







文本分类
基于规则的方法
人工为不同类别的文本指定划分规则,例如:
IF there exists word w in document d such that w in [good, great, extra-ordinary, …],
THEN output Positive
IF email address ends in [ithelpdesk.com, makemoney.com, spinthewheel.com, …]
THEN output SPAM
- 比较准确(人工制定的规则)
- 规则很难全面,有些规则可能不为人所知
- 价格昂贵
- 不容易推广
监督学习的方法
- 输入:
- m个分类
- n个已标记好分类的文本
- 输出:
- 一个函数F,实现从文本到分类的映射(通过学习得到)

基本流程
文本预处理
去噪、分句、分词、去停词、取词干、特征选择、词加权
- 过滤:去掉特殊字符、标点符号等
- 标记化:将句子切分为单独的字符,通常为单词
- 去停用词:去掉不重要或无意义的通用词
- 词形还原:保留词语的核心意义==(情感分类需要做词形还原)==
- 剪枝:删除低频词
文本表示
把自然语言文本转换为一种能够被计算机或算法识别和处理简洁的格式
向量空间模型
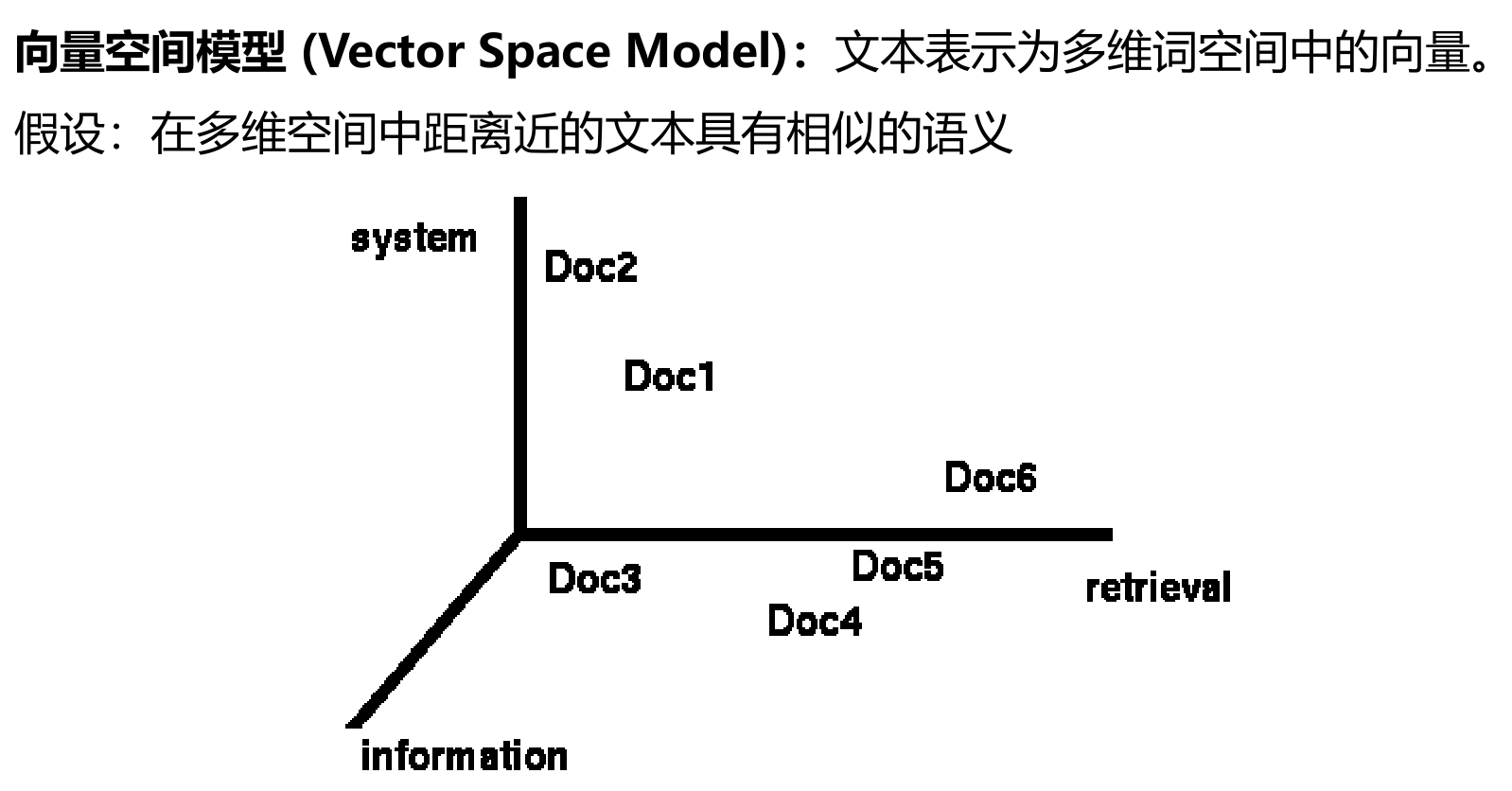

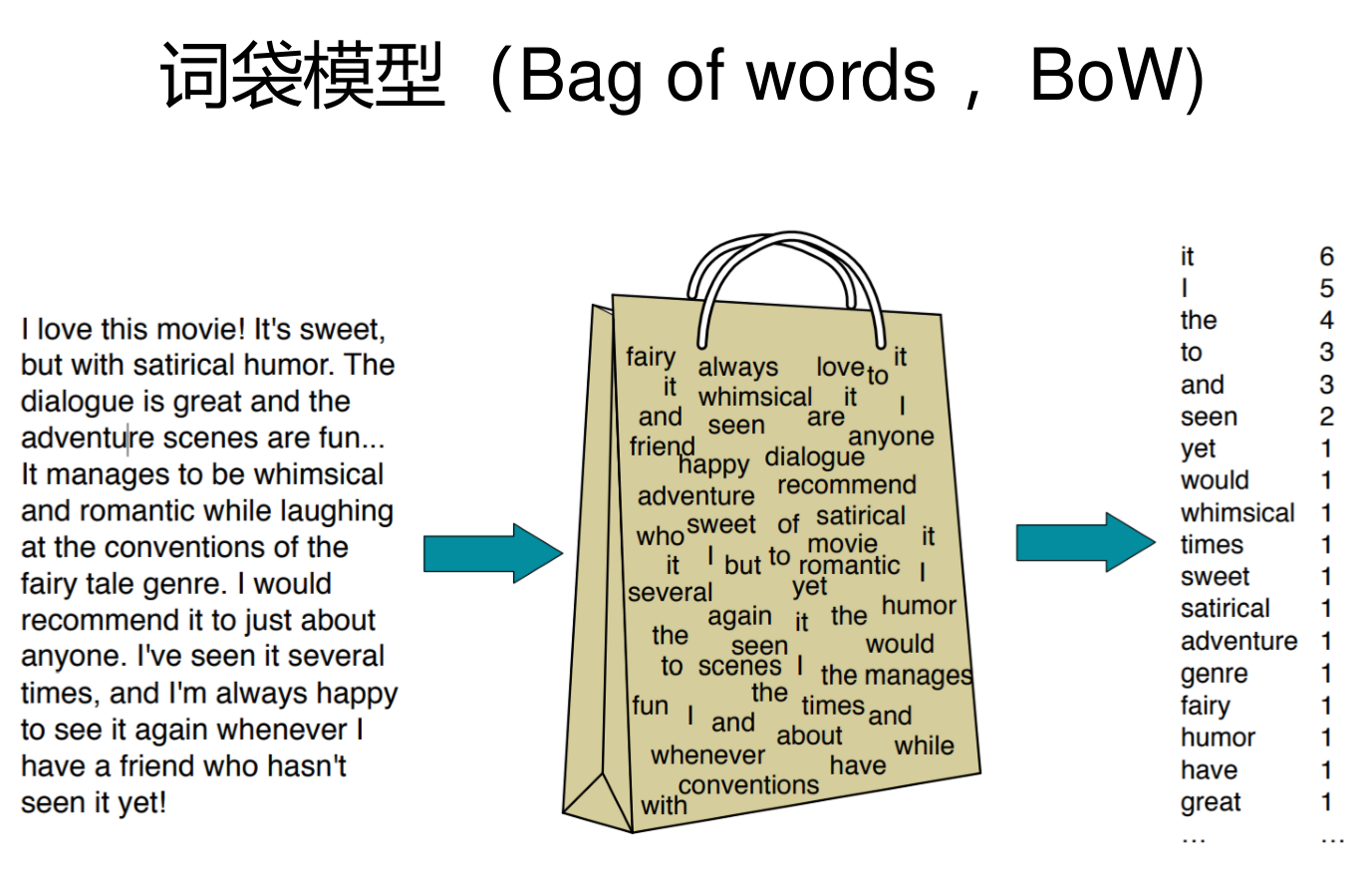
词袋模型
忽略了文本的内容(不考虑语义),只考虑在相应词表中出现的词的个数
词袋模型是空间向量模型的一个特例
基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。
简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
- 输入文本集
- 其中包含200个document
- 每个document运用词袋模型进行文本表示,形成每个文本的特征向量 ( f 1 , f 2 , … , f 99 ) (f_1,f_2,\ldots,f_{99}) (f1,f2,…,f99)
- 最终得到下图中的文本特征矩阵

特征提取
根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益、 χ 2 \chi^2 χ2统计量等
