







论文

标题:S 2 -FPN: Scale-ware Strip Attention Guided Feature Pyramid Network for Real-time Semantic Segmentation
地址:https://arxiv.org/abs/2206.07298
简介

本文立足于已有的框架,提出一个新的语义分割框架,包含有三个主要模块,APF注意力金字塔融合、SSAM范围感知的带状注意力模块、GFU全局特征上采样。实验证明,性能得到提升。
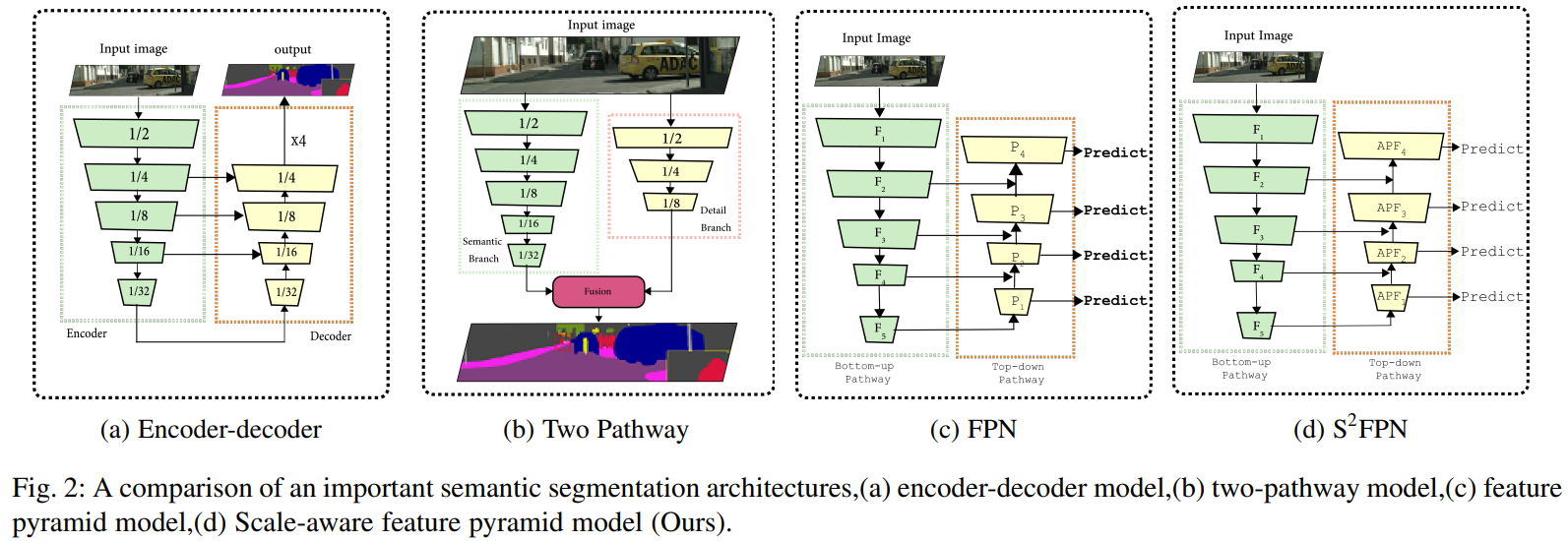
方法
框架
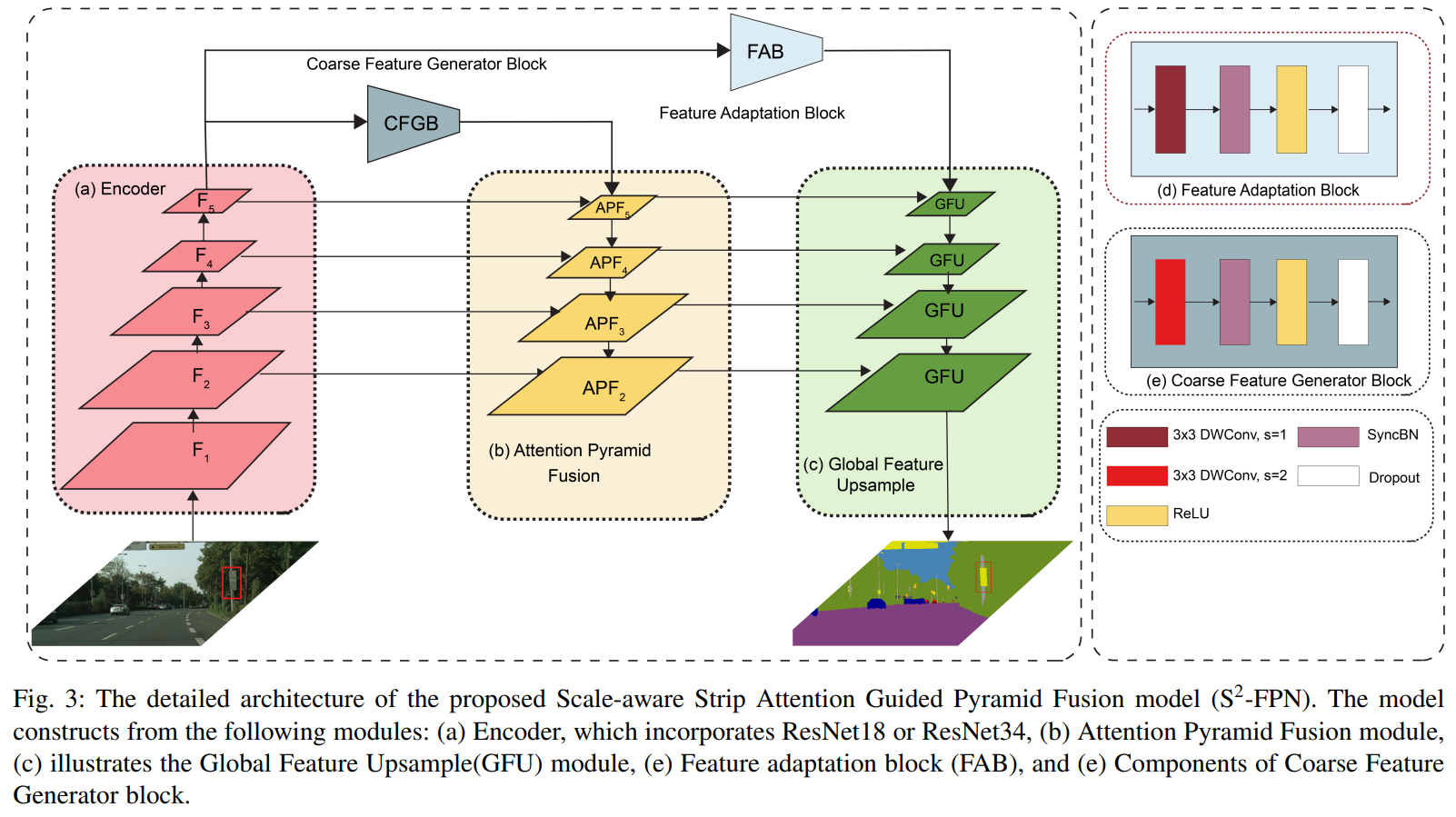
根据上面图片中的描述,就可以得到模型的总体结构,模型分为三个部分:
- 特征抽取或编码
- 注意力金字塔融合(APF)
- 全局特征上采样(GFU)
其中分别包括了CFGB,FAB,SSAM。
SSFPN采用resnet18或者resnet34作为基础的model,去掉其中的全局平均池化层以及softmax,根据基础模型的步长取出对应的特征。步长为2,4,8,16,32的情况下,得到F1,F2,F3,F4,F5。
在F5之后分别接两个模块:
- 粗糙特征生成块(CFGB)
- 包含一个步长为2的卷积层来生成粗糙特征,目的是为了APF做准备
- 特征适应块(FAB)
- 包含一个步长为1的卷积层来为GFU做准备
注意:APF中步长分别为4,8,16,32。
APF2,APF3,APF4,APF5是从上到下的特征生成,使用APF模块。
代码: SSFPN
class SSFPN(nn.Module):
def __init__(self, backbone, classes = 1, pretrained = True):
super().__init__()
self.backbone = backbone.lower()
self.pretrained = pretrained
self.encoder, self.out_channels = self.get_backbone_layer()
self.conv1_x = self.encoder.conv1
self.bn1 = self.encoder.bn1
self.relu = self.encoder.relu
self.maxpool = self.encoder.maxpool
self.conv2_x = self.encoder.layer1
self.conv3_x = self.encoder.layer2
self.conv4_x = self.encoder.layer3
self.conv5_x = self.encoder.layer4
self.fab = nn.Sequential(
