









深度学习爆发点AlexNet来源论文《ImageNet Classification with Deep Convolutional Neural Networks》读后总结
前言
这是一些对于论文《ImageNet Classification with Deep Convolutional Neural Networks》的简单的读后总结,文章下载地址奉上:http://dl.acm.org/ft_gateway.cfm?id=3065386&type=pdf
这篇文章是深度学习的祖师爷Geoffrey Hinton的团队所写的论文, 第一作者是Alex Krizhevsky,所以该网络名称为AlexNet,其是2012年ImageNet竞赛冠军获得者。该文章的重要意义在于其在ImageNet比赛中以巨大的优势击败了其它非神经网络的算法,在此之前,神经网络一直处于不被认可的状态。
废话不多说,直接进入主题。
文章主要内容与贡献
在该文章中获得成功的因素是:
- 有大量的样本防止网络欠拟合;
- 使用卷积和池化减少了参数量;
- 使用了反向传播得以训练参数;
- 使用了ReLU激活函数加速迭代;
- 使用了dropout防止网络欠拟合;
- 使用了数据增强技术;
- 使用了GPU加速迭代。
大量的样本
在这里指的当然是ImageNet数据集,大量的样本使得网络能拟合更复杂的函数。
卷积和池化
卷积神经网络的英文名即是论文中的Convolutional Neural Networks(CNN),卷积和池化如何实现的百度上都有,在这里需要重点说明的是该文章使用了重叠池化的技术降低了一些错误率。
反向传播
反向传播即BP(Back Propagation)算法,该算法以优化算法为基础,一层一层回传误差改进参数,该算法是深度神经网络得以实现的重要步骤。
具体使用的优化算法为随机梯度下降算法(Stochastic gradient descent, SGD),同时步长每次迭代都会有一定的衰减。
因为参数中有动量(取0.9),因此实质上算法应该是Momentum,且加入了权重衰减(取0.0005)。
ReLU激活函数
以前通常使用的是Sigmoid函数或tanh函数来作为激活函数,但是它们都是饱和非线性函数,一旦自变量超过一定值时便会迭代缓慢,而ReLU作为非饱和非线性函数则不会出现此类问题。
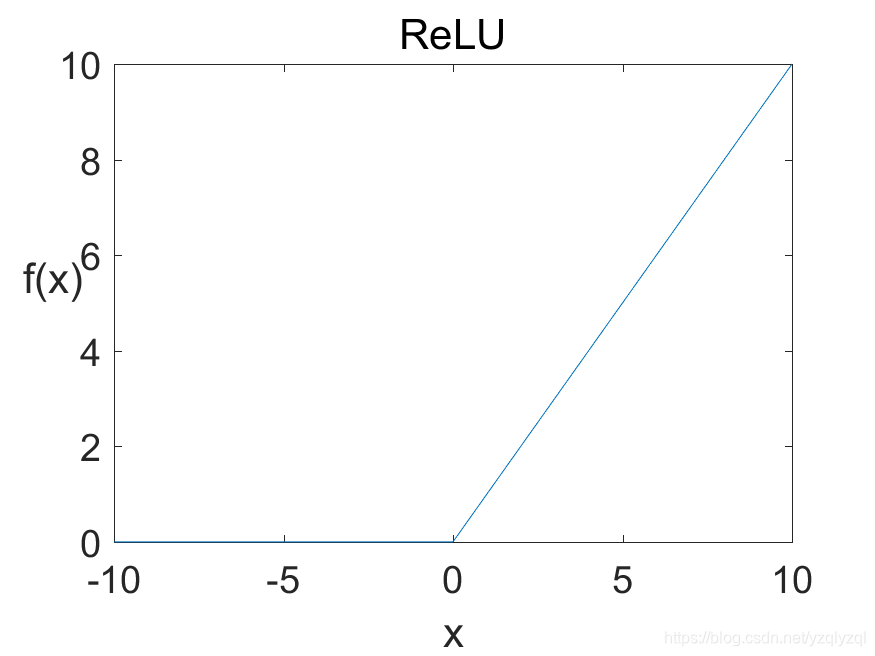
ReLU函数的公式和图皆如下所示:
f
(
x
)
=
m
a
x
(
0
,
x
)
.
f(x)=max(0,x).
f(x)=max(0,x).
