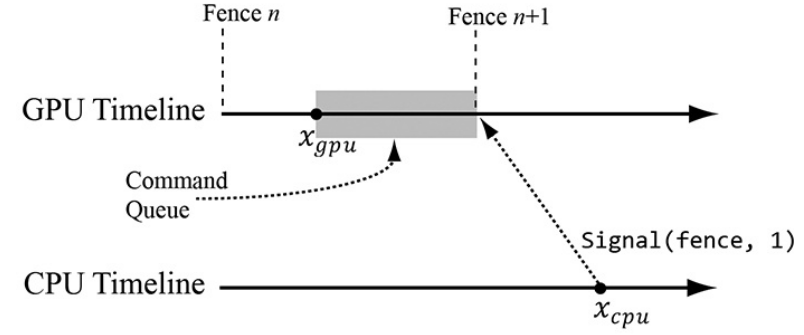
- 如上图和代码所示,CPU先给GPU命令队列末尾加一个篱笆,如果GPU立刻执行了这个篱笆(加1),则CPU就不会进if分支,一切正常;如果GPU尚未执行这个篱笆,CPU就会进入if分支,等待GPU执行篱笆(加1),再继续运行
- 这个方案的缺陷在于CPU需要等待GPU完成,代价较大
- 篱笆也可以用来确定GPU已经执行完全部的命令,从而可以重置command allocator
4.2.3 资源转移
- 渲染中,常常出现GPU先向资源中写,再从资源中读的情况。显然,如果GPU还没写完,甚至还没开始写,就开始读取,那肯定会有问题
- 为了解决这个问题,我们需要给资源设置状态。比如,在写入时,我们将资源设置为render target state;在读取时,我们将资源设置为shader resource state。为了性能考虑,这一状态变化应由用户进行维护
- 和之前的“篱笆”类似,这里我们称这种状态改变为“障碍”,即transition resource barriers,它的数据结构为D3D12_RESOURCE_BARRIER_DESC。d3dx12.h这一辅助代码中,帮助我们简化了状态转移的代码:
struct CD3DX12_RESOURCE_BARRIER : public D3D12_RESOURCE_BARRIER {
// 其他方法
static inline CD3DX12_RESOURCE_BARRIER Transition(
_In_ ID2D12Resource* pResource,
D2D12_RESOURCE_STATES stateBefore,
D2D12_RESOURCE_STATES stateAfter,
UINT subresource = D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES,
D3DX12_RESOURCE_BARRIER_FLAGS flags = D3DX12_RESOURCE_BARRIER_FLAG_NONE) {
CD3DX12_RESOURCE_BARRIER result;
ZeroMemory(&result, sizeof(result));
CD3DX12_RESOURCE_BARRIER &barrier = result;
result.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSTION;
result.Flags = flags;
barrier.Transition.pResource = pResource;
barrier.Transition.StateBefore = stateBefore;
barrier.Transition.StateAfter = stateAfter;
barrier.Transition.Subresource = subresource;
return result;
}
// 其他方法
}
- 因此我们可以如下将状态转换的命令加入到command list中
// 将back buffer从显示状态转换到写状态
mCommandList->ResourceBarrier(1,
&CD3DX12_RESOURCE_BARRIER::Transition(
CurrentBackBuffer(),
D3D12_RESOURCE_STATE_PRESENT,
D3D12_RESOURCE_STATE_RENDER_TARGET))
4.2.4 命令中的多线程
- 假设要绘制一个有很多物体的场景,则构建一个绘制整个场景的command list可能会消耗较多CPU时间;一种方法是在CPU中使用多线程,比如4个线程,每个线程绘制25%的物体
- 注意:
- command list不是线程共享的,多个线程不可以使用同一个command list
- command allocator不是线程共享的,多个线程不可以使用同一个command allocator
- command queue是线程共享的,因此多个线程可以使用同一个command queue,同时向它提交command list
- 在初始化时需要指定command list数量的上限
4.3 初始化Direct3D
4.3.1 创建设备