conv_block(in_channels=self.out_channels, out_channels=self.out_channels // 2, kernel_size=3, stride=1, padding=1, use_bn_act=True)
)
self.cfgb = nn.Sequential(
conv_block(in_channels=self.out_channels, out_channels=self.out_channels, kernel_size=3, stride=2, padding=1, use_bn_act=True)
)
self.apf5 = APF(self.out_channels, self.out_channels, self.out_channels // 2, classes=classes)
self.apf4 = APF(self.out_channels // 2, self.out_channels // 2, self.out_channels // 4, classes=classes)
self.apf3 = APF(self.out_channels // 4, self.out_channels // 4, self.out_channels // 8, classes=classes)
self.apf2 = APF(self.out_channels // 8, self.out_channels // 8, self.out_channels // 16, classes=classes)
self.gfu5 = GFU(self.out_channels // 2, self.out_channels // 2, self.out_channels // 2)
self.gfu4 = GFU(self.out_channels // 4, self.out_channels // 2, self.out_channels // 4)
self.gfu3 = GFU(self.out_channels // 8, self.out_channels // 4, self.out_channels // 8)
self.gfu2 = GFU(self.out_channels // 16, self.out_channels // 8, self.out_channels // 16)
self.classifier = conv_block(self.out_channels // 16, classes, 1, 1, 0, True)
def get_backbone_layer(self):
assert self.backbone == 'resnet18' or self.backbone == 'resnet34' or self.backbone == 'resnet50', f'backbone 不符合'