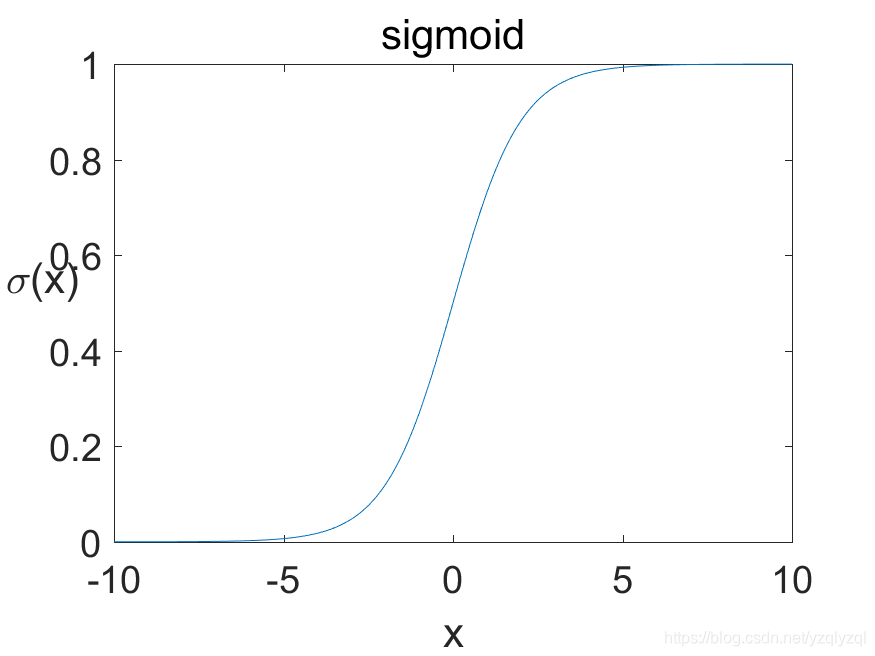
Sigmoid函数的公式和图皆如下所示:
σ
(
x
)
=
1
(
1
+
e
−
x
)
.
\sigma(x)=\dfrac {1}{(1+e^{-x})}.
σ(x)=(1+e−x)1.
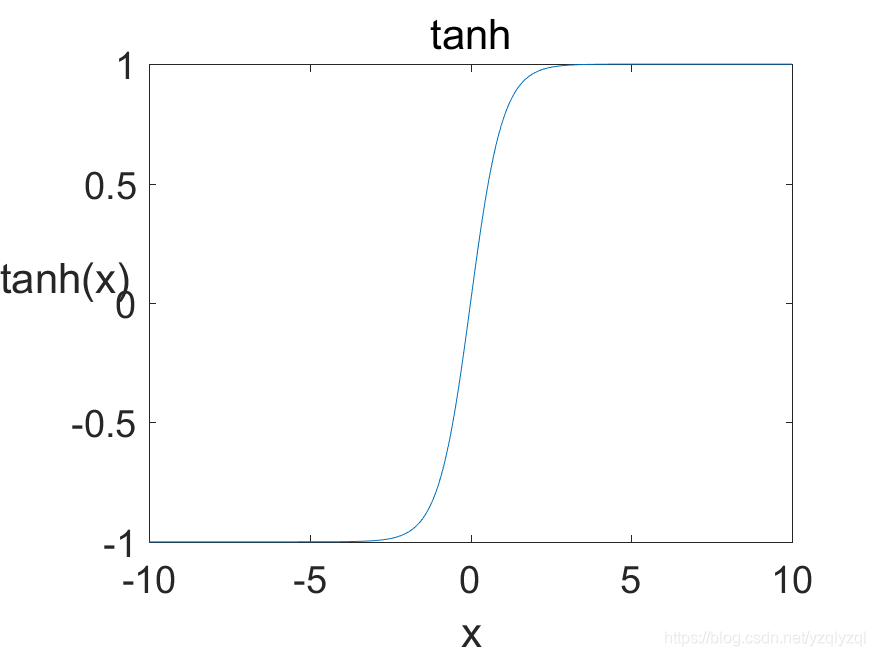
tanh函数的公式和图皆如下所示:
t
a
n
h
(
x
)
=
e
x
−
e
−
x
(
e
x
+
e
−
x
)
.
tanh(x)=\dfrac {e^x-e^{-x}}{(e^x+e^{-x})}.
tanh(x)=(ex+e−x)ex−e−x.
