









常用损失函数
ITC (image-text contrasctive loss)
CLIP中采用的对比损失,最大化配对文本对的余弦相似度,最小化非配对文本对的余弦相似度,采用交叉熵损失实现
MLM (masked language modeling)
BERT中采用的掩码语言建模任务,也是对每一个[MASK]进行分类
MVM (masked visiual modeling)
对图像采用掩码进行自监督预训练
ITM(image-text matching)
二分类损失,预测输入的(图像-文本)对是配对的还是非配对的
CLIP(2021)
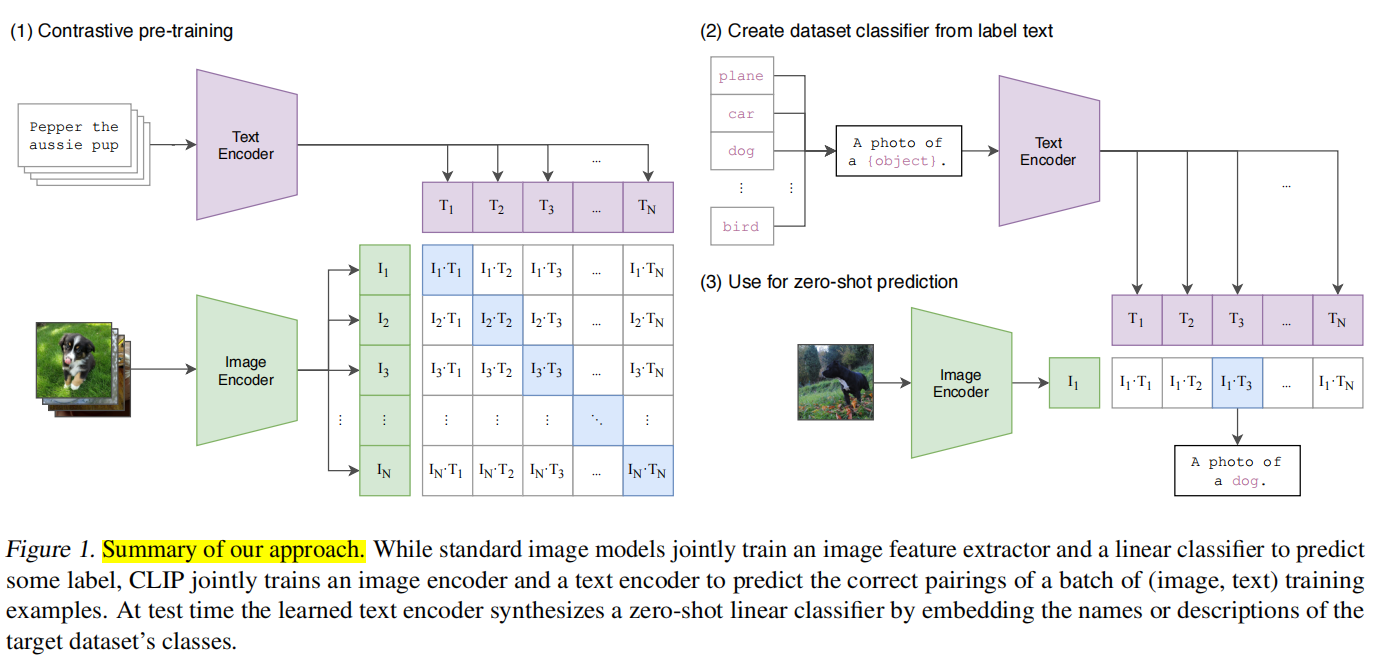

ViLT(2021)
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision

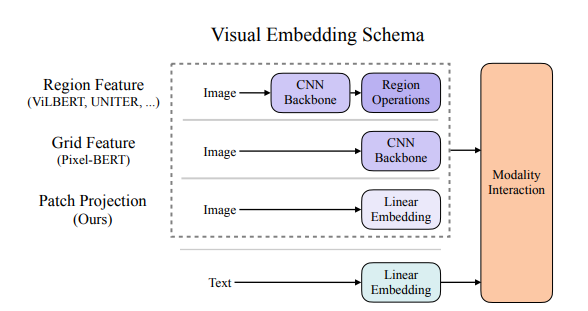
首次提出,在图像编码器中不需要采用目标检测器,直接采用图像的patch embedding。
但只采用图像的embedding导致图像编码器网络容量较小,因此该方法的性能不是太高
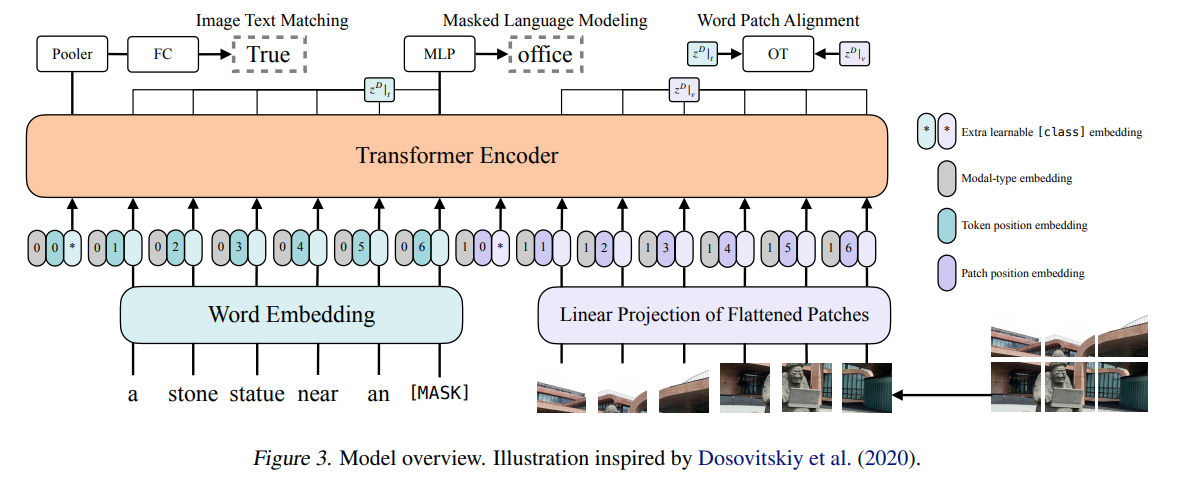
