






决策树是一种常用的机器学习算法,主要用于分类和回归任务。它是一种树形结构,其中每个内部节点代表一个特征,每个分支代表一个特征值,每个叶节点代表一个类别标签。
决策树的工作原理是通过一系列规则对数据进行分割,这些规则是基于特征的条件来制定的。从根节点开始,根据特征的某个值来选择一个分支,然后继续这个过程,直到达到叶节点,得到最终的分类结果。
决策树的主要优点是易于理解和解释,可以处理不同类型的特征(数值型和类别型),且不需要进行特征缩放或归一化。但是,决策树容易过拟合,且在处理回归任务时可能不如其他算法准确。
在构建决策树时,通常会使用一些准则来选择最优的特征和分割点,例如信息增益、基尼不纯度或最小化平方误差等。通过这些准则,可以找到一个最优的分割点,使得数据的纯度最高或误差最小。
决策树也有一些改进的算法,如随机森林、梯度提升树和自适应提升等。这些算法通过集成多个决策树来提高模型的准确性和鲁棒性。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import sklearn.metrics as sm
from sklearn.metrics import confusion_matrix
import seaborn as sns
from sklearn import preprocessing
df=pd.read_csv('5-mushrooms.csv',encoding = "utf-8",header = 0)
pd.options.display.max_columns = None
print(np.any(df.isnull()))
df.head(n=5)
X = df.drop(['class'], axis = 1)
Y = df['class']
X = pd.get_dummies(X, prefix_sep='_')
x = df.drop(['class'], axis = 1)
y = df['class']
x = pd.get_dummies(x, prefix_sep='_')
y = preprocessing.LabelEncoder().fit_transform(y)
x = preprocessing.StandardScaler().fit_transform(x)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.7, random_state = 2022)
print(y)
from sklearn import tree
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1
,criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
from sklearn.tree import DecisionTreeClassifier
trainedtree = DecisionTreeClassifier(max_depth=5).fit(x_train, y_train)
y_pre=trainedtree.predict(x_test)
y_pre=np.array(y_pre)
yTest = np.array(y_test)
j=0
for i in range(len(yTest)):
if yTest[i]==y_pre[i]:
j=j+1
print(j/len(y_test))
acc_score = trainedtree.score(x_test,y_test)
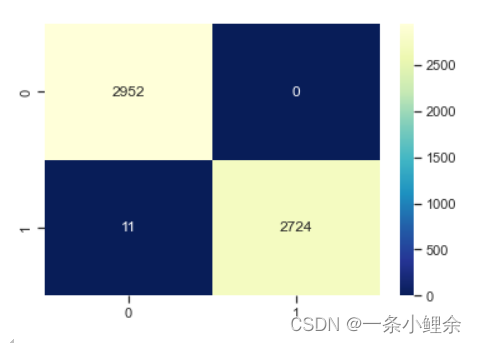
cm = confusion_matrix(y_test,y_pre)
sns.heatmap(cm,cmap="YlGnBu_r",fmt="d",annot=True)
import graphviz
dot_data = tree.export_graphviz(trainedtree, out_file=None) # 导出决策树
graph = graphviz.Source(dot_data) # 创建图形
graph















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