MLE与Naive Bayes实现情感分类
- 给定训练数据中的
<x, y>对,我们可以训练一个模型来估计新的数据的类概率 - 通过一组单词(特征)表示(假设其中每个单词(特征)独立于另一个单词(特征)),我们可以使用极大似然估计和Naïve Bayes来预测
- 这两类方法准确度逊色于其他模型,但是速度快,是其他模型的基础
最大似然估计分类 MLE
比较每个类别下数据的可能性,然后选择可能性最高的类别
例如:类别为
y
y
y的数据
X
X
X发生的概率
P
(
X
=
(
x
1
,
x
2
,
…
,
x
n
)
∣
Y
=
y
)
P(X=(x_1,x_2,\ldots,x_n)|Y=y)
P(X=(x1,x2,…,xn)∣Y=y)
条件概率
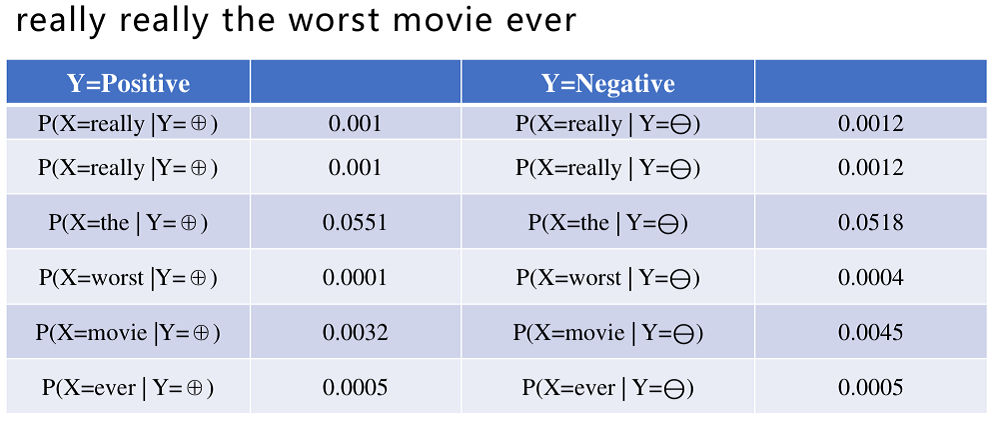
P ( X i = really ∣ Y = p o s i t i v e ) P(X_i=\text{really}|Y=positive) P(Xi=really∣Y=positive)
独立性假设
- 假设每个词的位置不重要
- 词与词之间在给定类别C的下是条件独立的
P ( w 1 , w 2 , … , w n ∣ c ) = ∏ i = 1 n P ( w i ∣ c ) P(w_1,w_2,\ldots,w_n|c)=\prod_{i=1}^{n} P(w_i|c) P(w1,w2,…,wn∣c)=i=1∏nP(wi∣c)
例如:
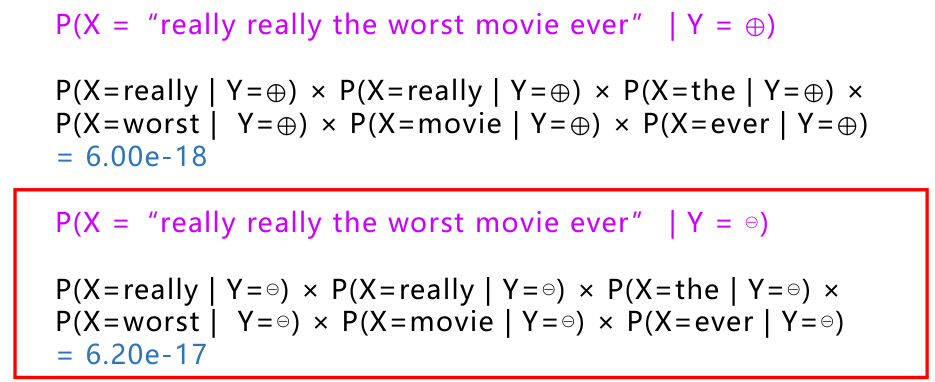
对数似然
乘以许多小概率(都小于1)会导致数值下溢(收敛到0)
log
∏
i
=
1
n
P
(
w
i
∣
c
)
=
∑
i
=
1
n
log
P
(
w
i
∣
c
)
\log{\prod_{i=1}^{n}P(w_i|c)}=\sum_{i=1}^{n}\log{P(w_i|c)}
logi=1∏nP(wi∣c)=i=1∑nlogP(wi∣c)
贝叶斯分类器
P ( Y = y ∣ X = x ) = P ( Y = y ) P ( X = x ∣ Y = y ) ∑ y P ( Y = y ) P ( X = x ∣ Y = y ) P(Y=y|X=x) =\frac{P(Y=y)P(X=x|Y=y)}{\sum_y P(Y=y)P(X=x|Y=y)} P(Y=y∣X=x)=∑yP(Y=y)P(X=x∣Y=y)P(Y=y)P(X=x∣Y=y)
