







关于mmdetection框架,根据其config文件,可以将模型分为Backbone、Neck、Bbox_head几个模块。其中:
- Backbone指的是模型的主干网络,主要用来特征提取;
- Neck主要用来做特征融合,以FPN(特征金字塔)为代表;
- Bbox_head指的是目标检测或者目标分割等任务的头部,分为分类和回归两个子任务。
本文用SwinTransformer作为Backbone,FPN作为Neck,TOOD模型作为Bbox_head,并加入一系列的模型调优策略,得到目前单GPU最优精度模型。
TOOD: Task-aligned One-stage Object Detection
针对目前模型的分类与定位任务交互少,导致预测不一致的问题,TOOD设计一个新的 head 结构来更好的将分类和定位任务对齐。
首先,任务对齐head在FPN 输出特征中进行分类和定位;
然后,采用任务对齐学习(TAL)用对齐度量参数来计算两者的对齐信号(alignment signal);
最后,在反向传播中使用对齐信号动态调整分类的得分和定位的位置,从而在预测过程中对两个任务进行对齐,为任务交互以及任务相关特征提供更好的平衡,提升模型的精度。
- 在分类头部用QualityFocalLoss代替FocalLoss作为分类损失,兼顾分类得分和质量评估得分,这样可以保证训练和测试的一致性,从而解决模型类别不均衡问题。
- 在回归头部用GIoULoss作为回归损失
- 设计了TaskAlignedAssigner进行正负样本分配
一、Backbone模块
1、SwinTransformer_small
大名鼎鼎的SwinTransformer系列特征提取网络,现有三个版本:Large、Small、Tiny。当然,用SwinTransformer_large训练的模型精度最优,但是模型太大,用实验室的单GPU跑不起来。
backbone=dict(
type='SwinTransformer',
embed_dims=96,
depths=[2, 2, 18, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
mlp_ratio=4,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
patch_norm=True,
out_indices=(1, 2, 3),
with_cp=False,
convert_weights=True,
init_cfg=dict(
type='Pretrained',
checkpoint=
'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth'
)),
2、SwinTransformer_large
backbone=dict(
type='SwinTransformer',
pretrain_img_size=384,
embed_dims=192,
depths=[2, 2, 18, 2],
num_heads=[6, 12, 24, 48],
window_size=12,
mlp_ratio=4,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.2,
patch_norm=True,
out_indices=(1, 2, 3),
# Please only add indices that would be used
# in FPN, otherwise some parameter will not be used
with_cp=False,
convert_weights=True,
init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
3、ResneXt101+DCNv2
mmdetection中最常见的高精度backbone网络,算是ResNeXt系列的顶配。
backbone=dict(
type='ResNeXt',
depth=101,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d'),
groups=64,
base_width=4,
dcn=dict(type='DCNv2', deformable_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, False, True, True)),
DCN模块
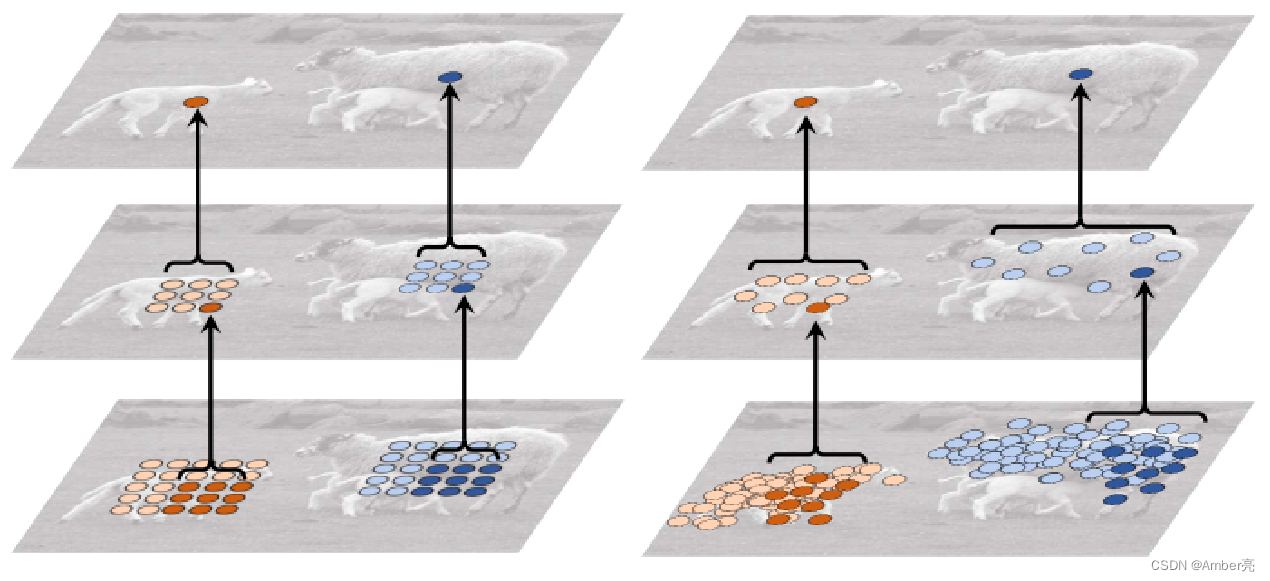
DCN能在模块中增加空间采样位置,并从目标任务中学习偏移量。
如下图分别是**标准卷积(左图)和可变形卷积(右图)**产生的感受野的采样点位置。由图可知,相比于标准卷积, 可变形卷积更能提取图像中的感兴趣区域。
二、Neck模块
Neck模块中通常用的是**FPN(特征金字塔)**及其改良版,比如:PAFPN (CVPR’2018)、NAS-FPN (CVPR’2019)、CARAFE (ICCV’2019)、FPG (ArXiv’2020)
1、SwinTransformer主干网络的FPN(SwinTransformer_small)
neck= dict(
type='FPN',
in_channels=[192, 384, 768],
out_channels=256,
start_level=0,
add_extra_convs='on_output',
num_outs=5),
2、Resnet主干网络的FPN
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_output',
num_outs=5),
三、Bbox_head模块
Bbox_head部分有非常之多的论文进行改进,比如双阶段的FasterRCNN、Cascade模型,单阶段的ResNet、FCOS、VFNet等等。我们用的是TOOD: Task-aligned One-stage Object Detection的bbox_head架构。
bbox_head=dict(
type='TOODHead',
num_classes=6,
in_channels=256,
stacked_convs=6,
feat_channels=256,
anchor_type='anchor_free',
anchor_generator=dict(
type= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









