






1.PASCAL数据集
有关目标检测,目标分类,目标分割,动作识别。
1.)下载的数据集文件介绍

标注信息:.xml文件实例:
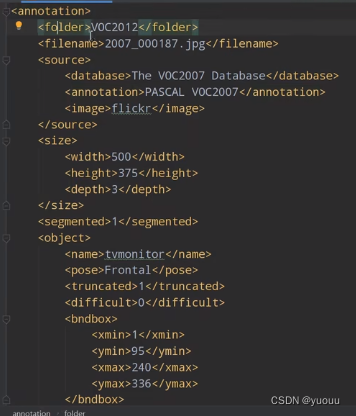
<segmented> 1:被分割 0:没有被分割
<object>: <truncated> 1:目标被截断 <difficult> 1:检测的难易程度较难 <bndbox>:检测目标的左上与右下坐标
main中除了train和val以及trainval之外还有一系列的.txt文件,比如:
boat_train.txt : 2008_000122 (0/-1/1) 1:有目标 -1:无目标 0:检测出来有困难
2)标注图片:
![]()

可以直接pip install labelImg , 若要修改源码则可下载原文件。
步骤: 新建文件夹----里面包括标注信息保存文件夹,图片保存文件夹,类别信息.txt文件
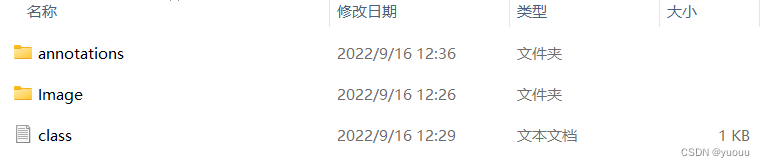
在当前文件夹下打开PowerShell , 输入labelImg ./ image ./class.txt
选中图片文件夹
点击change save dir (设置标注文件的保存位置 已设置好)
再点击create\nRectbox 框选出图片中的目标,框选成功后选取类别 选取成功后可以在BOXLABEL中勾选是否难以检测。接着框选其他目标 ,全部标记成功后点击save。
标注完图片,若想要训练文件,需要自己生成train.txt 与 val文件,生成后既可放入训练。
2.coco数据集以及pycocotools使用:

其中80个目标类别与91个材料类别中80与91的区别是:
stuff:包含了没有明确边界的材料与对象(天空)
80 object categories 是 91 stuff categories的子集,如果只用于目标检测则只需要80 object categories。
与PASACL的对比:
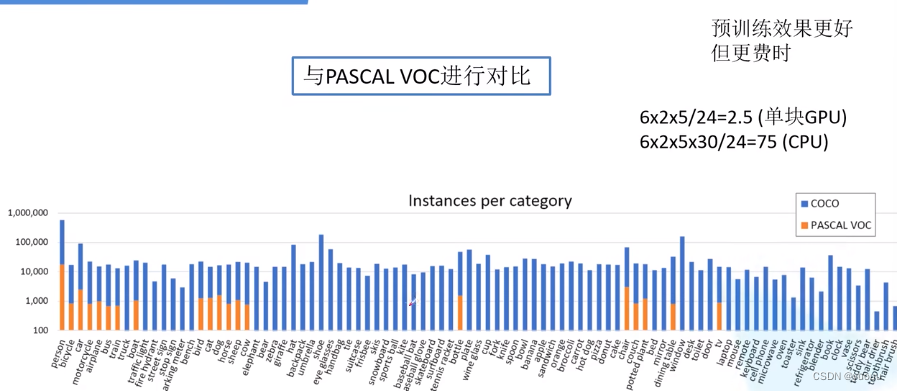
coco的官方网址:
https://cocodataset.org/
目标检测所需要下载的文件:

将文件全部进行解压,并放入coco文件夹中:

官方给出的标注文件的格式说明,可通过:https://cocodataset.org/#format - data 查看
示例:简单读取 instances_val2017.json文件
读取代码(设置断点):
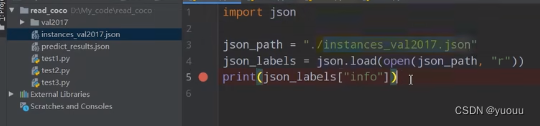

info:

数据集描述、地址、版本、年份等
images(对应的所有图片):
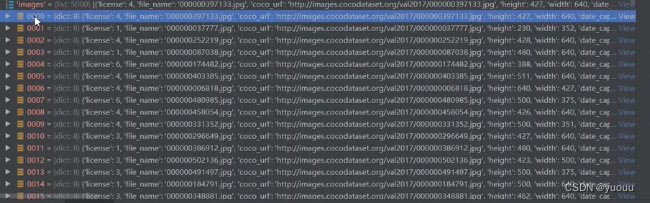
图片信息:
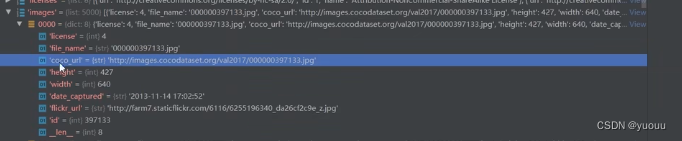
图片名称、图片下载、高度、宽度、创立时间、来源地址、图片id
annotation:

每个元素仅仅是一个目标,而不是一张图片下对应的所有目标。

segmentation:分割信息 、面积、是否是单个目标(目标重叠则为1)、bbox(x,y,w,h):前两个为左上xy坐标,后两个数据为框的宽度与高度。 、对应类别的索引(相对于91)
categories:
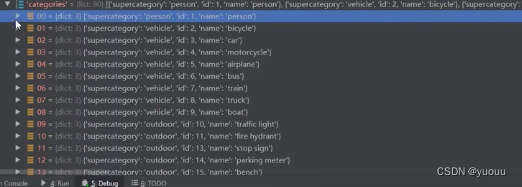
对应80个类别 其中索引是针对91个stuff categories 故检测时要考虑映射。
2.使用pycocotools工具读取标注文件
安装pycocotools: pip install pycocotools-windows
代码块:
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = './instances_val2017.json'
img_path = './val2017'
# 下载coco数据标注信息
coco = COCO(annotation_file = json_poth)
# 获取图像数据集
ids = list(sorted(coco.imgs.keys()))
print("number of image: {}".format(len(ids)))
# 获取coco分类标签
coco_classes = dict([(v['id'],v['name']) for k, v in coco.cats.items()])
# 遍历前三张图片
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息(就是集中一张图片的所有目标信息)
ann_ids = coco.getAnnIds(imgIds = img_id)
# 根据annotation idx获取所有标注信息
targets = coco.loadAnns(ann_ids)
# 获取图像文件夹的名字
path = coco.loadImgs(img_id)[0]['file_name']
# 读取图片
img = Image.open(os.path.join(img_path, path)).convert('RGB')
draw = ImageDraw.Draw(img)
# 检测框
for target in targets:
x, y, w, h, = target['bbox']
x1, y1, x2, y2 = x, y, int(x+w), int(y+h)
draw.rectangle((x1, y1, x2, y2))
draw.text((x1,y1), coco_classes[target['category_id']])
# 展示图片
plt.inshow(img)
plt.show()验证map:
首先登陆coco的官网,在Evaluate中选择results format
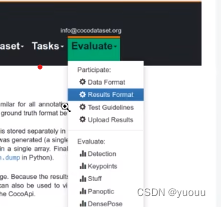
给出了每种任务给定的数据格式要求,例如目标检测

根据之前的instances_val2017_json文件与现在生成的predict_results_json文件进行对比
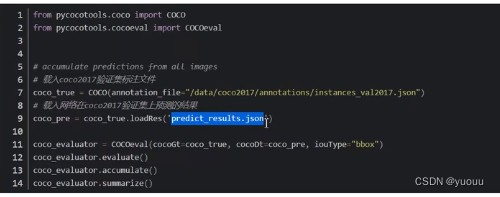
执行完后可得:
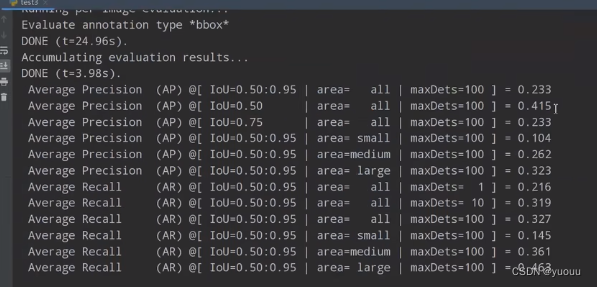
3. 目标检测mAP计算以及coco评价标准


绿色的是人为标注,红色的是预测框

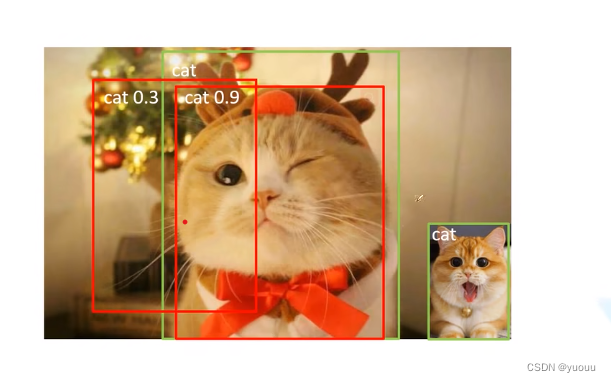
TP:(红色cat 0.9)true positive 此时lou > 0.5
FP: (红色cat 0.3)
FN: (右下角没有检测到的cat)
注:每个类别都需要取AP值

