








NOTE
第三章 管线一览
本章我们会学到什么
- OpenGL管线的每个阶段做什么的
- 如果连接着色器和固定功能管线阶段
- 如果创建一个程式同时使用图形管线的每个阶段
在本章我们将从始至终过一遍OpenGL管线,对每个阶段进行考察,包括固定功能块和可编程着色器块。我们已经对顶点着色器和片段着色器有了初步的大致了解。然而,我们创建的应用只能简单地在固定位置绘制一个三角形。如果我们想要使用OpenGL渲染任何有趣的东西,我们必须继续学习管线以及我们用它所能做的所有事。本章介绍管线的每个部分,将它们彼此联接并为每个阶段提供一个着色器示例。
传递数据给顶点着色器
顶点着色器是OpenGL管线中第一个可编程(programmable)的阶段并且是图形管线中唯一必须的阶段。不过,在顶点着色器运行之前,一个称为顶点获取(vertex fetching)或顶点拉取(vertex pulling)的固定功能阶段会运行。它自动为顶点着色器提供输入数据。
顶点属性
在GLSL中供着色器获取输入或输出数据的机制是使用in和out存储标识符声明全局变量。在第二章“我们的第一个OpenGL程式”中我们简要介绍了out标识符,在清单2.4中用它从片段着色器输出一个颜色。在OpenGL管线的开端,我们使用in关键字为顶点着色器输入数据。在阶段之间,使用in和out组成导管在着色器之间传递数据。我们马上就会知道这个。现在,考虑顶点着色器的输入以及如果我们使用in存储标识符声明一个变量发生了什么。这个标识符标明这个变量是顶点着色器的输入,意味着这个变量是OpenGL图形管线的重要输入。这个变量在固定功能的顶点获取阶段被自动填充。这个变量即为顶点属性(vertex attribute)。
顶点属性是顶点数据引入OpenGL管线的手段。要声明一个顶点属性,我们在顶点着色器中使用in存储标识符声明一个全局变量即可。如清单3.1所示,我们将offset变量声明为一个输入的顶点属性。
清单3.1 声明一个顶点属性:
#version 450 core
// 'offset' is an input vertex attribute
layout (location = 0) in vec4 offset;
void main(void)
{
const vec4 vertices[3] = vec4[3](vec4(0.25, -0.25, 0.5, 1.0),
vec4(-0.25, -0.25, 0.5, 1.0),
vec4(0.25, 0.25, 0.5, 1.0));
// Add 'offset' to our hard-coded vertex position
gl_Position = vertices[gl_VertexID] + offset;
}
在清单3.1中,我添加offset变量作为顶点着色器的输入。因为它是管线第一个着色器的输入,故它会在顶点获取阶段被自动填充。我们可以用众多顶点属性相关的函数(glVertexAttrib*())来指示OpenGL在顶点获取阶段为相关变量填充何值。我们将会用到的glVertexAttrib4fv()的原型如下:
void glVertexAttrib4fv(GLuint index, const GLfloat* v);
参数index用来索引指定的属性,v是要放入属性的新数据的指针。你或许已注意到声明offset属性中的代码layout (location = 0)。这是一个布局指示符(layout qualifier),我们用它来设置指定的顶点属性的位置(location)为0。这个位置的值就是我们通过index来传递进行这个属性引用的值。
每次我们调用任何一个glVertexAttrib*()函数都会更新传递给顶点着色器的顶点属性的值。我们可以使用这个方法来给我们的三角形加上动画。清单3.2展示了一个更新版本的渲染函数,它在每一帧都会更新offset的值。
清单3.2 更新一个顶点属性:
// Our rendering function
virtual void render(double currentTime)
{
const GLfloat color[] = { (float)sin(currentTime) * 0.5f + 0.5f,
(float)cos(currentTime) * 0.5f + 0.5f,
0.0f, 1.0f };
glClearBufferfv(GL_COLOR, 0, color);
// Use the program object we created earlier for rendering
glUseProgram(rendering_program);
GLfloat attrib[] = { (float)sin(currentTime) * 0.5,
(float)cos(currentTime) * 0.6f,
0.0f, 0.0f };
// Update the value of input attribute 0
glVertexAttrib4fv(0, attrib);
// Draw one triangle
glDrawArrays(GL_TRIANGLES, 0, 3);
}
运行清单3.2中的代码,我们会看到三角形在窗体中以一个圆滑的椭圆形路径运动。(译者注: 译者的仓库sb7examples中相应工程为chapter3/update_vertex_attribute)
在着色器阶段间传递数据
目前为止我们已经看到了如何通过使用in关键字创建一个顶点属性来传递数据给顶点着色器,如何通过读写诸如gl_VertexID、gl_Position等内置变量和固定功能块交流,如何使用out关键字从片段着色器输出数据。不过,我们同样可以使用in和out关键字在着色器阶段之间传递我们的数据。一如我们在片段着色器中使用out关键字来创建输出颜色值的变量一样,我们也能在顶点着色器中使用out关键字创建一个输出变量。在一个着色器中写入到一个输出变量的任何内容都会传递给下一个着色器阶段中以in声明的同名变量。比如,如果我们在顶点着色器中使用out关键字声明一个叫vs_color的变量,接下来在片段着色器阶段这个变量就会匹配到一个用in关键字声明的名为vs_color的变量上(假设它们间没有其他的阶段)。
如果将我们简单的顶点着色器修改为清单3.3,包含一个vs_color的输出变量,并相应将我们简单的片段着色器修改为清单3.4,包含一个vs_color的输入变量,我们便能将一个值从顶点着色器传给片段着色器。然后,相比之前输出一个固定的颜色值,现在这个片段着色器可以将顶点着色器传给它的颜色值输出。
清单3.3 带一个输出变量的顶点着色器:
#version 450 core
// 'offset' and 'colour' are input vertex attributes
layout (location = 0) in vec4 offset;
layout (location = 1) in vec4 color;
// 'vs_color' is an output that will be sent to the next shader stage
out vec4 vs_color;
void main(void)
{
const vec4 vertices[3] = vec4[3](vec4(0.25, -0.25, 0.5, 1.0),
vec4(-0.25, -0.25, 0.5, 1.0),
vec4(0.25, 0.25, 0.5, 1.0));
// Add 'offset' to our hard-coded vertex position
gl_Position = vertices[gl_VertexID] + offset;
// Output a fixed value for vs_color
vs_color = color;
}
从清单3.3可以看到,我们为这个顶点着色器声明了第二个输入变量: color(这次location为1),并将它的值写入到输出变量vs_color。然后这个值为清单3.4的片段着色器所用,写入到帧缓冲区。这使得我们可以把一个通过glVertexAttrib*设置的顶点属性的颜色值一路从顶点着色器传入片段着色器,然后写到帧缓冲区。结果就是我们可以绘制他色的三角形了。