整体架构:将图像的patch embedding和word embedding拼接起来,一起输入encoder中。
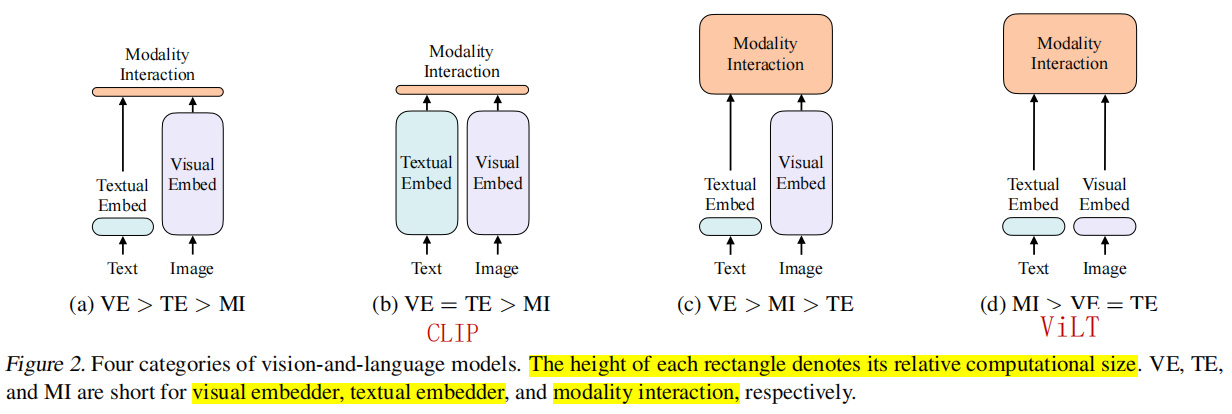
 根据作者总结的多模态网络结构,总结出最优网络结构应该是:
根据作者总结的多模态网络结构,总结出最优网络结构应该是:
(1)图像编码器网络容量大于文本编码器,
(2)多模态交互模块应该复杂一点,不只是采用对比损失ITC。
ALBEF(2021)
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation

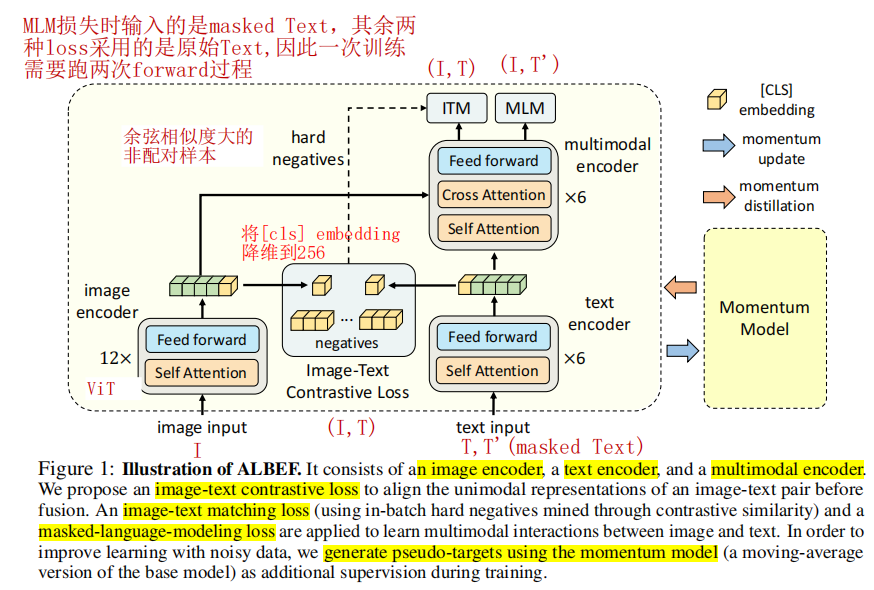
主要由三大部分组成
-
Image Encoder:作者采用 12 层的 ViT-B/16,用于从图像中提取 image embedding。
-
Text Encoder:作者采用 6 层的 Transformer encoder,从 Bert-Base 的前六层初始化,用于提取 text embedding。
-
