










1 用途
感知器即单层神经网络,或者叫做神经元,是组成神经网络的最小单元。其作用即为“分类”,但是什么叫做“分类“?“分类”在实际中又有什么用途?
为了方便理解,我想把“分类”和“聚类”对比着来总结。
分类
即,将不同的数据不同特性分成不同的类别。字面意思很好理解,但是实际中是做什么的呢?比如,垃圾邮件分类,可以把垃圾邮件的关键字设为1,其余的为0,这样就可以区分开来;比如银行决定是否要给你贷款,就需要将你以前的信用记录汇总按照贷款风险大小进行分类,最后得出要不要贷给你钱(插个题外话:大数据的力量催生了互联网金融,比如阿里,就可以根据你几年的交易记录来评估你的信用从而可以方便快捷的选择是否给你贷款以及给你多少贷款,比以往银行的评估系统高效很多);还比如图像处理中,需要检测是否出现人脸;还比如舆情监督,政府可以根据网络热词进行分类来对舆论进行监控(这让我想起【V字仇杀队】那个监控车……);还有很多其他用途,但以上方面足以看出其重要性!
聚类
也是对数据进行分类,但是和“分类”相比,没有训练数据集,这属于无监督学习——这个是更加基础的概念,即没有训练数据集的学习。而有监督学习即有训练数据集。把聚类再通俗来说:聚类分析就是根据事物彼此不同的属性进行辨认,将具有相似属性的事物聚为一类,使得同一类的事物具有高度的相似性。实际中用途在哪里呢?其实和上述用途也差不多,只是训练数据集是没有的,要从数据内部属性挖掘出相似性。比如,在生物领域,聚类分析被用来动植物分类和对基因进行分类,获取对种群固有结构的认识;比如,分组聚类出具有相似浏览行为的客户,并分析客户的共同特征,可以更好的帮助电子商务的用户了解自己的客户,向客户提供更合适的服务等等。
以上便是“分类”和“聚类”的含义及现实意义。
2 原理
既然是对一群点进行分类(准确的讲只是分为两类),但是每个点的“重要性”我们并不知道,所以在这里为每个点设置一个“权值”——w;但是我并不能明白这里的“偏置(bias)”——b的意义,从公式的角度来说
感知器算法的本质是由误分类点驱动的,原理便是“将误分类点与分类线(面)的距离不断调整使其减到最少,那么就说是分类完全了”,这种从反面解决问题的思想或许是这个算法最宝贵之处。那么,如何减到最小?首先我们要衡量误分类点到分类线or面的距离。假设误分类点是 xo ,即
3 注意
第一,这是向量操作,
x0代表的其实就是坐标(这里是二维坐标值),而不是
(xi,yi)
才是一个坐标;
第二,数据必须要满足线性可分才能用此法,如果线性不可分,则永远执行下去。所以,此法太有约束了;
第三,关于为何把这种算法叫做神经元,我认为一般解释都是不恰当的。简单的类比突触,轴突等没有太大意义。但是作为单层感知器,它局限性还体现在哪里,和多层又有何联系,下面可以以一幅图的形式展示:
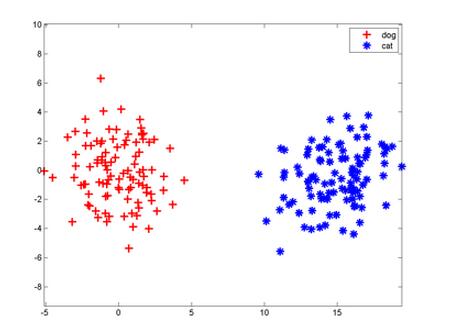
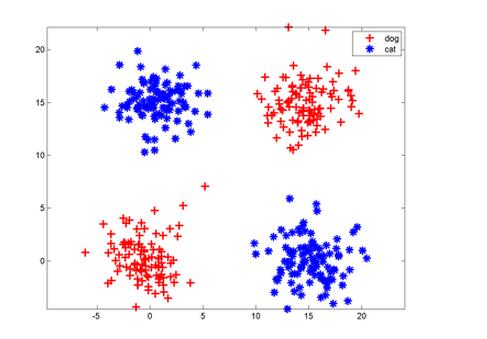
上面一个图可以一刀切下去,即单个神经元即可解决,但下面这个图你肿么一刀切开?所以,这就引入了神经网络
4 代码
lP=[-0.4 -0.6 0.7; 0.8 0 0.1];
T=[1 1 0];
net=newp([-1 1;-1 1],1);
%返回画线的句柄,下一次绘制分类线时将旧的删除
handle=plotpc(net.iw{1},net.b{1});
%设置训练次数最大为200
net.trainParam.epochs = 200;
net=train(net,lP,T);
%给定的输入向量
Q=[0.6 0.9 -0.1; -0.1 -0.5 0.5];
Y=sim(net,Q);
figure;
%绘制分类线
plotpv(Q,Y);
handle=plotpc(net.iw{1},net.b{1},handle)
grid















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