清单3.4 带有一个输入变量的片段着色器:
#version 450 core
// Input from the vertex shader
in vec4 vs_color;
// Output to the framebuffer
out vec4 color;
void main(void)
{
// Simply assign the colour we were given by the vertex shader to our output
color = vs_color;
}
译者注: 译者的sb7examples中相应工程为chapter3/different_colored_triangle。
数据块接口(Interface Blocks)
一次声明一个接口变量用来在着色器阶段间传递数据可能是最简单的方法。然而,在大多数工业用的应用的,我们会想在着色器阶段间传递成堆的数据,这些可能包括数组、结构体以及其他复杂排列的变量。为达此目的,我们可以将好些个变量组成一个数据块接口(interface block)。数据块接口的声明和C中结构体的声明很像,除了数据块接口依据它是从着色器输入数据还是输出数据而使用in或者out关键字声明。示一例如清单3.5。
清单3.5 带一个输出数据块接口的顶点着色器:
#version 450 core
// 'offset' is an input vertex attribute
layout (location = 0) in vec4 offset;
layout (location = 1) in vec4 color;
// Declare VS_OUT as an output interface block
out VS_OUT
{
vec4 colour; // Send color to the next stage
} vs_out;
void main(void)
{
const vec4 vertices[3] = vec4[3](vec4(0.25, -0.25, 0.5, 1.0),
vec4(-0.25, -0.25, 0.5, 1.0),
vec4(0.25, 0.25, 0.5, 1.0));
// Add 'offset' to our hard-coded vertex position
gl_Position = vertices[gl_VertexID] + offset;
// Output a fixed value for vs_color
vs_out.color = color;
}
值得注意的是清单3.5中的数据块接口同时有一个块名称(大写的VS_OUT)和一个实例名称(小写的vs_out)。数据块接口在着色器阶段间通过块名称匹配(本例中为VS_OUT)但在着色器中则是用实例名称引用(本例中为vs_out)。将我们的片段着色器修改为清单3.6来使用这个数据块接口。
清单3.6 带一个输入数据块接口的片段着色器:
#version 450 core
// Declare VS_OUT as an input interface block
in VS_OUT
{
vec4 colour; // Send color to the stage
} fs_in;
// Output to the framebuffer
out vec4 color;
void main(void)
{
// Simply assign the color we were given by the vertex shader to our output
color = fs_in.color;
}
译者注: 译者的sb7examples中相应工程为chapter3/interface_block_triangle。
通过块名称匹配但允许块实例在每个着色器阶段有不同的名称,这种设定出于两方面的考量。第一,允许不同着色器阶段使用不同的名称进行引用,可以避免一些混乱,比如要在片段着色器中使用vs_out。第二,当我们纵横于一些着色器阶段时,比如顶点着色器、细分着色器或者几何着色器阶段(我们马上就会看到了),这样使得接口从单个条目变成数组。值得注意的是数据块接口只能用于着色器阶段到着色器阶段的数据传递–我们不能用它将顶点着色器的输入或者片段着色器的输出组建成群。
细分曲面(Tessellation)
细分曲面是将高阶图元(在OpenGL中常称为碎片(patch))降解为很多更小的、更简单的图元,诸如三角形之后进行渲染。OpenGL包含一个固定功能的、可配置的细分曲面引擎,它可以将四边形、三角形以及线段降解为可能很多的可被常规光栅硬件使用的更小的点、线段或者三角形。从逻辑上来说,细分曲面阶段由三部分组成:细分曲面控制着色器,固定功能细分曲面引擎以及细分曲面运算着色器,在OpenGL管线中细分曲面阶段直接跟在顶点着色阶段之后。
细分曲面控制着色器(Tessellation Control Shaders)
细分曲面三个阶段的第一阶段为细分曲面控制着色器(TCS;有时简称为控制着色器)。这个着色器从顶点着色器接收输入并主要负责两件事:1.确定要发送给细分曲面引擎的细分曲面等级。2.生成细分曲面运行之后要发送给细分曲面运算着色器的数据。
在OpenGL中,细分曲面通过将被称为碎片(patches)的高阶表面降解为点、线段或者三角形而进行正常工作。每一个碎片都由一定数目的控制点(control points)组成。每个碎片的控制点数目都是可配置的,通过调用glPatchParameteri()即可设置,同时将pname设置为GL_PATCH_VERTICES以及value设置为构成每个碎片的控制点的数目。glPatchParameteri()的原型如:
void glPatchParameteri(GLenum pname, GLint value);
缺省情况下,每个碎片的控制点数目是3。所以,如果这就是我们想要的(一如我们接下来的示例),我们完全可以不调用这个函数。用来构成一个碎片的最高控制点数目是由实现定义的,但保证至少为32。
当细分曲面开始时,顶点着色器会针对每一个控制点运行一次,不过细分曲面控制着色器根据控制点的群组按批次运行,每个批次的大小和每个碎片的顶点数一样。意即,顶点被当做控制点而且顶点着色器的输出结果被成批送往细分曲面控制着色器当做输入。每个碎片的控制点数目是可以改变的所以细分曲面控制着色器输出的控制点数目可以和它消耗的控制点数目不同。控制着色器产生的控制点数目在控制着色器的源代码中使用一个输出布局标识符进行设置。这样的布局标识符看起来像这样:
layout (vertices = N) out;
这里的N即每个碎片的控制点数目。控制着色器有责任计算输出控制点的数目以及设置作为最终结果发送给固定功能细分曲面引擎的碎片的细分曲面因子。输出的细分曲面因子写入内置变量gl_TessLevelInner和gl_TessLevelOuter中,而其他任何在管线中传递的数据都正常地写入用户定义的输出变量(使用out关键字声明的或者特殊的内置gl_out数组)。
清单3.7展示了一个简单的细分曲面控制着色器。它用布局标识符layout (vertices = 3) out;设置输出的控制点数目为3(与缺省的输入控制点数目相同),将它的输入拷贝到输出(使用内置变量gl_in和gl_out),并设置内和外的细分曲面级别为5。更高的细分曲面级别会产生更密集的细分曲面输出,更低的级别会产生更粗糙的细分曲面输出。将细分曲面因子设置为0会导致整个碎片被丢弃。
内置变量gl_InvocationID被用作gl_in和gl_out数组的索引,从0开始算起。这个变量表示当前被调用的细分曲面控制着色器中被处理的碎片的控制点索引值。
清单3.7 我们的第一个细分曲面控制着色器:
#version 450 core
layout (vertices = 3) out;
void main(void)
{
// Only if I am invocation 0 ...