Multimodal Encoder:也是 6 层的 Transformer encoder,从 Bert-Base 的后六层初始化,并在 Self Attention 后添加 Cross Attention,实现 image embedding 和 text embedding 的交互,提取多模态 embedding。从这里也可以看出,Albef 没有使用 decoder,所以不具备序列文本生成能力,如果需要执行 VQA 等任务,需要额外添加 decoder。
VLMO(2022)
Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts

作者指出当前的视觉-语言多模态模型可以分成2种类型
- 使用两个dual encoder来分别编码图像和文本,然后使用余弦相似度或者线性投影层来建模图像和文本两种模态之间的交互。这种方式优点是对于视觉-文本检索任务非常适合,因为可以提前将大量图像或者文件的编码计算出来并存储下来,应用时只需要计算余弦相似度即可。但缺点是模态之间交互太简单,因此在视觉推理和视觉问答等复杂任务上性能一般。
- 使用带有cross-attention的deep fusion encoder来建模图像和文本两种模态之间的交互。Image-text matching, masked language modeling, word-region/patch alignment, masked region classification and feature regression are widely used to train fusion-encoder-based models. 这种方式在视觉-语言理解任务上性能较好,但是应用于检索任务时推理速度很慢,因为需要对所有的图文对进行joint encoding。
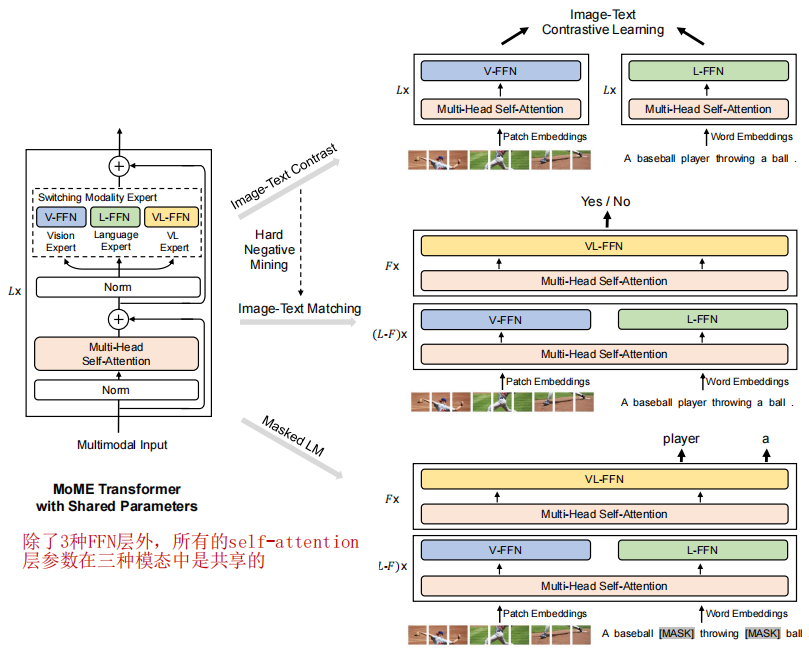
因此作者提出针对不同的模态,采用不同的expert的网络结构,具体做法如下图:不同模态采用不同的FFN层,共享self-attention层。这样一个网络结构同时适合图文检索和图文推理两种任务。
也是采用三种预训练任务。
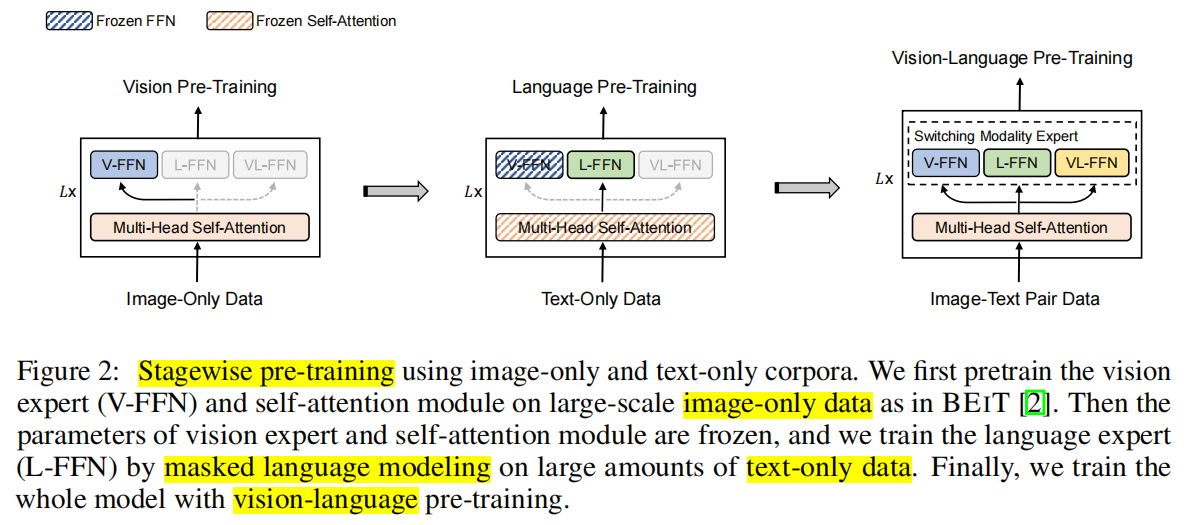
作者提出的分阶段预训练策略
- 使用图像数据和BEiT中训练方法,预训练V-FFN和自注意力层
- 冻结V-FFN和自注意力层,使用文本数据和MLM任务训练L-FFN
- 采用图像-文本数据,训练整个模型网络。
注意:先训文本,再训图像,效果好像不好
 作者挖的坑自己后面都填了
作者挖的坑自己后面都填了
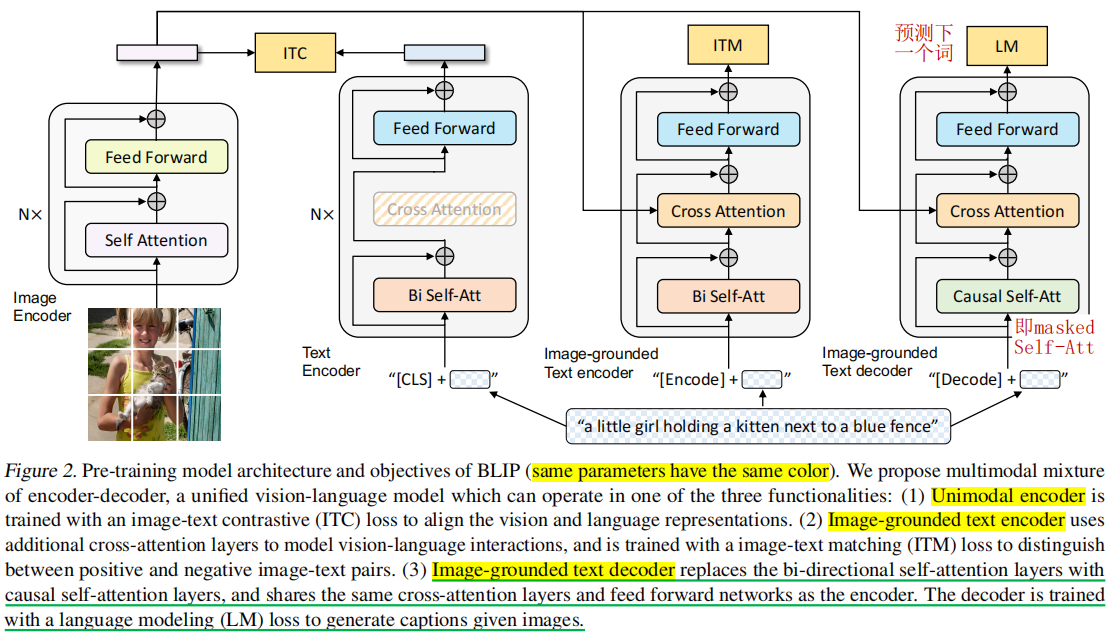
