







Stanford机器学习__Lecture notes CS229. Logistic Regression(逻辑回归)(2)
这里其实我们要说的是感知器算法。
之所以要把感知器算法(Perceptron Learning Algorithm)放在这里,是因为这两个算法在形式上的相似性。
我们在logistic回归中,考虑到二分类问题,其输出标记y∈(0,1),而线性回归模型产生的预测值 H(x)=wTx+b 是实值,于是我们需要将实值 H(x) 转化为0/1值。最理想的是“单位阶跃函数”(unit-step function)。最后我们用对数几率函数(Logistic functino)作为 g(.) 替代了“单位阶跃函数”得到了logistic回归函数。
hθ(x)=11+e(wTx)
当我们把对数几率函数(Logistic functino)替换为 sign 函数时,我们就得到了一个二元线性分类器——感知器。
g(z)={10if z≥0if z < 0
此时,另 hθ(x)=g(θTx)
参数更新规则:
θjnew=θjold−α(hθ(x(i))-y(i))x(i)j,
到这里,我们就已经有了完整的感知器学习算法。
我们可以看到,这里的参数更新规则实际上跟logistic随机梯度下降的参数更新规则是一致的。
细心一点可以看出,其实
θTx=0
在1维空间中代表一个点,在2维空间中代表一条直线,在3维空间中代表一个平面。
以2维空间为例:
对于所有满足
θTx<0
的x,将落在直线一边的区域中(下图中的蓝色).对于所有满足
θTx>0
的x,将落在直线另一边的区域中(下图中的红色).
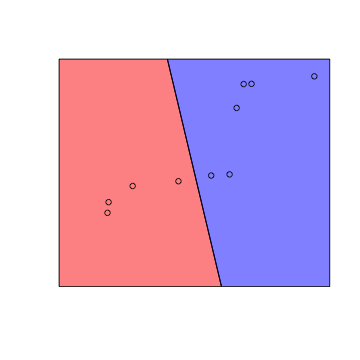
Perceptron Learning
Perceptron Learning Algorithm的目的是要找到一个perceptron,能把正确地把不同类别的点区分开来。在二维平面上,任何找一条直线都可以用来做perceptron,只不过有些perceptron分类能力比较好(分错的少),有些perceptron分类能力比较差(分错的多)。
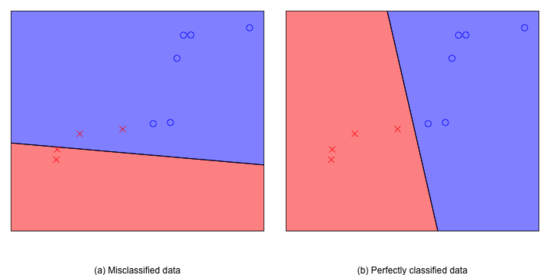
自然,Perceptron Learning Algorithm需要找到一个好的perceptron。
Perceptron Learning要做的是,在“线性可分”的前提下,至少存在一个perceptron,可以做到百分百的正确率,对于任意的
(yi,xi)
,有
hθ(xi)=yi
。
我们把完美的Perceptron记作:
由一个初始的Perceptron开始,通过不断的learning,不断的调整 hθ(x) 的参数 θ ,使他最终成为一个完美的perceptron。
Perceptron Learning Algorithm (PLA) - “知错就改”的算法
PLA的方法如下:
PLA的 costfunction(x)=−∑错误分类的索引集合iyi(θxi+b)
为了简化我们之后的论证过程,在这里做出小改动:
1. 我们将负样本标记为-1
2. 基于1的改动,我们也需要把g(.)函数替换为:
sign(z)={1−1if z≥0if z < 0
3. 基于以上,我们需要变动参数的更新法则:
极小化cost function的梯度是对w和b求偏导,即:
∇θcostfunction=−∑yixi∇bcostfunction=−∑yi
这样,我们只需要对每个错分类的样本进行下面的更新即可:
θjnew=θjold+yix(j)i,
For(t=0,1,...) ,t 表示第t次更新——第t次遍历数据集
xi
表示第
i
个样本,循环遍历整个训练集
如果
直到找不到错误点,返回最后一次迭代的 θbest 。
Perceptron Learning Algorithm (PLA)收敛性证明
我们知道在数据线性可分的前提下,我们心目中有个完美的
θbest
,它能够完美的把圈圈和叉叉区分开来。那么如何证明PLA能够使
θ
不断接近
θbest
呢?
这里就要用到夹角余弦的公式,如果令t表示
θ
的更新次数,
θt
更新之后的
θi+1
与
θbest
之间的夹角余弦变大(夹角变小)了,则我们可以认为PLA是有效的。
- 当数据“线性可分”时, θbest 是必然存在的,所以训练集中任意的 (xi,yi) 都可以被正确分类,可知:
2. 下面证明在数据线性可分时,简单的感知机算法会收敛。
初始时
θ0=0
,每次遇见错误数据才会更新。
t次更新以后:
看起来
θt
更接近
θbest
了,但他们内积的增大并不能表示他们夹角的变小。也可能是
|θt|
变大了。
证:
根据上述的性质,我们可以求算
θbest
与
θt
的夹角的余弦值,从
θ0
开始,经过t次错误更正,变成
θt
。
根据上式可得:
由于夹角余弦是小于等于1的,我们可以有:
1≥θbestθt|θbest||θt|≥t√*const常数
上面的不等式告诉我们两点:
- PLA能够帮助 θt 进步,因为 θt 与 θbest 的夹角余弦随着更新错误点的次数 t 的增加而增加, θt 越来越接近 θbest 。
- PLA会停止(halt),因为当数据是线性可分时,经过有限次数的迭代,一定能找到一个能够把数据完美区分开的perceptron。
Pocket Algorithm
当数据线性不可分时(存在噪音),简单的PLA 算法显然无法收敛。我们要讨论的是如何得到近似的结果。即寻找
θg
使错误分类的数据尽可能得少。

与简单PLA 的区别:迭代有限次数(提前设定);随机地寻找分错的数据(而不是循环遍历);只有当新得到的
θ
比之前得到的最好的
θg
还要好时,才更新
θg
(这里的好指的是分出来的错误更少)。
由于计算
θ
后要和之前的
θg
比较错误率来决定是否更新
θg
, 所以pocket algorithm 比简单的PLA 方法要低效。
参考博客:
https://www.douban.com/note/319669984/
http://www.tuicool.com/articles/eeame2















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