- 需要求的概率:已知
X
X
X,判定
Y
Y
Y的分类为
y
y
y的概率(即贝叶斯估计的后验概率)
- 为了将概率转化为分类决策,我们只需选择具有最高后验概率的标签
y
^
\hat{y}
y^
y ^ = a r g m a x y ∈ Y P ( Y ∣ X ) \hat{y}=argmax_{y\in Y}P(Y|X) y^=argmaxy∈YP(Y∣X)
- 为了将概率转化为分类决策,我们只需选择具有最高后验概率的标签
y
^
\hat{y}
y^
- P ( Y = y ) P(Y=y) P(Y=y)是类别 y y y的先验概率,一般基于训练集得到
- P ( X = x ∣ Y = y ) P(X=x|Y=y) P(X=x∣Y=y)是类别为 y y y的数据 X X X发生的概率的最大似然估计
例如:

朴素贝叶斯 Naive Bayes
原理
原理基于贝叶斯分类器
- 记 C C C为所有类的集合, D D D为文本集
- c M A P c_{MAP} cMAP指"maximum a posteriori",即最可能的类
c M A P = a r g m a x c ∈ C P ( c ∣ d ) = a r g m a x c ∈ C P ( d ∣ c ) P ( c ) P ( d ) ∝ a r g m a x c ∈ C P ( d ∣ c ) P ( c ) \begin{split} c_{MAP} &=argmax_{c\in C}P(c|d)\\ &=argmax_{c\in C}\frac{P(d|c)P(c)}{P(d)}\\ &\propto{argmax_{c\in C}P(d|c)P(c)} \end{split} cMAP=argmaxc∈CP(c∣d)=argmaxc∈CP(d)P(d∣c)P(c)∝argmaxc∈CP(d∣c)P(c)
注:
- P ( d ∣ c ) P(d|c) P(d∣c)指类别为 c c c的条件下,产生文本 d d d的条件概率
- P ( c ) P(c) P(c)指类别 c c c的先验概率