BLIP(2022)
- Text Encoder:用ITC损失训练,比较常规(采用[CLS])
- Image-grounded Text Encoder:用ITM训练,也比较常规(采用[Encoder], 算ITM时也和ALBEF一样用到了ITC计算出的困难负样本)
- Image-grounded Text Decoder:用标准语言建模任务LM训练解码器,这样网络就可以适用于文本生成任务(如image caption)。只替换了self-attention层,cross-attention和FFN层参数是共享的。是主要创新点。采用[Decoder])
训练一次,图像只需要前向一次,但文本需要前向三次,因为采用三种不同的网络结构,因此训练比较费时,也比较难训练
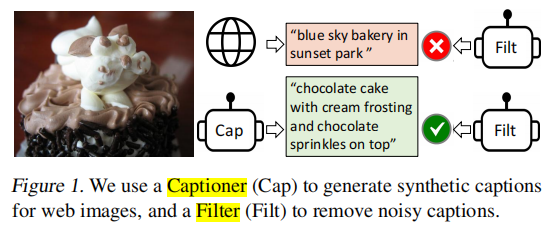
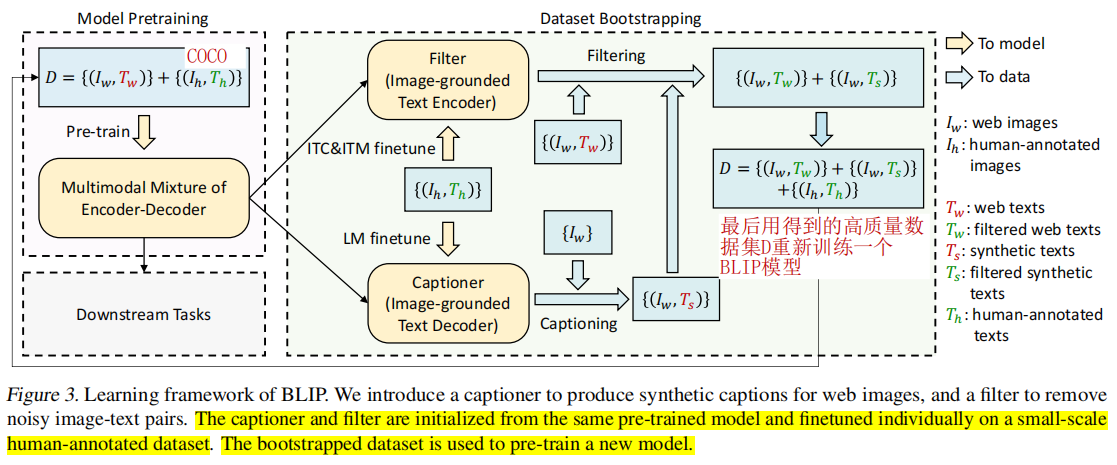
提出一种新的数据采样方法,用于从含有噪声的图像-文本对数据中学习:
- 先用原始数据训练一个BLIP模型,然后分别用不同的小量人类标注数据集微调BLIP得到captioner和filter。
- 采用captioner(Image-grounded Text Decoder),对图像生成一个合成的描述;
