






一、机器学习算法的实现-估计器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
1、用于分类的估计器:
•sklearn.neighbors k-近邻算法
•sklearn.naive_bayes 贝叶斯
•sklearn.linear_model.LogisticRegression 逻辑回归
2、用于回归的估计器:
•sklearn.linear_model.LinearRegression 线性回归
•sklearn.linear_model.Ridge 岭回归
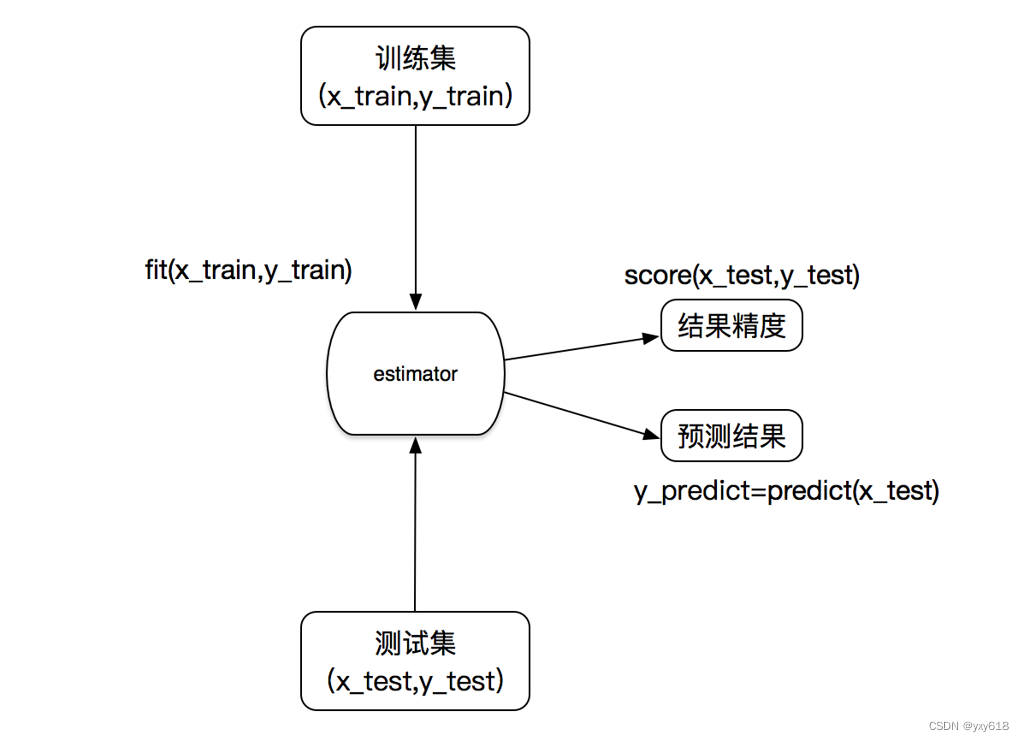
3.估计器的工作流程
4.分类算法-k近邻算法(knn)
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
计算距离公式:
两个样本的距离可以通过如下公式计算,又叫欧式距离
比如说,a(a1,a2,a3),b(b1,b2,b3)
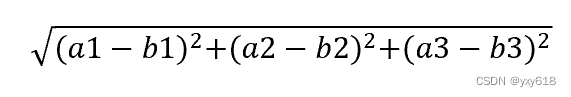
sklearn Knn API:
去测试
5.分类模型的评估
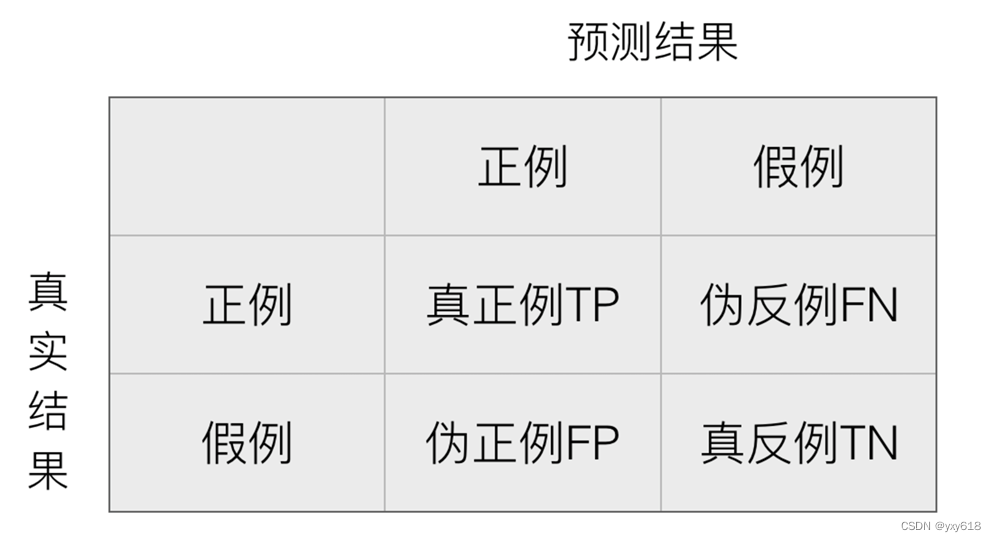