if (gl_InvocationID == 0)
{
gl_TessLevelInner[0] = 5.0;
gl_TessLevelOuter[0] = 5.0;
gl_TessLevelOuter[1] = 5.0;
gl_TessLevelOuter[2] = 5.0;
}
// Everybody copies their input to their output
gl_out[gl_InvocationID].gl_Position =
gl_in[gl_InvocationID].gl_Position;
}
细分曲面引擎(The Tessellation Engine)
细分曲面引擎是OpenGL管线中的一个固定功能部分,它接收表示为碎片的高阶表面并将它们降解为更简单的图元,比如:点、线段或者三角形。在细分曲面引擎接收碎片之前,细分曲面控制着色器处理输入的控制点并设置细分曲面因子,然后用它们来降解这个碎片。细分曲面引擎生成输出图元之后,用以表示这些图元的顶点被细分曲面运算着色器所利用。细分曲面引擎有责任生成用以调用细分曲面运算着色器的参数,然后细分曲面运算着色器用这些参数转换作为最终结果的图元并将它们准备好光栅化。
细分曲面运算着色器(Tessellation Evaluation Shaders)
一旦固定功能细分曲面引擎运行后,它会产生一些输出顶点用来表示生成的图元。这些顶点会传递给细分曲面运算着色器。细分曲面运算着色器(TES;或者简称为运算着色器)会对细分曲面器生成的每个顶点运行一次。当细分曲面级别高时,细分曲面运算着色器将会运行很多次。为此,对于复杂的运算着色器和高细分曲面级别我们需要小心应付。
清单3.8展示了一个细分曲面运算着色器,它接受由清单3.7所示的控制着色器运行输出的顶点作为输入。在这个着色器开头是一个布局标识符,它设置了细分曲面模式。在本例中,我们选择模式为三角形。其他标识符equal_spacing和cw表明新的顶点生成时要是沿着细分的多边形边缘等距的并且生成的三角形的顶点环绕次序是顺时针的。我们会在第八章的“细分曲面”中对其他可能的选项进行更全面的介绍。
这个着色器的剩余部分如顶点着色器一样对gl_Position进行了赋值。它使用多个内置变量来计算gl_Position的值。第一个是gl_TessCoord,它是细分曲面器生成的顶点的质心坐标。第二个是gl_in[]结构体数组的成员gl_Position。gl_in匹配清单3.7中的细分曲面控制着色器写入的gl_out结构体。这个着色器主要实做了直通细分(pass-through tessellation)。意即,细分后输出的碎片与原始输入的三角形碎片形状一致。
清单3.8 我们的第一个细分曲面运算着色器:
#version 450 core
layout (triangles, equal_spacing, cw) in;
void main(void)
{
gl_Position = (gl_TessCoord.x * gl_in[0].gl_Position +
gl_TessCoord.y * gl_in[1].gl_Position +
gl_TessCoord.z * gl_in[2].gl_Position);
}
为了能看到细分曲面器的结果,我们需要指示OpenGL只绘制最终结果的三角形的轮廓。为达此目的,我们调用glPolygonMode(),它的原型为:
void glPolygonMode(GLenum face, GLenum mode);
face参数指明我们想影响哪个类型的多边形。因为我们想要影响所有东西,故我们设置它为GL_FRONT_AND_BACK.mode表明我们想要如何渲染多边形。我们想要渲染为线框模式(即直线),我们将这个参数设置为GL_LINE。其他模式我们很快就会解释的。我们的三角形示例在使用细分曲面以及清单3.7、清单3.8的着色器之后,渲染结果如图示3.1:
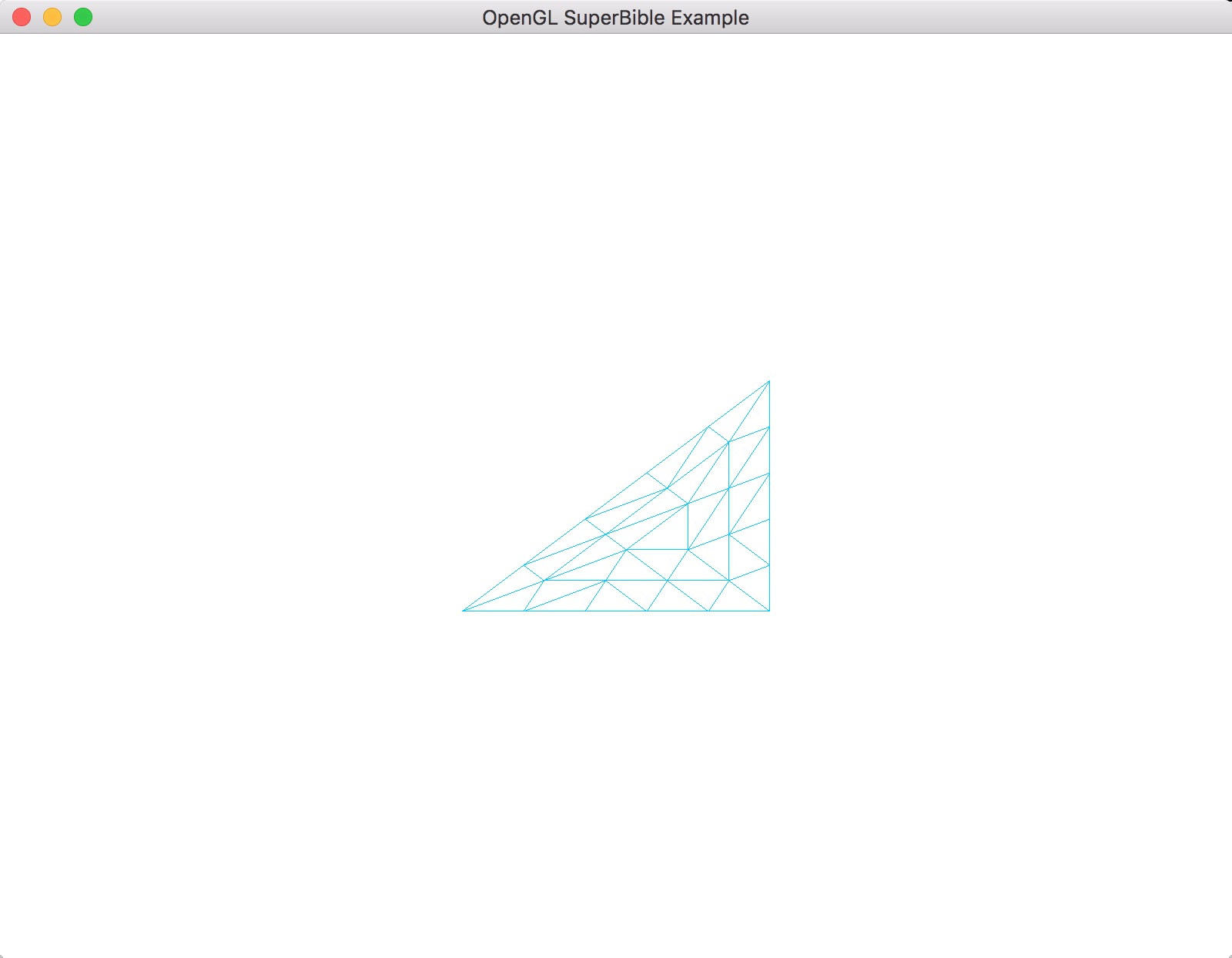
译者注: 译者的sb7examples中相应项目为chapter3/triangle_with_tessellation
几何着色器(Geometry Shaders)
从逻辑上来讲,几何着色器是是前端着色器的最后阶段了,它在顶点和细分曲线阶段之后、光栅器之前。几何着色器针对每个图元运行一次并且对正在处理的图元的所有组成顶点有访问权限。几何着色器也是着色器阶段中唯一可以编程控制数据流总量增减的着色器。虽然说细分曲面着色器也可以增减管线的工作量,但它只能通过设置碎片的细分曲面级别来隐式地影响工作量。而相对的,几何着色器包含两个函数–EmitVertex()和EndPrimitive(),它们能显示地产生顶点发送到图元组装(primitive assembly)和光栅化(rasterization)。
