







本文将学习使用机器学习方法解决结果只有是与非的问题,也就是说可以进行线性划分的方法并且延申出非线性情况下该如何寻找最优解。
注:学习自林轩田机器学习基石国语国语
1.1 银行发卡问题
1.1.1 发卡问题简略说明
如果银行保存有往年信用卡用户的使用情况,面对如下申请信用卡用户的数据,采用何种机器学习方法来确定根据哪些方面来决定是否发放信用卡?(当然,简略了往年信用卡使用情况数据,一定包含以下申请数据)
| 类别 | 数据 |
|---|---|
| 年龄 | 23岁 |
| 性别 | 女性 |
| 年薪 | 1,000,000 新台币 |
| 居住年限 | 1 年 |
| 工作年限 | 0.5 年 |
| 负债 | 200,000 新台币 |
1.1.2 机器学习方法思路理解
以上每行都是作为一个演算的维度,符号命名为 xi ,而每个维度的重要性具有正负性且经过机器学习之后为已知常数具有正负性且经过机器学习之后为已知常数则命名为 wi ,每个维度的数据乘以其重要性,再全部相加得到该个人的申请分数,再与某个临界数值进行比较,确定发卡与否。具体表示公式如下:
发卡设置为:临界数值发卡(设置为1):∑i=1dwixi>临界数值(threshold)
不发卡设置为:临界数值不发卡(设置为−1):∑i=1dwixi≤临界数值(threshold)
发卡,不发卡)y:1(发卡),−1(不发卡)
通过以上公式,我们也可以总结为以下一条假说公式:
h(x)=sign((∑i=1dwixi)−threshold)
临界值由于是通过类似的维度数据转换而来的,那我们就可以将这些维度数据统合称一个维度数据与权重的相加,可转化为 − t h r e s h o l d ⏟ w 0 ⋅ + 1 ⏟ x 0 归入前面的归入前面的 w i 、 x i \underbrace{−threshold}_{w_0}·\underbrace{+1}_{x_0}归入前面的归入前面的w_i、x_i w0 −threshold⋅x0 +1归入前面的归入前面的wi、xi 中。
简化为:h(x)=sign(∑i=0dwixi))
向量化处理: h ( x ) = s i g n ( ∑ i = 0 d w T x ) ) h(x)=sign(\displaystyle \sum^{d}_{i=0}w^Tx)) h(x)=sign(i=0∑dwTx))
补充一下:
-
h(x)最后转化为第0维到更高维的两个向量内积结果的判断,不过这只是公式的简化,而非改变了其内在的公式逻辑思路。
-
sign 表示判断结果是否为正值,是为 1,否为 -1。
-
h(x) 又被称为感知器,可在二维图像中表现为一条直线,在三维空间中表现为一个平面,正是这样具有划分切割的特征,它又叫线性感知器。
方便理解,二维图像展示:
h ( x ) = s i g n ( w 0 ⋅ ( + 1 ) + w 1 x 1 + w 2 x 2 ) :分类直线 h(x)=sign(w_0·(+1)+w_1x_1+w_2x_2):分类直线 h(x)=sign(w0⋅(+1)+w1x1+w2x2):分类直线
由于经过机器学习训练, w i w_i wi 都为已知数据,故 h(x) 就是以 w 0 w_0 w0 为截距,关于 x 的直线方程。x 确定图像中点的位置,而 x 对应的判断结果(1,+1),将决定是绘制成什么形状。

蓝圈为发卡(+1),红叉为不发卡(-1),分界直线为 h(x)
1.1.3 类似案例分析
同样类似的还有垃圾邮件的拦截,邮件文本中的每一个词都是一个个的维度(存在为 1,不存在为 0),它们组成了一个一长串的维度向量,而判断每一个词与是否是垃圾邮件的关联度又是对应的权重,也组成了一长串的权重向量。通过同样的操作也能够完成对于垃圾邮件的判断。


