






目录
1.1 系统的概述
基于康奈尔电影语料库的Seq2Seq模型聊天机器人是一种利用自然语言处理技术实现的对话系统,其概述如下:
康奈尔电影语料库
• 数据规模与特点:康奈尔电影语料库(Cornell Movie-Dialogs Corpus)由康奈尔大学创建,包含超过22万条对话,涵盖617部电影。这些对话不仅数量庞大,而且内容丰富多样,涉及多种情境和角色互动。数据集的结构化设计使得对话序列和独立台词之间的关联清晰,便于模型理解和生成连贯的对话。
Seq2Seq模型
• 基本原理:Seq2Seq模型由编码器和解码器组成。编码器将输入序列(如用户的对话)转换为一个固定长度的向量表示,解码器则根据这个向量生成输出序列(如机器人的回复)。这种结构使得Seq2Seq能够处理长度可变的输入和输出序列,非常适合对话生成任务。
聊天机器人的应用
• 多轮对话管理:利用康奈尔电影语料库中的丰富对话数据,Seq2Seq模型可以学习到不同情境下的对话模式,实现多轮对话管理。
• 情感识别与生成:电影对话中包含丰富的情感表达,使得聊天机器人能够更好地理解和生成带有情感色彩的对话。
技术挑战与优化
• 数据预处理:电影对话中常包含非标准语言和俚语,这对模型的理解和生成提出了更高的要求。需要进行有效的数据清洗和格式化,以确保数据的质量和适用性。
• 模型优化:为了提高对话的自然度和连贯性,可以通过调整模型的超参数、引入强化学习等技术进行优化。
综上所述,基于康奈尔电影语料库的Seq2Seq模型聊天机器人能够利用丰富的电影对话数据和先进的自然语言处理技术,实现自然、连贯的对话生成,具有广泛的应用前景和研究价值.
1.2需求分析
1.2.1功能需求
• 自然语言理解:能够准确理解用户的输入意图和语义信息,包括识别关键词、理解上下文和语义关系等。
• 对话生成:根据理解的用户意图,生成自然、连贯且相关的回复文本。需要能够处理多种对话场景和话题。
• 多轮对话管理:支持多轮对话,能够根据对话历史信息和上下文状态,保持对话的连贯性和一致性。
• 个性化服务:根据不同用户的偏好和需求,提供个性化的对话内容和风格,如根据用户的历史行为和喜好推荐相关话题。
1.2.2 技术需求
• 数据需求:需要大量的高质量对话数据进行模型训练,数据应涵盖多种场景和话题。
• 模型优化:引入注意力机制、强化学习等技术对Seq2Seq模型进行优化,提高生成文本的质量和创新性。
• 集成能力:能够与其他系统或平台进行集成,如CRM系统、电商平台等,以实现更广泛的应用。
1.3系统开发环境
编程语言
- 常使用Python,因其有大量用于深度学习和自然语言处理的库。
深度学习框架
- TensorFlow:功能强大,适用于大规模数据训练,有很好的可视化工具,如TensorBoard,来监控模型训练过程。
- PyTorch:简洁灵活,动态计算图使调试更方便,在学术研究和快速实验中应用广泛。
自然语言处理库
- NLTK(Natural Language Toolkit):提供多种语料库和工具,像分词、词性标注等基本操作都很方便。
- spaCy:高效处理文本,能快速进行实体识别、句法分析等复杂任务。
开发工具
- Jupyter Notebook或JupyterLab:方便代码编写、运行以及结果展示,在实验阶段可以快速看到每一步的输出,便于调整代码。
- IDE(如PyCharm):如果是进行大型项目开发,使用专业IDE可以更好地管理代码结构、进行版本控制等。
2.1 准备工作
首先要开始使用,必须下载电影对话语料库 zip 文件。
# and put in a ``data/`` directory under the current directory.## After that, let’s import some necessities.#
import torchfrom torch.jit import script, traceimport torch.nn as nnfrom torch import optimimport torch.nn.functional as Fimport csvimport randomimport reimport osimport unicodedataimport codecsfrom io import openimport itertoolsimport mathimport json
USE_CUDA = torch.cuda.is_available()device = torch.device("cuda" if USE_CUDA else "cpu")//决定路径
2.2 加载和数据预处理
下一步是重新格式化我们的数据文件,并将数据加载到我们可以处理的结构中。下一步是重新格式化我们的数据文件,并将数据加载到我们可以处理的结构中。的康奈尔电影对话语料库是电影角色对话的丰富数据集10,292 对电影角色之间有 220,579 次对话交流来自 617 部电影的 9,035 个角色304,713 个总的语句这个数据集很大很多样化,语言形式、时间段、情感等都有很大的差异。
我们希望这种多样性能让我们的模型对各种形式的输入和查询具有鲁棒性。
首先,我们将查看数据文件中的几行,以查看原始格式。

为方便起见,我们将创建一个格式良好的数据文件,其中每行包含一个制表符分隔的查询句和响应句对。
以下函数有助于解析原始的 utterances.jsonl 数据文件。
- loadLinesAndConversations 将文件的每一行拆分为包含以下字段的行字典:lineID、characterID 和文本,然后将它们分组为包含以下字段的对话:conversationID、movieID 和行。
- extractSentencePairs 从对话中提取句子对
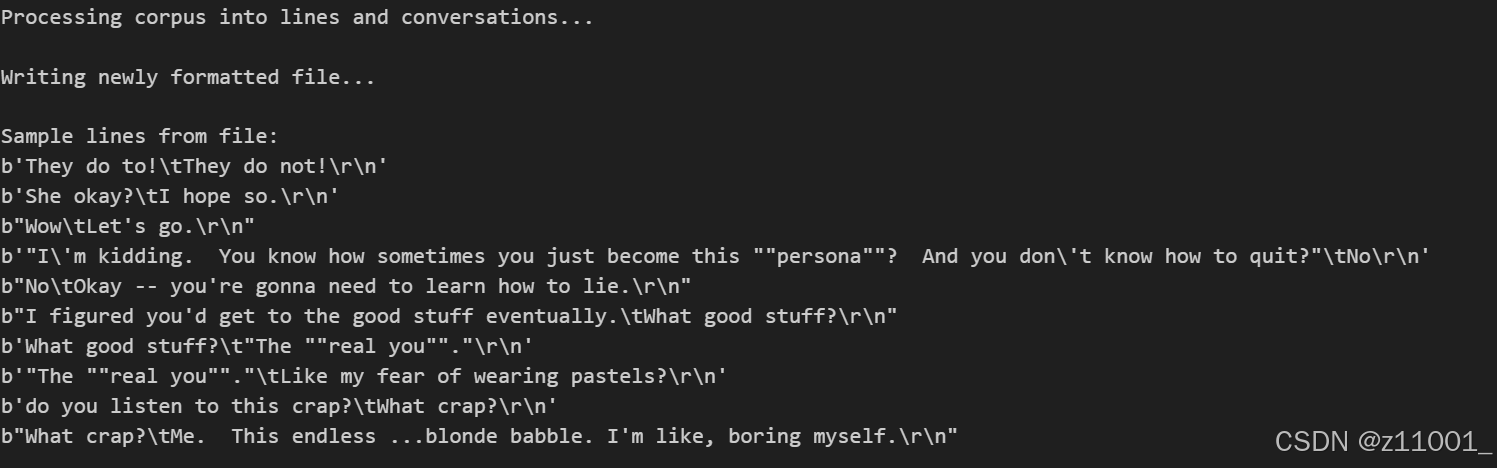
2.3加载和裁剪数据
我们的下一个任务是创建一个词汇表并将查询/响应句子对加载到内存中。请注意,我们正在处理单词序列,这些序列没有隐式映射到离散的数值空间。因此,我们必须通过将数据集中的每个唯一单词映射到一个索引值来创建一个映射。为此,我们定义了一个 Voc 类,它保留从单词到索引的映射、从索引到单词的反向映射、每个单词的计数和总单词计数。该类提供了用于将单词添加到词汇表(addWord)、将句子中的所有单词添加到词汇表(addSentence)和修剪不常出现的单词(trim)的方法。稍后将详细介绍修剪。裁剪完成后,现在我们可以组装我们的词汇表和查询/响应句子对。在我们准备使用这些数据之前,我们必须进行一些预处理。
首先,我们必须使用 unicodeToAscii 将 Unicode 字符串转换为 ASCII 字符串。接下来,我们应该将所有字母转换为小写并修剪所有非字母字符,除了基本标点符号(normalizeString)。最后,为了帮助训练收敛,我们将过滤掉长度大于 MAX_LENGTH 阈值的句子(filterPairs)
另一个有助于在训练期间更快收敛的策略是从我们的词汇表中修剪很少使用的单词。减少特征空间也会降低模型必须学习近似的函数的难度。我们将通过一个两步过程来实现这一点。使用 voc.trim 函数修剪使用次数低于 MIN_COUNT 阈值的单词。过滤掉包含已修剪单词的词对。
虽然我们已经付出了很多努力将我们的数据准备和处理成一个不错的词汇表对象和句子对列表,但我们的模型最终将期望数值火炬张量作为输入。在seq2seq 翻译教程中可以找到一种准备处理后的数据的方法。在该教程中,我们使用大小为 1 的批量,这意味着我们所要做的就是将句子对中的单词转换为词汇表中对应的索引,然后将它们提供给模型。
但是,如果您有兴趣加速训练或想要利用 GPU 并行化功能,则需要使用小批量进行训练。
使用小批量还意味着我们必须注意批量中句子长度的变化。为了容纳批量中不同大小的句子,我们将使我们的批量输入张量形状为(max_length, batch_size),其中短于max_length的句子在EOS_token之后进行零填充。
如果我们只是通过将单词转换为它们的索引(indexesFromSentence)并将英语句子转换为张量并进行零填充,我们的张量将具有(batch_size, max_length) 的形状,并且索引第一维将返回所有时间步长的完整序列。但是,我们需要能够按时间索引我们的批量,并在批量中的所有序列中索引。因此,我们将输入批量的形状转置为(max_length, batch_size),以便跨第一维索引返回跨批量中所有句子的时间步长。我们在 zeroPadding 函数中隐式地处理这种转置。

inputVar 函数处理将句子转换为张量,最终创建一个正确形状的零填充张量的过程。它还返回一个包含批量中每个序列的lengths 张量的张量,该张量将在稍后传递给我们的解码器。
outputVar 函数执行类似于 inputVar 的功能,但它不返回 lengths 张量,而是返回一个二进制掩码张量和最大目标句子长度。二进制掩码张量与输出目标张量具有相同的形状,但每个元素都是PAD_token 的元素为 0,其他元素为 1。
batch2TrainData 只需获取一堆词对并使用上述函数返回输入和目标张量即可。

4.1 Seq2Seq 模型
我们对话机器人的核心是一个序列到序列 (seq2seq) 模型。seq2seq 模型的目标是使用固定大小的模型,将可变长度序列作为输入,并返回可变长度序列作为输出。