- 使用CreateDXGIFactory1()创建DXGI工厂
- 使用mdxgiFactory->EnumWarpAdapter()遍历适配器IDXGIAdapter
- 使用D3D12CreateDevice(),以适配器为输入创建设备ID3D12Device
4.3.2 创建Fence并查询descriptor大小
- 使用md3dDevice->CreateFence()创建Fence
- 使用md3dDevice->GetDescriptorHandleIncrementSize()获得不同类型descriptor的大小,不同GPU的descriptor大小不同
4.3.3 检查4倍多重采样抗锯齿(MSAA,Multisampling Anti Aliasing)的质量等级支持
- 支持Direct3D 11的设备都支持4倍MSAA,因此不需要检查4倍MSAA的支持
- 但对于质量等级(详见4.1.8)的支持,还是需要检查的。可以使用md3dDevice->CheckFeatureSupport()进行检查
4.3.4 创建命令队列(command queue)和命令表(command list)
- 使用md3dDevice->CreateCommandQueue()创建command queue,使用md3dDevice->CreateCommandAllocator创建command allocator,使用md3dDevice->CreateCommandList创建command list,创建command list时,需要传入command allocator的指针
4.3.5 描述并创建交换链(swap chain)
- 交换链的描述数据结构为DXGI_SWAP_CHAIN_DESC,如下
typedef struct DXGI_SWAP_CHAIN_DESC {
DXGI_MODE_DESC BufferDesc; // back buffer的属性,包括高度、宽度、刷新率、像素属性等等
DXGI_SAMPLE_DESC SampleDesc; // 多重采样倍数和质量,详见4.1.8
DXGI_USAGE BufferUsage; // 指定为DXGI_USAGE_RENDER_TARGET_OUTPUT,因为back buffer是一个渲染目标
UINT BufferCount; // 2或3,表示双重采样或三重采样
HWND OutputWindow; // 输出窗口的handle
BOOL Windowed; // 是否全屏
DXGI_SWAP_EFFECT SwapEffect; // 指定为DXGI_SWAP_EFFECT_FLIP_DSCARD
UINT Flags;
} DXGI_SWAP_CHAIN_DESC;
- 然后就可以使用mdxgiFactory->CreateSwapChain()来创建swap chain
4.3.6 创建描述符堆(descriptor heap)
- 假设我们需要n重采样的n个RTV(render target view),以及一个DSV(depth / stencil view),那么我们需要一个descriptor heap用来存储n个RTV,和一个descriptor heap用来存储1个DSV
- 首先填写好D3D12_DESCRIPTOR_HEAP_DESC
- 然后使用md3dDevice->CreateDescriptorHeap()来创建descriptor heap
- 使用mRtvHeap->GetCPUDescriptotForHeapStart()和mDsvHeap->GetCPUDescriptotForHeapStart()来获取堆里的第一个descriptor
4.3.7 创建RTV(Render Target View)
ComPtr<ID3D12Resource> mSwapChainBuffer[SwapChainBufferCount]; // 2或3
CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHeapHandle(mRtvHeap->GetCPUDescriptotForHeapStart());
for (UINT i=0; i<SwapChainBufferCount; i++) {
// 获取第i个buffer