GT ID:检测目标的id confidence: 概率值 IOU:(交并比)重合率 OB:是否正确检测目标
之后继续对图片检测:
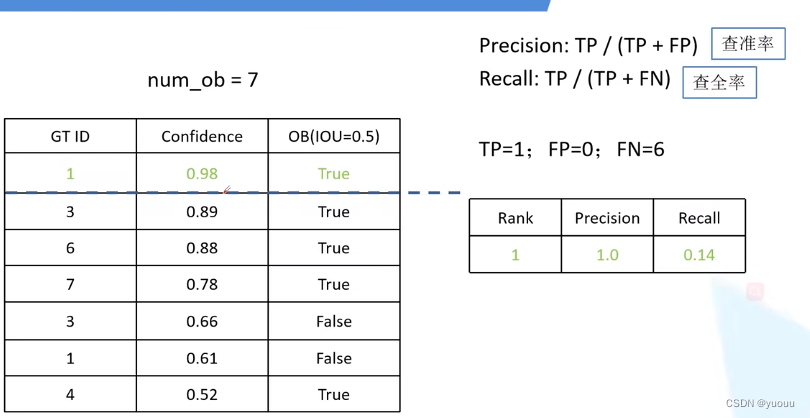
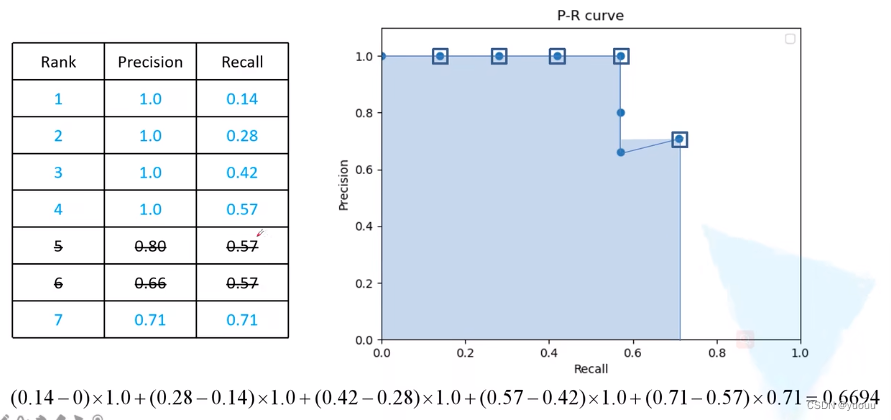
Recall=0.57时, 取Precision最大的值。 得到猫这个类别的AP值为0.6694。
coco官网说明评价指标:https://cocodataset.org/#detection-eval

AP (IOU :0.5-0.95中以0.05为步长)计算出十个AP的均值mAP
AP针对小、中、大目标,针对不同尺度的检测的效果。
每个图片最多取1 、10、100个目标对应的AR均值
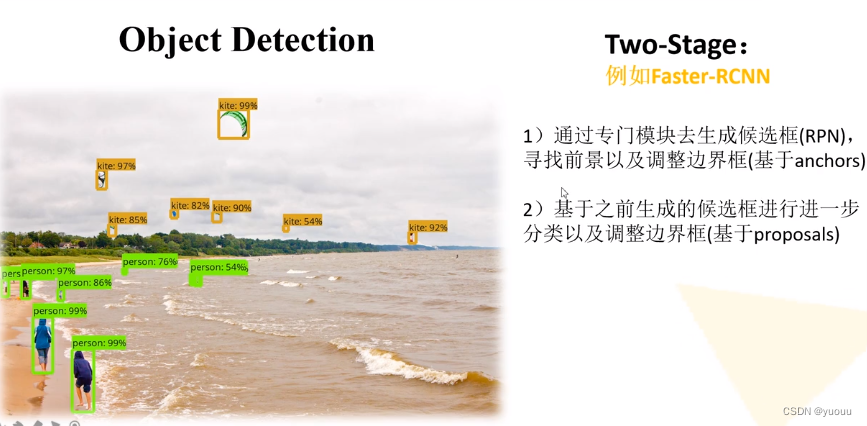
3.目标检测前言
one-stage : SSD、YOLO two-stage: Faster-RCNN

















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