1.2 机器学习中目标函数与假说公式
在未知的目标函数 f 中,我们要如何验证学习所得到的假说公式 g 能够基本与目标函数 f 相似。当然,目前只有已经经过训练的数据,所以,我们可以先将假说公式 g 的的结果与目标函数 f 作用下的结果(未知过程,但存在结果)进行比较,基本结果相等,可以简单说明两者基本相似,而且,仅仅建立在已训练数据的结论,未加入的数据下可能存在不同的结论。这是验证两者相似的基本思路。当然,这很麻烦,数据量庞大所产生的假说公式数量极多,我们无法全部包含地去一一验证比较,并且也无法更好地确定那一条是可能全局最优的结论。
那我们可以换种思路,如果无法一一去验证全部,那可以让一条可能不是最优的假说公式,通过不断地优化,使得它越来越符合预期。

也就像上图,在假说公式的划分下,下半部分仍存在一个不该存在的蓝圈,这是一个错误,我们可以尝试将假说公式的划分线进行移动,使得错误变得合理化。正是这样的一步步地修正,假说公式迟早会符合预期。那我们要怎样去修正呢?

首先,假设此时的 g 0 g_0 g0 为 w 0 w_0 w0 ,即未修正的假说公式,通过某些遍历方式(由于修正之后会影响已有的点,可能需要经过多次修正),每次遍历数假设为 t,即第 n 个点第 t 次被遍历到可表示为 ( x n ( t ) , y n ( t ) ) (x_{n(t)},y_{n(t)}) (xn(t),yn(t))判断是否存在错误,可如下判断:
s i g n ( W t T x n ( t ) ) ≠ y n ( t ) sign(W^{T}_{t}x_{n(t)})\neq y_{n(t)} sign(WtTxn(t))=yn(t)
由于方程ax+by+cz=d表示的平面,向量(a,b,c)就是其法线。故 w 向量为分类直线的法向量
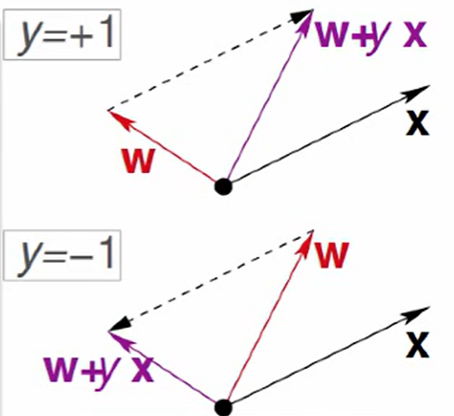