- 由于我们只需要选择出最可能的类,因此不需要考虑 P ( d ) P(d) P(d),也就是说不用计算出具体的概率值,只需要比较不同类的概率大小
如何估算概率
给定标记好的训练集: { ( d 1 , c 1 ) , ( d 2 , c 2 ) , … , ( d n , c n ) } \{(d_1,c_1),(d_2,c_2),\ldots,(d_n,c_n)\} {(d1,c1),(d2,c2),…,(dn,cn)}
其中对于每个文本 d i d_i di,有 d i = ( w 1 , w 2 , … , w k ) d_i=(w_1,w_2,\ldots,w_k) di=(w1,w2,…,wk),表示文本 d i d_i di中有 k k k个词
需要求出:
c
M
A
P
∝
a
r
g
m
a
x
c
∈
C
P
(
c
)
P
(
d
∣
c
)
=
a
r
g
m
a
x
c
∈
C
P
(
c
)
∏
i
=
1
k
P
(
w
i
∣
c
)
c_{MAP}\propto{argmax_{c\in C}P(c)P(d|c)}=argmax_{c\in C}P(c)\prod_{i=1}^{k} P(w_i|c)
cMAP∝argmaxc∈CP(c)P(d∣c)=argmaxc∈CP(c)i=1∏kP(wi∣c)
-
P
^
(
c
j
)
=
c
o
u
n
t
(
c
j
)
n
\hat{P}(c_j)=\frac{count(c_j)}{n}
P^(cj)=ncount(cj)
- 其中 n n n为训练集总数
- c o u n t ( c j ) count(c_j) count(cj)指训练集中类别为 c j c_j cj的文本数量
-
P
^
(
w
i
∣
c
j
)
=
c
o
u
n
t
(
w
i
,
c
j
)
∑
w
∈
V
c
o
u
n
t
(
w
,
c
j
)
\hat{P}(w_i|c_j)=\frac{count(w_i,c_j)}{\sum_{w\in V}count(w,c_j)}
P^(wi∣cj)=∑w∈Vcount(w,cj)count(wi,cj)
- 即 c j c_j cj类中,词语 w i w_i wi在该类所有词语中的占比
平滑
常用拉普拉斯平滑,取 α = 1 \alpha=1 α=1,也称加一平滑