几何着色器的另一个独一的功能是它可以在管线中途改变图元模式。比如,它们可以接收三角形作为输入并输出一些列的点或者线,再或者从一系列不相干的点创建三角形。清单3.9示一例。
清单3.9 我们的第一个几何着色器:
#version 450 core
layout (triangles) in;
layout (points, max_vertices = 3) out;
void main(void)
{
int i;
for (i = 0; i < gl_in.length(); i++)
{
gl_Position = gl_in[i].gl_Position;
EmitVertex();
}
}
清单3.9的几何着色器再次扮演了一个简单地直通着色器,它将输入的三角形转换为点,这样我们便能看见它们的顶点。第一个布局标识符表明这个几何着色器期望输入数据为三角形。第二个布局标识符指示OpenGL这个几何着色器会产生点并且每个着色器最多产生三个点。在main函数中,迭代了gl_in数组的所有成员,gl_in数组的长度通过它的.length()函数获知。
实际上我们知道gl_in数组的长度就是三,因为我们正在处理的是三角形,每个三角形有三个顶点。这个几何着色器的输出再一次与顶点着色器神似(前面有细分曲面运算着色器)。特别是我们写入值到gl_Position来设置输出顶点的位置。然后,我们调用EmitVertex(),它在几何着色器的输出中产生一个顶点。几何着色器在着色器结束的时候自动调用EndPrimitive(),故本例中我们无须显示调用它。运行这个着色器之后,将会产生三个顶点,然后渲染为三个点。
将这个几何着色器插入到我们之前的细分曲面三角形示例中,我们会得到如图示3.2的输出。为了得到这个图像,我们通过调用glPointSize()将点的大小设置为5.0,这样会使得点大一些容易辨识。
图示3.2 带几何着色器的细分曲面三角形:
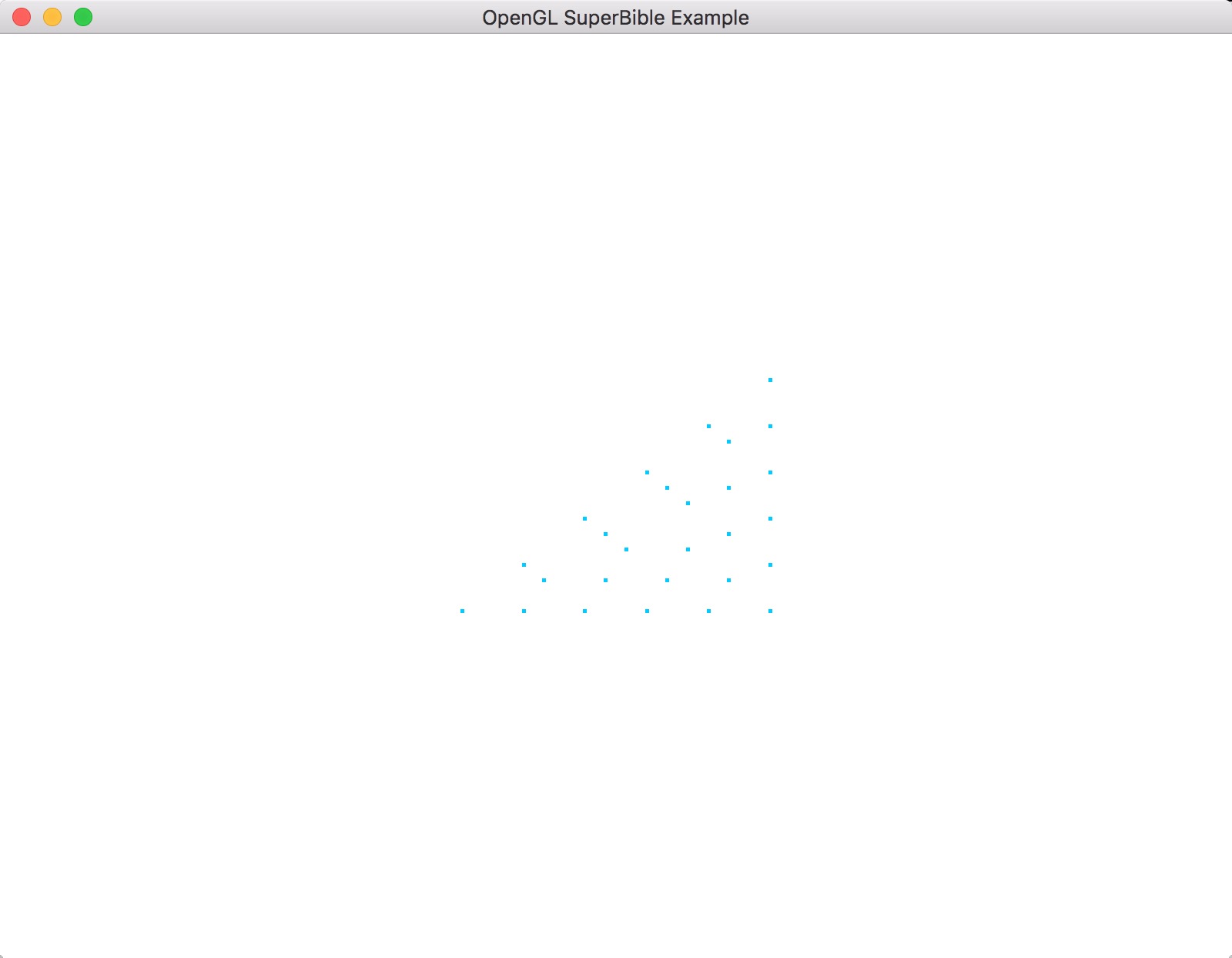
译者注: 译者的sb7examples中相应的项目为chapter3/triangle_with_tess_geometry
图元组装、修剪和光栅化(Primitive Assembly,Clipping, and Rasterization)
管线的前端(这包括顶点着色、细分曲面以及几何着色)运行完成之后,管线中一个固定功能部分会开始执行一系列任务,它接收顶点表示的场景并将其转换为一系列像素,这些像素轮流被上色并写入到显示屏幕上。这个过程的第一步是图元组装,它将顶点群组为线或者三角形。图元组装仍然发生在“点”上,不过这种情况它无关紧要了。
一旦各个分散独立的顶点被组成为图元,图元就会针对可显示区域进行修剪(clipped),这个可显示区域通常是窗体或者显示屏幕,但也可以是一个更小的称为视口(viewport)的区域。最终,图元中被判断为可能可见的部分被发送到一个称为光栅器(rasterizer)的固定功能子系统。这个子系统会判断出哪些像素被图元(点、线或者三角形)覆盖到并将这些像素发送到下一阶段–换言之,就是片段着色阶段。
修剪
随着顶点离开管线的前端,它们的位置便处于修剪空间(clip space)。修剪空间是众多用来表示位置的坐标系统之一。你可能已注意到,我们在顶点、细分曲面以及几何着色器中写入的gl_Position变量是一个vec4类型的,我们写入到它的产生的位置值也是四个分量的向量。这个被称为齐次坐标(homogeneous coordinate)。齐次坐标系统被用在投影几何(projective geometry)中,因为很多数学问题最终在齐次坐标中都比常规笛卡尔坐标空间(Cartesian space)要简单。齐次坐标值比对应的笛卡尔坐标值要多一个分量,这也是为什么我们的三维位置向量被表示为四分量的变量。
尽管管线前端的输出是四分量齐次坐标,但修剪却是依靠笛卡尔坐标的。因此,为了将齐次坐标转换为笛卡尔坐标,OpenGL执行了透视分割(perspective division),将位置的四个分量都用w分量进行分割。这样可以将顶点从齐次坐标空间投影到笛卡尔坐标空间,保持w为1.0.到目前为止的所有示例,我们都将gl_Position的w分量设置为1.0,所以这种情况下分割不会有任何效果。我们之后研究投影几何时会对将w设置为其他值的效果做讨论的。
位置在投影分割之后的结果就会处于标准设备空间(normalized device space)。在OpenGL中,标准设备空间的可视区域是在x和y轴上-1.0到1.0以及z轴上0.0到1.0的体积。任何在这个区域内的几何图形都可能对用户是可见的而这个区域外的任何东西都将被丢弃。这个体积的六个面由三维空间的平面组成。因为一个平面将一个坐标空间一分为二,所以这六个平面的每一边的体积被称为半空间(half-spaces)。