分类模型评估API:
•sklearn.metrics.classification_report

5.分类算法-朴素贝叶斯算法



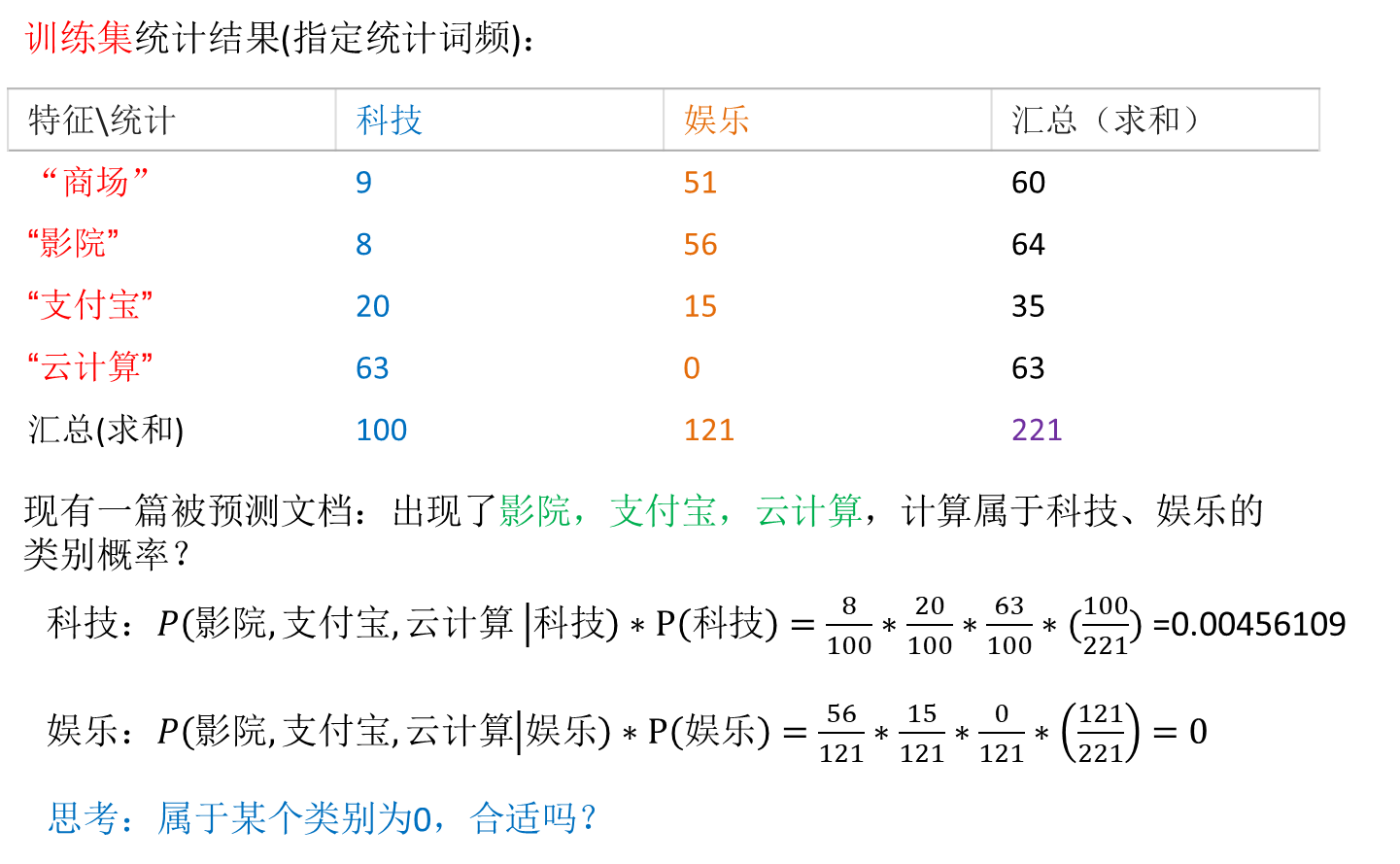

sklearn朴素贝叶斯实现API:

