









高斯混合模型
下图以一维坐标系中的几个样本为例来说明混合高斯模型
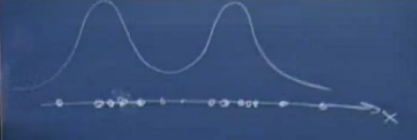
由图中可以看出,样本的分布情况可以由两个高斯分布来近似表示。这玩意就叫混合高斯模型。
简单的说就是:m个样本
{x1,...xm}
,可以分为k类,每个类别都服从高斯分布。
EM算法
给定训练样本
{x1,...xm}
,与k-means中的样本一样是没有标签的,因此EM也是非监督学习方法,我们将隐含类别标签用
z(i)
表示。与 k-means 的硬指定不同,我们首先认为
z(i)
是满足一定的概率分布的,这里我们认为满足多项式分布:
z(i)∼Multinomial(ϕ)
,其中
ϕj≥0,∑kj=1ϕj=1
,
ϕj=p(z(i)=j)
即第
i
个样本属于第
回想之前的高斯判别分析,我们知道,若
z(i)
是确定的,例如
z(i)=j
,那么
x(i)
应该是满足多元高斯分布的,即:
(x(i)|z(i)=j)∼N(μj,Σj)
.
我们知道
x(i)和z(i)
的联合概率分布
p(x(i),z(i))=p(x(i)|z(i))p(z(i))
.
模型中有三个参数
ϕ,μ,Σ
,类似高斯判别分析中的处理,我们可以写出似然函数:
然而,这里 z(i) 的值是不确定的,此时我们就无法通过之前求最大似然值的方法获得参数值的。
假如我们知道了类别
z(i)
的值,就可以通过求最大似然值获得参数,此时的likelihood函数也可以简写为:
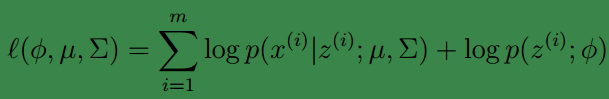
(显而易见,如果
z(i)
的取值只能是{0,1},那么上式就和高斯辨别分析模型一样一样的。)
通过最大似然值可求的参数:
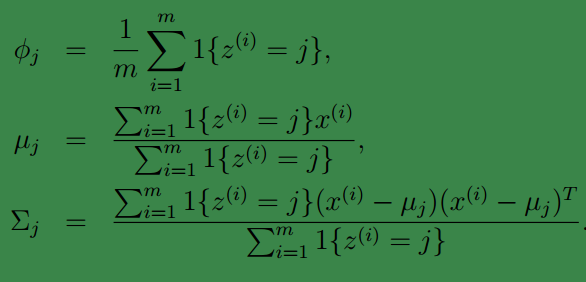
注意,这里的协方差矩阵是:每个高斯模型对应一个协方差矩阵,与高斯判别分析中共用一个协方差矩阵不同鸟。
但是事实上我们并不知道
z(i)
的具体指,怎么办呢?
EM算法按照如下思想应对这个问题:
1、猜测样本属于每个类别的概率
2、利用1中得到的概率值去更新参数
3、1和2迭代,直到收敛。
算法描述如下:
Repeat until convergence: {
(E-step) For each
i
,
w(i)j=p(z(i)=j|x(i);ϕ,μ,Σ)
(M-step) Update the parameters:
ϕj=1m∑mi=1w(i)j
μj=∑mi=1w(i)jx(i)∑mi=1w(i)j
Σj=∑mi=1w(i)j(x(i)−μj)(x(i)−μj)TΣmi=1w(i)j
}
在
E
步中,我们将其他参数
上面的
w(i)j
代表当前迭代中,第
i
个样本是第















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