- 采用过滤器filter(Image-grounded Text Encoder),过滤掉质量低的captioner生成的合成描述或者爬取的原始网页上的描述
- 最后用高质量的最新数据集,重新训练一个BLIP模型
CoCa(2022)
CoCa: Contrastive Captioners are Image-Text Foundation Models

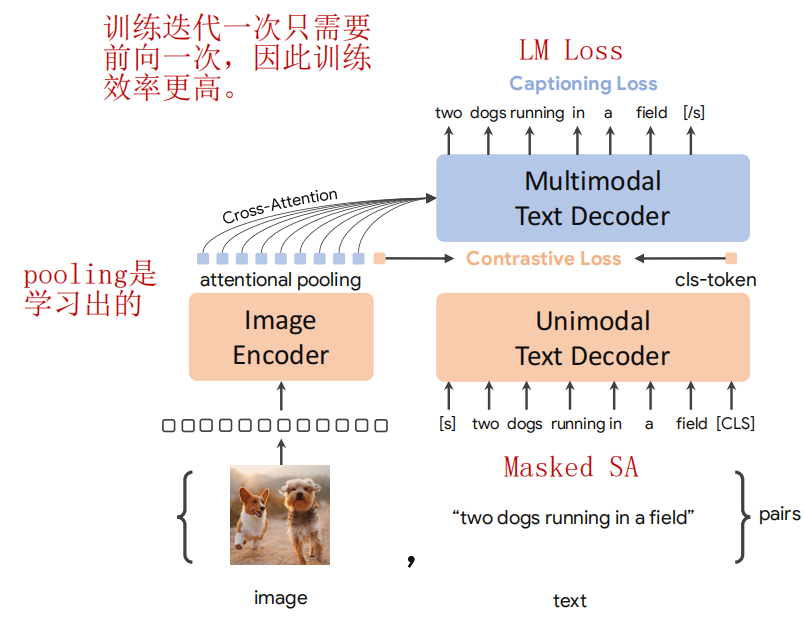
 CoCa的网络结构和ALBEF非常相似,但是更加简单,训练效率更高(ALBEF在文本采用的是编码器,CoCa采用解码器,因此可以不做适配修改直接生成文字)
CoCa的网络结构和ALBEF非常相似,但是更加简单,训练效率更高(ALBEF在文本采用的是编码器,CoCa采用解码器,因此可以不做适配修改直接生成文字)
只采用图像-文本对数据进行训练

BEiTv3(2022)
Image as a Foreign Language_BEiT Pretraining for All Vision and Vision-Language Tasks

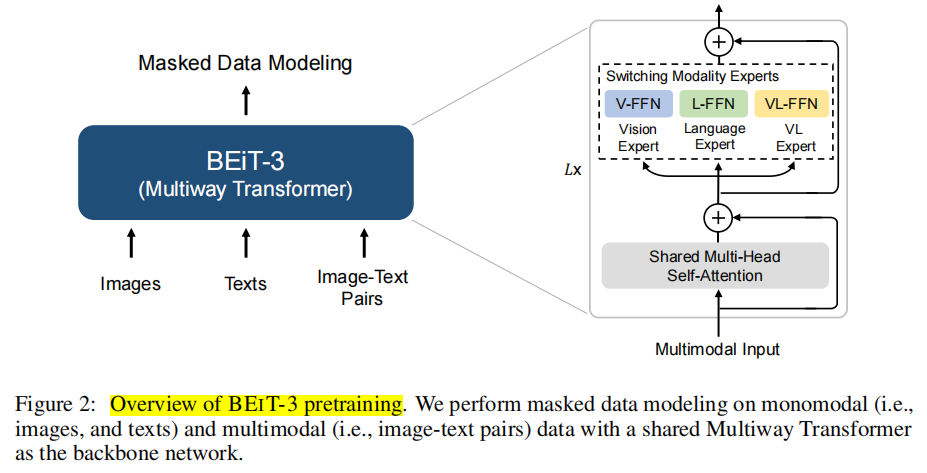