Sutskever 等人发现通过使用两个独立的循环神经网络,我们可以完成这项任务。一个 RNN 充当编码器,将可变长度输入序列编码为固定长度的上下文向量。理论上,这个上下文向量(RNN 的最后一层隐藏层)将包含有关输入到机器人的查询句子的语义信息。第二个 RNN 是一个解码器,它接受一个输入词和上下文向量,并返回对序列中下一个词的猜测,以及在下次迭代中使用的隐藏状态。

4.2编码器
编码器 RNN 在每次时间步长上依次遍历输入句子中的每个标记(例如单词),在每次时间步长上输出一个“输出”向量和一个“隐藏状态”向量。隐藏状态向量随后被传递到下一个时间步长,而输出向量被记录下来。编码器将它在序列中的每个点上看到的上下文转换为高维空间中的一组点,解码器将使用这些点为给定的任务生成有意义的输出。
我们编码器的核心是一个多层门控循环单元,由Cho 等人于 2014 年发明。我们将使用 GRU 的双向变体,这意味着实际上存在两个独立的 RNN:一个以正常顺序接收输入序列,另一个以相反顺序接收输入序列。每个网络的输出在每个时间步长上求和。使用双向 GRU 将使我们能够编码过去和未来的上下文。
4.3双向 RNN
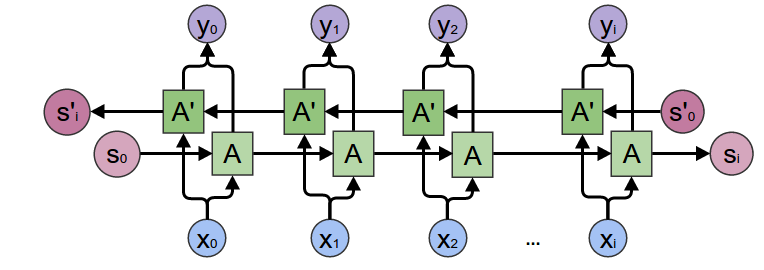
请注意,embedding 层用于在任意大小的特征空间中编码我们的词索引。对于我们的模型,该层将每个单词映射到大小为hidden_size 的特征空间。经过训练后,这些值应该编码具有相似含义的单词之间的语义相似性。
最后,如果将填充的序列批次传递给 RNN 模块,我们必须分别使用 nn.utils.rnn.pack_padded_sequence 和 nn.utils.rnn.pad_packed_sequence 在 RNN 传递周围打包和解包填充。
4.4计算图
输入
input_seq:输入句子的批次;形状=(max_length, batch_size)
input_lengths:与批次中每个句子相对应的句子长度列表;形状=(batch_size)
hidden:隐藏状态;形状=(n_layers x num_directions, batch_size, hidden_size)
输出
outputs:来自 GRU 的最后一层隐藏层的输出特征(双向输出的总和);形状=(max_length, batch_size, hidden_size)
hidden:来自 GRU 的更新后的隐藏状态;形状=(n_layers x num_directions, batch_size, hidden_size)
4.5解码器
解码器 RNN 以逐个标记的方式生成响应句子。它使用编码器的上下文向量和内部隐藏状态来生成序列中的下一个词。它会继续生成词,直到输出一个EOS_token,表示句子的结束。一个香草 seq2seq 解码器的常见问题是,如果我们仅仅依靠上下文向量来编码整个输入序列的含义,我们很可能会丢失信息。这在处理长输入序列时尤其如此,极大地限制了我们解码器的能力。
为了解决这个问题,Bahdanau 等人创建了一个“注意力机制”,允许解码器关注输入序列的某些部分,而不是在每一步都使用整个固定上下文。
在高层次上,注意力是使用解码器的当前隐藏状态和编码器的输出计算的。输出的注意力权重与输入序列具有相同的形状,允许我们将其乘以编码器输出,得到一个加权和,它指示要关注的编码器输出的哪些部分。Sean Robertson 的图很好地描述了这一点

Luong 等人在 Bahdanau 等人的基础上进行了改进,创建了“全局注意力”。关键的区别在于,使用“全局注意力”,我们考虑了编码器所有隐藏状态,而 Bahdanau 等人的“局部注意力”只考虑了当前时间步的编码器隐藏状态。另一个区别是,使用“全局注意力”,我们只使用当前时间步的解码器隐藏状态来计算注意力权重或能量。Bahdanau 等人的注意力计算需要了解前一时间步的解码器状态。此外,Luong 等人还提供了各种方法来计算编码器输出和解码器输出之间的注意力能量,这些方法被称为“得分函数”
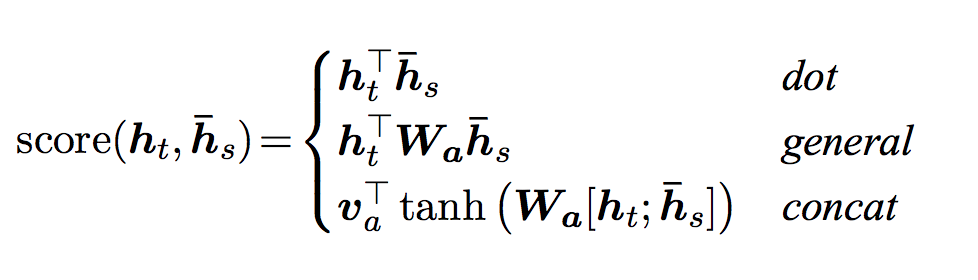
其中 ℎ�ht = 当前目标解码器状态,ℎˉ�hˉs = 所有编码器状态。
总的来说,全局注意力机制可以用下图概括。注意,我们将“注意力层”实现为一个单独的 nn.Module,称为 Attn。此模块的输出是一个形状为(batch_size, 1, max_length) 的 softmax 归一化权重张量。
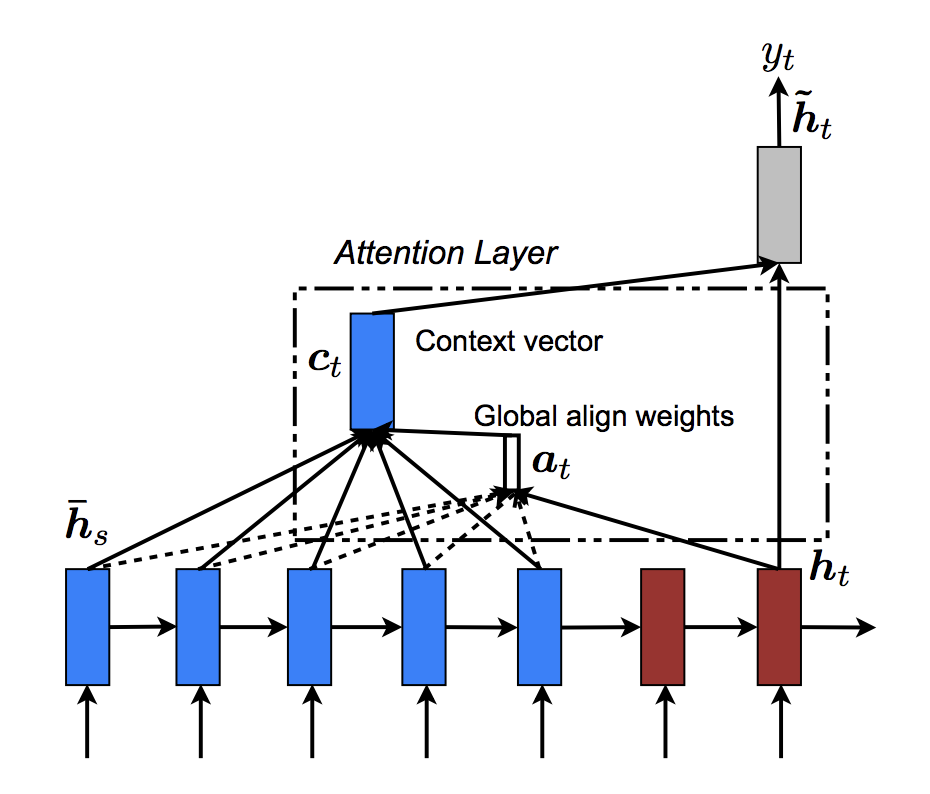
现在我们已经定义了注意力子模块,我们可以实现实际的解码器模型。对于解码器,我们将手动一次一步地馈送批处理。这意味着我们的嵌入词张量和 GRU 输出都将具有形状(1, batch_size, hidden_size)。
4.6计算图
- 获取当前输入词的嵌入。
- 通过单向 GRU 进行前向传播。
- 从 (2) 中的当前 GRU 输出计算注意力权重。
- 将注意力权重乘以编码器输出以获得新的“加权和”上下文向量。
- 使用 Luong 等式 5 将加权上下文向量和 GRU 输出连接起来。
- 使用 Luong 等式 6 预测下一个词(不使用 softmax)。
- 返回输出和最终隐藏状态。
输入
input_step:输入序列批处理的一次时间步(一个词);形状=(1, batch_size)
last_hidden:GRU 的最终隐藏层;形状=(n_layers x num_directions, batch_size, hidden_size)
encoder_outputs:编码器模型的输出;形状=(max_length, batch_size, hidden_size)
输出
output:softmax 归一化张量,给出每个词在解码序列中成为正确下一个词的概率;形状=(batch_size, voc.num_words)
hidden:GRU 的最终隐藏状态;形状=(n_layers x num_directions, batch_size, hidden_size)
5.1掩蔽损失
由于我们正在处理填充序列的批次,因此我们不能在计算损失时简单地考虑张量的所有元素。我们定义 maskNLLLoss 来根据解码器的输出张量、目标张量和描述目标张量填充的二进制掩码张量来计算我们的损失。此损失函数计算与掩码张量中为1 的元素相对应的平均负对数似然。
def maskNLLLoss(inp, target, mask):
nTotal = mask.sum()
crossEntropy = -torch.log(torch.gather(inp, 1, target.view(-1, 1)).squeeze(1))
loss = crossEntropy.masked_select(mask).mean()
loss = loss.to(device)
return loss, nTotal.item()
5.2单个训练迭代
该 train 函数包含单个训练迭代(一批输入)的算法。
我们将使用一些巧妙的技巧来帮助收敛
第一个技巧是使用教师强迫。这意味着,以由 teacher_forcing_ratio 设置的某个概率,我们使用当前目标词作为解码器的下一个输入,而不是使用解码器的当前猜测。此技术充当解码器的训练轮,有助于更有效地训练。但是,教师强迫会导致推理期间模型不稳定,因为解码器可能没有足够的机会在训练期间真正构建自己的输出序列。因此,我们必须注意如何设置 teacher_forcing_ratio,不要被快速收敛所迷惑。
我们实现的第二个技巧是梯度裁剪。这是一种常用的技术,用于对抗“梯度爆炸”问题。本质上,通过将梯度裁剪或阈值设置为最大值,我们防止梯度呈指数增长,从而导致溢出 (NaN) 或超过成本函数中的陡峭悬崖。
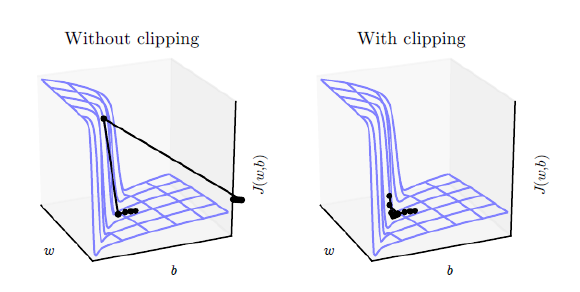
5.3操作序列
将整个输入批次前向传播到编码器。
将解码器输入初始化为 SOS_token,并将隐藏状态初始化为编码器的最终隐藏状态。
将输入批次序列一次一步地前向传播到解码器。
如果教师强迫:将下一个解码器输入设置为当前目标;否则:将下一个解码器输入设置为当前解码器输出。
计算并累积损失。
执行反向传播。
裁剪梯度。
更新编码器和解码器模型参数。
注意:PyTorch 的 RNN 模块 (RNN、LSTM、GRU) 可以像任何其他非循环层一样使用,只需将整个输入序列(或序列批次)传递给它们即可。我们在 encoder 中像这样使用 GRU 层。现实情况是在幕后,有一个迭代过程循环遍历每个时间步,计算隐藏状态。或者,您可以一次一步地运行这些模块。在这种情况下,我们必须像必须为 decoder 模型所做的那样,在训练过程中手动循环遍历序列。只要您保持对这些模块的正确概念模型,实现顺序模型就可以非常简单。
5.4训练迭代
现在是时候将完整的训练过程与数据联系起来。该 trainIters 函数负责运行 n_iterations 次训练,前提是传递了模型、优化器、数据等。此函数相当不言自明,因为我们在 train 函数中完成了繁重的工作。
需要注意的一点是,当我们保存模型时,我们会保存一个包含编码器和解码器 state_dicts(参数)、优化器 state_dicts、损失、迭代等信息的 tarball。以这种方式保存模型将为我们提供检查点的最大灵活性。加载检查点后,我们将能够使用模型参数来运行推理,或者我们可以从停止的地方继续训练。