首先随机选择一条直线进行分类。然后找到第一个分类错误的点,也就是判断学习的结果与本应该的结果是否相等,若不相等,进行修正,修正公式为 w t + 1 = w t + y ⋅ x w_{t+1}=w_{t}+y·x wt+1=wt+y⋅x。
当正确结果 y 为 +1 时,学习结果 w (-1),即 W t T x n ( t ) ≤ 0 W^{T}_{t}x_{n(t)}\leq 0 WtTxn(t)≤0 , 两向量相乘结果表示为两者夹角的余弦值,即 w 与 x 的夹角超过九十度,x被误分到直线的下方(相对于法向量,法向量的方向即为正类所在的一侧),与正确结果夹角(小于九十度)较大,修正的方法就是使w和x夹角小于90度,由于 y ⋅ x y·x y⋅x 表示两个向量之间的夹角,经过计算会减低 w 与 y 的夹角,一次或多次更新后的与x夹角 w = w + y ⋅ x w=w+y·x w=w+y⋅x 小于90度,能保证x位于直线的上侧,则对误分为负类的错误点完成了直线修正。反之亦然。继续寻找下一个错误点,循环遍历,直至线性可分。
要注意一点:每次修正直线,可能使之前分类正确的点变成错误点,这是可能发生的。但是没关系,不断迭代,不断修正,最终会将所有点完全正确分类(PLA前提是线性可分的)
当然,如果实际情况无法做到线性可分的话,可以设置误差阈值,只要小于误差阈值就可以认为已经线性划分完成。这个算法也叫感知器算法(PLA),通过改错修正完成优化。
补充一下:
线性代数——向量、向量加法、向量数乘_HerdingCat的博客-CSDN博客_向量相乘
感知器算法_okiwilldoit的博客-CSDN博客_感知器算法
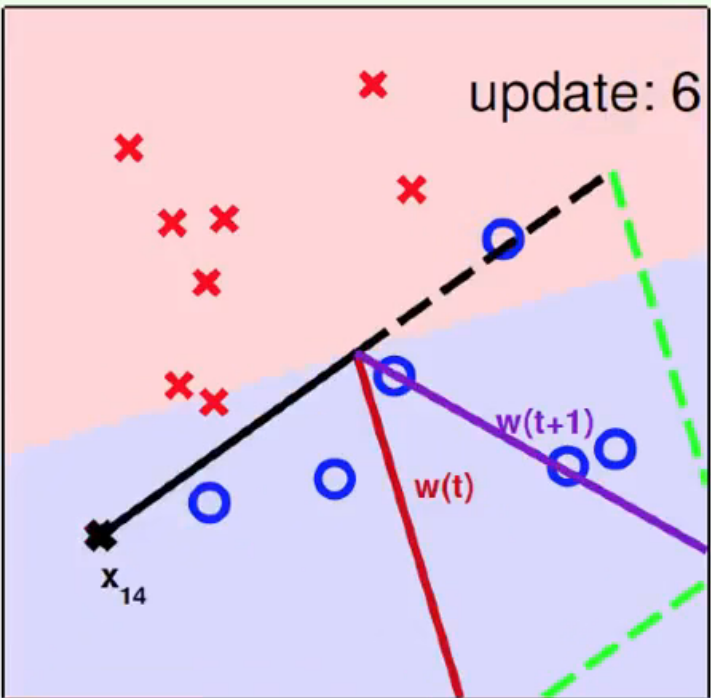
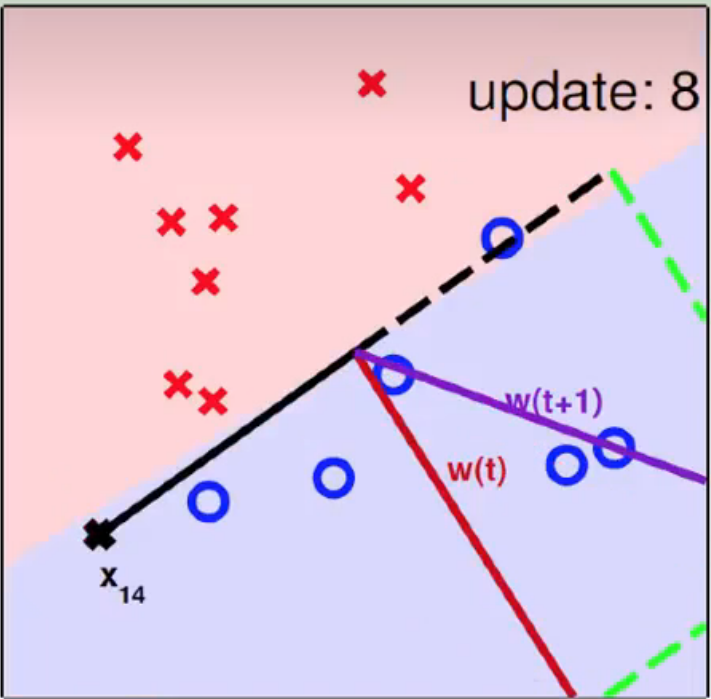
运行图示如下:
初始状态
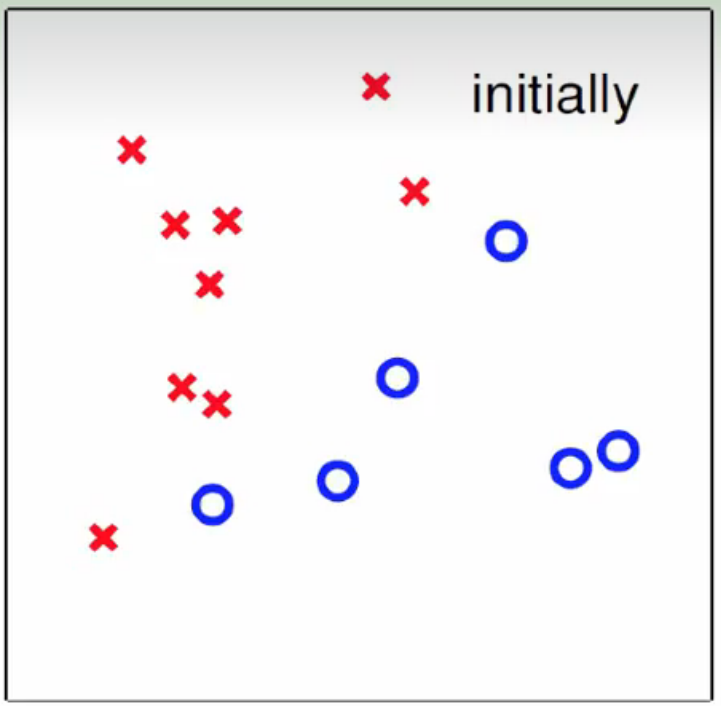
中心为原点,选取某一个数据点,连接成随机选取第一条分类直线,基本是错的,开始修正