if self.backbone == 'resnet18':
encoder = resnet18(pretrained=self.pretrained)
out_channels = 512
if self.backbone == 'resnet34':
encoder = resnet34(pretrained=self.pretrained)
out_channels = 512
if self.backbone == 'resnet50':
encoder = resnet50(pretrained=self.pretrained)
out_channels = 2048
return encoder, out_channels
def forward(self, x):
B, C, H, W = x.size()
x = self.conv1_x(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x2 = self.conv2_x(x)
x3 = self.conv3_x(x2)
x4 = self.conv4_x(x3)
x5 = self.conv5_x(x4)
cfgb = self.cfgb(x5)
fab = self.fab(x5)
apf5, cls5 = self.apf5(cfgb, x5)
apf4, cls4 = self.apf4(apf5, x4)
apf3, cls3 = self.apf3(apf4, x3)
apf2, cls2 = self.apf2(apf3, x2)
gfu5 = self.gfu5(apf5, fab)
gfu4 = self.gfu4(apf4, gfu5)
gfu3 = self.gfu3(apf3, gfu4)
gfu2 = self.gfu2(apf2, gfu3)
cls = self.classifier(gfu2)
pre = F.interpolate(cls, size=(H,W), mode='bilinear')
sup5 = F.interpolate(cls5, size=(H,W), mode='bilinear')
sup4 = F.interpolate(cls4, size=(H,W), mode='bilinear')
sup3 = F.interpolate(cls3, size=(H,W), mode='bilinear')
sup2 = F.interpolate(cls2, size=(H,W), mode='bilinear')
if self.training:
return pre, sup5, sup4, sup3, sup2
else:
return pre注意力金字塔融合模块(APF)