训练完模型后,我们希望能够自己与机器人交谈。首先,我们必须定义我们希望模型如何解码编码的输入。
6.1贪婪解码
贪婪解码是我们训练期间使用的解码方法,当我们不使用教师强迫时。换句话说,在每个时间步,我们只选择具有最高 softmax 值的 decoder_output 中的词。这种解码方法在单一时间步级别上是最优的。
为了促进贪婪解码操作,我们定义了一个 GreedySearchDecoder 类。运行时,此类的对象会接收形状为(input_seq length, 1) 的输入序列 (input_seq)、标量输入长度 (input_length) 张量和一个 max_length 来限制响应句子长度。输入句子使用以下计算图进行评估
6.2计算图
- 将输入前向传播到编码器模型。
- 准备编码器的最终隐藏层,作为解码器的第一个隐藏输入。
- 将解码器的第一个输入初始化为 SOS_token。
- 初始化张量以将解码后的词追加到其中。
- 迭代地一次解码一个词标记
1、通过解码器进行前向传播。
2、获取最可能的词标记及其 softmax 得分。
3、记录标记和得分。
4、准备当前标记作为下一个解码器输入。
6、返回词标记和得分的集合。
6.3评估我的文本
现在我们已经定义了解码方法,我们可以编写函数来评估字符串输入句子。该 evaluate 函数管理处理输入句子的底层过程。我们首先将句子格式化为具有batch_size==1 的词索引的输入批次。我们通过将句子的词转换为其对应的索引,并将维度转置来为我们的模型准备张量来实现这一点。我们还创建一个 lengths 张量,其中包含输入句子的长度。在本例中,lengths 是标量,因为我们一次只评估一个句子 (batch_size==1)。接下来,我们使用 GreedySearchDecoder 对象 (searcher) 获取解码后的响应句子张量。最后,我们将响应的索引转换为词并返回解码后的词列表。
evaluateInput 充当我们聊天机器人的用户界面。调用时,将出现一个输入文本字段,我们可以在其中输入查询句子。在输入查询句子并按下Enter 键后,我们的文本将以与训练数据相同的方式进行规范化,并最终馈送到 evaluate 函数以获取解码后的输出句子。我们循环此过程,这样我们就可以一直与我们的机器人聊天,直到我们输入“q”或“quit”。
最后,如果输入的句子包含不在词汇表中的单词,我们会通过打印错误消息并提示用户输入另一个句子来优雅地处理这种情况。
最后,是时候运行我们的模型了!无论我们是想训练还是测试聊天机器人模型,我们都必须初始化单个编码器和解码器模型。在下面的代码块中,我们设置了所需的配置,选择从头开始还是设置要加载的检查点,并构建和初始化模型。随意尝试不同的模型配置以优化性能。
# Configure modelsmodel_name = 'cb_model'attn_model = 'dot'#``attn_model = 'general'``#``attn_model = 'concat'``hidden_size = 500encoder_n_layers = 2decoder_n_layers = 2dropout = 0.1batch_size = 64
# Set checkpoint to load from; set to None if starting from scratchloadFilename = Nonecheckpoint_iter = 4000
7.1从检查点加载的示例代码
loadFilename = os.path.join(save_dir, model_name, corpus_name,
'{}-{}_{}'.format(encoder_n_layers, decoder_n_layers, hidden_size),
'{}_checkpoint.tar'.format(checkpoint_iter))
# Load model if a ``loadFilename`` is providedif loadFilename:
# If loading on same machine the model was trained on
checkpoint = torch.load(loadFilename)
# If loading a model trained on GPU to CPU
#checkpoint = torch.load(loadFilename, map_location=torch.device('cpu'))
encoder_sd = checkpoint['en']
decoder_sd = checkpoint['de']
encoder_optimizer_sd = checkpoint['en_opt']
decoder_optimizer_sd = checkpoint['de_opt']
embedding_sd = checkpoint['embedding']
voc.__dict__ = checkpoint['voc_dict']
print('Building encoder and decoder ...')# Initialize word embeddingsembedding = nn.Embedding(voc.num_words, hidden_size)if loadFilename:
embedding.load_state_dict(embedding_sd)# Initialize encoder & decoder modelsencoder = EncoderRNN(hidden_size, embedding, encoder_n_layers, dropout)decoder = LuongAttnDecoderRNN(attn_model, embedding, hidden_size, voc.num_words, decoder_n_layers, dropout)if loadFilename:
encoder.load_state_dict(encoder_sd)
decoder.load_state_dict(decoder_sd)# Use appropriate deviceencoder = encoder.to(device)decoder = decoder.to(device)print('Models built and ready to go!')

7.2运行训练
想要训练模型,首先,我们设置训练参数,然后初始化优化器,最后调用trainIters 函数来运行我们的训练迭代。
# Configure training/optimizationclip = 50.0teacher_forcing_ratio = 1.0learning_rate = 0.0001decoder_learning_ratio = 5.0n_iteration = 4000print_every = 1save_every = 500
# Ensure dropout layers are in train modeencoder.train()decoder.train()
# Initialize optimizersprint('Building optimizers ...')encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate * decoder_learning_ratio)if loadFilename:
encoder_optimizer.load_state_dict(encoder_optimizer_sd)
decoder_optimizer.load_state_dict(decoder_optimizer_sd)
# If you have CUDA, configure CUDA to callfor state in encoder_optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.cuda()
for state in decoder_optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.cuda()
# Run training iterationsprint("Starting Training!")trainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer,
embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size,
print_every, save_every, clip, corpus_name, loadFilename)
7.3 运行评估
要与你的模型聊天,请运行以下代码块。
# Set dropout layers to ``eval`` mode
encoder.eval()
decoder.eval()
# Initialize search module
searcher = GreedySearchDecoder(encoder, decoder)
