







1. 问题的提出
若存在一个样本集,其中有两类数据,我们希望将他们分类
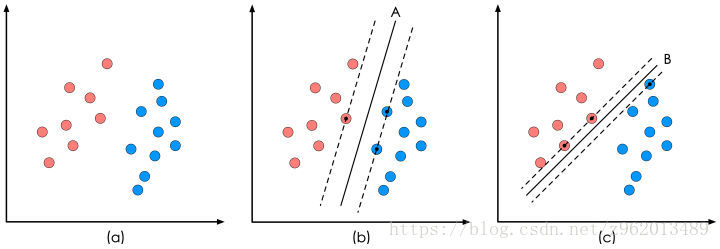
像上图(a)那样的样本集,SVM的目的就是企图获得一个超平面(在这个例子中超平面是一个直线),这个超平面可以完美的分割不同的数据集,我们用下面的线性方程来表示这个超平面:
ω
T
x
+
b
=
0
\mathbf{\omega ^{T}x}+b=0
ωTx+b=0
对于二维空间的超平面,实际上就是:
[
w
1
w
2
]
[
x
y
]
+
b
=
0
\begin{bmatrix} w1 & w2 \end{bmatrix} \begin{bmatrix} x\\ y \end{bmatrix} +b=0
[w1w2][xy]+b=0
我们再观察图(b)和©的两个直线,很明显b中的直线对样本集的划分更好一些,因为,在直线边缘的样本点离直线更远一些,这样就提高了样本划分的鲁棒性,所以我们就有了一个寻找超平面的最开始的理念:找到的这个超平面要离2组样本集尽量的远,即点到超平面的距离尽量大。
这里直接给出点到超平面的距离:
d
=
∣
ω
T
x
+
b
∣
∥
ω
∥
d=\frac{\left | \omega ^{T}\mathbf{x}+b \right |}{\left \| \omega \right \|}
d=∥ω∥∣∣ωTx+b∣∣
我们现在再给出样本的类别标签,红色点为-1,蓝色点为1,则有:
{
ω
T
x
i
+
b
>
0
y
i
=
1
ω
T
x
i
+
b
<
0
y
i
=
−
1
\left\{\begin{matrix} \omega ^{T}\mathbf{x_{i}}+b>0 & y_{i}=1\\ \omega ^{T}\mathbf{x_{i}}+b<0 & y_{i}=-1 \end{matrix}\right.
{ωTxi+b>0ωTxi+b<0yi=1yi=−1
如果我们要求再高一些,我们希望这些点到超平面的距离都要大于d,则有:
{
(
ω
T
x
i
+
b
)
/
∥
ω
∥
≥
d
y
i
=
1
(
ω
T
x
i
+
b
)
/
∥
ω
∥
≤
d
y
i
=
−
1
\left\{\begin{matrix} (\omega ^{T}\mathbf{x_{i}}+b)/\left \| \omega \right \|\geq d & y_{i}=1\\ (\omega ^{T}\mathbf{x_{i}}+b)/\left \| \omega \right \|\leq d & y_{i}=-1 \end{matrix}\right.
{(ωTxi+b)/∥ω∥≥d(ωTxi+b)/∥ω∥≤dyi=1yi=−1
不等式两边同时除以d,可以得到:
{
ω
d
T
x
i
+
b
d
≥
1
y
i
=
1
ω
d
T
x
i
+
b
d
≤
−
1
y
i
=
−
1
\left\{\begin{matrix} \omega_{d} ^{T}\mathbf{x_{i}}+b_{d}\geq 1 & y_{i}=1\\ \omega_{d} ^{T}\mathbf{x_{i}}+b_{d}\leq -1 & y_{i}=-1 \end{matrix}\right.
