






 文章探讨了基于Transformer的方法在超高清低光图像增强中的应用,对比了Stripformer的工作机制,并提出了可能的优化方向。此外,介绍了用于图像超分辨率的ShuffleMixerConvNet,强调其在计算效率和多尺度融合方面的潜力。DEA-Net利用细节增强卷积进行单图像去雾,而DAE-Former则展示了在医疗图像分割中双注意力引导的高效Transformer设计。
文章探讨了基于Transformer的方法在超高清低光图像增强中的应用,对比了Stripformer的工作机制,并提出了可能的优化方向。此外,介绍了用于图像超分辨率的ShuffleMixerConvNet,强调其在计算效率和多尺度融合方面的潜力。DEA-Net利用细节增强卷积进行单图像去雾,而DAE-Former则展示了在医疗图像分割中双注意力引导的高效Transformer设计。
目录
- Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
- ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
- A Close Look at Spatial Modeling: From Attention to Convolution
- DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
- DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
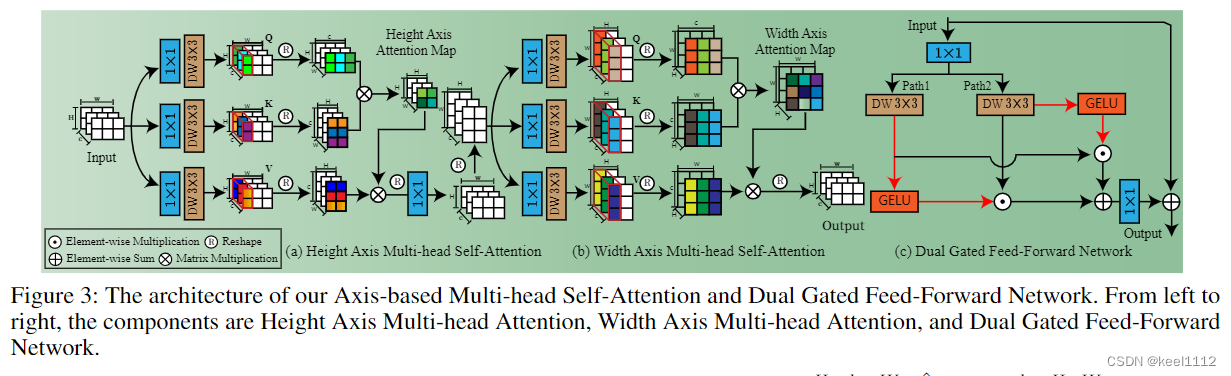
本文的轴注意力先计算H方向的注意力,再计算W上的注意力,跟stripformer工作中计算条带间注意力的工作非常相似。下图为stripformer计算条带间注意力的模型。
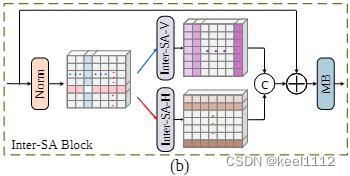
可以看到stripformer是并联的。串联是否会比并联更有效,串联好像融合了更多信息,这个点可以跑跑实验证明一下。
stripformer还进行了条带内的注意力计算。另外两个创新点(双门控FFN和Layer Attention)也可以尝试融入stripformer中。
ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
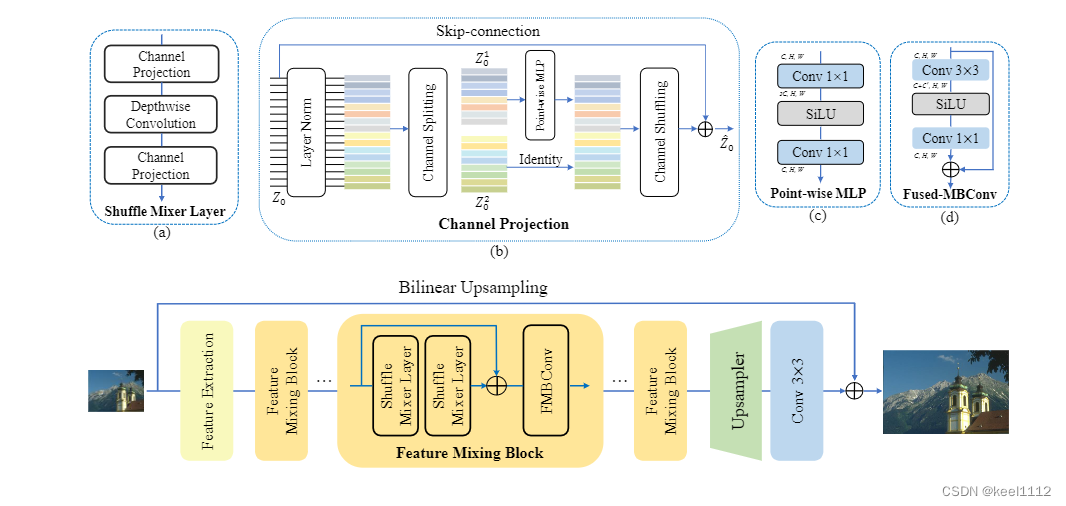
超分的工作思路感觉可以用在多尺度特征的多尺度融合。比如下图中低尺度特征的上采样过程。
在低尺度上用计算量也不会太大。
A Close Look at Spatial Modeling: From Attention to Convolution