# Begin chatting (uncomment and run the following line to begin)
# evaluateInput(encoder, decoder, searcher, voc)
7.4 运行结果
7.4.1 训练代码
import torch
from torch.jit import script, trace
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import csv
import random
import re
import os
import unicodedata
import codecs
from io import open
import itertools
import math
import json
USE_CUDA = torch.cuda.is_available()
device = torch.device("cuda" if USE_CUDA else "cpu")
corpus_name = "movie-corpus"
corpus = os.path.join("data", corpus_name)
def printLines(file, n=10):
with open(file, 'rb') as datafile:
lines = datafile.readlines()
for line in lines[:n]:
print(line)
printLines(os.path.join(corpus, "utterances.jsonl"))
def loadLinesAndConversations(fileName):
lines = {}
conversations = {}
with open(fileName, 'r', encoding='iso-8859-1') as f:
for line in f:
lineJson = json.loads(line)
# Extract fields for line object
lineObj = {}
lineObj["lineID"] = lineJson["id"]
lineObj["characterID"] = lineJson["speaker"]
lineObj["text"] = lineJson["text"]
lines[lineObj['lineID']] = lineObj
# Extract fields for conversation object
if lineJson["conversation_id"] not in conversations:
convObj = {}
convObj["conversationID"] = lineJson["conversation_id"]
convObj["movieID"] = lineJson["meta"]["movie_id"]
convObj["lines"] = [lineObj]
else:
convObj = conversations[lineJson["conversation_id"]]
convObj["lines"].insert(0, lineObj)
conversations[convObj["conversationID"]] = convObj
return lines, conversations
# Extracts pairs of sentences from conversations
def extractSentencePairs(conversations):
qa_pairs = []
for conversation in conversations.values():
# Iterate over all the lines of the conversation
for i in range(len(conversation["lines"]) - 1): # We ignore the last line (no answer for it)
inputLine = conversation["lines"][i]["text"].strip()
targetLine = conversation["lines"][i+1]["text"].strip()
# Filter wrong samples (if one of the lists is empty)
if inputLine and targetLine:
qa_pairs.append([inputLine, targetLine])
return qa_pairs
datafile = os.path.join(corpus, "formatted_movie_lines.txt")
delimiter = '\t'
# Unescape the delimiter
delimiter = str(codecs.decode(delimiter, "unicode_escape"))
# Initialize lines dict and conversations dict
lines = {}
conversations = {}
# Load lines and conversations
print("\nProcessing corpus into lines and conversations...")
lines, conversations = loadLinesAndConversations(os.path.join(corpus, "utterances.jsonl"))
# Write new csv file
print("\nWriting newly formatted file...")
with open(datafile, 'w', encoding='utf-8') as outputfile:
writer = csv.writer(outputfile, delimiter=delimiter, lineterminator='\n')
for pair in extractSentencePairs(conversations):
writer.writerow(pair)
# Print a sample of lines
print("\nSample lines from file:")
printLines(datafile)
# Default word tokens
PAD_token = 0 # Used for padding short sentences
SOS_token = 1 # Start-of-sentence token
EOS_token = 2 # End-of-sentence token
class Voc:
def __init__(self, name):
self.name = name
self.trimmed = False
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count SOS, EOS, PAD
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.num_words
self.word2count[word] = 1
self.index2word[self.num_words] = word
self.num_words += 1
else:
self.word2count[word] += 1
# Remove words below a certain count threshold
def trim(self, min_count):
if self.trimmed:
return
self.trimmed = True
keep_words = []
for k, v in self.word2count.items():
if v >= min_count:
keep_words.append(k)
print('keep_words {} / {} = {:.4f}'.format(
len(keep_words), len(self.word2index), len(keep_words) / len(self.word2index)
))
# Reinitialize dictionaries
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count default tokens
for word in keep_words:
self.addWord(word)
MAX_LENGTH = 10 # Maximum sentence length to consider
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
s = re.sub(r"\s+", r" ", s).strip()
return s
# Read query/response pairs and return a voc object
def readVocs(datafile, corpus_name):
print("Reading lines...")