{ωdTxi+bd≥1ωdTxi+bd≤−1yi=1yi=−1
其中
ω
d
=
ω
∥
ω
∥
d
,
b
d
=
b
∥
ω
∥
d
\omega _{d}=\frac{\omega }{\left \| \omega \right \|d}, b_{d}=\frac{b}{\left \| \omega \right \|d}
ωd=∥ω∥dω,bd=∥ω∥db
实际上
ω
d
T
x
i
+
b
d
=
0
\omega_{d} ^{T}\mathbf{x_{i}}+b_{d}=0
ωdTxi+bd=0和
ω
T
x
i
+
b
=
0
\omega ^{T}\mathbf{x_{i}}+b=0
ωTxi+b=0是同样的超平面,既然如此我们就把
ω
d
\omega _{d}
ωd和 $ b_{d}$继续叫做
ω
\omega
ω和
b
b
b,那么我们就获得了SVM优化问题的约束条件:
{
ω
T
x
i
+
b
≥
1
y
i
=
1
ω
T
x
i
+
b
≤
−
1
y
i
=
−
1
(1.1)
\left\{\begin{matrix} \omega ^{T}\mathbf{x_{i}}+b\geq 1 & y_{i}=1\\ \omega ^{T}\mathbf{x_{i}}+b\leq -1 & y_{i}=-1 \end{matrix}\right. \tag{1.1}
{ωTxi+b≥1ωTxi+b≤−1yi=1yi=−1(1.1)
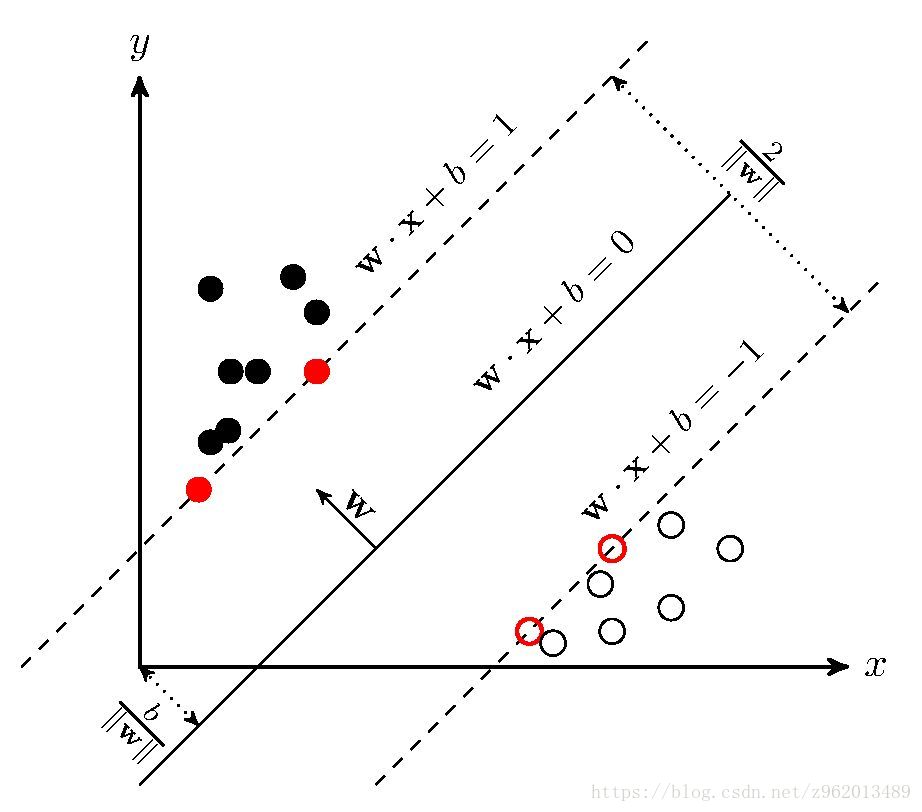
(图片来自https://www.cnblogs.com/freebird92/p/8909546.html)
如上图所示的距离超平面最近的几个训练样本点使(1.1)中的等号成立,这些点我们称为“支持向量”,两个异类支持向量到超平面的距离之和为
2
∥
ω
∥
\frac{2}{\left \| \omega \right \|}
∥ω∥2,我们希望这个值越大越好,即
1
2
∥
ω
∥
2
\frac{1}{2}\left \| \omega \right \|^{2}
21∥ω∥2越小越好,所以我们的问题就变成了:
m
i
n
1
2
∥
ω
∥
2
s
.
t
.
y
i
(
ω
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
.
.
.
,
m
.
(1.2)
min \frac{1}{2}\left \| \omega \right \|^{2} \\s.t.\ y_{i}(\omega ^{T}\mathbf{x_{i}}+b)\geq 1,\quad i=1,2,...,m.\tag{1.2}
min21∥ω∥2s.t. yi(ωTxi+b)≥1,i=1,2,...,m.(1.2)
2. 对偶问题##
式(1.2)是一个凸二次规划问题,我们可以使用拉格朗日乘子法获取其对偶问题来求解,引入拉格朗日乘子
α
i
≥
0
i
=
1
,
2
,
.
.
.