为防止训练集某个类中某个词出现频率为0,通过词袋模型统计出词表后,我们在词表中每个词语的出现次数加 α \alpha α(关于平滑完整介绍见NLP笔记:n-grams语言模型-CSDN博客)
此时MLE估计结果化为:
P
^
(
w
i
∣
c
j
)
=
c
o
u
n
t
(
w
i
,
c
j
)
+
α
∑
w
∈
V
c
o
u
n
t
(
w
,
c
j
)
+
∣
V
∣
α
\hat{P}(w_i|c_j)=\frac{count(w_i,c_j)+\alpha}{\sum_{w\in V}count(w,c_j)+|V|\alpha}
P^(wi∣cj)=∑w∈Vcount(w,cj)+∣V∣αcount(wi,cj)+α
实例
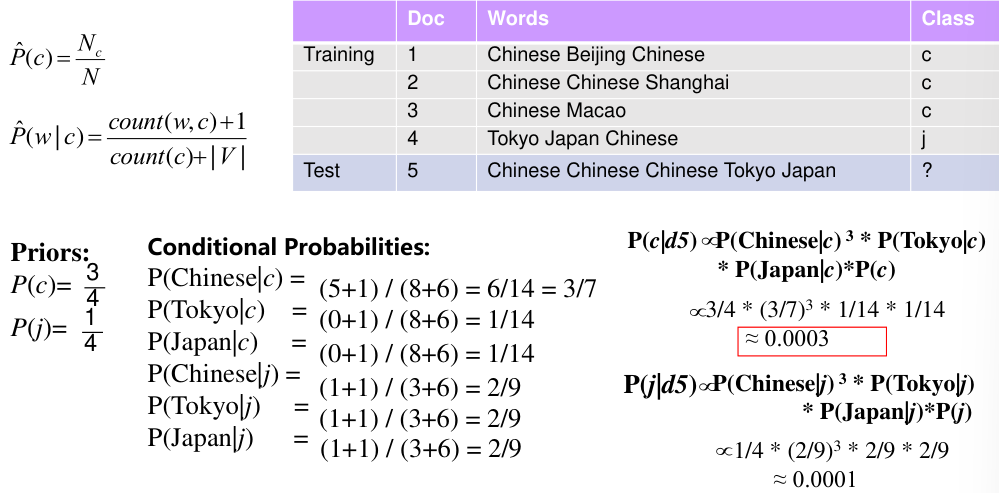
评估
混淆矩阵 Confusion Matrix
- TP(True Positive):将正类预测为正类数,真实为0,预测也为0
- FN(False Negative):将正类预测为负类数,真实为0,预测为1
- FP(False Positive):将负类预测为正类数, 真实为1,预测为0
- TN(True Negative):将负类预测为负类数,真实为1,预测也为1
| correct | not correct | |
|---|---|---|
| selected | TP | FP |
| not selected | FN | TN |
- 准确率: a c c u r a c y = T P + T N T P + T N + F P + F N accuracy=\frac{TP+TN}{TP+TN+FP+FN} accuracy=TP+TN+FP+FNTP+TN
- 精确率: p r e c i s i o n = T P / ( T P + F P ) precision=TP/(TP+FP) precision=TP/(TP+FP)
- 召回率: r e c a l l = T P / ( T P + F N ) recall=TP/(TP+FN) recall=TP/(TP+FN)
F-Measure
F度量是一个评估Precision/Recall权衡的组合度量(加权调和平均数)
F
=
1
α
1
P
+
(
1
−
α
)
1
R
=
1
α
P
R
(
1
α
−
1
)
P
+
R
=
β
2
=