# Read the file and split into lines
lines = open(datafile, encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
voc = Voc(corpus_name)
return voc, pairs
# Returns True if both sentences in a pair 'p' are under the MAX_LENGTH threshold
def filterPair(p):
# Input sequences need to preserve the last word for EOS token
return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH
# Filter pairs using the ``filterPair`` condition
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
# Using the functions defined above, return a populated voc object and pairs list
def loadPrepareData(corpus, corpus_name, datafile, save_dir):
print("Start preparing training data ...")
voc, pairs = readVocs(datafile, corpus_name)
print("Read {!s} sentence pairs".format(len(pairs)))
pairs = filterPairs(pairs)
print("Trimmed to {!s} sentence pairs".format(len(pairs)))
print("Counting words...")
for pair in pairs:
voc.addSentence(pair[0])
voc.addSentence(pair[1])
print("Counted words:", voc.num_words)
return voc, pairs
# Load/Assemble voc and pairs
save_dir = os.path.join("data", "save")
voc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)
# Print some pairs to validate
print("\npairs:")
for pair in pairs[:10]:
print(pair)
MIN_COUNT = 3 # Minimum word count threshold for trimming
def trimRareWords(voc, pairs, MIN_COUNT):
# Trim words used under the MIN_COUNT from the voc
voc.trim(MIN_COUNT)
# Filter out pairs with trimmed words
keep_pairs = []
for pair in pairs:
input_sentence = pair[0]
output_sentence = pair[1]
keep_input = True
keep_output = True
# Check input sentence
for word in input_sentence.split(' '):
if word not in voc.word2index:
keep_input = False
break
# Check output sentence
for word in output_sentence.split(' '):
if word not in voc.word2index:
keep_output = False
break
# Only keep pairs that do not contain trimmed word(s) in their input or output sentence
if keep_input and keep_output:
keep_pairs.append(pair)
print("Trimmed from {} pairs to {}, {:.4f} of total".format(len(pairs), len(keep_pairs), len(keep_pairs) / len(pairs)))
return keep_pairs
# Trim voc and pairs
pairs = trimRareWords(voc, pairs, MIN_COUNT)
def indexesFromSentence(voc, sentence):
return [voc.word2index[word] for word in sentence.split(' ')] + [EOS_token]
def zeroPadding(l, fillvalue=PAD_token):
return list(itertools.zip_longest(*l, fillvalue=fillvalue))
def binaryMatrix(l, value=PAD_token):
m = []
for i, seq in enumerate(l):
m.append([])
for token in seq:
if token == PAD_token:
m[i].append(0)
else:
m[i].append(1)
return m
# Returns padded input sequence tensor and lengths
def inputVar(l, voc):
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
padList = zeroPadding(indexes_batch)
padVar = torch.LongTensor(padList)
return padVar, lengths
# Returns padded target sequence tensor, padding mask, and max target length
def outputVar(l, voc):
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
max_target_len = max([len(indexes) for indexes in indexes_batch])
padList = zeroPadding(indexes_batch)
mask = binaryMatrix(padList)
mask = torch.BoolTensor(mask)
padVar = torch.LongTensor(padList)
return padVar, mask, max_target_len
# Returns all items for a given batch of pairs
def batch2TrainData(voc, pair_batch):
pair_batch.sort(key=lambda x: len(x[0].split(" ")), reverse=True)
input_batch, output_batch = [], []
for pair in pair_batch:
input_batch.append(pair[0])
output_batch.append(pair[1])
inp, lengths = inputVar(input_batch, voc)
output, mask, max_target_len = outputVar(output_batch, voc)
return inp, lengths, output, mask, max_target_len
# Example for validation
small_batch_size = 5
batches = batch2TrainData(voc, [random.choice(pairs) for _ in range(small_batch_size)])
input_variable, lengths, target_variable, mask, max_target_len = batches
print("input_variable:", input_variable)
print("lengths:", lengths)
print("target_variable:", target_variable)
print("mask:", mask)
print("max_target_len:", max_target_len)
# %%
class EncoderRNN(nn.Module):
def __init__(self, hidden_size, embedding, n_layers=1, dropout=0):
super(EncoderRNN, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embedding = embedding
# Initialize GRU; the input_size and hidden_size parameters are both set to 'hidden_size'
# because our input size is a word embedding with number of features == hidden_size
self.gru = nn.GRU(hidden_size, hidden_size, n_layers,
dropout=(0 if n_layers == 1 else dropout), bidirectional=True)
def forward(self, input_seq, input_lengths, hidden=None):
# Convert word indexes to embeddings
embedded = self.embedding(input_seq)
# Pack padded batch of sequences for RNN module
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
# Forward pass through GRU
outputs, hidden = self.gru(packed, hidden)
# Unpack padding
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)
# Sum bidirectional GRU outputs
outputs = outputs[:, :, :self.hidden_size] + outputs[:, : ,self.hidden_size:]
# Return output and final hidden state
return outputs, hidden
# %%
# Luong attention layer
class Attn(nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.FloatTensor(hidden_size))
def dot_score(self, hidden, encoder_output):
return torch.sum(hidden * encoder_output, dim=2)
def general_score(self, hidden, encoder_output):
energy = self.attn(encoder_output)
return torch.sum(hidden * energy, dim=2)
def concat_score(self, hidden, encoder_output):
energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1), encoder_output), 2)).tanh()
return torch.sum(self.v * energy, dim=2)
def forward(self, hidden, encoder_outputs):
# Calculate the attention weights (energies) based on the given method
if self.method == 'general':
attn_energies = self.general_score(hidden, encoder_outputs)
elif self.method == 'concat':
attn_energies = self.concat_score(hidden, encoder_outputs)
elif self.method == 'dot':
attn_energies = self.dot_score(hidden, encoder_outputs)
# Transpose max_length and batch_size dimensions
attn_energies = attn_energies.t()
# Return the softmax normalized probability scores (with added dimension)
return F.softmax(attn_energies, dim=1).unsqueeze(1)
class LuongAttnDecoderRNN(nn.Module):
def __init__(self, attn_model, embedding, hidden_size, output_size, n_layers=1, dropout=0.1):
super(LuongAttnDecoderRNN, self).__init__()
# Keep for reference
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout = dropout
# Define layers
self.embedding = embedding
self.embedding_dropout = nn.Dropout(dropout)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout))
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.attn = Attn(attn_model, hidden_size)
def forward(self, input_step, last_hidden, encoder_outputs):
# Note: we run this one step (word) at a time
# Get embedding of current input word
embedded = self.embedding(input_step)
embedded = self.embedding_dropout(embedded)
# Forward through unidirectional GRU
rnn_output, hidden = self.gru(embedded, last_hidden)
# Calculate attention weights from the current GRU output
attn_weights = self.attn(rnn_output, encoder_outputs)
# Multiply attention weights to encoder outputs to get new "weighted sum" context vector
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
# Concatenate weighted context vector and GRU output using Luong eq. 5
rnn_output = rnn_output.squeeze(0)
context = context.squeeze(1)
concat_input = torch.cat((rnn_output, context), 1)
concat_output = torch.tanh(self.concat(concat_input))
# Predict next word using Luong eq. 6
output = self.out(concat_output)
output = F.softmax(output, dim=1)
# Return output and final hidden state
return output, hidden
def maskNLLLoss(inp, target, mask):
nTotal = mask.sum()
crossEntropy = -torch.log(torch.gather(inp, 1, target.view(-1, 1)).squeeze(1))
loss = crossEntropy.masked_select(mask).mean()
loss = loss.to(device)
return loss, nTotal.item()
def train(input_variable, lengths, target_variable, mask, max_target_len, encoder, decoder, embedding,
encoder_optimizer, decoder_optimizer, batch_size, clip, max_length=MAX_LENGTH):
# Zero gradients
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# Set device options
input_variable = input_variable.to(device)
target_variable = target_variable.to(device)
mask = mask.to(device)
# Lengths for RNN packing should always be on the CPU
lengths = lengths.to("cpu")
# Initialize variables
loss = 0
print_losses = []
n_totals = 0
# Forward pass through encoder
encoder_outputs, encoder_hidden = encoder(input_variable, lengths)
# Create initial decoder input (start with SOS tokens for each sentence)
decoder_input = torch.LongTensor([[SOS_token for _ in range(batch_size)]])
decoder_input = decoder_input.to(device)
# Set initial decoder hidden state to the encoder's final hidden state
decoder_hidden = encoder_hidden[:decoder.n_layers]
# Determine if we are using teacher forcing this iteration
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
# Forward batch of sequences through decoder one time step at a time
if use_teacher_forcing:
for t in range(max_target_len):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
# Teacher forcing: next input is current target
decoder_input = target_variable[t].view(1, -1)
# Calculate and accumulate loss
mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])
loss += mask_loss
print_losses.append(mask_loss.item() * nTotal)
n_totals += nTotal
else:
for t in range(max_target_len):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
# No teacher forcing: next input is decoder's own current output
_, topi = decoder_output.topk(1)
decoder_input = torch.LongTensor([[topi[i][0] for i in range(batch_size)]])
decoder_input = decoder_input.to(device)
# Calculate and accumulate loss
mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])
loss += mask_loss
print_losses.append(mask_loss.item() * nTotal)
n_totals += nTotal
# Perform backpropagation
loss.backward()
# Clip gradients: gradients are modified in place
_ = nn.utils.clip_grad_norm_(encoder.parameters(), clip)
_ = nn.utils.clip_grad_norm_(decoder.parameters(), clip)
# Adjust model weights
encoder_optimizer.step()
decoder_optimizer.step()
return sum(print_losses) / n_totals
def trainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer, embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size, print_every, save_every, clip, corpus_name, loadFilename):
# Load batches for each iteration
training_batches = [batch2TrainData(voc, [random.choice(pairs) for _ in range(batch_size)])
for _ in range(n_iteration)]
# Initializations
print('Initializing ...')
