









多元高斯分布
多变量高斯分布描述的是 n维随机变量的分布情况,这里的 μ 变成了向量, σ 也变成了矩阵 Σ 。写作 N(μ,Σ) 。其中 Σ (协方差矩阵)是一个半正定的矩阵, μ 是高斯分布的均值,下面给出它的概率密度函数:
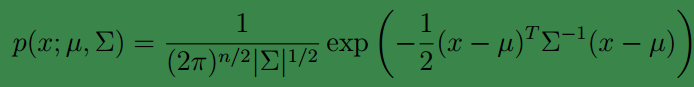
begin-补充-协方差和协方差矩阵:
协方差
在概率论和统计学中,协方差用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
期望值分别为E[X]与E[Y]的两个实随机变量X与Y之间的协方差Cov(X,Y)定义为:
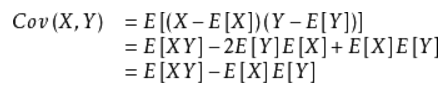
显然,当X=Y时就是方差啦。
从直观上来看,协方差表示的是两个变量总体误差的期望。
如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值时另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值;如果两个变量的变化趋势相反,即其中一个变量大于自身的期望值时另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
如果X与Y是统计独立的,那么二者之间的协方差就是0,因为两个独立的随机变量满足E[XY]=E[X]E[Y],因此协方差为0的两个随机变量称为是不相关的。但是,反过来并不成立。即如果X与Y的协方差为0,二者并不一定是统计独立的。
关于协方差还有以下定义:
1、设X和Y是随机变量,若E(Xk),k=1,2,...存在,则称它为X的k阶原点矩,简称k阶矩。
2、若E[X−E(X)]k,k=1,2,...存在,则称它为X的k阶中心矩。
3、若E{(Xk)(Yp)},k、p=1,2,...存在,则称它为X和Y的k+p阶混合原点矩。
4、若E{[X−E(X)]k[Y−E(Y)]l},k、l=1,2,...存在,则称它为X和Y的k+l阶混合中心矩。
显然,X的数学期望E(X)是X的一阶原点矩,方差D(X)是X的二阶中心矩,协方差Cov(X,Y)是X和Y的二阶混合中心矩。