1
α
−
1
(
β
2
+
1
)
P
R
β
2
P
+
R
\begin{split} F &=\frac{1}{\alpha\frac{1}{P}+(1-\alpha)\frac{1}{R}}\\ &=\frac{\frac{1}{\alpha}PR}{(\frac{1}{\alpha}-1)P+R}\\ &\overset{\beta^2=\frac{1}{\alpha}-1}{=}\frac{(\beta^2+1)PR}{\beta^2P+R} \end{split}
F=αP1+(1−α)R11=(α1−1)P+Rα1PR=β2=α1−1β2P+R(β2+1)PR
-
α
\alpha
α表示对精确率和召回率的相对重视程度
- α → 0 \alpha \rightarrow 0 α→0时,更重视召回率Recall
- α → 1 \alpha \rightarrow 1 α→1时,更重视精确率Precision
-
β
\beta
β是用来调整精确率和召回率权衡的参数
- 通常取
β
=
1
\beta=1
β=1,表示对精确率和召回率平等看待
- 此时的F值记为 F 1 F_1 F1,即 F 1 = 2 P R P + R F_1=\frac{2PR}{P+R} F1=P+R2PR
- β > 1 \beta>1 β>1时,更重视精确率
- β < 1 \beta<1 β<1时,更重视召回率
- 通常取
β
=
1
\beta=1
β=1,表示对精确率和召回率平等看待
综合评估
- 混淆矩阵和F度量值都是对单个类别的评估
- 微平均/宏平均则用于汇总多个类别的性能指标,如准确率、召回率和F1分数,以便评估整个分类器的性能
一个比较好的解释:
The difference between macro and micro averaging is that macro averaging gives equal weight to each category while micro averaging gives equal weight to each sample. If we have the same number of samples for each class, both macro and micro will provide the same score.