ThrowIfFailed(mSwapChain->GetBuffer(i, IID_PPV_ARGS(&mSwapChainBuffer[i])));
// 创建RTV
md3dDevice->CreateRenderTargetView(mSwapChainBuffer[i].Get(), nullptr, rtvHeapHandle);
// 获取堆中的下一个位置
rtvHeapHandle.Offset(1, mRtvDescriptorSize); // 这里用到了之前查询得到的descriptor大小
}
4.3.8 创建深度/模板缓冲和描述符
4.3.9 设置视窗(Viewport)
- 通常我们在整个back buffer上绘制,但如果我们仅在back buffer上的一个子矩阵中绘制,则需要设置view port
- 首先设置数据结构D3D12_VIEWPORT,然后使用mCommandList->RSSetViewports()来设置view port
- 如果使用整个back buffer,则代码如下:
D3D12_VIEWPORT vp;
vp.TopLeftX = 0.0f;
vp.TopLeftY = 0.0f;
vp.Width = static_cast<float>(mClientWidth);
vp.Height = static_cast<float>(mClientHeight);
vp.MinDepth = 0.0f;
vp.MaxDepth = 1.0f;
mCommandList->RSSetViewports(1, &vp);
- 不可以对同一个render target设置多个viewport
- 如果command list被重置了,则view port也需要被重新设置
- viewport可以用来双人单机游戏设置分屏
4.3.10 设置裁剪矩形
- 我们可以设置一个裁剪矩形,使得这个矩形外的像素都不会被渲染。比如,我们知道屏幕上会包含一个位于一切上方的矩形UI,则这个矩形UI内的部分不需要被渲染
- 可以用mCommandList->RSSetScissorRects()来设置裁剪矩形
- 不可以对同一个render target设置多个裁剪矩形
- 如果command list被重置了,则裁剪矩形需要被重新设置
4.4 计时和动画
4.5 DEMO
4.6 Debug
第五章 渲染管线
5.1 三维错觉
- 平行线在无穷远处交于一点
- 近大远小
- 正确的遮挡关系
- 正确的光照和着色
- 正确的阴影
5.2 模型表示
- 网格
5.3 颜色
- 加法
- 逐元素乘法
- 超过1.0的削减到1.0
5.4 渲染管线总述
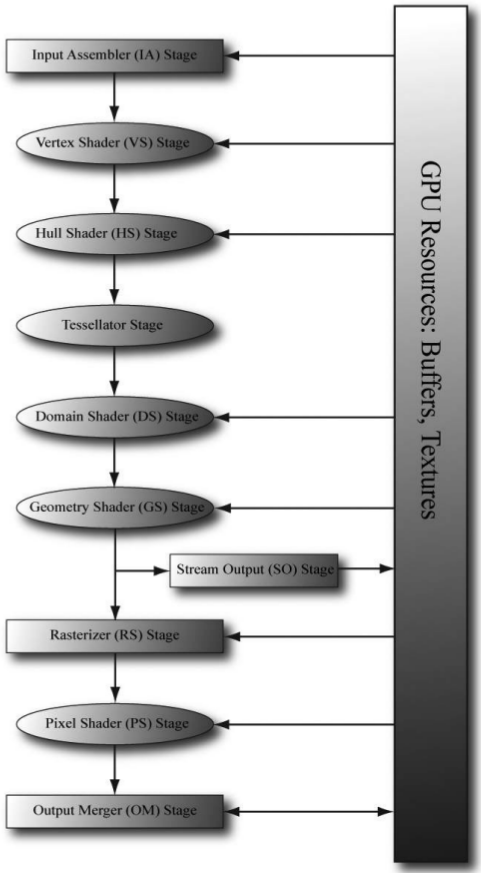
5.5 Input Assembler阶段
- 顶点被存储在vertex buffer中,它除了包含顶点几何位置外,还可以包含顶点法向、纹理坐标等信息
- vertex buffer的读取顺序,由枚举变量D3D_PRIMITIVE_TOPOLOGY决定
- 使用index减少vertex重复次数
5.6 Vertex Shader阶段
- 局部坐标->世界坐标->视口坐标->投影坐标
- 转换到投影坐标时,三维坐标已经被转换成了二维像素坐标和一个深度值,此时深度值还要被后续用来判断遮挡关系,因此不能丢弃。而且,为了使得近处深度判断精度更高,深度值需要进行一定的变换,满足近平面g(z)为0,远平面g(z)为1
g ( z ) = A + B z g(z) = A + \frac{B}{z} g(z)=A+zB
5.7 Tessellation阶段
- 细分以增加细节
- 优势:
- 和LOD(Level of Detail)结合,近处高精度渲染,远处低精度渲染
- 仅存储低精度模型,使用细分增加细节,节约存储空间
- 在低精度模型上进行物理和动画计算,仅在渲染时使用高精度模型
- 可选(详见第十四章),Direct3D 11的新特性。在Direct3D 11之前,tessellation仅能在CPU中计算,因此效率低下
5.8 Geometry Shader阶段
- 可选(详见第十二章)
- 可将一个顶点变成一个多边形
5.9 Clipping阶段
- 裁剪看不见区域的模型
5.10 Rasterization阶段
- 转换到视口坐标
- 去除模型背面
- 顶点属性插值