协方差矩阵:
分别为
m
与
两个向量变量的协方差
Cov(X,Y)
与
Cov(Y,X)
互为转置矩阵。
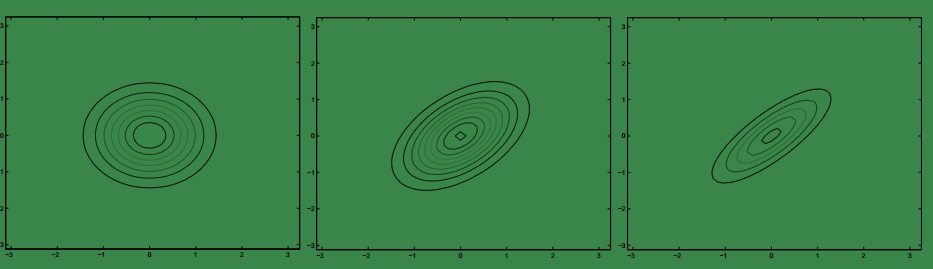
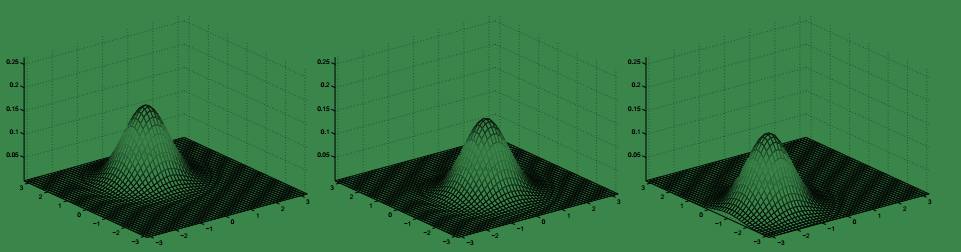
下面给出一些二元高斯分布的概率密度图:
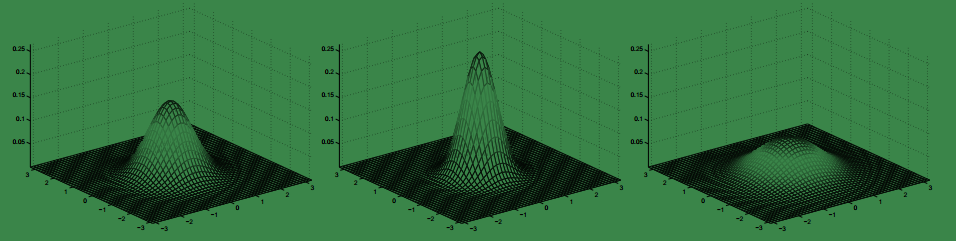
左图以
0
为均值,即
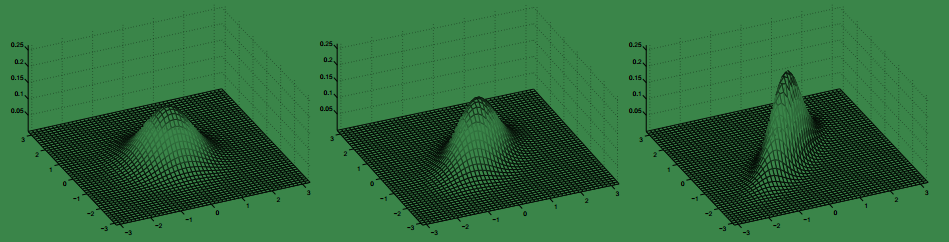
上图是以均值0,协方差矩阵的取值从左到右依次为:
下面是上图的轮廓图:
下面是固定Σ=I不变,改变μ的值,对应的概率密度图:
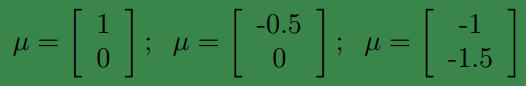
end-补充-协方差和协方差矩阵矩阵
高斯辨别模型
如果输入特征
x是
连续型随机变量,那么可以使用高斯判别分析模型来确定
p(x|y)
,建立模型如下:
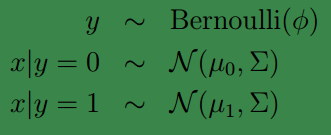
现在可以写出下面的概率密度函数:
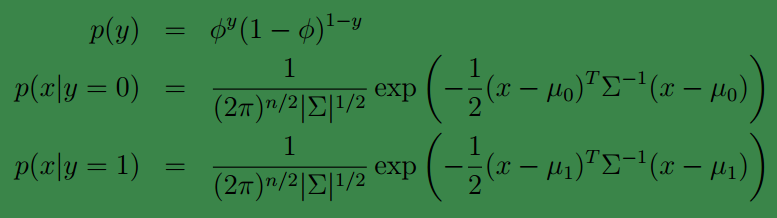
由
y∼Bernoulli(ϕ)
可得
p(y)=ϕy(1−ϕ)1−y
;而下面两个式子是由一维高斯分布推广得到。注意这里的参数有两个
μ
,表示在不同的结果模型下,特征均值不同,但我们假设协方差相同。 反映在图上就是不同模型中心位置不同,但形状相同。 这样就可以用直线来进行分隔判别。
从上式可知,模型中的参数是
ϕ,Σ,μ0,μ1
,因此可得log-likehood:
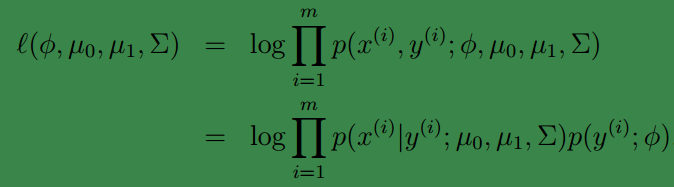
注:由上面可看出,最大似然值的大小与每次预测结果的乘积相关。假如有3个样本,第一个预测结果为类别y=1,且概率为0.1;第二个预测结果为类别y=1,且概率为0.1;第三个预测结果为类别y=0,且概率为0.1;这样似然值就是0.1X0.1X0.1=0.001,log-likehood就是log(0.001)。而假如:第一个预测结果为类别y=1,且概率为0.9;第二个预测结果为类别y=1,且概率为0.9;第三个预测结果为类别y=0,且概率为0.9;这样似然值就是0.9X0.9X0.9=0.729,log-likehood就是log(0.729);显然预测结果越精准,似然值越大。因此我们要求最大似然值。