由于选取了一个数据点作为初始直线的一部分,所以下一条分类直线等于法向量 w
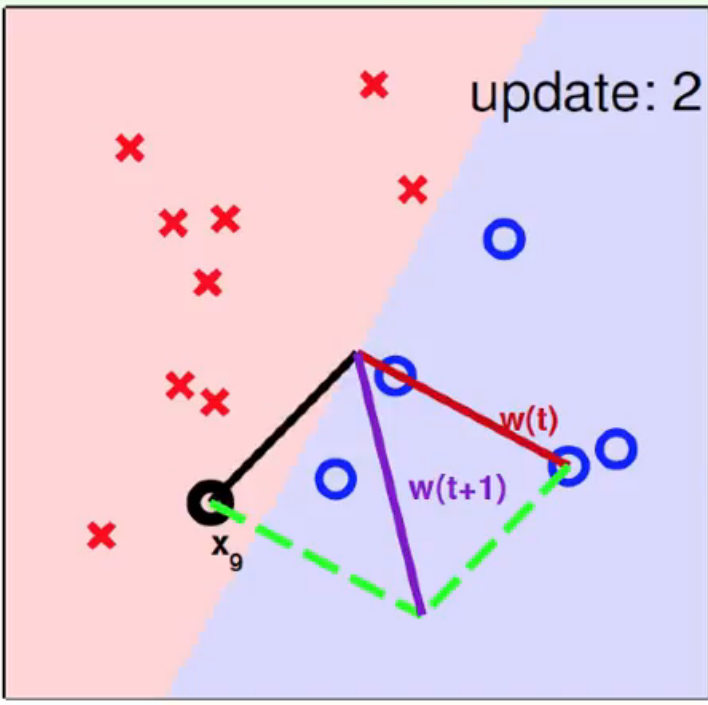
x 9 x_9 x9 为分类错误点,夹角过大,向法向量方向移动

x 14 x_{14} x14 为分类错误点,夹角过小,向法向量反方向移动
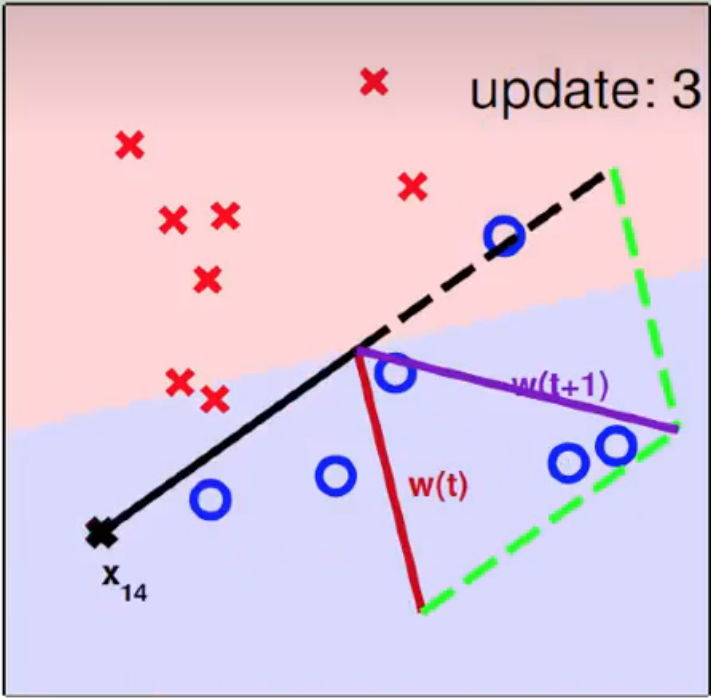
重复几次,如下:



1.3 感知机(感知器)算法 PLA
1.3.1 线性可分情况下,PLA 是否会停止?