5.11 Pixel Shader阶段
- 可用于逐像素光照、阴影等
5.12 Output Merger阶段
- blending:新一帧像素的值和当前back buffer中像素的值做融合(详见第十章)
第六章 在Direct3D中绘制
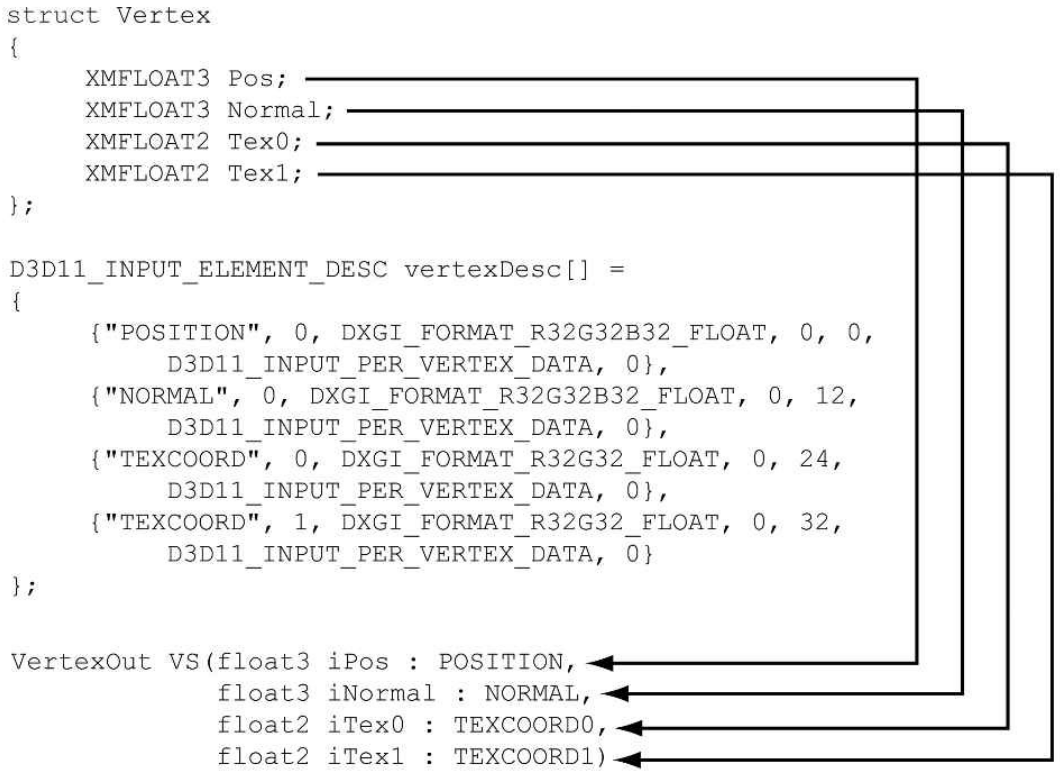
6.1 顶点和输入布局
- 对自定义的顶点格式,使用D3D12_INPUT_LAYOUT_DESC和D3D12_INPUT_ELEMENT_DESC进行描述
6.2 Vertex Buffers
- 为了让GPU可以读取到数组数据(如这里的顶点),我们需要将数据放到一种叫做buffer的GPU资源中
- buffer相比texture,是一种更简单的资源,它只有一个一维数组,没有多维,没有mipmap、filter或多重采样
- 和4.3.8类似,为了得到一个资源对象ID3D12Resource,我们需要先填好一个描述数据结构D3D12_RESOURCE_DESC,然后调用md3dDevice->CreateCommittedResource()。对于buffer,Direct3D 12提供了一个简化版的接口CD3DX12_RESOURCE_DESC::Buffer(),仅需指定buffer的大小即可
static inline CD3DX12_RESOURCE_DESC Buffer(UINT64 width,
D3D12_RESOURCE_FLAGS flags = D3D12_RESOURCE_FLAG_NONE,
UINT64 alignment = 0) {
return CD3DX12_RESOURCE_DESC(
D3D12_RESOURCE_DIMENSION_BUFFER,
alignment, width, 1, 1, 1,
DXGI_FORMAT_UNKNOWN, 1, 0,
D3D12_TEXTURE_LAYOUT_ROW_MAJOR, flags
);
}
- 注意到,一维的buffer和二维的texture都使用了ID3D12Resource这一对象,这和Direct3D 11中将它们分别写成两个类不同。不同种类的对象由维度来区分,如buffer的维度是D3D12_RESOURCE_DIMENTSION_BUFFER,二维texture维度是D3D12_RESOURCE_DIMENTSION_TEXTURE2D
- 对于静态几何体(不需要随着时间进行动画),出于性能的考虑,我们可以将vertex buffer放到default heap中(D3D12_HEAP_TYPE_DEFAULT)。对于default heap中的buffer,(初始化后)只允许GPU的读操作,因此效率高。但如何让CPU将内存中的数据复制进去呢?我们需要另外创建一个upload buffer,它放到D3D12_HEAP_TYPE_UPLOAD的heap下,从而可以将内存中的数据复制进去,再将数据(由GPU)从upload buffer中复制到vertex buffer中。由于每个default buffer都需要一个upload buffer,因此d3dUtil.h/.cpp就做了一个函数:
ComPtr<ID3D12Resource> d3dUtil::CreateDefaultBuffer(
ID3D12Device* device,
ID3D12GraphicsCommandList* cmdList,
const void* initData,
UINT64 byteSize,
ComPtr<ID3D12Resource> &uploadBuffer
) {
ComPtr<ID3D12Resource> defaultBuffer;
// 创建default buffer
ThrowIfFailed(device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(byteSize),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(uploadBuffer.GetAddressOf())
));
// 描述要复制到default buffer中的数据
D3D12_SUBRESOURCE_DATA subResourceData = {};
subResourceData.pData = initData;