start_iteration = 1
print_loss = 0
if loadFilename:
start_iteration = checkpoint['iteration'] + 1
# Training loop
print("Training...")
for iteration in range(start_iteration, n_iteration + 1):
training_batch = training_batches[iteration - 1]
# Extract fields from batch
input_variable, lengths, target_variable, mask, max_target_len = training_batch
# Run a training iteration with batch
loss = train(input_variable, lengths, target_variable, mask, max_target_len, encoder,
decoder, embedding, encoder_optimizer, decoder_optimizer, batch_size, clip)
print_loss += loss
# Print progress
if iteration % print_every == 0:
print_loss_avg = print_loss / print_every
print("Iteration: {}; Percent complete: {:.1f}%; Average loss: {:.4f}".format(iteration, iteration / n_iteration * 100, print_loss_avg))
print_loss = 0
# Save checkpoint
if (iteration % save_every == 0):
directory = os.path.join(save_dir, model_name, corpus_name, '{}-{}_{}'.format(encoder_n_layers, decoder_n_layers, hidden_size))
if not os.path.exists(directory):
os.makedirs(directory)
torch.save({
'iteration': iteration,
'en': encoder.state_dict(),
'de': decoder.state_dict(),
'en_opt': encoder_optimizer.state_dict(),
'de_opt': decoder_optimizer.state_dict(),
'loss': loss,
'voc_dict': voc.__dict__,
'embedding': embedding.state_dict()
}, os.path.join(directory, '{}_{}.tar'.format(iteration, 'checkpoint')))
class GreedySearchDecoder(nn.Module):
def __init__(self, encoder, decoder):
super(GreedySearchDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, input_seq, input_length, max_length):
# Forward input through encoder model
encoder_outputs, encoder_hidden = self.encoder(input_seq, input_length)
# Prepare encoder's final hidden layer to be first hidden input to the decoder
decoder_hidden = encoder_hidden[:decoder.n_layers]
# Initialize decoder input with SOS_token
decoder_input = torch.ones(1, 1, device=device, dtype=torch.long) * SOS_token
# Initialize tensors to append decoded words to
all_tokens = torch.zeros([0], device=device, dtype=torch.long)
all_scores = torch.zeros([0], device=device)
# Iteratively decode one word token at a time
for _ in range(max_length):
# Forward pass through decoder
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden, encoder_outputs)
# Obtain most likely word token and its softmax score
decoder_scores, decoder_input = torch.max(decoder_output, dim=1)
# Record token and score
all_tokens = torch.cat((all_tokens, decoder_input), dim=0)
all_scores = torch.cat((all_scores, decoder_scores), dim=0)
# Prepare current token to be next decoder input (add a dimension)
decoder_input = torch.unsqueeze(decoder_input, 0)
# Return collections of word tokens and scores
return all_tokens, all_scores
def evaluate(encoder, decoder, searcher, voc, sentence, max_length=MAX_LENGTH):
indexes_batch = [indexesFromSentence(voc, sentence)]
lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
input_batch = torch.LongTensor(indexes_batch).transpose(0, 1)
input_batch = input_batch.to(device)
lengths = lengths.to("cpu")
tokens, scores = searcher(input_batch, lengths, max_length)
decoded_words = [voc.index2word[token.item()] for token in tokens]
return decoded_words
def evaluateInput(encoder, decoder, searcher, voc):
input_sentence = ''
while(1):
try:
input_sentence = input('> ')
if input_sentence == 'q' or input_sentence == 'quit': break
input_sentence = normalizeString(input_sentence)
output_words = evaluate(encoder, decoder, searcher, voc, input_sentence)
output_words[:] = [x for x in output_words if not (x == 'EOS' or x == 'PAD')]
print('Bot:', ' '.join(output_words))
except KeyError:
print("Error: Encountered unknown word.")
model_name = 'cb_model'
attn_model = 'dot'
hidden_size = 500
encoder_n_layers = 2
decoder_n_layers = 2
dropout = 0.1
batch_size = 64
loadFilename = None
checkpoint_iter = 4000
if loadFilename:
checkpoint = torch.load(loadFilename)
encoder_sd = checkpoint['en']
decoder_sd = checkpoint['de']
encoder_optimizer_sd = checkpoint['en_opt']
decoder_optimizer_sd = checkpoint['de_opt']
embedding_sd = checkpoint['embedding']
voc.__dict__ = checkpoint['voc_dict']
print('Building encoder and decoder ...')
embedding = nn.Embedding(voc.num_words, hidden_size)
if loadFilename:
embedding.load_state_dict(embedding_sd)
encoder = EncoderRNN(hidden_size, embedding, encoder_n_layers, dropout)
decoder = LuongAttnDecoderRNN(attn_model, embedding, hidden_size, voc.num_words, decoder_n_layers, dropout)
if loadFilename:
encoder.load_state_dict(encoder_sd)
decoder.load_state_dict(decoder_sd)
encoder = encoder.to(device)
decoder = decoder.to(device)
print('Models built and ready to go!')
clip = 50.0
teacher_forcing_ratio = 1.0
learning_rate = 0.0001
decoder_learning_ratio = 5.0
n_iteration = 4000
print_every = 1
save_every = 500
encoder.train()
decoder.train()
print('Building optimizers ...')
encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate * decoder_learning_ratio)
if loadFilename:
encoder_optimizer.load_state_dict(encoder_optimizer_sd)
decoder_optimizer.load_state_dict(decoder_optimizer_sd)
for state in encoder_optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.cuda()
for state in decoder_optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.cuda()
print("Starting Training!")
trainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer,
embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size,
print_every, save_every, clip, corpus_name, loadFilename)
7.4.2 运行代码
import torch
from torch.jit import script, trace
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import csv
import random
import re
import os
import unicodedata
import codecs
from io import open
import itertools
import math
import json
USE_CUDA = torch.cuda.is_available()
device = torch.device("cuda" if USE_CUDA else "cpu")
corpus_name = "movie-corpus"
corpus = os.path.join("data", corpus_name)
def printLines(file, n=10):
with open(file, 'rb') as datafile:
lines = datafile.readlines()
for line in lines[:n]:
print(line)
printLines(os.path.join(corpus, "utterances.jsonl"))
def loadLinesAndConversations(fileName):
lines = {}
conversations = {}
with open(fileName, 'r', encoding='iso-8859-1') as f:
for line in f:
lineJson = json.loads(line)
# Extract fields for line object
lineObj = {}
lineObj["lineID"] = lineJson["id"]
lineObj["characterID"] = lineJson["speaker"]
lineObj["text"] = lineJson["text"]
lines[lineObj['lineID']] = lineObj
# Extract fields for conversation object
if lineJson["conversation_id"] not in conversations:
convObj = {}
convObj["conversationID"] = lineJson["conversation_id"]
convObj["movieID"] = lineJson["meta"]["movie_id"]
convObj["lines"] = [lineObj]
else:
convObj = conversations[lineJson["conversation_id"]]
convObj["lines"].insert(0, lineObj)
conversations[convObj["conversationID"]] = convObj
return lines, conversations
# Extracts pairs of sentences from conversations
def extractSentencePairs(conversations):
qa_pairs = []
for conversation in conversations.values():
# Iterate over all the lines of the conversation
for i in range(len(conversation["lines"]) - 1): # We ignore the last line (no answer for it)
inputLine = conversation["lines"][i]["text"].strip()
targetLine = conversation["lines"][i+1]["text"].strip()
# Filter wrong samples (if one of the lists is empty)
if inputLine and targetLine:
qa_pairs.append([inputLine, targetLine])
return qa_pairs
datafile = os.path.join(corpus, "formatted_movie_lines.txt")
delimiter = '\t'
# Unescape the delimiter
delimiter = str(codecs.decode(delimiter, "unicode_escape"))
# Initialize lines dict and conversations dict
lines = {}
conversations = {}
# Load lines and conversations
print("\nProcessing corpus into lines and conversations...")
lines, conversations = loadLinesAndConversations(os.path.join(corpus, "utterances.jsonl"))
# Write new csv file
print("\nWriting newly formatted file...")
with open(datafile, 'w', encoding='utf-8') as outputfile:
writer = csv.writer(outputfile, delimiter=delimiter, lineterminator='\n')
for pair in extractSentencePairs(conversations):
writer.writerow(pair)
# Print a sample of lines
print("\nSample lines from file:")
printLines(datafile)
# Default word tokens
PAD_token = 0 # Used for padding short sentences
SOS_token = 1 # Start-of-sentence token
EOS_token = 2 # End-of-sentence token
class Voc:
def __init__(self, name):
self.name = name
self.trimmed = False
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count SOS, EOS, PAD
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.num_words
self.word2count[word] = 1
self.index2word[self.num_words] = word
self.num_words += 1
else:
self.word2count[word] += 1
# Remove words below a certain count threshold
def trim(self, min_count):
if self.trimmed:
return
self.trimmed = True
keep_words = []
for k, v in self.word2count.items():
if v >= min_count:
keep_words.append(k)
print('keep_words {} / {} = {:.4f}'.format(
len(keep_words), len(self.word2index), len(keep_words) / len(self.word2index)
))
# Reinitialize dictionaries
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count default tokens
for word in keep_words:
self.addWord(word)
MAX_LENGTH = 10 # Maximum sentence length to consider
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
s = re.sub(r"\s+", r" ", s).strip()
return s
# Read query/response pairs and return a voc object
def readVocs(datafile, corpus_name):
print("Reading lines...")