在将图元传递到下一个阶段之前,OpenGL通过判断每个图元的顶点在六个平面的哪一边来进行修剪。每个平面实际上有一个外侧(outside)和里侧(inside)。如果一个图元的所有顶点都处在某一个平面的外侧,那这个图元就被丢弃。如果一个图元的所有顶点都处在所有平面的里侧(换言之处在可视体积内),然后这个图元就会原封不动传递下去。部分可视(意即这个图元与某个平面交叉)的图元需要特殊处理。这个主题更多的详情我们将在第七章“修剪”给出。
视口变换(Viewport Transformation)
在修剪后,几何图形的所有顶点都会处在标准设备坐标范围内,也就是在x和y轴上-1.0到1.0意即z轴上0.0到1.0的体积内。然而,我们绘制的目标是窗体,它的坐标通常是从左下的(0,0)到右上的(w-1,h-1),其中w和h分别为窗体的宽和高,单位是像素(窗体的坐标原点可以进行更改,比如改为右上)。为了将我们的几何图形放入窗体,OpenGL应用视口变换(viewport transform),它将缩放和偏移应用到顶点的标准设备坐标上,从而将它们放置到窗体坐标(window coordinates)中。要应用的缩放和偏移通过视口界限来决定,界限可以通过调用glViewport()和glDepthRange()来设置。它们的原型为:
void glViewport(GLint x, GLint y, GLsizei width, GLsizei height);
void glDepthRange(GLdouble nearVal, GLdouble farVal);
变换按照如下形式进行:
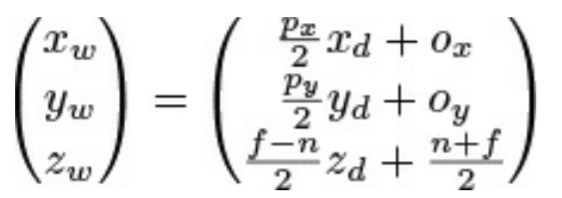
其中xw、yw和zw是顶点最终在窗体空间的坐标,xd、yd和zd是顶点在标准设备空间的坐标。px和py是视口的宽和高,以像素为单位,然后n和f分别是标准设备坐标中修剪空间z轴的近和远平面坐标值。最后,ox和oy是视口的原点。
剔除(Culling)
在一个三角形继续处理之前,它可能需要被传递到一个叫“剔除”的阶段,这个阶段会判断三角形的面朝向或者背向观察者,然后会根据计算结果决定是否真地进行下一步以及绘制它。如果三角形的面朝向观察者,那它就被认为是正面,否则,它就被认为是背面。丢弃背面的三角形是很普遍的,因为当一个对象是封闭的,任何背面的三角形都会被其他正面的三角形所隐藏。
为了判断一个三角形是正面还是背面,OpenGL会判断三角形在窗体空间的面积正负。一种判断三角形面积正负的方法是取两边的叉积。方程式为:
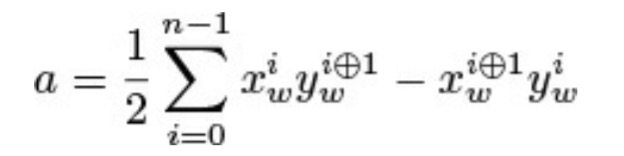
其中,xiw和yiw是三角形第i个顶点在窗体空间的坐标,i⊕1是(i+1)模3。如果这个面积是正的,那么这个三角形就被认为是正面;如果它是负的,那么它就被认为是背面。这个计算结果的含义可以通过调用glFrontFace()进行颠倒,它的原型为:
void glFrontFace(GLenum mode);
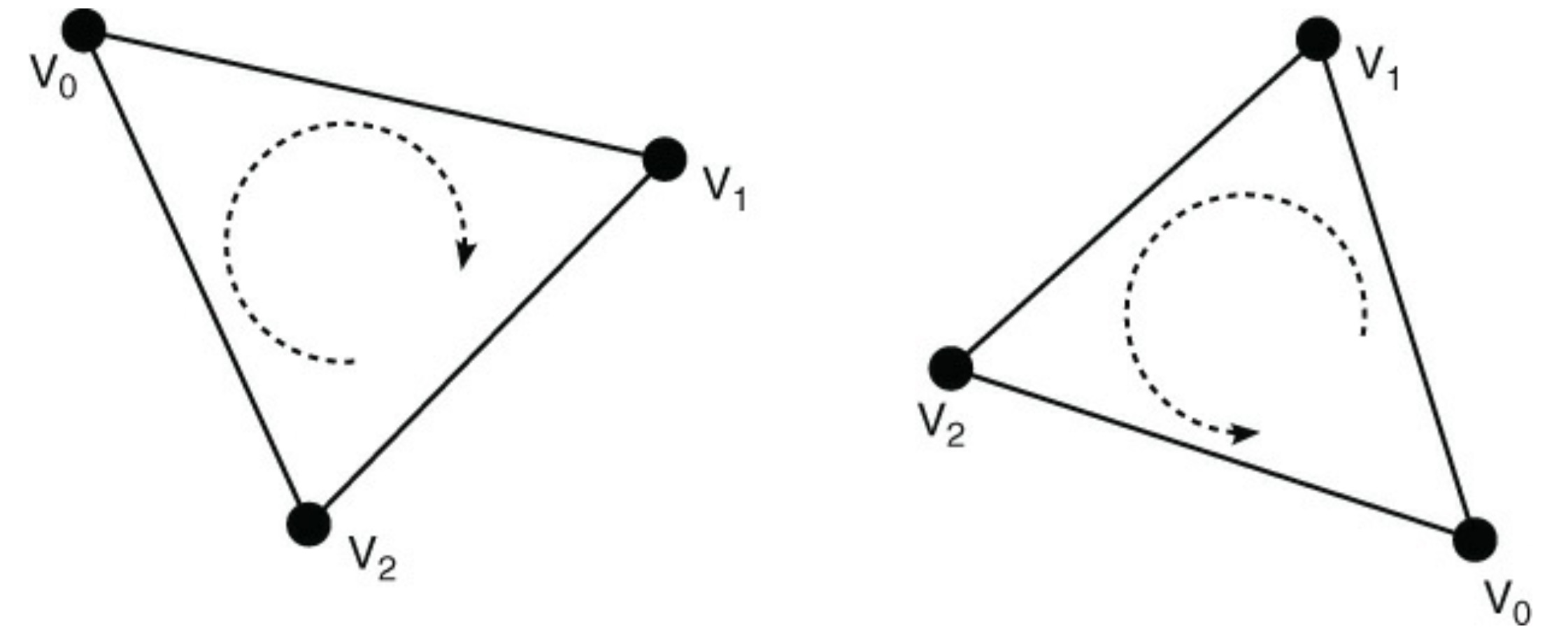
mode可被设置为GL_CW或者GL_CCW(其中GL_CW表示顺时针,GL_CCW表示逆时针)。这被称为三角形的环绕方向(winding order),顺时针和逆时针表示三角形顶点出现在窗体空间的次序。缺省情况下,环绕方向为逆时针,这意味着顶点次序为逆时针的三角形被认为是正面,顶点次序为顺时针的三角形被认为是背面。如果环绕方面被设置为GL_CW,那前面方程式中的a的含义在剔除过程中也就和前述相反。图示3.3以可观的方式展示方才所述。
图示3.3 顺时针(左)和逆时针(右)环绕方向
一旦三角形的方向被确定,OpenGL便可以丢弃正面、背面或者全部。缺省情况下,OpenGL会渲染所有的三角形,不管三角形的面的方向如何。要打开剔除,调用glEnable(),将cap参数设置为GL_CULL_FACE。当我们启用剔除,OpenGL缺省下就会剔除背面的三角形。要想变更三角形剔除的类型,调用glCullFace(),将face参数设置为GL_FRONT、GL_BACK或者GL_FRONT_AND_BACK。
因为点和线没有几何面积(很显然,一旦点和线渲染到显示屏幕上是有面积的,否则我们不会看到它们。然而这个面积是人为造成的,从它们的顶点上并不能直接计算出来),所以这个面向计算并不应用于它们,它们也无法在这个阶段被剔除。
光栅化
光栅化是判断哪些片段被一个图元(比如一条线或者一个三角形)所覆盖了的过程。有很多算法可以完成此事,不过对于三角形,大多数OpenGL系统会选定基于半空间的算法,因为它可以很好的并行实做。简明扼要地讲就是,OpenGL会在窗体坐标内为三角形设定一个界限框(bounding box),并对界限框内的每个片段测试它在三角形内还是外。要完成这个测试,将三角形的每个边当成窗体的半空间分割线即可。
在三角形三边内侧的片段被认为是在三角形内,在任何一边外侧的片段则被认为是在三角形外。因为判断一条线、一个点在哪一侧是相对简单的而且和除了线的端点或点本身的位置之外都不想干,很多测试可以并发执行,这样为大规模并行提供了机会。