subResourceData.RowPitch = byteSize;
subResourceData.SlicePitch = subResourceData.RowPitch;
// 复制数据到default buffer中
// 最高层调用了UpdateSubresources这个辅助函数
// 辅助函数内调用了ID3D12CommandList::CopySubresourceRegion()方法
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(
defaultBuffer.Get(), D3D12_RESOURCE_STATE_COMMON,
D3D12_RESOURCE_STATE_COPY_DEST));
UpdateSubresources<1>(cmdList, defaultBuffer.Get(),
uploadBuffer.Get(), 0, 0, 1, &subResourceData);
cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(
defaultBuffer.Get(), D3D12_RESOURCE_STATE_COPY_DEST,
D3D12_RESOURCE_STATE_GENERIC_READ));
// upload buffer在此函数执行完仍需有效,因为command list只是添加了任务,但是尚未执行
return defaultBuffer;
}
- 为了将vertex buffer绑定到渲染管线中,我们需要对资源创建一个descriptor,即vertex buffer view。和render target view不同的是,它不需要descriptor heap。这个结构是D3D12_VERTEX_BUFFER_VIEW_DESC。然后就可以通过ID3D12GraphicsCommandList::IASetVertexBuffers()绑定到Input Assembler里
- 最后,使用ID3D12GraphicsCommandList::DrawInstanced()函数进行绘制,当然在绘制之前还需要调用ID3D12GraphicsCommandList::IASetPrimitiveTopology()来决定顶点连接顺序(详见5.5.2)
6.3 Index Buffers
- 和vertex buffer非常类似,使用d3dUtil::CreateDefaultBuffer()进行创建
- 填写D3D12_INDEX_BUFFER_VIEW,使用ID3D12GraphicsCommandList::SetIndexBuffer()绑定到渲染管线上
- 如果有了index buffer,就要使用ID3D12GraphicsCommandList::DrawIndexedInstanced()函数进行绘制
6.4 Vertex Shader示例

- gWorldViewProj见6.6 Constant Buffers
- 上面的着色器也可以写成:
cbuffer cbPerObject : register(b0) {
float4x4 gWorldViewProj;
};
struct VertexIn {
float3 PosL : POSITION;
float4 Color : COLOR;
};
struct VertexOut {
float4 PosH : SV_POSITION;
float4 Color : COLOR;
};
VertexOut VS(VertexIn vin) {
VertexOut vout;
vout.PosH = mul(float4(vin.PosL, 1.0f), gWorldViewProj);
vout.Color = vin.Color;
return vout;
}
- 如果没有geometry shader,则vertex shader必须输出SV_POSITION
- 如果VertexIn数据结构和D3D12_INPUT_ELEMENT_DESC不匹配,则会报错;但顺序不一致则没关系;如果类型不一致(如float和int),则会报warning
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









