







Transformer
Layer Norm
Batch Norm(左): 在每个batch里,将特征均值变成0,方差变成1,如下蓝色,不同batch的相同feature维度做norm

Layer Norm(右): 在同一batch的不同feature里做norm
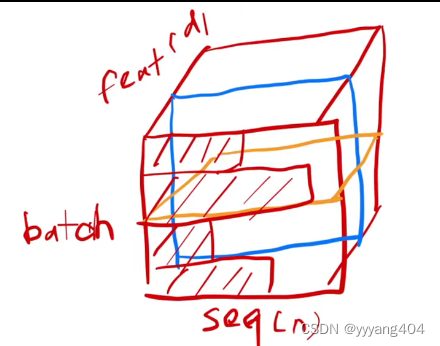
在实际训练中数据是(Batch*Seq*Feature),不同batch对应的seq的长度不同,然而又用了等长的feature表达。样本长度变化较大的时候,均值和方差的抖动比较大。Layer Norm在每个样本内部算均值和方差,较为稳定。
Attention
从整个序列中提取信息。尤其是self-attention,从自身中提取所有信息,再根据q-k找出相似度最大的信息,也就是有用的信息作为了特征向量。
例如给出一个q “hello”,根据q “hello”的vector去整个序列中计算点乘,越大的代表相似度(compatibility)越大,越小的代表相似度越小(比如空间上垂直)(e.g. “hello”和“hi”的相似度应该越大)。得到所有key和q“hello”的相似度之后,再再各个维度上根据相似度加权计算v,得到attention的output。
output再经过后面的Feed-Forward层等投影到目标的语义空间。
Multi-head Attention
有了上面的概念,类似于CNN不同通道的不同filter,使用不同head的attention可以提取出不同特性的信息。
Transformer实现的意义和RNN是一样的,将时序信息传递给输入进行计算,实现时序信息的传递。RNN中是前一时刻传递给后一时刻,Transformer中是通过attention在全局的序列中提取信息。又由于Transformer中不同信息可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1825
1825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