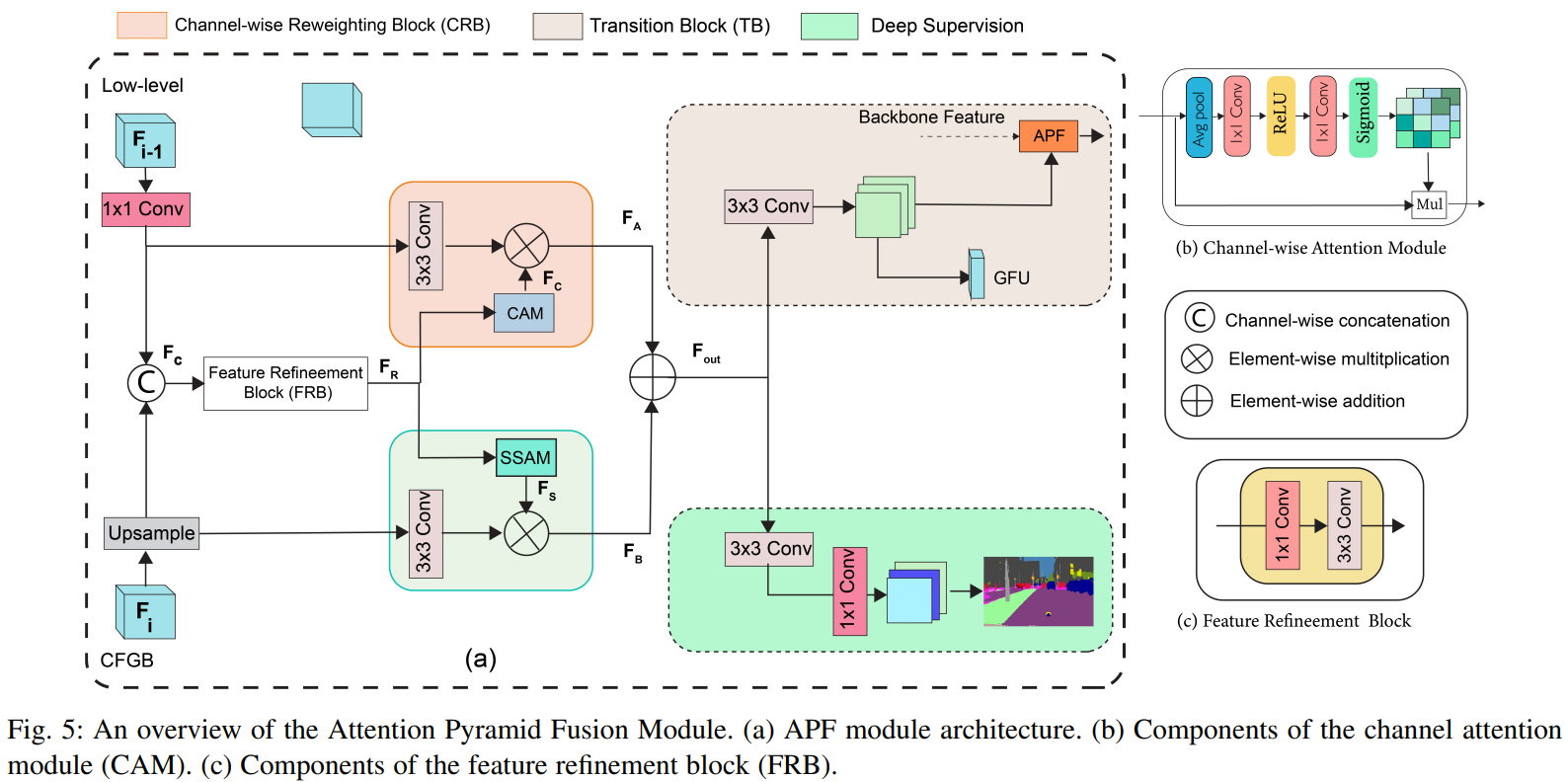

代码: APF
class APF(nn.Module):
def __init__(self, channels_high, channels_low, channel_out, classes = 1):
super().__init__()
self.lateral_low = conv_block(channels_low, channels_high, 1, 1, 0, use_bn_act=True)
self.frb = nn.Sequential(
conv_block(channels_high * 2, channel_out, 1, 1, 0, True),
conv_block(channel_out, channel_out, 3, 1, 1, True)
)
self.fc_conv = conv_block(channels_high, channel_out, 3, 1, 1, True)
self.fs_conv = conv_block(channels_high, channel_out, 3, 1, 1, True)
self.cam = CAM(channel_out)
self.ssam = SSAM(channel_out, channel_out)
self.classifier = conv_block(channel_out, classes, 3, 1, 1, True)
self.apf = conv_block(channel_out, channel_out, 3, 1, 1, True)
def forward(self, x_high, x_low):
x_low = self.lateral_low(x_low)
x_high = F.interpolate(x_high, size=x_low.size()[2:], mode='bilinear')
f_c = torch.cat([x_low, x_high], 1)
f_r = self.frb(f_c)
f_a = torch.mul(self.fc_conv(x_low), self.cam(f_r))
f_b = torch.mul(self.fs_conv(x_high), self.ssam(f_r))
f_out = f_a + f_b
apf = self.apf(f_out)
classifier = self.classifier(f_out)
return apf, classifier
class CAM(nn.Module):
def __init__(self, channel):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1 = conv_block(channel, channel, 1, 1, use_bn_act=False, padding=0)