片段着色器(Fragment Shaders)
片段着色器是OpenGL图形管线中的最后可编程阶段了。每个片段在发送到帧缓冲(framebuffer)混合到窗体之前,这个阶段有责任决定每个片段的颜色。在光栅器处理一个图元之后,它会产生一系列片段,这些片段需要传递给片段着色器进行调色。到了这一步,管线的工作量会有一个爆炸式的增长,因为每一个三角形都可能产生数百、数千甚至上百万个片段。
片段用来描述一种元素,它可能对像素的最终颜色造成至关重要的影响。不过像素的最终颜色可能并不会是某个指定的片段着色器执行的结果,因为像素的最终颜色还与很多其他因素有关,比如深度(depth)、模板测试(stencil tests)、混合(blending)以及多重采样(multi-sampling),当然这些在本书后面都会涉及到。
第二章的清单2.4展示了我们的第一个片段着色器的源代码。它是一个简单到不行的着色器,仅仅只是声明了一个输出变量,然后为它赋了一个固定的值。在真实世界的应用中,片段着色器通常会复杂很多并且需要进行与光照、材质甚至片段深度的诸多计算。片段着色器有多个可用的内置输入变量,比如gl_FragCoord,gl_FragCoord包含了片段在窗体中的位置。我们可以用它来为每个片段都产生独一无二的颜色。
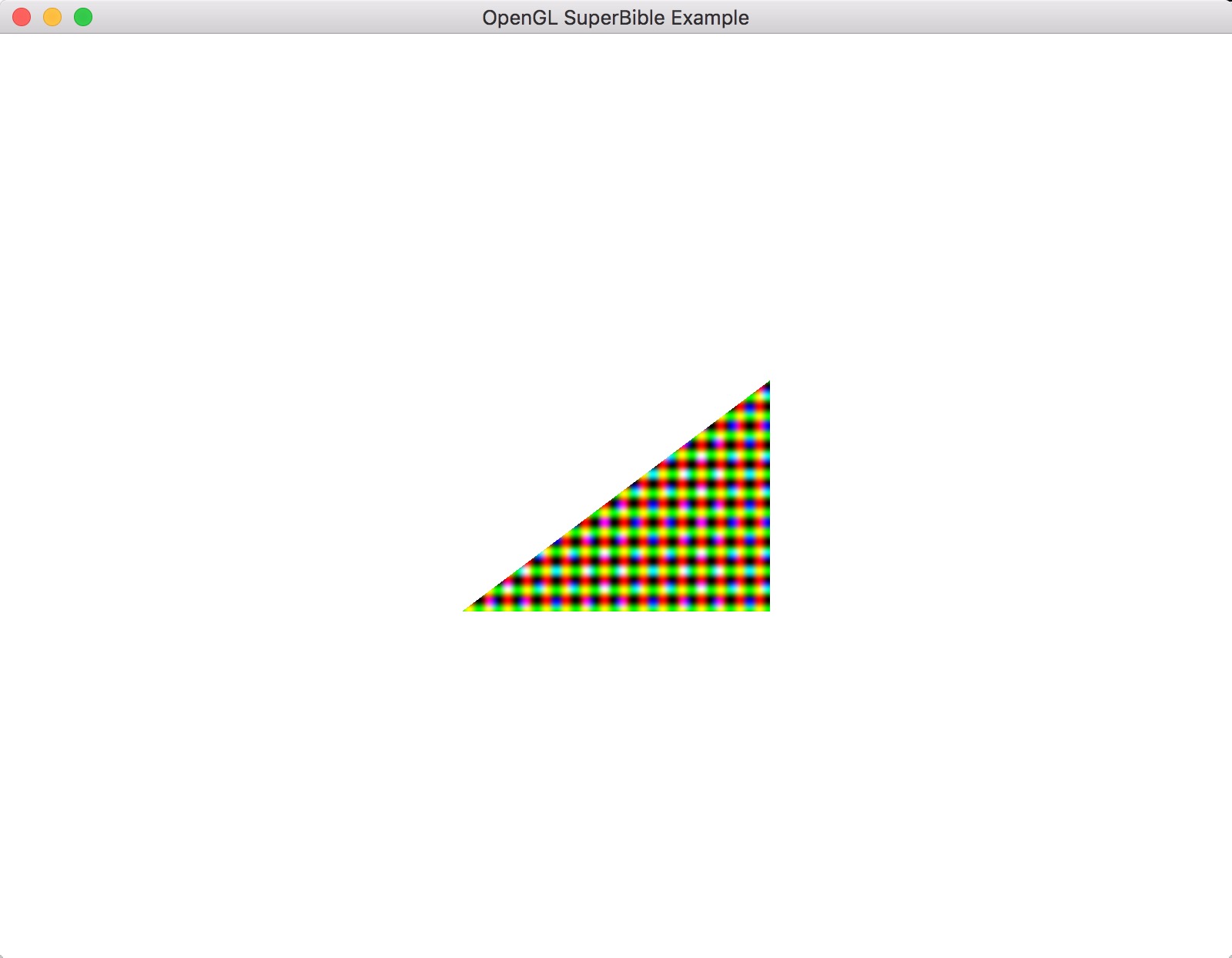
清单3.10提供了一个片段着色器,它从gl_FragCoord得出输出的颜色。图示3.4展示了我们原先的“我们的一个三角形”搭配清单3.10的着色器的输出。
清单3.10 从一个片段的位置得出颜色:
#version 450 core
out vec4 color;
void main(void)
{
color = vec4(sin(gl_FragCoord.x * 0.25) * 0.5 + 0.5,
cos(gl_FragCoord.y * 0.25) * 0.5 + 0.5,
sin(gl_FragCoord.x * 0.15) * cos(gl_FragCoord.y * 0.15),
1.0);
}
图示3.4:
译者注:译者的sb7examples中相应工程为chapter3/triangle_with_fragshader
我们可以看到,图示3.4中三角形的每个像素的颜色现在都是关于它的位置的函数,而且产生了与显示屏幕匹配(screen-aligned)的模式。清单3.10的着色器创建了一种格子样式(checkered patterns)。
gl_FragCoord是片段着色器可用的内置变量中的一个。不过,和其他着色器阶段一样,我们可以为片段着色器定义自定义的输入,这些输入会在光栅化前的任何一个阶段进行填充。比如,如果我们有一个简单的程式只有一个顶点着色器和片段着色器,我们可以从顶点着色器传递数据给片段着色器。
片段着色器的输入不像其他着色器阶段的,OpenGL会针对要渲染的图元对输入进行插值计算。为了演示这种情况,我们取来清单3.3的顶点着色器,将它做一些修改,为每个顶点赋予不同的固定颜色,最后如3.11所示。
清单3.11 顶点不同颜色的顶点着色器:
#version 450 core
// 'vs_color' is an output that will be sent to the next shader stage
out vec4 vs_color;
void main(void)
{
const vec4 vertices[3] = vec4[3](vec4(0.25, -0.25, 0.5, 1.0),
vec4(-0.25, -0.25, 0.5, 1.0),
vec4(0.25, 0.25, 0.5, 1.0));
const vec4 colors[] = vec4[3](vec4(1.0, 0.0, 0.0, 1.0),
vec4(0.0, 1.0, 0.0, 1.0),
vec4(0.0, 0.0, 1.0, 1.0));
// Add 'offset' to our hard-coded vertex position
gl_Position = vertices[gl_VertexID] + offset;
// Output a fixed value for vs_color
vs_color = color[gl_VertexID];
}
如清单3.11中所示,我们增加了第二个常量数组,它包含一组颜色并且使用gl_VertexID进行索引,它的值最终写入到输出变量vs_color中。在清单3.12中,我们将之前简单的片段着色器进行修改如下。
清单3.12 顶点不同颜色的片段着色器:
#version 450 core
// 'vs_color' is the color produced by the vertex shader
in vec4 vs_color;
