






引言
在Python开发中,多线程是实现并发编程的重要手段,尤其适合I/O密集型任务(如文件读写、网络请求)。但直接使用threading模块创建线程存在明显痛点:
- 线程生命周期需手动管理(创建/销毁开销大)
- 无法控制并发数量(可能导致资源耗尽)
- 任务结果获取复杂(需通过共享变量或队列)
为解决这些问题,Python 3.2 引入了concurrent.futures模块,提供了线程池(ThreadPoolExecutor) 这一高级接口。本文将从基础原理到实战案例,带你彻底掌握线程池的核心用法。
一、线程池的核心价值
线程池通过复用线程和统一管理任务队列,实现了:
✅ 降低资源开销:线程重复使用,避免频繁创建/销毁
✅ 控制并发数量:通过max_workers限制同时运行的线程数
✅ 简化任务提交:无需手动管理线程生命周期
✅ 安全获取结果:通过Future对象获取任务返回值
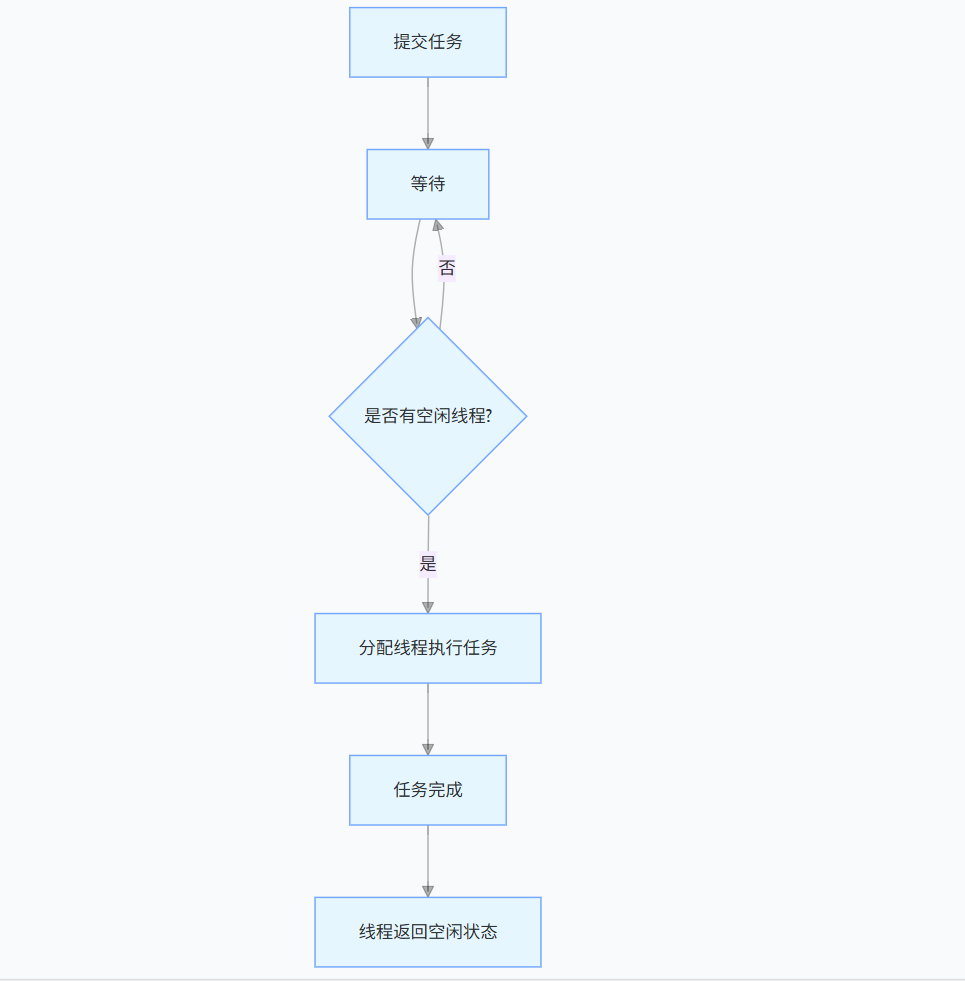
二、线程池的底层架构(图解)
线程池的工作流程可简化为以下4步:
三、ThreadPoolExecutor 基础使用
3.1 环境准备
- Python 3.2+(本文基于Python 3.10)
- 核心模块:
concurrent.futures.ThreadPoolExecutor
3.2 快速上手:第一个线程池程序
我们通过一个模拟文件下载的案例,演示线程池的基础用法。
示例1:多线程下载文件(基础版)
import time
import concurrent.futures
def download_file(url: str) -> str:
"""模拟文件下载任务"""
print(f"开始下载:{url}")
time.sleep(2) # 模拟下载耗时
return f"{url} 下载完成"
if __name__ == "__main__":
urls = [
"https://example.com/file1.zip",
"https://example.com/file2.jpg",
"https://example.com/file3.pdf",
"https://example.com/file4.png"
]
# 创建线程池(最多3个工作线程)
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
# 提交所有任务(返回Future对象列表)
futures = [executor.submit(download_file, url) for url in urls]
# 遍历获取结果(按任务完成顺序)
for future in concurrent.futures.as_completed(futures):
try:
result = future.result() # 阻塞等待任务完成
print(f"任务结果:{result}")
except Exception as e:
print(f"任务出错:{e}")
运行结果
开始下载:https://example.com/file1.zip
开始下载:https://example.com/file2.jpg
开始下载:https://example.com/file3.pdf
(等待2秒后...)
