







CH1 强化学习简介(Introduction to Reinforcement Learning)
文章目录
1 关于强化学习
强化学习应用于许多学科,而它自身也属于机器学习分支之一。
机器学习 { 监督学习 非监督学习 强化学习 机器学习\left\{ \begin{array}{l} 监督学习\\ 非监督学习\\强化学习\end{array} \right. 机器学习⎩ ⎨ ⎧监督学习非监督学习强化学习
特点:
- 无监督者,只有奖励信号
- 反馈存在时延,非即时
- 时间重要,非独立同分布数据
- 个体动作影响后续接收的数据
2 强化学习问题
2.1 奖励
奖励(Reward,标量反馈信号),暗示个体如何做,个体可以最大化累积奖励为目标。
强化学习基于奖励假设(reward hypothesis):目标为期望累积报酬最大化
1️⃣序列决策:
- 目标:选择合适的动作以使得未来奖励最大
- 动作可能会有长期后果
- 奖励可能会延迟
- 可能会出现牺牲短期回报以获得长期回报的情况
2.2 环境
个体与环境:
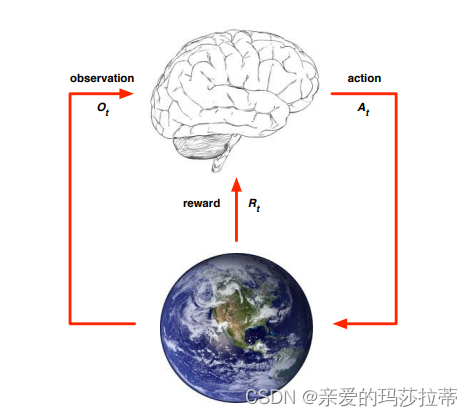
在t步中:
-
个体:接收来自环境的观察 Q t Q_t Qt,执行动作 A t A_t At,获得标量奖励 R t R_t Rt
-
环境:接收动作 A t A_t At,发射观察 Q t + 1 Q_{t+1} Qt+1,发射标量奖励 R t + 1 R_{t+1} Rt+1
t不断步进
2.3 状态
1️⃣历史与状态:
历史(history): 观察(observation)、行动(action)、奖励(reward)的序列。
t时刻的历史: H t = Q 1 , R 1 , A 1 , . . . , A t − 1 , Q t , R t H_t=Q_1,R_1,A_1,...,A_{t-1},Q_t,R_t Ht=Q1,R1,A1,...,At−1,Qt,Rt
(没有t时刻的行动)
- 是1~t时刻均可观测的变量
- 下一步会发生什么取决于历史:个体的行动选择、由环境选择的观察或奖励
状态(state): 用来确定接下来发生的事情的信息。
状态是历史的函数。
S t = f ( H t ) S_t=f(H_t) St=f(Ht)
2️⃣环境状态 S t e S^e_t Ste(environment state)
-
环境用于选择下一个观察/奖励的数据;
-
主体一般无法知道环境状态,即使环境状态已知,它也可能包含不相关信息。
3️⃣主体状态 S t a S^a_t Sta(agent state)
-
主体用于选择下一个动作的信息;
-
强化学习算法使用的信息;
-
主体状态也是历史的函数: S t a = f ( H t ) S^a_t=f(H_t) Sta=f(Ht)
4️⃣信息状态 O t O_t Ot(马尔科夫状态)(information state)
定义: S t S_t St是马尔科夫状态<=> P [ S t + 1 ∣ S t ] = P [ S t + 1 ∣ S 1 , . . . , S t ] P[S_{t+1}|S_t]=P[S_{t+1}|S_1,...,S_t] P[St+1∣St]=P[St+1∣S1,...,St]
特性:
- 未来由现在决定,与过去无关 H 1 : t − > S t − > H t + 1 : ∞ H_{1:t}->S_t->H_{t+1:\infty} H1:t−>St−>Ht+1:∞
- 环境状态 S t e S^e_t Ste和历史状态 H t H_t Ht都是马尔科夫状态
5️⃣完全可视环境与部分可视环境(Fully observable environments and partially observable environments)
完全可视环境:
-
个体可直接观察环境状态:信息状态=个体状态=环境状态
O t = S t a = S t e O_t=S^a_t=S^e_t Ot=Sta=Ste
-
属于马尔科夫决策过程(MDP,Markov decision process)
部分可视环境:
- 个体不直接观察环境:个体状态!=环境状态
S t a ! = S t e S^a_t!=S^e_t Sta!=Ste
-
属于部分可视马尔科夫决策过程(POMDP,partially observable Markov decision process)
-
个体须构造自身状态:
例如: S t a = H t S^a_t=H_t Sta=Ht
3 RL Agents(个体)
强化学习个体的组成部分:
- 策略(Policy):决定个体的动作函数
- 值函数(Value function):每个状态或动作的奖励(How good)
- 模型(Model):个体对环境的表示(模拟环境)
1️⃣策略(Policy)
策略是个体的动作,是状态到动作的map
确定策略(Deterministic policy): a = π ( s ) a=\pi(s) a=π(s)
随机策略(Stochastic policy): π ( a ∣ s ) = P [ A t = a ∣ S t = s ] \pi(a|s)=P[A_t=a|S_t=s] π(a∣s)=P[At=a∣St=s]
2️⃣值函数(Value function)
值函数是对未来奖励的预测,用于估计状态的好处与坏处
可以以此进行操作的选择,例如:
v π ( s ) = E π [ R t + 1 + γ R T + 2 + γ 2 R t + 3 + . . . ∣ S t = s ] v_{\pi}(s)=E_{\pi}[R_{t+1}+\gamma R_{T+2}+\gamma^2R_{t+3}+...|S_t=s] vπ(s)=Eπ[Rt+1+γRT+2+γ2Rt+3+...∣St=s]
3️⃣模型(Model)
模型用来模拟环境
P P P表示下一状态, R R R表示下一奖励(即时奖励)
例如:
P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] P^a_{ss'}=P[S_{t+1}=s'|S_t=s,A_t=a] Pss′a=P[St+1=s′∣St=s,At=a]
R s a = E [ R t + 1 ∣ S t = s , A t = a ] R^a_s=E[R_{t+1}|S_t=s,A_t=a] Rsa=E[Rt+1∣St=s,At=a]
4️⃣RL个体的分类:
-
基于值函数:无模型,有值函数
-
基于策略:无值函数,有策略
-
表演艺术家(Actor Critic):策略+值函数
-
基于模型:策略或值函数+模型

4 RL内的问题
1️⃣学习与计划(Learning and planning)
| 强化学习 | 计划 |
|---|---|
| 初始环境未知 | 环境模型已知 |
| 主体与环境互动 | 个体使用模型【模拟器】执行运算(不与外界交互) |
| 主体去决定策略 | 个体去决定策略 |
2️⃣探索与利用(Exploration and Exploitation)
| 探索 | 利用 |
|---|---|
| 探索从环境中寻找更多未知信息 | 利用已知的信息以使得回报最大化(目的性更强) |
探索与利用同等重要。
强化学习是种试错学习(trial-and- error learning),在不损失过多奖励的前提下,个体应从环境的经验中寻找策略。
3️⃣预测与控制(Prediction and control)
| 预测 | 控制 |
|---|---|
| 评估给出策略的未来 | 寻找最优策略以优化未来 |
奖励的前提下,个体应从环境的经验中寻找策略。
3️⃣预测与控制(Prediction and control)
| 预测 | 控制 |
|---|---|
| 评估给出策略的未来 | 寻找最优策略以优化未来 |














 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