核心思想:把图像也看成语言,patch embedding之后就是tokens,和语言没有区别。这样训练任务都可以用masked data modeling来做了,不再需要ITC, ITM等图像文本对损失了。采用了统一的Multiway Transformers网络架构,可同时适用于图像和图像-文本两种任务

网络整体架构如下:each layer contains a vision expert and a language expert. Moreover, the top three layers have vision-language experts designed for fusion encoders. Refer to Figure 3 (a)(b)(c) for more detailed modeling layouts.
适用于多种视觉和视觉语言多模态下游任务 :
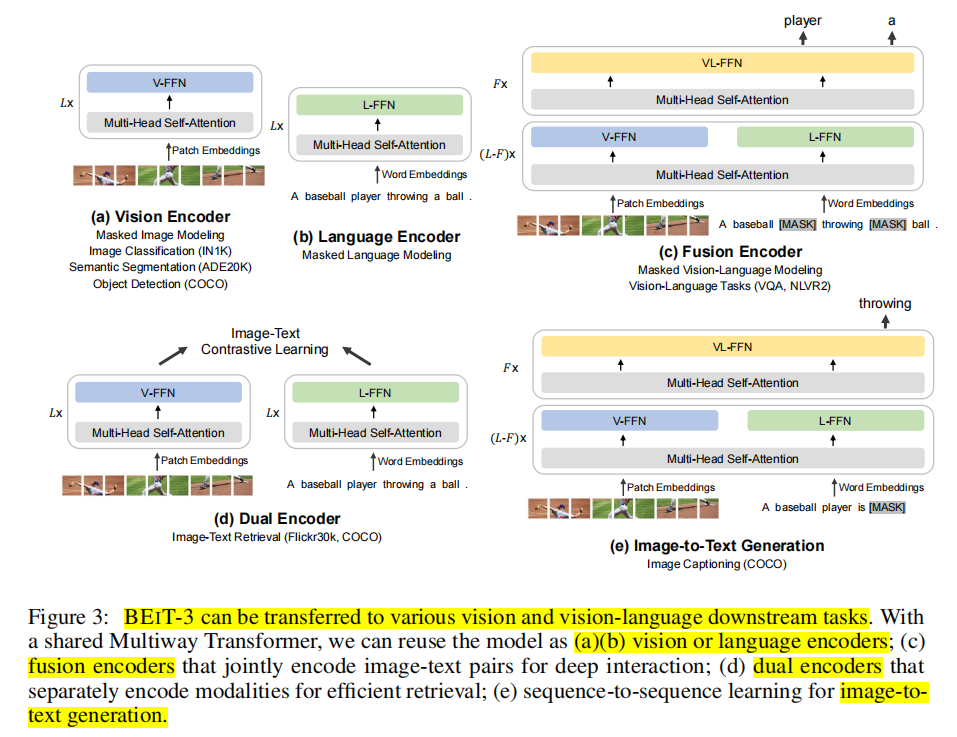
预训练任务采用masked data modeling,其中图像采用BEiTv2中的tokenizer, 并masked掉40%的patch block。
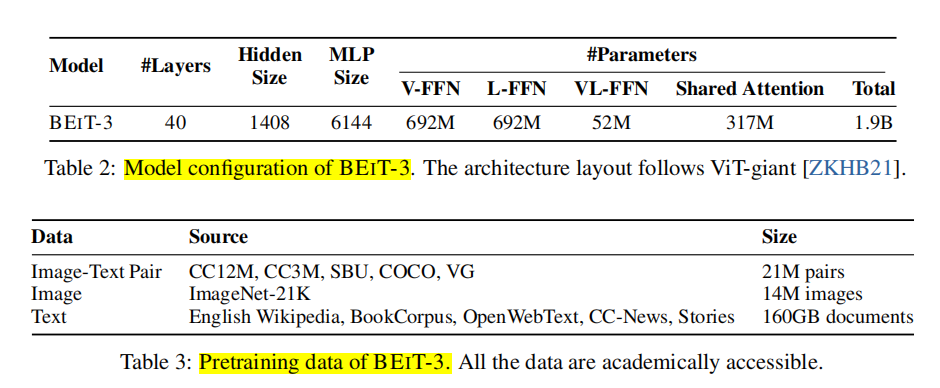
