







一.文章思想
通过融合网络层中的相机数据和投影稀疏雷达数据来增强当前的2D目标检测网络。所提出的CameraRadarFusionNet(CRF-Net)自动学习传感器数据融合在哪个级别对检测结果最有利。此外,我们还介绍了BlackIn,这是一种受dropout启发的培训策略,它将学习重点放在特定传感器类型也就是雷达上,通过同时停用相机图像数据的所有输入神经元,用于随机训练步骤。网络更加依赖雷达数据。目标是让网络了解稀疏雷达数据的信息价值。
借鉴了:
a)将雷达数据投影到地面,也就是垂直于图像的平面;
b)3d激光雷达目标检测的将非结构化激光点云转化为规则网格的思想;
c)网络可以在网络中学习优化网络的深度;
二.网络结构
1.主干部分为VGG与FPN:
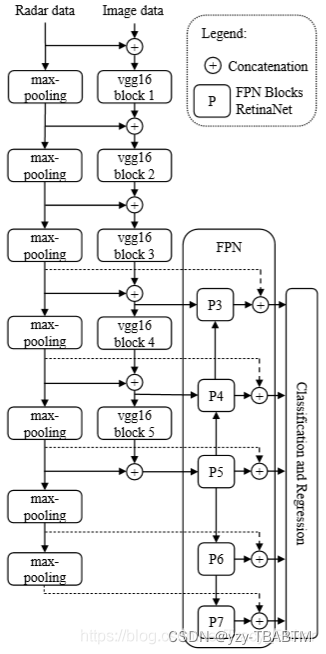
FPN:
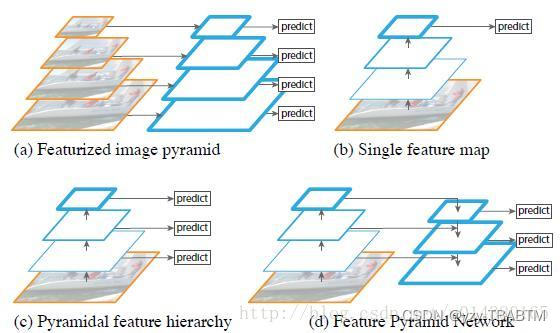
解释一下FPN:
利用FPN构建Faster R-CNN检测器步骤
首先,选择一张需要处理的图片,然后对该图片进行预处理操作;
然后ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2817
2817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