有关宏平均/微平均的更详细解释可以参考:model evaluations - Micro Average vs Macro average Performance in a Multiclass classification setting - Data Science Stack Exchange
宏平均
- 对每个类 c i ∈ C c_i\in C ci∈C分别统计 P r e c i s i o n Precision Precision、 R e c a l l Recall Recall和 F 1 F_1 F1值,记为 P i , R i , F i P_i,R_i,F_i Pi,Ri,Fi
- 计算算术平均值
- M a c r o _ P r e c i s i o n = ( ∑ i = 1 n P i ) / n Macro\_Precision=(\sum_{i=1}^{n}P_i)/n Macro_Precision=(∑i=1nPi)/n
- M a c r o _ R e c a l l = ( ∑ i = 1 n R i ) / n Macro\_Recall=(\sum_{i=1}^{n}R_i)/n Macro_Recall=(∑i=1nRi)/n
- M a c r o _ F 1 = ( ∑ i = 1 n F i ) / n Macro\_F_1=(\sum_{i=1}^{n}F_i)/n Macro_F1=(∑i=1nFi)/n
微平均
-
将每个类 c i ∈ C c_i\in C ci∈C的混淆矩阵相加,即
Confusion Matrix of All Classes ( = [ T P A l l F P A l l F N A l l T N A l l ] ) = ∑ i = 1 n [ T P i F P i F N i T N i ] \text{Confusion Matrix of All Classes} \left( =\begin{bmatrix} TP_{All}&FP_{All}\\ FN_{All}&TN_{All} \end{bmatrix} \right) =\sum_{i=1}^{n} \begin{bmatrix} TP_i&FP_i\\ FN_i&TN_i \end{bmatrix} Confusion Matrix of All Classes(=[TPAllFNAllFPAllTNAll])=i=1∑n[TPiFNiFPiTNi] -
计算总体混淆矩阵的 P r e c i s i o n Precision Precision、 R e c a l l Recall Recall和 F 1 F_1 F1值
- M i c r o _ P r e c i s i o n = T P A l l / ( T P A l l + F P A l l ) Micro\_Precision=TP_{All}/(TP_{All}+FP_{All}) Micro_Precision=TPAll/(TPAll+FPAll)
- M i c r o _ R e c a l l = T P A l l / ( T P A l l + F N A l l ) Micro\_Recall=TP_{All}/(TP_{All}+FN_{All}) Micro_Recall=TPAll/(TPAll+FNAll)
- M i c r o _ F 1 = 2 × M i c r o _ P r e c i s i o n × M i c r o _ R e c a l l M i c r o _ P r e c i s i o n + M i c r o _ R e c a l l Micro\_F_1=\frac{2\times Micro\_Precision\times Micro\_Recall}{Micro\_Precision+Micro\_Recall} Micro_F1=Micro_Precision+Micro_Recall2×Micro_Precision×Micro_Recall















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