self.relu = nn.ReLU()
self.conv2 = conv_block(channel, channel, 1, 1, use_bn_act=False, padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
redisual = x
x = self.avg_pool(x)
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.sigmoid(x)
return torch.mul(redisual, x)比例感知注意力模块(SSAM)
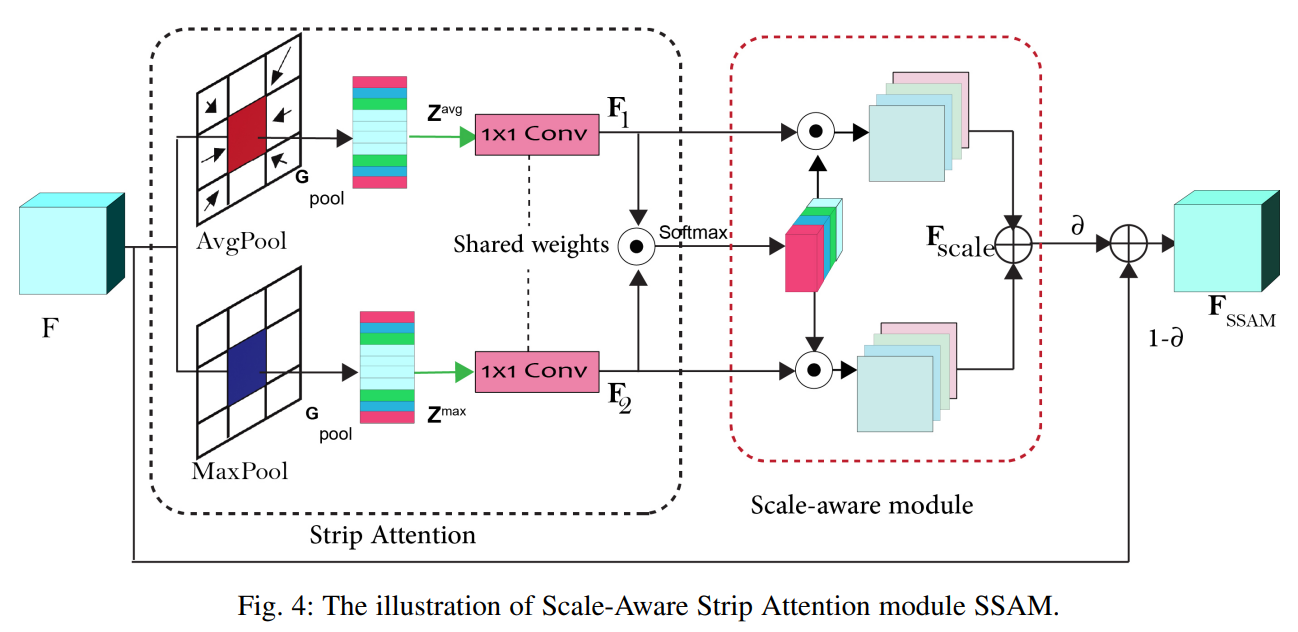

代码: SSAM
class SSAM(nn.Module):
def __init__(self, in_channels, out_channels):
super(SSAM, self).__init__()
self.conv_shared = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1)
self.bn_shared_max = nn.BatchNorm2d(in_channels)
self.bn_shared_avg = nn.BatchNorm2d(in_channels)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
B, C, H, W = x.size()
max_pool = F.max_pool2d(x, [1, W])
max_pool = self.conv_shared(max_pool)
max_pool = self.bn_shared_max(max_pool)
avg_pool = F.avg_pool2d(x, [1, W])
avg_pool = self.conv_shared(avg_pool)
avg_pool = self.bn_shared_avg(avg_pool)
att = torch.softmax(torch.mul(max_pool, avg_pool), 1)
f_scale = att * max_pool + att * avg_pool
out = F.relu(self.gamma * f_scale + (1 - self.gamma) * x)
return out全局特征上采样(GFU)
在模型纵览中的第一张图片中,APF后面接的是Predict,但是在第二张图中,显示的是GFU,同时该模型会输出5个输出。
其中每个APF后各有一个输出,GFU后还有一个输出,做推理的时候用的是GFU后的输出.
