






贝叶斯逻辑回归是一种利用贝叶斯定理进行逻辑回归分析的方法,它允许我们结合先验知识和数据来推断模型参数的概率分布。在传统的逻辑回归中,我们寻找的是能够最大化对数似然函数的参数值,而在贝叶斯逻辑回归中,我们则对参数的概率分布进行推断。
贝叶斯逻辑回归的基本原理可以概括为以下几个步骤:
-
先验分布:首先为逻辑回归的参数(权重)指定一个先验分布。通常,我们会假设权重服从一个高斯分布(正态分布),即每个权重 𝑤𝑖都来自于一个均值为 𝜇 ,方差为
的正态分布。
-
似然函数:在指定了先验分布之后,我们需要计算似然函数,即给定参数和数据,观测到当前数据的概率。在逻辑回归中,似然函数是基于二项分布的,因为响应变量是二元的(0或1)。
-
后验分布:利用贝叶斯定理,结合先验分布和似然函数,计算参数的后验分布。后验分布是模型参数在给定数据下的概率分布。
贝叶斯定理的公式是:
𝑃(𝐴∣𝐵)=𝑃(𝐵∣𝐴)𝑃(𝐴)𝑃(𝐵)
在逻辑回归的上下文中,𝐴 代表参数的某个值,𝐵 代表观测到的数据。 -
模型推断:有了参数的后验分布之后,我们可以进行各种推断,比如参数的预测、模型的预测等。通常,我们会使用后验分布的均值或中位数作为参数的估计值。
-
模型选择:在贝叶斯框架下,还可以通过比较不同模型的证据(marginal likelihood)来选择模型,这涉及到模型复杂度的自然惩罚,有助于避免过拟合。
公式上,如果我们假设权重 𝑤 的先验分布是高斯分布 𝑁(0,),并且假设数据服从逻辑回归模型,那么后验分布可以通过以下公式计算:
𝑃(𝑤∣𝐷)∝𝑃(𝐷∣𝑤)𝑃(𝑤)
其中 𝑃(𝐷∣𝑤)是似然函数,𝑃(𝑤)是先验分布。这个公式的计算通常需要使用数值方法,如马尔可夫链蒙特卡洛(MCMC)方法。
贝叶斯逻辑回归的一个优点是它能够提供更稳健的参数估计,因为它考虑了参数的不确定性,并且可以很自然地处理过拟合问题。然而,这种方法计算量通常比传统逻辑回归大,需要更多的计算资源和技巧来正确实施。
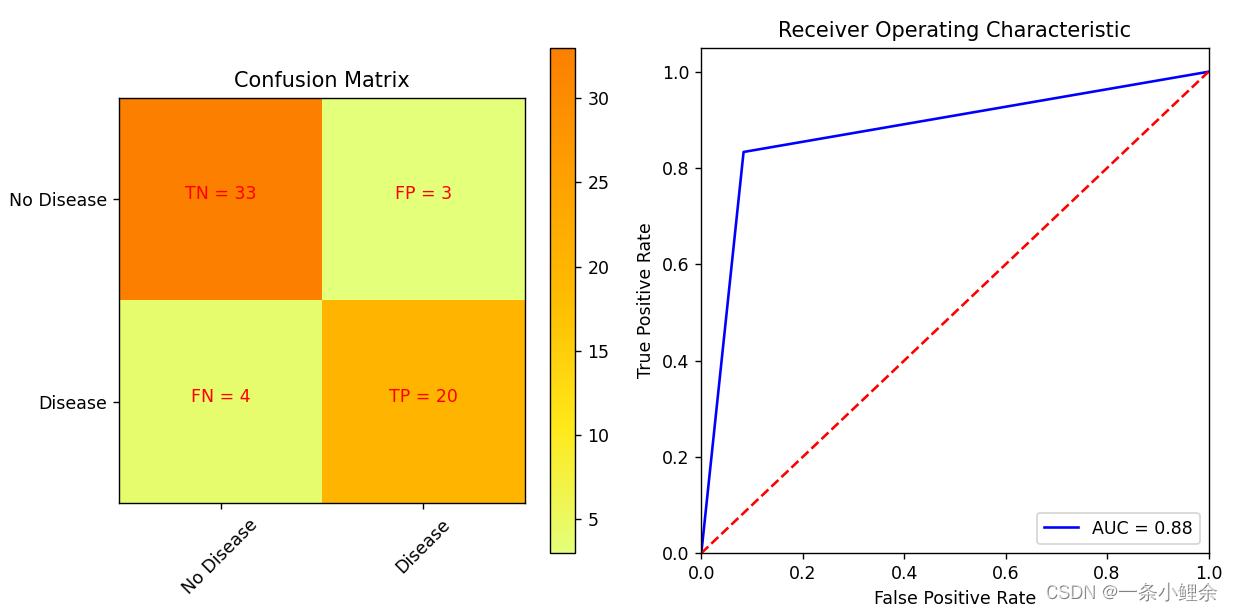
ROC(Receiver Operating Characteristic)曲线是一种统计图表,用于评估二分类模型的性能。它描绘了模型在所有可能的阈值下的真正例率(True Positive Rate, TPR)和假正例率(False Positive Rate, FPR)之间的关系。
真正例率(TPR)和假正例率(FPR)
- 真正例率(TPR),也称为敏感性或召回率,是模型正确识别的正例的比例。计算公式为𝑇𝑃/(𝑇𝑃+𝐹𝑁),其中TP是真正例,FN是假反例。
- 假正例率(FPR) 是模型错误地将反例识别为正例的比例。计算公式为𝐹𝑃/(𝐹𝑃+𝐹𝑃),其中FP是假正例,TN是真反例。
ROC曲线
ROC曲线是通过将模型的阈值从0变到1,并计算每个阈值下的TPR和FPR来绘制的。曲线上的每个点代表了在某个阈值下的TPR和FPR的值。
AUC(曲线下的面积)
ROC曲线下的面积(Area Under the Curve, AUC)是一个重要的性能指标,取值范围从0到1。AUC值越大,模型的性能越好。AUC=0.5表示模型的性能与随机猜测相当,而AUC=1表示完美的分类。
import pandas as pd
# 读取整个数据集
data = pd.read_csv("processed.cleveland.data.csv", header=None)
# 查看数据的基本信息
data_info = data.info()
data_head = data.head()
data_info, data_head
from sklearn.model_selection import train_test_split