# Read the file and split into lines
lines = open(datafile, encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
voc = Voc(corpus_name)
return voc, pairs
# Returns True if both sentences in a pair 'p' are under the MAX_LENGTH threshold
def filterPair(p):
# Input sequences need to preserve the last word for EOS token
return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH
# Filter pairs using the ``filterPair`` condition
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
# Using the functions defined above, return a populated voc object and pairs list
def loadPrepareData(corpus, corpus_name, datafile, save_dir):
print("Start preparing training data ...")
voc, pairs = readVocs(datafile, corpus_name)
print("Read {!s} sentence pairs".format(len(pairs)))
pairs = filterPairs(pairs)
print("Trimmed to {!s} sentence pairs".format(len(pairs)))
print("Counting words...")
for pair in pairs:
voc.addSentence(pair[0])
voc.addSentence(pair[1])
print("Counted words:", voc.num_words)
return voc, pairs
# Load/Assemble voc and pairs
save_dir = os.path.join("data", "save")
voc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)
# Print some pairs to validate
print("\npairs:")
for pair in pairs[:10]:
print(pair)
MIN_COUNT = 3 # Minimum word count threshold for trimming
def trimRareWords(voc, pairs, MIN_COUNT):
# Trim words used under the MIN_COUNT from the voc
voc.trim(MIN_COUNT)
# Filter out pairs with trimmed words
keep_pairs = []
for pair in pairs:
input_sentence = pair[0]
output_sentence = pair[1]
keep_input = True
keep_output = True
# Check input sentence
for word in input_sentence.split(' '):
if word not in voc.word2index:
keep_input = False
break
# Check output sentence
for word in output_sentence.split(' '):
if word not in voc.word2index:
keep_output = False
break
# Only keep pairs that do not contain trimmed word(s) in their input or output sentence
if keep_input and keep_output:
keep_pairs.append(pair)
print("Trimmed from {} pairs to {}, {:.4f} of total".format(len(pairs), len(keep_pairs), len(keep_pairs) / len(pairs)))
return keep_pairs
# Trim voc and pairs
pairs = trimRareWords(voc, pairs, MIN_COUNT)
def indexesFromSentence(voc, sentence):
return [voc.word2index[word] for word in sentence.split(' ')] + [EOS_token]
def zeroPadding(l, fillvalue=PAD_token):
return list(itertools.zip_longest(*l, fillvalue=fillvalue))
def binaryMatrix(l, value=PAD_token):
m = []
for i, seq in enumerate(l):
m.append([])
for token in seq:
if token == PAD_token:
m[i].append(0)
else:
m[i].append(1)
return m
# Returns padded input sequence tensor and lengths
def inputVar(l, voc):
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
padList = zeroPadding(indexes_batch)
padVar = torch.LongTensor(padList)
return padVar, lengths
# Returns padded target sequence tensor, padding mask, and max target length
def outputVar(l, voc):
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
max_target_len = max([len(indexes) for indexes in indexes_batch])
padList = zeroPadding(indexes_batch)
mask = binaryMatrix(padList)
mask = torch.BoolTensor(mask)
padVar = torch.LongTensor(padList)
return padVar, mask, max_target_len
# Returns all items for a given batch of pairs
def batch2TrainData(voc, pair_batch):
pair_batch.sort(key=lambda x: len(x[0].split(" ")), reverse=True)
input_batch, output_batch = [], []
for pair in pair_batch:
input_batch.append(pair[0])
output_batch.append(pair[1])
inp, lengths = inputVar(input_batch, voc)
output, mask, max_target_len = outputVar(output_batch, voc)
return inp, lengths, output, mask, max_target_len
# Example for validation
small_batch_size = 5
batches = batch2TrainData(voc, [random.choice(pairs) for _ in range(small_batch_size)])
input_variable, lengths, target_variable, mask, max_target_len = batches
print("input_variable:", input_variable)
print("lengths:", lengths)
print("target_variable:", target_variable)
print("mask:", mask)
print("max_target_len:", max_target_len)
# %%
class EncoderRNN(nn.Module):
def __init__(self, hidden_size, embedding, n_layers=1, dropout=0):
super(EncoderRNN, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embedding = embedding
# Initialize GRU; the input_size and hidden_size parameters are both set to 'hidden_size'
# because our input size is a word embedding with number of features == hidden_size
self.gru = nn.GRU(hidden_size, hidden_size, n_layers,
dropout=(0 if n_layers == 1 else dropout), bidirectional=True)
def forward(self, input_seq, input_lengths, hidden=None):
# Convert word indexes to embeddings
embedded = self.embedding(input_seq)
# Pack padded batch of sequences for RNN module
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
# Forward pass through GRU
outputs, hidden = self.gru(packed, hidden)
# Unpack padding
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)
# Sum bidirectional GRU outputs
outputs = outputs[:, :, :self.hidden_size] + outputs[:, : ,self.hidden_size:]
# Return output and final hidden state
return outputs, hidden
# %%
# Luong attention layer
class Attn(nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.FloatTensor(hidden_size))
def dot_score(self, hidden, encoder_output):
return torch.sum(hidden * encoder_output, dim=2)
def general_score(self, hidden, encoder_output):
energy = self.attn(encoder_output)
return torch.sum(hidden * energy, dim=2)
def concat_score(self, hidden, encoder_output):
energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1), encoder_output), 2)).tanh()
return torch.sum(self.v * energy, dim=2)
def forward(self, hidden, encoder_outputs):
# Calculate the attention weights (energies) based on the given method
if self.method == 'general':
attn_energies = self.general_score(hidden, encoder_outputs)
elif self.method == 'concat':
attn_energies = self.concat_score(hidden, encoder_outputs)
elif self.method == 'dot':
attn_energies = self.dot_score(hidden, encoder_outputs)
# Transpose max_length and batch_size dimensions
attn_energies = attn_energies.t()
# Return the softmax normalized probability scores (with added dimension)
return F.softmax(attn_energies, dim=1).unsqueeze(1)
class LuongAttnDecoderRNN(nn.Module):
def __init__(self, attn_model, embedding, hidden_size, output_size, n_layers=1, dropout=0.1):
super(LuongAttnDecoderRNN, self).__init__()
# Keep for reference
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout = dropout
# Define layers
self.embedding = embedding
self.embedding_dropout = nn.Dropout(dropout)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout))
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.attn = Attn(attn_model, hidden_size)
def forward(self, input_step, last_hidden, encoder_outputs):
# Note: we run this one step (word) at a time
# Get embedding of current input word
embedded = self.embedding(input_step)
embedded = self.embedding_dropout(embedded)
# Forward through unidirectional GRU
rnn_output, hidden = self.gru(embedded, last_hidden)
# Calculate attention weights from the current GRU output
attn_weights = self.attn(rnn_output, encoder_outputs)
# Multiply attention weights to encoder outputs to get new "weighted sum" context vector
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
# Concatenate weighted context vector and GRU output using Luong eq. 5
rnn_output = rnn_output.squeeze(0)
context = context.squeeze(1)
concat_input = torch.cat((rnn_output, context), 1)
concat_output = torch.tanh(self.concat(concat_input))
# Predict next word using Luong eq. 6
output = self.out(concat_output)
output = F.softmax(output, dim=1)
# Return output and final hidden state
return output, hidden
def maskNLLLoss(inp, target, mask):
nTotal = mask.sum()
crossEntropy = -torch.log(torch.gather(inp, 1, target.view(-1, 1)).squeeze(1))
loss = crossEntropy.masked_select(mask).mean()
loss = loss.to(device)
return loss, nTotal.item()
def train(input_variable, lengths, target_variable, mask, max_target_len, encoder, decoder, embedding,
encoder_optimizer, decoder_optimizer, batch_size, clip, max_length=MAX_LENGTH):
# Zero gradients
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# Set device options
input_variable = input_variable.to(device)
target_variable = target_variable.to(device)
mask = mask.to(device)
# Lengths for RNN packing should always be on the CPU
lengths = lengths.to("cpu")
# Initialize variables
loss = 0
print_losses = []
n_totals = 0
# Forward pass through encoder
encoder_outputs, encoder_hidden = encoder(input_variable, lengths)
# Create initial decoder input (start with SOS tokens for each sentence)
decoder_input = torch.LongTensor([[SOS_token for _ in range(batch_size)]])
decoder_input = decoder_input.to(device)
# Set initial decoder hidden state to the encoder's final hidden state
decoder_hidden = encoder_hidden[:decoder.n_layers]
# Determine if we are using teacher forcing this iteration
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
# Forward batch of sequences through decoder one time step at a time
if use_teacher_forcing:
for t in range(max_target_len):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
# Teacher forcing: next input is current target
decoder_input = target_variable[t].view(1, -1)
# Calculate and accumulate loss
mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])
loss += mask_loss
print_losses.append(mask_loss.item() * nTotal)
n_totals += nTotal
else:
for t in range(max_target_len):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
# No teacher forcing: next input is decoder's own current output
_, topi = decoder_output.topk(1)
decoder_input = torch.LongTensor([[topi[i][0] for i in range(batch_size)]])
decoder_input = decoder_input.to(device)
# Calculate and accumulate loss
mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])
loss += mask_loss
print_losses.append(mask_loss.item() * nTotal)
n_totals += nTotal
# Perform backpropagation
loss.backward()
# Clip gradients: gradients are modified in place
_ = nn.utils.clip_grad_norm_(encoder.parameters(), clip)
_ = nn.utils.clip_grad_norm_(decoder.parameters(), clip)
# Adjust model weights
encoder_optimizer.step()
decoder_optimizer.step()
return sum(print_losses) / n_totals
def trainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer, embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size, print_every, save_every, clip, corpus_name, loadFilename):
# Load batches for each iteration
training_batches = [batch2TrainData(voc, [random.choice(pairs) for _ in range(batch_size)])
for _ in range(n_iteration)]
# Initializations
print('Initializing ...')