实验证明使用ReLU激活函数可以比Sigmoid或tanh快上好几倍。
dropout
dropout是一个很好的防过拟合方法,通过在训练时随机使一些神经元暂时失活来得以减少网络对单个神经元的依赖性,使得神经网络被迫学习更强大的特征。
数据增强
在该文章中,其相当于使用了10倍的原始数据集的数据来进行的实验,具体实现方法是通过取
256
×
256
256\times256
256×256的原始图片和其水平镜像的左上左下右上右下居中这5个方向的
224
×
224
224\times224
224×224的图片来实现的。
通过PCA计算出来相应的值来改变图像的亮度。
GPU加速的实现
该文章使用的是两块GTX580显卡来进行的训练,这是由于单块GTX580只有3GB的显存可以使用,不足以放下所有的参数,但是现今的显卡显存已足够。该文章的先进之处还是使用了显卡来训练神经网络。
AlexNet网络结构解析
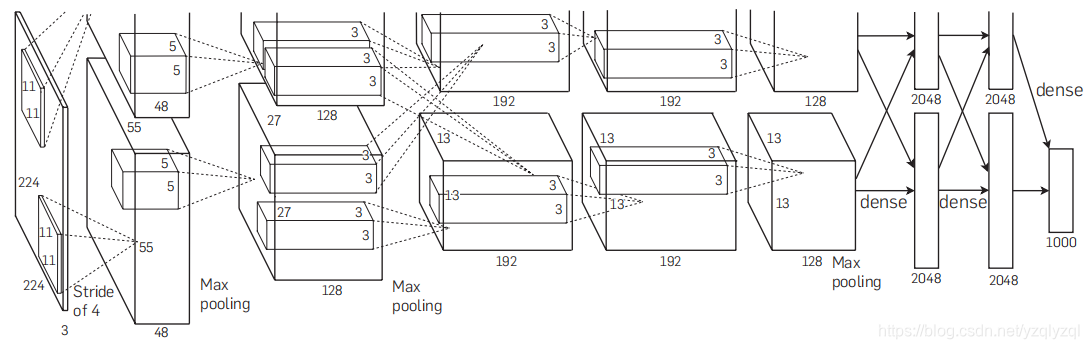
该网络总共有8层,前5层为卷积层,后3层为全连接层,输入为
224
×
224
×
3
224\times224\times3
224×224×3大小的RGB图片,池化层都是用的最大池化,最后的输出为一个
1000
1000
1000个分类的softmax层。
第一个卷积层用
96
96
96个大小为
11
×
11
×
3
11\times11\times3
11×11×3的步长为