6.模型的选择与调优
1、交叉验证
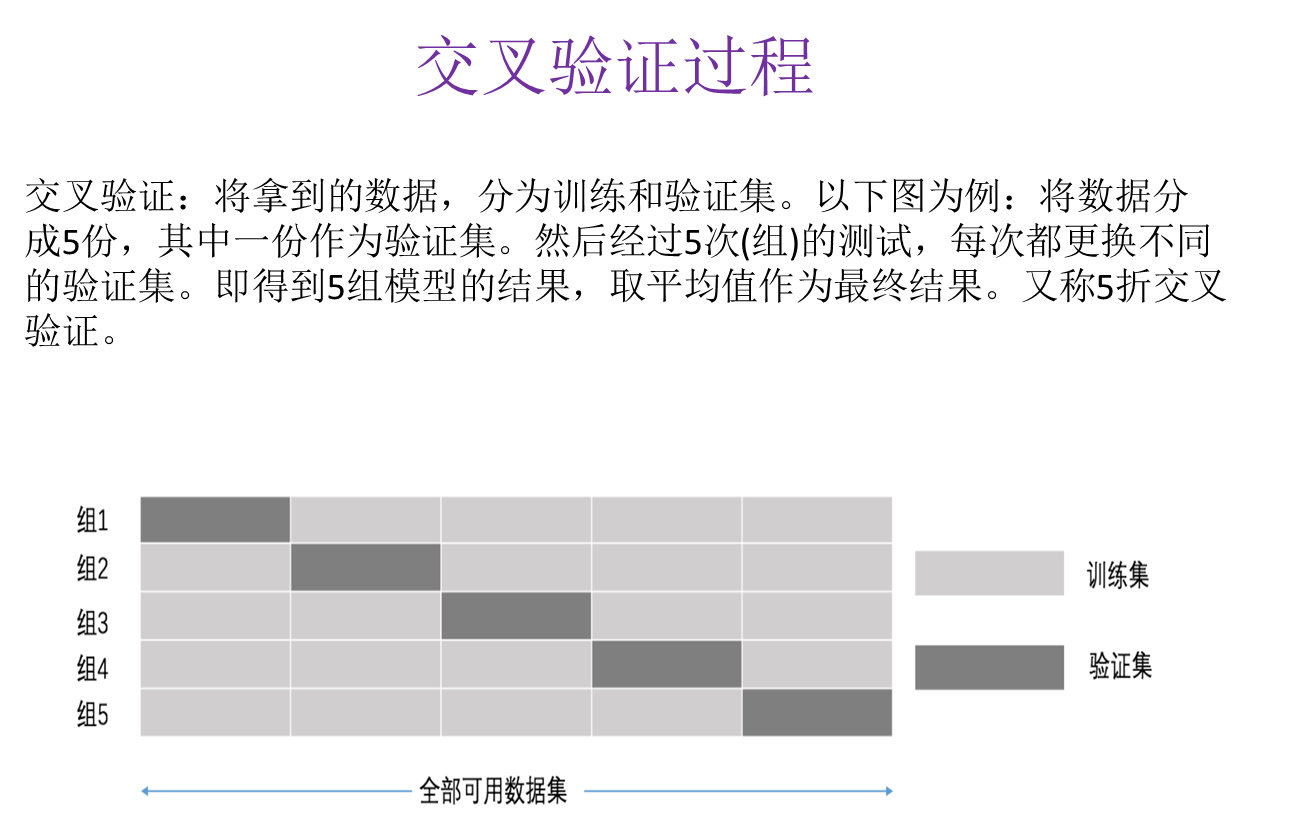
2、网格搜索

超参数搜索-网格API

7.分类算法-决策树,随机森林



常见决策树使用的算法:
信息增益 最大的准则
信息增益比 最大的准则
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则


随机森林:
随机森林是一种集成学习方法,包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
学习算法
根据下列算法而建造每棵树:
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
max_depth=None, bootstrap=True, random_state=None)
•随机森林分类器
•n_estimators:integer,optional(default = 10) 森林里的树木数量
•criteria:string,可选(default =“gini”)分割特征的测量方法
•max_depth:integer或None,可选(默认=无)树的最大深度
•bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
随机森林的优点















 652
652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