out vec4 color;
void main(void)
{
color = vs_color;
}
最终的输出结果如图示3.5,可以看到,颜色在三角形上平滑地变化。
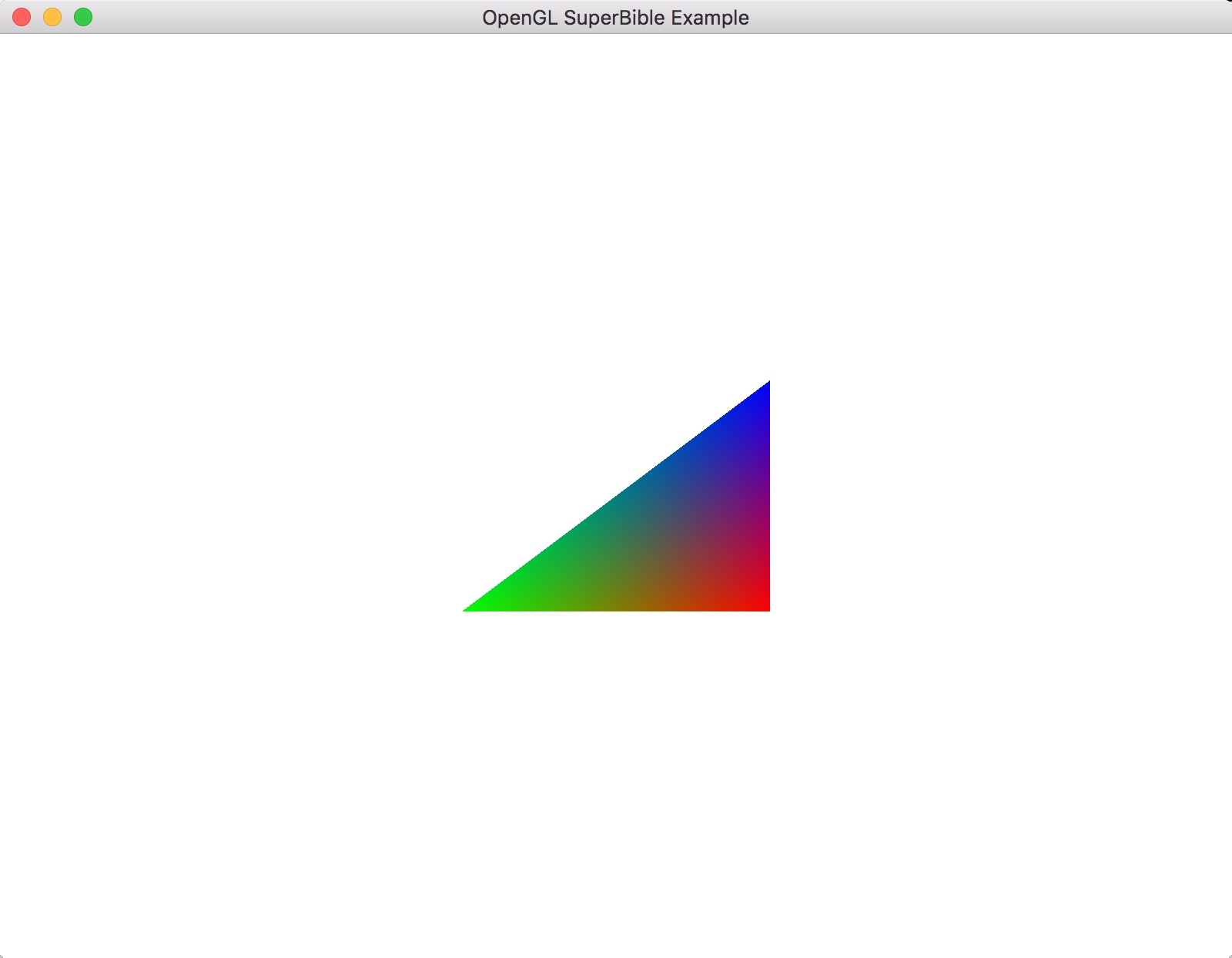
译者注:译者的sb7examples中相应工程为chapter3/triangle_color_smooth
帧缓冲运算
帧缓冲是OpenGL图形管线的最后一个阶段。它可以表示显示屏幕的可视内容以及用来存储每个像素除了颜色之外额外值的内存区域。在大多数平台上,这意味着我们在桌面上看到的窗体(或者说整个显示屏幕,如果我们的应用覆盖了整个显示屏幕)是属于操作系统(或者更精确来说是窗体系统)的。窗体系统提供的帧缓冲是缺省帧缓冲,但如果我们想渲染到显示屏幕外的区域的话,我们是可以提供自己的帧缓冲的。帧缓冲中存储的状态包含有诸多信息,比如片段着色器产生的数据写到哪,这些数据是什么格式,等等。这个状态存储在一个帧缓冲对象(framebuffer object)中。像素操作状态也可以被认为是帧缓冲的一部分,但不会每个像素都存储一个帧缓冲对象。
像素运算
片段着色器产生一个输出片段后,在这个片段写入窗体前还会做一些事情,比如判断它是否仍在所属的窗体中。这些事情我们都可以在应用中打开或者关闭。首先可能发生的事是裁剪测试(scissor test),它将片段与我们定义的一个矩形进行测试。如果片段在矩形内,就继续处理;如果片段在矩形外,就被丢弃。
然后会进行模板测试(stencil test)。这一步会将我们的应用提供的值与模板缓冲作比较,模板缓冲为每个像素都对应存储了一个值。模板缓冲的内容并没有特别的含义,可以随便存啥。当我们要使用一种叫做多重采样(multi-sampling)的技术时,一个帧缓冲中是可以存储多个深度缓冲、模板缓冲或者每个像素的颜色值的。本书后面我们会对此做更深入的探索。
模板测试完成之后,就会进行深度测试(depth test)。所谓的深度测试就是将片段的z坐标值与深度缓冲(depth buffer)的内容做比较。深度缓冲是和模板缓冲相似的一段内存区域,它做为帧缓冲的一部分为每个像素存储了一个值,这个值就是每个像素的深度(与到观察者的距离相关)。
通常深度缓冲中的值是从0到1,其中0是深度缓冲中最近的点,1是深度缓冲中最远的点。为了判断出同一位置上已被渲染的片段与新的片段哪个更近,OpenGL可以比较新片段与已在深度缓冲中的片段在窗体空间坐标的z分量。如果新片段的z分量小于深度缓冲中片段的z分量,则新片段应可见。当然这个测试结果的含义是可以变更的。比如,我们让z值大于、相等或者不等于深度缓冲内容的片段通过测试。深度测试的结果还会影响到OpenGL对模板缓冲的行为。
然后片段的颜色被发送到混合(blending)阶段或者逻辑运算(logical operation)阶段,这依赖于帧缓冲是否被认为存储浮点数值或者标准整型值。如果帧缓冲的内容是浮点值或者标准整型值,那就会应用混合。混合是OpenGL中高度可配置的一个阶段,我们将在单独的章节详细讨论。
简而言之,OpenGL可以用很多函数来综合片段着色器的输出与帧缓冲的内容计算出新的值并写回帧缓冲区。如果帧缓冲区包含非标准整型值,那逻辑运算与(AND)、或(OR)和异或(XOR)就可以应用到片段着色器的输出和当前帧缓冲区的内容上,产生一个新的值并会写回帧缓冲区。
计算着色器(Compute Shaders)
本章的第一节描述了OpenGL中的图形管线(graphics pipeline)。然而,OpenGL还包含计算着色器阶段,它可以被想象成独立于其他图形相关阶段的单独管线。
计算着色器是一种挖掘系统中图形处理器可计算能力的手段。不像以图形为中心的顶点、细分曲面、几何以及片段着色器,计算着色器可被当成是一个特殊的,单一阶段的管线。每一个计算着色器运算一个单一的被称为工作项目(work item)的工作。这些工作项目被轮流收集到一个群组当做一个局部工作组(local workgroups)。这些工作组的集合可以被发送到OpenGL的计算管线进行处理。计算着色器除了几个少数的内置变量用来指示着色器的工作项目之外,没有任何固定的输入或输出。所有被计算着色器处理的过程都由着色器显示地写入内存,而不是被下一个管线的阶段使用。一个很基础的计算着色器如清单3.13。
清单3.13 一个啥也不干的计算着色器:
#version 450 core
layout (local_size_x = 32, local_size_y = 32) in;
void main(void)
{
// Do nothing
}
在其他方面计算着色器和其他着色器一样。要编译一个计算着色器,我们用glCreateShader()传入GL_COMPUTE_SHADER来创建一个计算着色器对象,用glShaderSource()将GLSL源代码附加上去,用glCompileShader()编译它,然后用glAttachShader()和glLinkProgram()将它链接到一个程式中。最后得出一个有编译的计算着色器的程式对象,它可以启动为我们工作了。