from sklearn.linear_model import BayesianRidge
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc, accuracy_score, precision_score, recall_score, f1_score
import matplotlib.pyplot as plt
import numpy as np
# 将数据集分为特征(X)和目标变量(y)
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
y = (y > 0).astype(int) # 将目标变量进行二分类处理
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用贝叶斯逻辑回归模型进行训练
model = BayesianRidge(n_iter=300, alpha_1=1.0, alpha_2=1e-6, lambda_1=1e-6, lambda_2=1.0)
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
y_pred = (y_pred > 0.5).astype(int) # 将预测结果进行二分类处理
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 计算ROC曲线和AUC值
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
roc_auc = auc(fpr, tpr)
# 绘制混淆矩阵
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title('Confusion Matrix')
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Wistia)
plt.colorbar()
classNames = ['No Disease', 'Disease']
tick_marks = np.arange(len(classNames))
plt.xticks(tick_marks, classNames, rotation=45)
plt.yticks(tick_marks, classNames)
s = [['TN', 'FP'], ['FN', 'TP']]
for i in range(2):
for j in range(2):
plt.text(j, i, str(s[i][j]) + " = " + str(cm[i, j]), horizontalalignment='center', color='red')
# 绘制ROC曲线
plt.subplot(1, 2, 2)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1.05])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
# 显示图表
plt.tight_layout()
plt.show()
# 输出准确率、精确率、召回率和F1分数
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(accuracy, precision, recall, f1)















 2194
2194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