前文提到 PLA 算法可能存在无法线性可分的情况,如果没有进行任何补充修正的话,PLA 算法可能会一直进行下去,无穷无尽地进行划分。那凭什么线性可分的情况下,PLA 一定会停下来?
还是同样的例子(发卡案例),已知如下结论:
假设 g ≈ w f g\approx w_f g≈wf 且数据集线性可分的情况下:
分类错误点: s i g n ( w t T x n ) ≠ y n sign(w^T_tx_n)\neq y_n sign(wtTxn)=yn
w t + 1 = w t + y n x n w_{t+1} = w_t + y_nx_n wt+1=wt+ynxn
假设 w t + 1 ⋅ x n y n 且 w t ⋅ x n y n w_{t+1} · x_ny_n 且 w_t · x_ny_n wt+1⋅xnyn且wt⋅xnyn可得:
w t + 1 ⋅ x n y n = x n w t + 1 y n + ( x n y n ) 2 w_{t+1} · x_ny_n = x_n w_{t+1}y_n+(x_ny_n)^2 wt+1⋅xnyn=xnwt+1yn+(xnyn)2
即 w t + 1 x n y n ≥ w t x n y n 即\,w_{t+1}x_ny_n \geq w_tx_ny_n 即wt+1xnyn≥wtxnyn
易知 y n ( t ) w f t X n ( t ) ≥ n m i n y n w n t x n > 0 y_{n(t)}w^t_fX_{n(t)}\geq \stackrel{{min}}{n}y_nw^t_nx_n >0 yn(t)wftXn(t)≥nminynwntxn>0 表示距离,后者表示在所有点中,离线最近的点。
某个角度(观点)下,衡量向量接近的一个方法就是将两个向量进行内积(余弦值),越大越接近。想要得到新的分类直线与期望分类直线的区别(可能是长度,可能是方向的区别),可以采用 w f t ⋅ w t + 1 w^t_f·w_{t+1} wft⋅wt+1 的方式进行验证。如下:

当然,这只是第一步,我们想要知道的是它们在方向上的区别,所以需要进一步论证。已知分类错误情况下 s i g n ( w t T x n ) ≠ y n sign(w^T_tx_n)\neq y_n sign(wtTxn)=yn 即左右两边异号,可得 w t ⋅ x n y n ≤ 0 w_t · x_ny_n \leq 0 wt⋅xnyn≤0 。
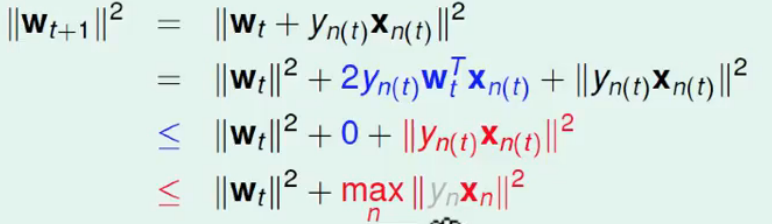
由于 y = + 1 或 − 1 y=+1\,或-1 y=+1或−1 且 x n , y n x_n,y_n\, xn,yn为错误点的值,其中, y n y_n yn 的平方值不影响 w t w_t wt 的变化, w t w_t wt 只会在分类错误的情况下更新,综上可得, w t + 1 w_{t+1} wt+1 的变化与 x n x_n xn 相关性最大。最终得到的 ∣ ∣ w t + 1 2 ∣ ∣ ||w^2_{t+1}|| ∣∣wt+12∣∣相比的 ∣ ∣ w t 2 ∣ ∣ ||w^2_t|| ∣∣wt2∣∣增量值不超过 m a x ∣ x n 2 ∣ max|x^2_n| max∣xn2∣。也就是说, w t w_t wt 增长被限制了, w t + 1 w_{t+1} wt+1与 w t w_t wt向量长度不会差别太大!
所以, w f t ⋅ w t + 1 w^t_f·w_{t+1} wft⋅wt+1 不是代表长度之间的差异,而是代表角度、方向的差异。
如果令初始权重 w 0 = 0 w_0 = 0 w0=0,那么经过 T 次修正之后,有以下结论:
w f T ∥ w f ∥ w T w T ≥ T ⋅ constant \frac{w_{f}^{T}}{\left\|w_{f}\right\|} \frac{w_{T}}{w_{T}} \geq \sqrt{T} \cdot \text { constant } ∥wf∥wfTwTwT≥T⋅ constant
注:constant 为常数
推导过程如下:


上述不等式左边其实是 w t w_t wt 与 w f w_f wf 夹角的余弦值,随着T增大,该余弦值越来越接近1,即 w t w_t wt 与 w f w_f wf 越来越接近。同时,需要注意的是, T ⋅ constant ≤ 1 \sqrt{T} \cdot \text { constant } \leq 1 T⋅ constant ≤1,也就是说,迭代次数T是有上界的。根据以上证明,我们最终得到的结论是: w t w_t wt 与 w f w_f wf的是随着迭代次数增加,逐渐接近的。而且,PLA最终会停下来(因为T有上界),实现对线性可分的数据集完全分类。
感知器算法虽然简单,但是,由于我们无法事先得知 w f w_f wf 具体是多少?所以我们无法知道究竟该数据集是否线性可分。并且,在线性不可分的情况下,前面的所有推论完全不成立,此时,PLA 也不一定会停下来。即使 PLA 会停下来,我们也无从得知具体会进行多久(推导使用到的 ρ \rho ρ 代表运行时间,是建立在 w f w_f wf 计算来的),无从计算。弊端很明显,我们不知道是没跑够时间,还是数据集无法线性可分。
1.3.2 非线性可分下,我们如何去寻求最优解
对于非线性可分的情况,我们可以把它当成是数据集D中掺杂了一下 noise(噪声),事实上,大多数情况下我们遇到的D,都或多或少地掺杂了 noise。这时,机器学习流程是这样的:

此时,我们就需要去容忍犯错,也就是取错误点个数的权重 w w w 最少的情况。然而,事实证明,上面的解是 NPhard 问题,难以求解。
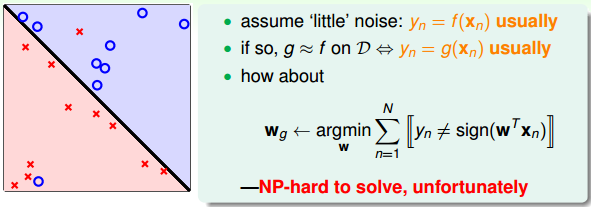
修改后的PLA称为Packet Algorithm。它的算法流程与PLA基本类似,首先初始化权重 w 0 w_0 w0,计算出在这条初始化的直线中,分类错误点的个数。然后对错误点进行修正,更新w,得到一条新的直线,在计算其对应的分类错误的点的个数,并与之前错误点个数比较,取个数较小的直线作为我们当前选择的分类直线。之后,再经过n次迭代,不断比较当前分类错误点个数与之前最少的错误点个数比较,选择最小的值保存。直到迭代次数完成后,选取个数最少的直线对应的w,即为我们最终想要得到的权重值。
2.1 PLA(感知器算法)延伸
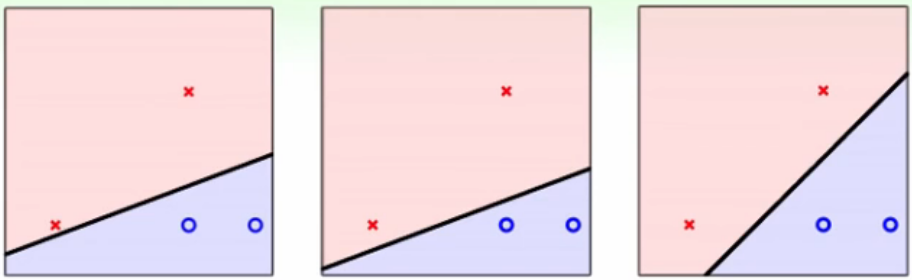
哪个才是最好的?

















 6501
6501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