清单3.13中的着色器指示OpenGL局部工作组会有32*32个工作项目,不过之后它们啥也没做。要创建一个做些有用事情的计算着色器,我们需要对OpenGL有更多的了解–所以我们之后还会再重温这个话题。
使用OpenGL扩展(Extensions)
目前为止本书所展示的示例都依赖于OpenGL核心功能。然而OpenGL的一个强大之处在于它可以被硬件制造商、操作系统零售商、甚至工具和调试器发行商进行扩展或者加强。OpenGL的扩展有很多不同的效果。
一个扩展是一个OpenGL核心版本的任何附加。所有扩展的列表在OpenGL站点的OpenGL扩展注册处(http://www.opengl.org/registry/)。这些扩展针对某个特定版本的OpenGL规范的差别被写在一个列表中,并标记出那个OpenGL版本是什么。那意味着扩展相关的文本描述了OpenGL核心规范必须如何改变以期支持特定的扩展。不过流行的以及广泛使用的扩展通常会被提升到OpenGL的核心版本中。所以,如果你正在运行OpenGL最新的、最牛逼的版本,那很多有趣的扩展都是核心档案的一部分了。每个OpenGL版本中提升进来的扩展以及它们的简要概述的完成列表在附录C–OpenGL特性和版本。
OpenGL扩展分为三大类:零售商,EXT以及ARB。零售商扩展被编写以及实做在零售商的硬件中。特定销售商的首字母缩写通常是零售商扩展名字的一部分–“AMD”用于Advanced Micro Devices,“NV”用于NVIDIA,等等。多个零售商支持同一个零售商扩展是可能的,特别当这个扩展被广泛接受之后。EXT扩展便是用于多个零售商支持的扩展。EXT扩展通常作为某一零售商扩展发展,但如果另一个零售商也对实做这个扩展很感兴趣,虽然可能会做一些小的修改,然后这些零售商就会合作产生一个EXT版本的扩展。ARB扩展是OpenGL官方的一部分,因为它们被OpenGL管理团队(Architecture Review Board-ARB)所批准。ARB扩展通常由大多数或者全部硬件零售商所支持,并且可能已经由零售商扩展或者EXT扩展开始发展。
这种扩展处理方式第一次听起来感觉乱乱的。现在已有数以百计的扩展可用!不过新版本的OpenGL通常从程序员发现的有用的扩展构造出来。通过这种方式,每个扩展都有被临幸的机会。优秀的扩展就可以被提升到核心中;而不太好的则不被考虑。这种“自然选择”的处理确保只有大多数有用而且重要的新特性加入到OpenGL核心版本中。
有一个很有用的工具可以用来判断我们的机器中OpenGL实现所支持的扩展,它就是Realtech VR的OpenGL Extensions Viewer。它可以从Realtech VR站点免费获得,如图示3.6。
图示3.6 Realtech VR的OpenGL Extensions Viewer:
使用扩展增强OpenGL
在使用任何扩展之前,我们必须确定我们的应用运行的OpenGL实现支持特定的扩展。要获取OpenGL支持哪些扩展,我们可以用两个函数。首先,为了判断支持的扩展的总数,我们可以调用glGetIntergerv()传入参数GL_NUM_EXTENSIONS。下一步,我们调用glGetStringi()来获取每个支持的扩展的名字。
const GLubyte* glGetStringi(GLenum name, GLuint index);
我们将name参数传递值GL_EXTENSIONS,index传递0到支持的扩展数减1的值。这个函数返回一个字符串表示扩展的名字。要查询一个特定的扩展是否支持,我们可以查询扩展的总数,然后迭代每个扩展,将它的名字与我们要查找的扩展的名字进行比较。本书的应用框架为我们提供了一个函数来做这件事:sb7IsExtensionSupported()。它的原型为:
int sb7IsExtensionSupported(const char* extname);
这个函数在
总结
在这一章,我们对OpenGL的图形管线做了一个快速的了解。我们对每个主要的阶段做了一个很粗浅的介绍,并且创建了一个用到每一个阶段的程式,虽然它没做啥有意义的事。我们掩盖甚至忽略了一些OpenGL中有用的特性,主要是为了在比较短的篇幅内让我们可以从零到可以渲染些什么东西。我们还看到OpenGL的管线和功能如何使用扩展进行增强,其中不乏本书之后的示例会用到的。在下面的几个章节中,我们会学到更多计算机图形和OpenGL的基础,然后我们会再次回顾管线,对本章中的主题做更深入的了解,并且对本章跳过的一些OpenGL可以做的事情做了解。















 1925
1925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