任务结果:https://example.com/file1.zip 下载完成
开始下载:https://example.com/file4.png (第4个任务由空闲线程执行)
(再等待2秒后...)
任务结果:https://example.com/file2.jpg 下载完成
任务结果:https://example.com/file3.pdf 下载完成
任务结果:https://example.com/file4.png 下载完成
关键知识点
with语句自动管理线程池生命周期(等价于调用shutdown())executor.submit(func, *args):提交单个任务,返回Future对象as_completed(futures):按任务完成顺序迭代结果(非提交顺序)
3.3 进阶参数:线程池的核心配置
ThreadPoolExecutor的构造函数支持以下关键参数:
| 参数名 | 类型 | 说明 |
|---|---|---|
max_workers | int | 最大工作线程数(默认min(32, os.cpu_count() + 4)) |
thread_name_prefix | str | 线程名称前缀(用于调试,如"DownloadThread-") |
initializer | callable | 线程初始化函数(每个线程创建时执行一次,如连接数据库) |
initargs | tuple | initializer的参数元组 |
示例2:带初始化函数的线程池(数据库连接场景)
import sqlite3
import concurrent.futures
def init_db():
"""线程初始化函数:创建数据库连接"""
# 每个线程独立持有连接(避免共享连接的线程安全问题)
thread_conn = sqlite3.connect("thread_db.db")
print(f"线程 {threading.get_ident()} 初始化数据库连接")
return thread_conn # 可通过threading.local()存储
def save_data(data: str):
"""模拟数据库写入任务"""
conn = init_db() # 实际应通过threading.local获取已初始化的连接
cursor = conn.cursor()
cursor.execute("INSERT INTO logs VALUES (?)", (data,))
conn.commit()
return f"数据 {data} 写入成功"
if __name__ == "__main__":
with concurrent.futures.ThreadPoolExecutor(
max_workers=2,
initializer=init_db # 指定初始化函数
) as executor:
results = executor.map(save_data, ["日志1", "日志2", "日志3"])
for result in results:
print(result)
四、任务提交的两种模式对比
线程池提供了两种任务提交方式,适用不同场景:
4.1 submit():灵活的单任务提交
- 特点:支持动态提交任务、获取
Future对象、处理异常 - 适用场景:任务参数不固定、需要单独处理结果/异常
4.2 map():批量任务的简化提交
- 特点:参数需可迭代、结果按提交顺序返回(非完成顺序)
- 适用场景:任务参数是可迭代对象(如列表)、无需单独处理异常
示例3:submit() vs map() 对比
import time
import concurrent.futures
def task(n: int) -> int:
time.sleep(1)
return n * 2
if __name__ == "__main__":
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
# 方式1:submit()
futures = [executor.submit(task, i) for i in range(3)]
print("submit结果(按完成顺序):")
for future in concurrent.futures.as_completed(futures):
print(future.result()) # 输出:0, 2, 4(可能乱序)
# 方式2:map()
results = executor.map(task, range(3))
print("map结果(按提交顺序):")
for result in results:
print(result) # 输出:0, 2, 4(严格顺序)
关键差异总结
| 特性 | submit() | map() |
|---|---|---|
| 任务参数 | 任意参数(args, kwargs) | 必须是可迭代对象(iterables) |
| 结果顺序 | 按完成顺序(通过as_completed) | 按提交顺序 |
| 异常处理 | 可通过future.exception()捕获 | 异常会在迭代时抛出 |
| 内存占用 | 需存储所有Future对象 | 流式处理(内存更友好) |
五、回调函数:任务完成后的自动处理
线程池支持为Future对象添加回调函数,实现任务完成后自动触发操作(如结果保存、通知用户)。
示例4:带回调函数的文件下载(通知功能)
import time
import concurrent.futures
from datetime import datetime
def download_file(url: str) -> str:
time.sleep(2)
return f"{url} 下载完成(时间:{datetime.now().strftime('%H:%M:%S')})"
def send_notification(future: concurrent.futures.Future):
"""回调函数:下载完成后发送通知"""
result = future.result()
print(f"[通知] {result},已推送至用户手机")
if __name__ == "__main__":
urls = ["https://example.com/file1.zip", "https://example.com/file2.jpg"]
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for url in urls:
future = executor.submit(download_file, url)
future.add_done_callback(send_notification) # 注册回调
# 主线程可以继续执行其他操作(非阻塞)
print("主线程:开始处理其他任务...")
time.sleep(1)
print("主线程:其他任务处理完成")
运行结果
主线程:开始处理其他任务...