网络总参数量1.9B。预训练数据采用图像,文本,图像文本对三种
 将BeiTv3应用于 Image Captioning做法:设计了特殊的self-attention mask。即在图像token中注意力是双向的,但在文本token中注意力只能看到左侧的。推理的时候以autoregressive方式每次生成一个token。
将BeiTv3应用于 Image Captioning做法:设计了特殊的self-attention mask。即在图像token中注意力是双向的,但在文本token中注意力只能看到左侧的。推理的时候以autoregressive方式每次生成一个token。
将BeiTv3应用于目标检测和实例分割下游任务的方法:将BeiTv3作为backbone,采用和ViTDet一样的做法,包括特征金字塔和window attention,推理时候采用Soft-NMS。最终在COCO测试集上取得了63.7 box AP和54.8 mask AP
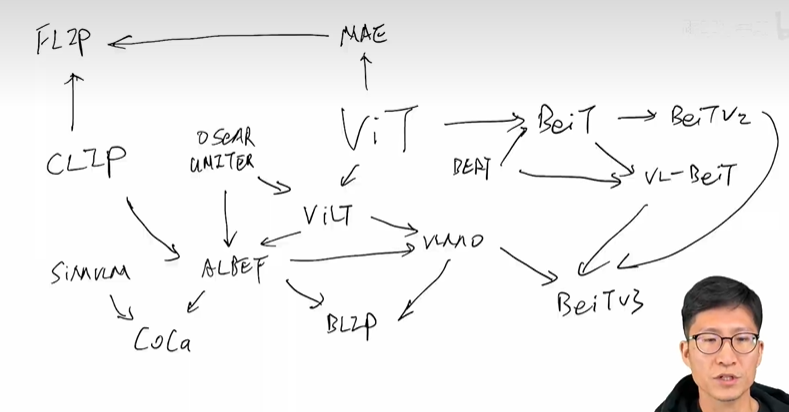
总结:这些算法之间的关系















 1368
1368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