start_iteration = 1
print_loss = 0
if loadFilename:
start_iteration = checkpoint['iteration'] + 1
# Training loop
print("Training...")
for iteration in range(start_iteration, n_iteration + 1):
training_batch = training_batches[iteration - 1]
# Extract fields from batch
input_variable, lengths, target_variable, mask, max_target_len = training_batch
# Run a training iteration with batch
loss = train(input_variable, lengths, target_variable, mask, max_target_len, encoder,
decoder, embedding, encoder_optimizer, decoder_optimizer, batch_size, clip)
print_loss += loss
# Print progress
if iteration % print_every == 0:
print_loss_avg = print_loss / print_every
print("Iteration: {}; Percent complete: {:.1f}%; Average loss: {:.4f}".format(iteration, iteration / n_iteration * 100, print_loss_avg))
print_loss = 0
# Save checkpoint
if (iteration % save_every == 0):
directory = os.path.join(save_dir, model_name, corpus_name, '{}-{}_{}'.format(encoder_n_layers, decoder_n_layers, hidden_size))
if not os.path.exists(directory):
os.makedirs(directory)
torch.save({
'iteration': iteration,
'en': encoder.state_dict(),
'de': decoder.state_dict(),
'en_opt': encoder_optimizer.state_dict(),
'de_opt': decoder_optimizer.state_dict(),
'loss': loss,
'voc_dict': voc.__dict__,
'embedding': embedding.state_dict()
}, os.path.join(directory, '{}_{}.tar'.format(iteration, 'checkpoint')))
class GreedySearchDecoder(nn.Module):
def __init__(self, encoder, decoder):
super(GreedySearchDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, input_seq, input_length, max_length):
# Forward input through encoder model
encoder_outputs, encoder_hidden = self.encoder(input_seq, input_length)
# Prepare encoder's final hidden layer to be first hidden input to the decoder
decoder_hidden = encoder_hidden[:decoder.n_layers]
# Initialize decoder input with SOS_token
decoder_input = torch.ones(1, 1, device=device, dtype=torch.long) * SOS_token
# Initialize tensors to append decoded words to
all_tokens = torch.zeros([0], device=device, dtype=torch.long)
all_scores = torch.zeros([0], device=device)
# Iteratively decode one word token at a time
for _ in range(max_length):
# Forward pass through decoder
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden, encoder_outputs)
# Obtain most likely word token and its softmax score
decoder_scores, decoder_input = torch.max(decoder_output, dim=1)
# Record token and score
all_tokens = torch.cat((all_tokens, decoder_input), dim=0)
all_scores = torch.cat((all_scores, decoder_scores), dim=0)
# Prepare current token to be next decoder input (add a dimension)
decoder_input = torch.unsqueeze(decoder_input, 0)
# Return collections of word tokens and scores
return all_tokens, all_scores
def evaluate(encoder, decoder, searcher, voc, sentence, max_length=MAX_LENGTH):
indexes_batch = [indexesFromSentence(voc, sentence)]
lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
input_batch = torch.LongTensor(indexes_batch).transpose(0, 1)
input_batch = input_batch.to(device)
lengths = lengths.to("cpu")
tokens, scores = searcher(input_batch, lengths, max_length)
decoded_words = [voc.index2word[token.item()] for token in tokens]
return decoded_words
def evaluateInput(encoder, decoder, searcher, voc):
input_sentence = ''
while(1):
try:
input_sentence = input('> ')
if input_sentence == 'q' or input_sentence == 'quit': break
input_sentence = normalizeString(input_sentence)
output_words = evaluate(encoder, decoder, searcher, voc, input_sentence)
output_words[:] = [x for x in output_words if not (x == 'EOS' or x == 'PAD')]
print('Bot:', ' '.join(output_words))
except KeyError:
print("Error: Encountered unknown word.")
model_name = 'cb_model'
attn_model = 'dot'
hidden_size = 500
encoder_n_layers = 2
decoder_n_layers = 2
dropout = 0.1
batch_size = 64
loadFilename = None
checkpoint_iter = 4000
if loadFilename:
checkpoint = torch.load(loadFilename)
encoder_sd = checkpoint['en']
decoder_sd = checkpoint['de']
encoder_optimizer_sd = checkpoint['en_opt']
decoder_optimizer_sd = checkpoint['de_opt']
embedding_sd = checkpoint['embedding']
voc.__dict__ = checkpoint['voc_dict']
print('Building encoder and decoder ...')
embedding = nn.Embedding(voc.num_words, hidden_size)
if loadFilename:
embedding.load_state_dict(embedding_sd)
encoder = EncoderRNN(hidden_size, embedding, encoder_n_layers, dropout)
decoder = LuongAttnDecoderRNN(attn_model, embedding, hidden_size, voc.num_words, decoder_n_layers, dropout)
if loadFilename:
encoder.load_state_dict(encoder_sd)
decoder.load_state_dict(decoder_sd)
encoder = encoder.to(device)
decoder = decoder.to(device)
print('Models built and ready to go!')
clip = 50.0
teacher_forcing_ratio = 1.0
learning_rate = 0.0001
decoder_learning_ratio = 5.0
n_iteration = 4000
print_every = 1
save_every = 500
encoder.train()
decoder.train()
print('Building optimizers ...')
encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate * decoder_learning_ratio)
if loadFilename:
encoder_optimizer.load_state_dict(encoder_optimizer_sd)
decoder_optimizer.load_state_dict(decoder_optimizer_sd)
for state in encoder_optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.cuda()
for state in decoder_optimizer.state.values():
for k, v in state.items():
if isinstance(v, torch.Tensor):
state[k] = v.cuda()
print("Starting Training!")
trainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer,
embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size,
print_every, save_every, clip, corpus_name, loadFilename)
[1].吴元魁的 PyTorch 对话机器人实现:GitHub - ywk991112/pytorch-chatbot: Pytorch seq2seq chatbot
[2]. Sean Robertson 的实用 PyTorch seq2seq 翻译示例:practical-pytorch/seq2seq-translation at master · spro/practical-pytorch · GitHub
[3]. FloydHub 康奈尔电影语料库预处理代码:GitHub - floydhub/textutil-preprocess-cornell-movie-corpus: textutil-preprocess-cornell-movie-corpus

















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