4
4
4的卷积核对
224
×
224
×
3
224×224×3
224×224×3的输入图像进行卷积操作然后最大池化;
第二个卷积层用
256
256
256个大小为
5
×
5
×
48
5\times5\times48
5×5×48的步长为
1
1
1的卷积核对第一个卷积层的输出进行卷积操作然后最大池化;
第三个卷积层用
384
384
384个大小为
3
×
3
×
256
3\times3\times256
3×3×256的步长为
1
1
1的卷积核;
第四个卷积层用
384
384
384个大小为
3
×
3
×
192
3\times3\times192
3×3×192的步长为
1
1
1的卷积核;
第五个卷积层用
256
256
256个大小为
3
×
3
×
192
3\times3\times192
3×3×192的步长为
1
1
1的卷积核对第四个卷积层的输出进行卷积操作然后最大池化;
第六个全连接层有4096个神经元;
第七个全连接层有4096个神经元;
最后一层是输出层,为1000个分类的softmax层。
总共有6000万个参数。
AlexNet的结构可简单的的表示为下图:
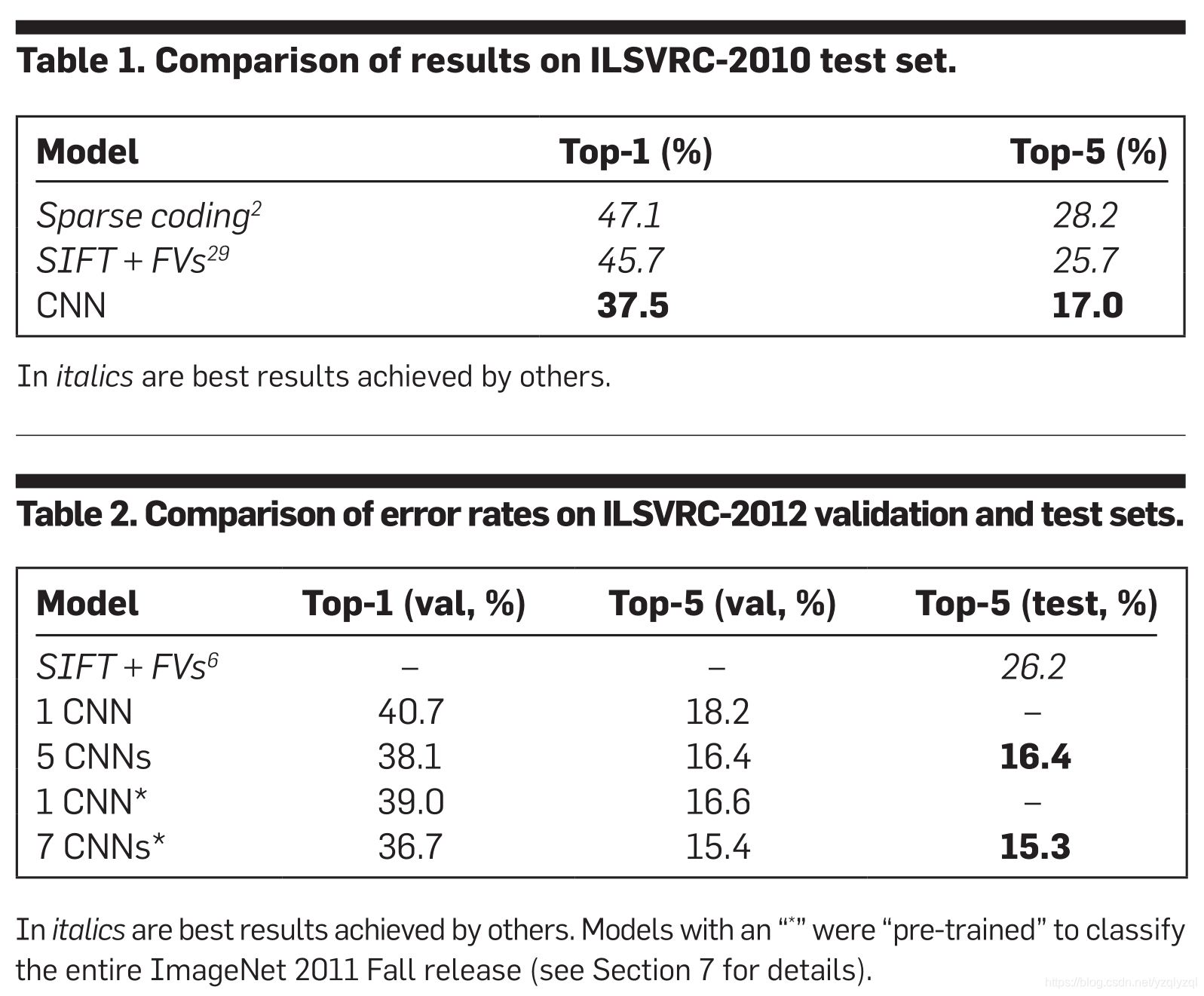
最后献上数值实验

















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