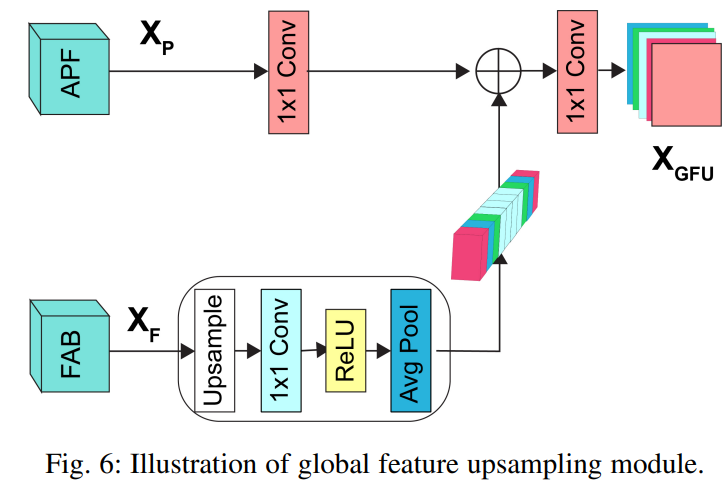

代码: GFU
class GFU(nn.Module):
def __init__(self, apf_channel, fab_channel, out_channel):
super().__init__()
self.apf_conv = conv_block(apf_channel, out_channel, 1, 1, 0, True)
self.fab_conv = nn.Sequential(
conv_block(fab_channel, out_channel, 1, 1, 0, False),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1)
)
self.out_conv = conv_block(out_channel, out_channel, 1, 1, 0, True)
def forward(self, apf, fab):
