






一、注意力机制来源
正常来说,我们在使用深度学习encoder-decoder框架的时候,使用的非线性变换方式都是没有偏重的,也就是对所有的输入都同等看待:
对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
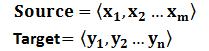
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:通常就是隐藏层的状态值:
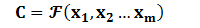
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息 来生成i时刻要生成的单词
来生成i时刻要生成的单词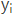 :
:
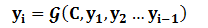
若引入注意力机制,那么对应每一个输入,他的中间语义表示C应该都不同,
即生成目标句子单词的过程成了下面的形式:
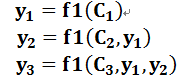
而新的Ci就是将原来隐藏层的值hi通过概率密度(就是你所需要的注意力的)转换为加了注意力的隐藏层的值:
即下列公式:
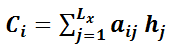
那么概率密度怎么得到呢:
"对于采用RNN的Decoder来说,在时刻i,如果要生成yi单词,我们是可以知道Target在生成之前的时刻i-1时,隐层节点i-1时刻的输出值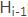 的,而我们的目的是要计算生成时输入句子中的单词“Tom”、“Chase”、“Jerry”对来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(
的,而我们的目的是要计算生成时输入句子中的单词“Tom”、“Chase”、“Jerry”对来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F( ,)来获得目标单词和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。"
,)来获得目标单词和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。"
给定这样一个场景:把输入信息向量X看做是一个信息存储器,现在给定一个查询向量q,用来查找并选择X中的某些信息,那么就需要知道被选择信息的索引位置。采取“软性”选择机制,不是从存储的多个信息中只挑出一条信息来,而是雨露均沾,从所有的信息中都抽取一些,只不过最相关的信息抽取得就多一些。
于是定义一个注意力变量来表示被选择信息的索引位置,即
来表示选择了第i个输入信息,然后计算在给定了q和X的情况下,选择第i个输入信息的概率
:
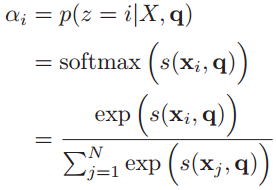
其中构成的概率向量就称为注意力分布(Attention Distribution)。
是注意力打分函数,有以下几种形式:
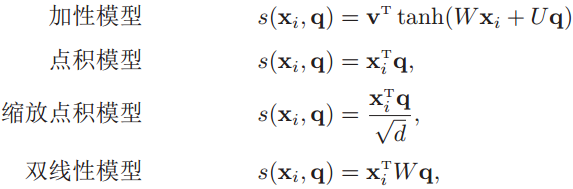
其中W、U和v是可学习的网络参数,d是输入信息的维度。
两个向量的点积与它们之间夹角的余弦成正比(图2.4),因此它们在方向上越接近,点积就越大。如果它们指向同一个方向,那么角A为0⁰,余弦为0⁰等于1。如果它们指向相反的方向(因此A=180⁰),那么余弦值为-1。

二、步骤
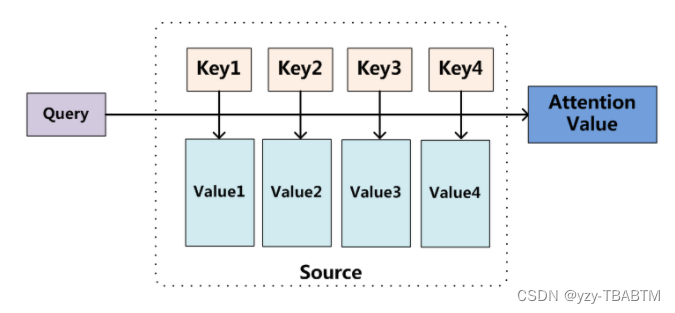
最早来源于翻译,对于一组数据对(key,value),通过给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key(你想要关注的地方,也就是注意力)对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
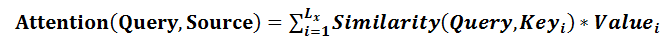
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个 ,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:
,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
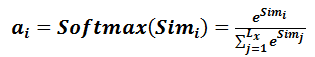
第二阶段的计算结果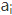 即为
即为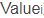 对应的权重系数,然后进行加权求和即可得到Attention数值:
对应的权重系数,然后进行加权求和即可得到Attention数值:

通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
例子:strip pooling 条带池化:
1.对于传统的池化方法,空洞卷积(dilated convolutional)还有全局/金字塔池化(global/pyramid pooling),二者对应与spp和aspp,对于各向异性上下文的语义信息捕获不好。
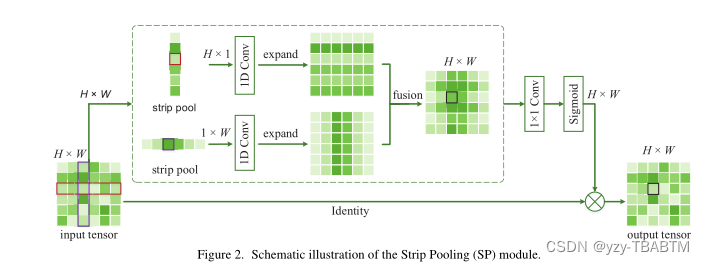
上图中,sigmiod函数处便是第二个步骤,也就是 将相似性变为概率,乘以原始特征得到attention的特征图。
三、自我注意力机制
而后,硕士论文“基于多元传感器的无人车感知算法研究”将条带池化扩展到条带注意力机制:
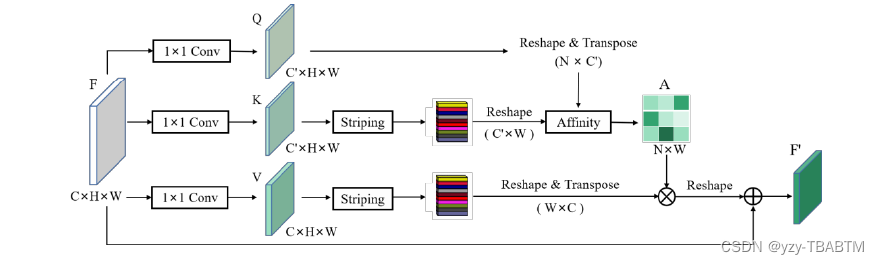
可以看到,K图通过条带池化得到带状特征(value),通过和源特征图(key)进行相似度求解(为什么具体到矩阵就是乘法,此处下文affnet也用到) 得到相似性矩阵,再乘以带状特征(value)得到















 1531
1531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