为了能获得最大似然值,我们对
ϕ,Σ,μ0,μ1
分别求偏导数可以得到:
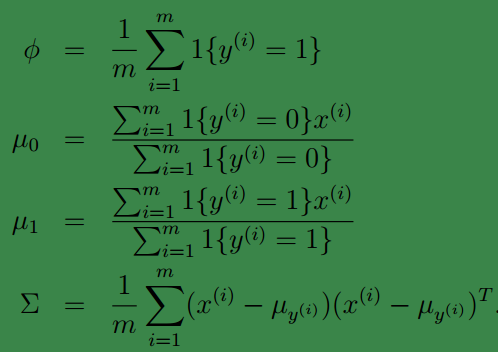
这里
ϕ
代表
y=1
的概率,而
y=0
的概率是
1−ϕ
,因此
ϕ=∑mi=1y(i)m=∑mi=1I{y(i)=1}m.
ϕ是训练样本中结果y=1占有的比例。
μ0是y=0的样本中特征均值。
μ1是y=1的样本中特征均值。
Σ是样本特征方差均值。
用图来表示我们训练的模型如下:
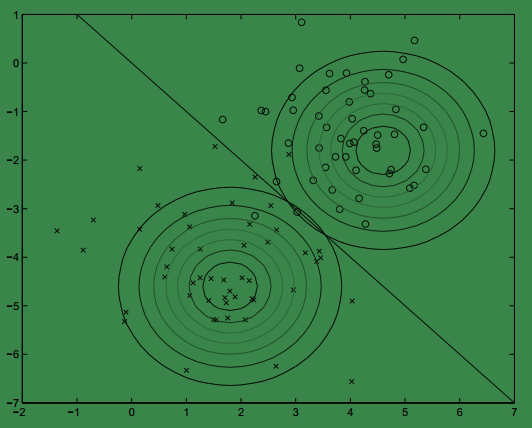
协方差矩阵相同,因此形状相同。 μ不同,因此位置不同。
在测试时,输出结果在图中直线上时,我们认为
p(y=1|x)与p(y=0|x)的概率都为0.5,否则,输出落在直线的哪一边,我们便认为样本更有可能是哪一类。
高斯判别分析( GDA)与 logistic 回归的关系
将 GDA 用条件概率方式来表述的话,如下:
p(y=1|x;ϕ,µ0,µ1,Σ)
,和之前的线性回归比较
p(y|x;θ)
,我们可以将前者改写成后者的形式,进而:
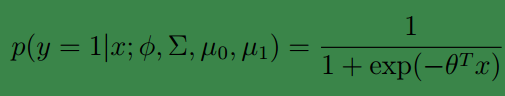
其中
θ是以ϕ,μ0,μ1Σ为参数构成的,这样就变成了线性回归模型,
这说明,可以用高斯辨别模型解决的问题也可以通过线性回归来解决。
也就是说如果p(x|y)符合多元高斯分布,那么p(y|x)符合logistic回归模型。
但是反过来却不一定成立,因为 GDA(高斯判别分析) 有着更强的假设条件和约束。
如果认定训练数据满足多元高斯分布,那么 GDA 能够在训练集上是最好的模型。然而,我们往往事先不知道训练数据满足什么样的分布, 不能做很强的假设。 Logistic回归的条件假设要弱于GDA,因此更多的时候采用 logistic 回归的方法。















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