B, C, H, W = apf.size()
apf = self.apf_conv(apf)
fab = F.interpolate(fab, size=(H, W), mode='bilinear')
fab = self.fab_conv(fab)
f_out = apf + fab
f_out = self.out_conv(f_out)
return f_out
class conv_block(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, use_bn_act):
super(conv_block, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
self.relu = nn.ReLU()
self.normalization = nn.BatchNorm2d(out_channels)
self.use_bn_act = use_bn_act
def forward(self, x):
if self.use_bn_act:
return self.relu(self.normalization(self.conv(x)))
else:
return self.conv(x)实验
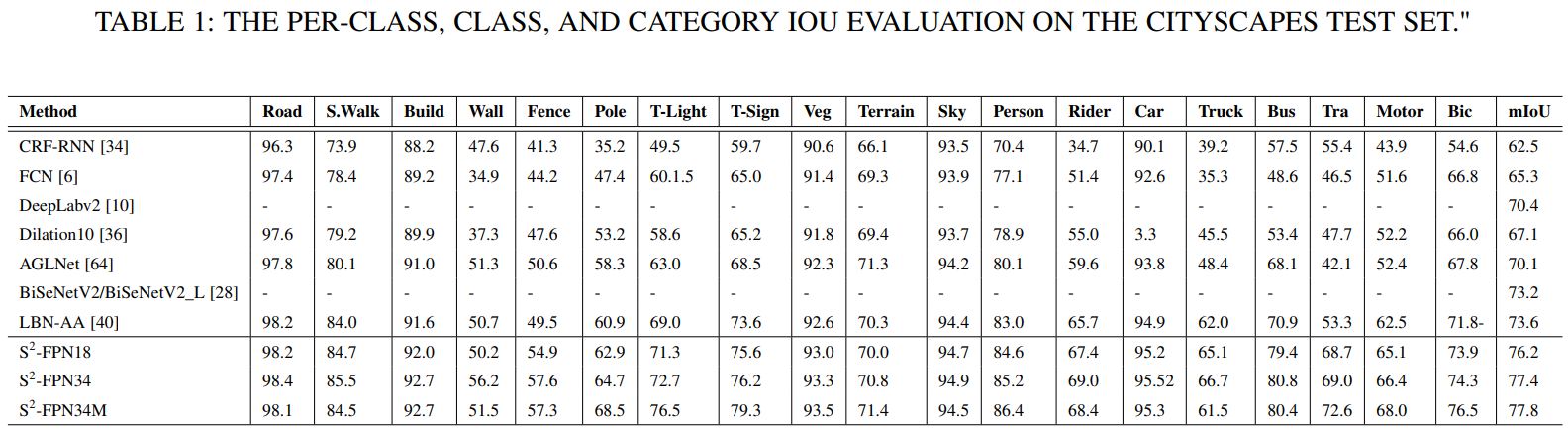
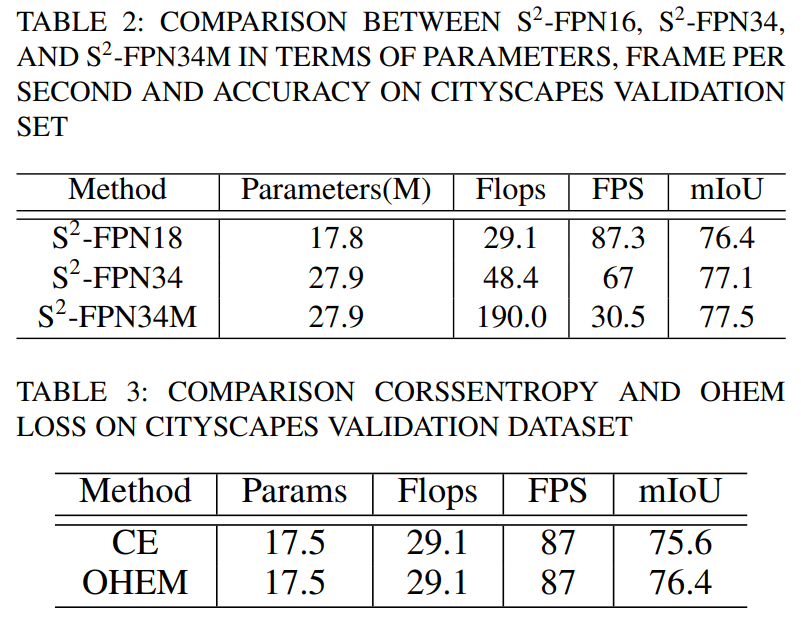
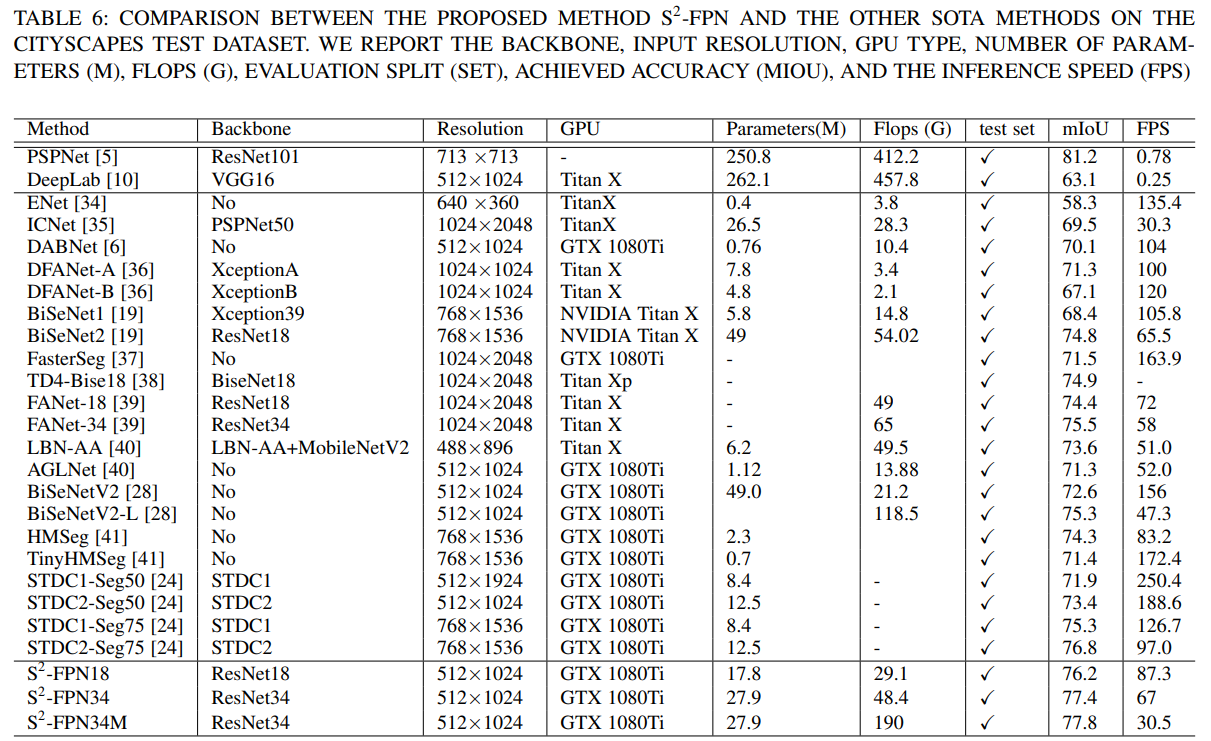
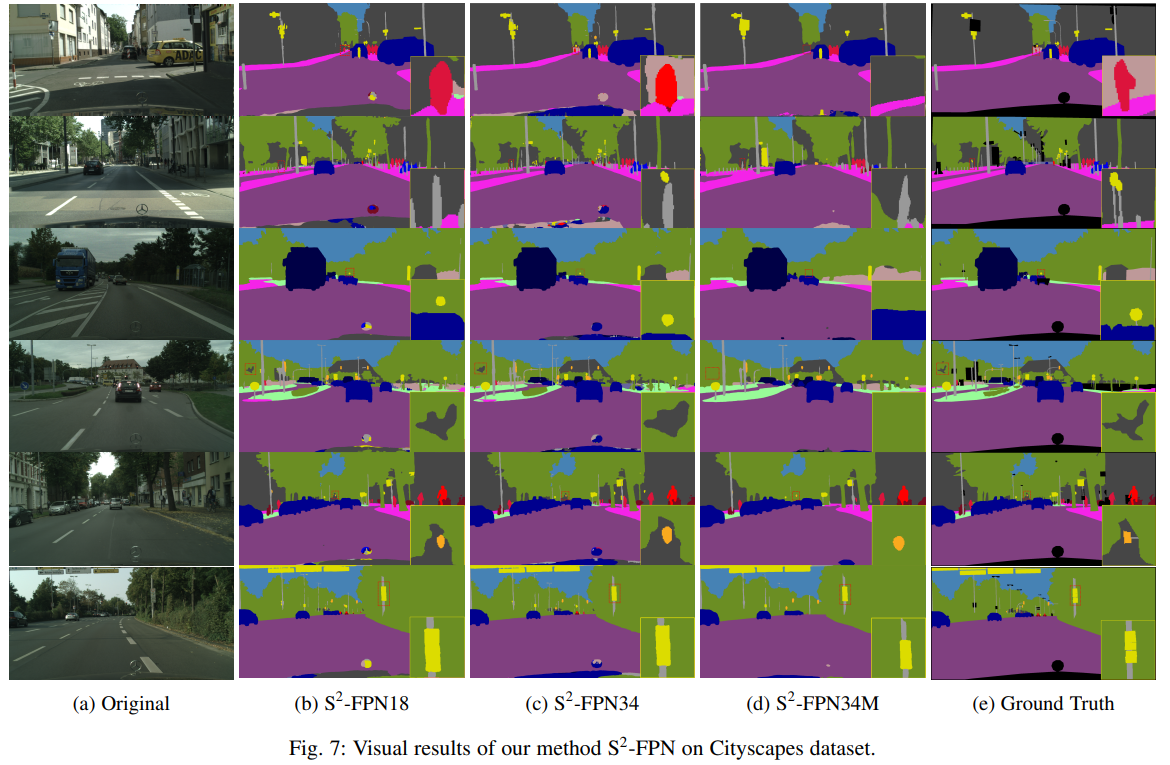
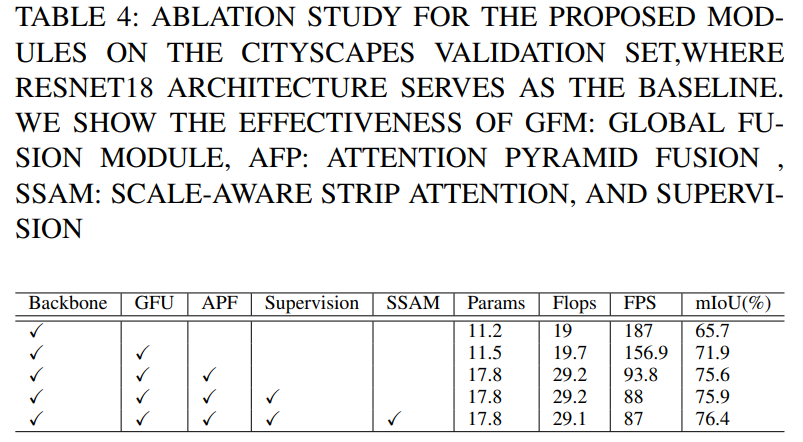
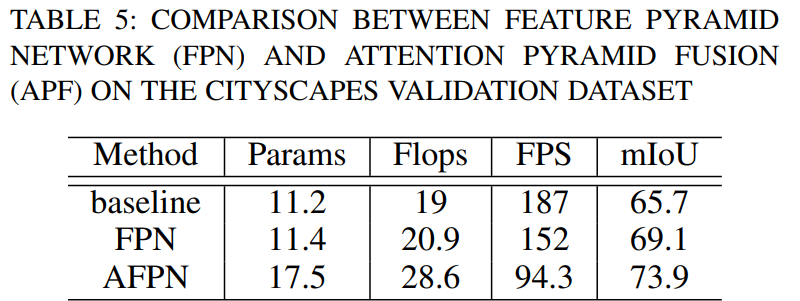
消融实验

















 1970
1970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