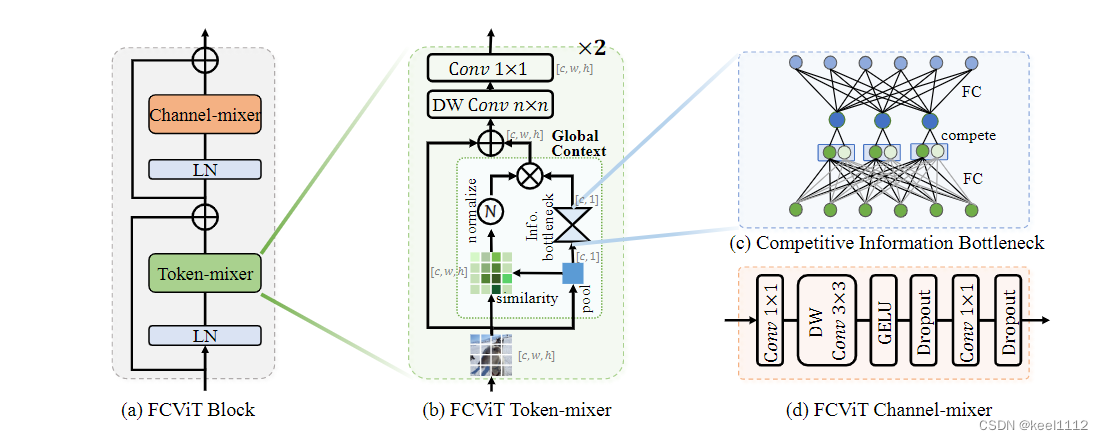
用卷积代替Transformer,核心问题就是怎么求注意力矩阵。
DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
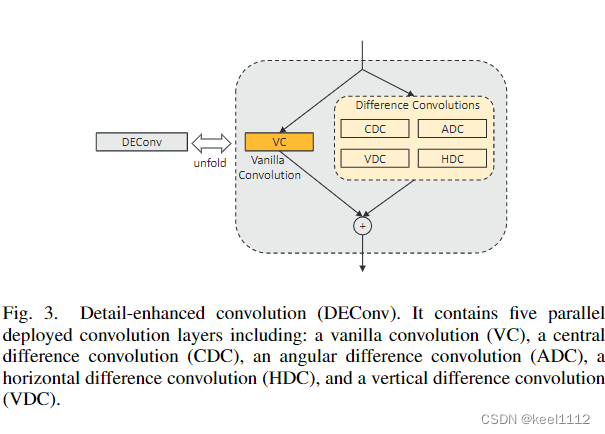
对这个卷积很感兴趣,这是受边缘先验启发设计的一个细节增强卷积(DEConv)层。
这个vanilla卷积用于获得强度水平信息,而差分卷积用于增强梯度水平信息。只需将学习到的特征相加,即可获得DEConv的输出。
作者相信,更复杂的像素差计算方法的设计可以进一步有利于图像恢复任务
DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
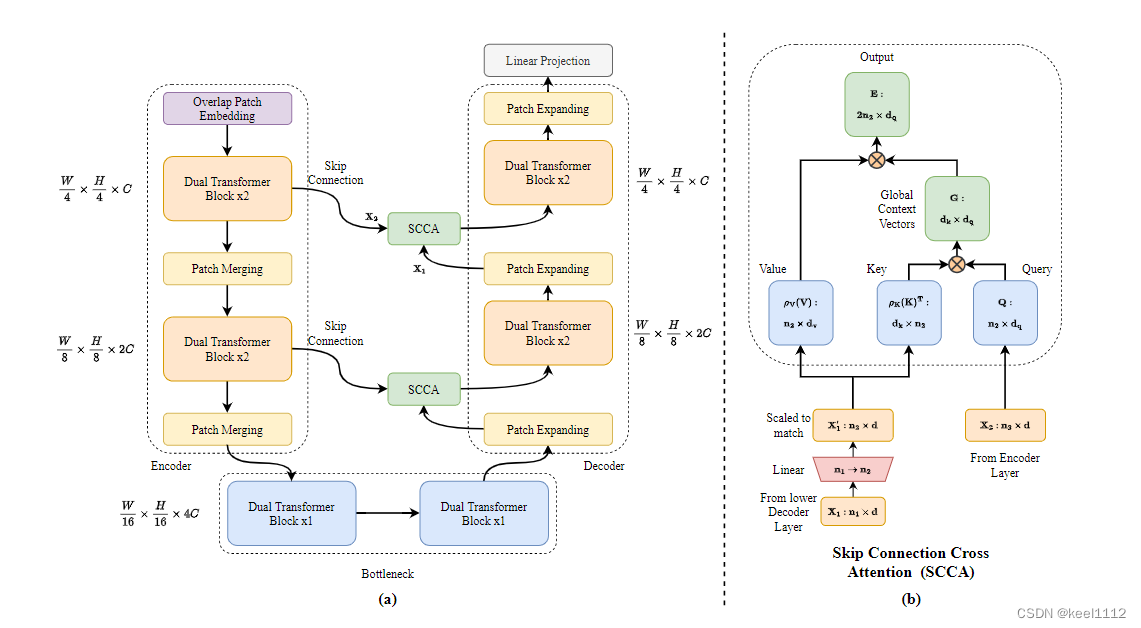
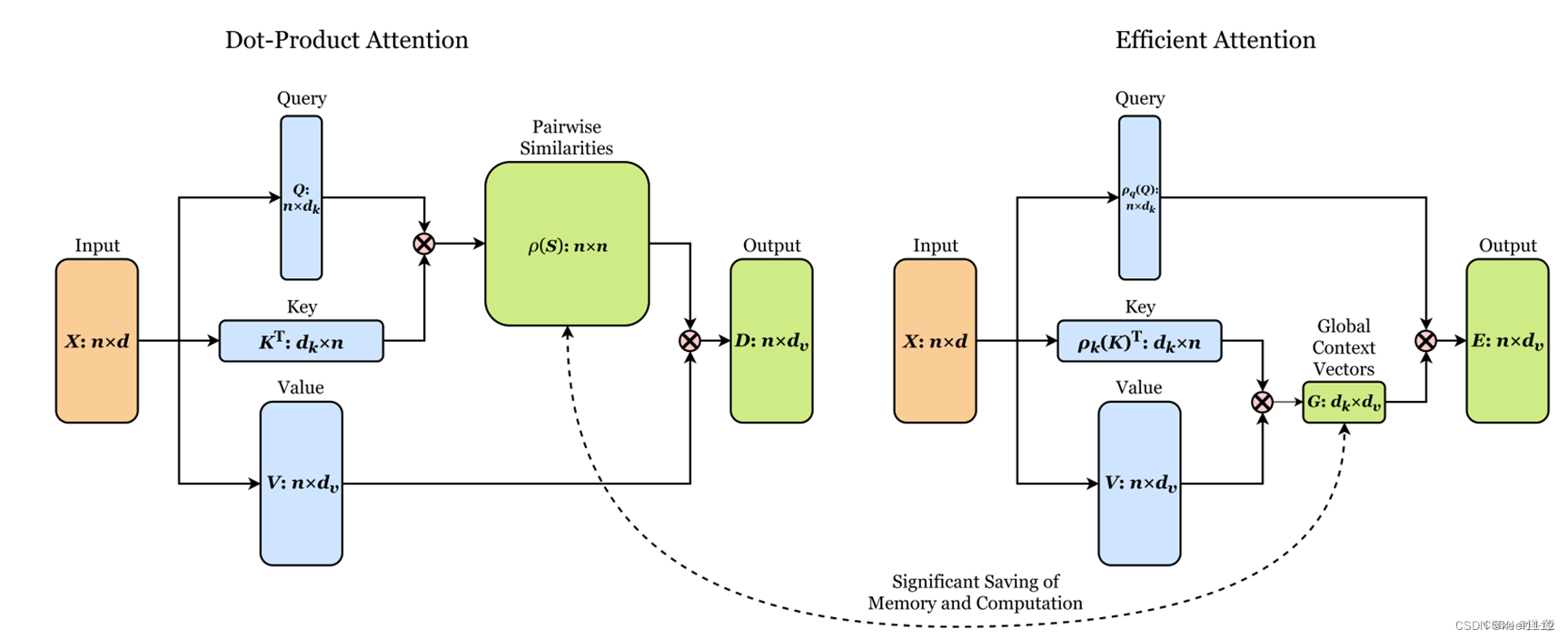
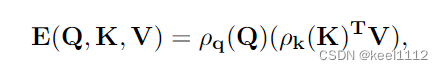
先对Q K进行归一化,然后将K与V相乘,再与Q相乘。降低了计算复杂度。

















 4488
4488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