主线程:其他任务处理完成
(等待2秒后...)
[通知] https://example.com/file1.zip 下载完成(时间:15:30:45),已推送至用户手机
[通知] https://example.com/file2.jpg 下载完成(时间:15:30:45),已推送至用户手机
关键点
- 回调函数通过
future.add_done_callback(func)注册 - 回调函数的参数是
Future对象本身(需通过future.result()获取结果) - 回调函数在任务完成后异步执行(不阻塞主线程)
六、异常处理:避免线程池“静默崩溃”
线程池中的任务异常不会直接抛出到主线程,需通过Future对象主动捕获,否则可能导致“任务失败但无提示”的问题。
示例5:任务异常的正确处理
import concurrent.futures
def risky_task(n: int) -> int:
if n % 2 == 0:
return n * 2
raise ValueError(f"奇数{n}不被允许") # 模拟异常
if __name__ == "__main__":
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(risky_task, i) for i in range(3)]
for future in concurrent.futures.as_completed(futures):
try:
print(f"任务结果:{future.result()}")
except ValueError as e:
print(f"捕获到异常:{e}")
except Exception as e:
print(f"未知异常:{e}")
运行结果
捕获到异常:奇数1不被允许
任务结果:0
捕获到异常:奇数3不被允许 (假设range(3)改为range(4))
任务结果:2
七、线程池的关闭与资源释放
线程池提供shutdown()方法用于优雅关闭,支持以下参数:
| 参数 | 类型 | 说明 |
|---|---|---|
wait | bool | 是否阻塞等待所有任务完成(默认True) |
canceling_futures | bool | 是否取消未开始的任务(Python 3.9+,默认False) |
最佳实践
- 优先使用
with语句(自动调用shutdown(wait=True)) - 手动关闭时建议
shutdown(wait=True)确保任务完成 - 紧急关闭时可
shutdown(canceling_futures=True)取消未执行任务
八、实战场景:线程池的典型应用
场景1:批量网络请求(爬虫优化)
import requests
import concurrent.futures
def fetch_url(url: str) -> int:
response = requests.get(url)
return response.status_code
if __name__ == "__main__":
urls = [
"https://www.baidu.com",
"https://www.github.com",
"https://www.csdn.net"
]
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# 同时发起3个请求(受max_workers限制)
results = executor.map(fetch_url, urls)
for url, status in zip(urls, results):
print(f"{url} 状态码:{status}")
场景2:文件批量处理(日志分析)
import os
import concurrent.futures
def analyze_log(file_path: str) -> int:
"""统计日志中的错误行数"""
error_count = 0
with open(file_path, "r") as f:
for line in f:
if "ERROR" in line:
error_count += 1
return error_count
if __name__ == "__main__":
log_dir = "./logs"
log_files = [os.path.join(log_dir, f) for f in os.listdir(log_dir) if f.endswith(".log")]
with concurrent.futures.ThreadPoolExecutor() as executor:
# 并行分析所有日志文件
error_counts = executor.map(analyze_log, log_files)
total_errors = sum(error_counts)
print(f"总错误数:{total_errors}")
九、性能优化:如何设置max_workers?
线程池的性能与max_workers的设置密切相关,需根据任务类型调整:
9.1 I/O密集型任务(如网络请求)
- 特点:线程大部分时间等待I/O完成(CPU空闲)
- 建议:
max_workers = 核心数 * 5(经验值,可根据实际负载调整)
9.2 计算密集型任务(如数值计算)
- 特点:线程需大量占用CPU
- 建议:
max_workers ≤ CPU核心数(受GIL限制,多线程无法利用多核)
十、总结与最佳实践
核心优势总结
- 简化线程管理,降低代码复杂度
- 控制并发数量,防止资源耗尽
- 安全获取任务结果,支持回调与异常处理
最佳实践清单
- 优先使用
with语句管理线程池生命周期 - 根据任务类型设置
max_workers(I/O密集型可偏大,计算密集型需限制) - 对关键任务添加回调函数(如结果存储、通知)
- 始终处理任务异常(避免静默失败)
- 对批量任务优先使用
map()(内存更友好)
思考与练习:
尝试用线程池优化你项目中的一个I/O密集型功能(如批量文件上传、接口测试),并记录性能提升数据。欢迎在评论区分享你的实践经验!

















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