,
m
\alpha _{i}\geq 0 \quad i=1,2,...,m
αi≥0i=1,2,...,m,则式(1.2)写为:
L
(
ω
,
b
,
α
)
=
1
2
∥
ω
∥
2
+
∑
i
=
1
m
α
i
(
1
−
y
i
(
ω
T
x
i
+
b
)
)
(2.1)
L(\omega ,b,\mathbf{\alpha })=\frac{1}{2}\left \| \omega \right \|^{2}+\sum_{i=1}^{m}\alpha _{i}(1-y_{i}(\omega ^{T}x_{i}+b))\tag{2.1}
L(ω,b,α)=21∥ω∥2+i=1∑mαi(1−yi(ωTxi+b))(2.1)
对
ω
\omega
ω,b求偏导为0可得:
ω
=
∑
i
=
1
m
α
i
y
i
x
i
0
=
∑
i
=
1
m
α
i
y
i
(2.2)
\omega =\sum_{i=1}^{m}\alpha _{i}y_{i}\mathbf{x_{i}} \qquad 0=\sum_{i=1}^{m}\alpha _{i}y_{i}\tag{2.2}
ω=i=1∑mαiyixi0=i=1∑mαiyi(2.2)
将(2.2)带入(2.1)可得:
L
(
ω
,
b
,
α
)
=
1
2
∥
ω
∥
2
+
∑
i
=
1
m
α
i
(
1
−
y
i
(
ω
T
x
i
+
b
)
)
=
1
2
ω
T
ω
−
ω
T
∑
i
=
1
m
α
i
y
i
x
i
+
∑
i
=
1
m
α
i
−
∑
i
=
1
m
α
i
y
i
b
=
1
2
ω
T
(
ω
−
2
∑
i
=
1
m
α
i
y
i
x
i
)
+
∑
i
=
1
m
α
i
=
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
,
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
(2.3)
L(\omega ,b,\mathbf{\alpha })=\frac{1}{2}\left \| \omega \right \|^{2}+\sum_{i=1}^{m}\alpha _{i}(1-y_{i}(\omega ^{T}x_{i}+b))\\ =\frac{1}{2}\omega ^{T}\omega -\omega ^{T}\sum_{i=1}^{m}\alpha _{i}y_{i}\mathbf{x_{i}}+\sum_{i=1}^{m}\alpha _{i}-\sum_{i=1}^{m}\alpha _{i}y_{i}b\\ =\frac{1}{2}\omega ^{T}(\omega -2\sum_{i=1}^{m}\alpha _{i}y_{i}\mathbf{x_{i}})+\sum_{i=1}^{m}\alpha _{i}\\ =\sum_{i=1}^{m}\alpha _{i}-\frac{1}{2}\sum_{i=1,j=1}^{m}\alpha _{i}\alpha _{j}y_{i}y_{j}\mathbf{x_{i}^{T}x_{j}} \tag{2.3}
L(ω,b,α)=21∥ω∥2+i=1∑mαi(1−yi(ωTxi+b))=21ωTω−ωTi=1∑mαiyixi+i=1∑mαi−i=1∑mαiyib=21ωT(ω−2i=1∑mαiyixi)+i=1∑mαi=i=1∑mαi−21i=1,j=1∑mαiαjyiyjxiTxj(2.3)
最后的对偶问题为:
m
a
x
.
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
,
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
s
.
t
.
α
i
≥
0
∑
i
=
1
m
α
i
y
i
(2.4)
max. \sum_{i=1}^{m}\alpha _{i}-\frac{1}{2}\sum_{i=1,j=1}^{m}\alpha _{i}\alpha _{j}y_{i}y_{j}\mathbf{x_{i}^{T}x_{j}}\\ s.t.\ \alpha _{i}\geq 0 \quad \sum_{i=1}^{m}\alpha _{i}y_{i}\tag{2.4}
max.i=1∑mαi−21i=1,j=1∑mαiαjyiyjxiTxjs.t. αi≥0i=1∑mαiyi(2.4)
解出
α
\alpha
α后求出
ω
\omega
ω和b就可以得到模型:
f
(
x
)
=
ω
T
x
+
b
=
∑
i
=
1
m
α
i
y
i
x
i
x
+
b
(2.5)
f(\mathbf{x})=\omega ^{T}\mathbf{x}+b\\ =\sum_{i=1}^{m}\alpha _{i}y_{i}\mathbf{x_{i}x}+b \tag{2.5}
f(x)=ωTx+b=i=1∑mαiyixix+b(2.5)
因为式(1.2)含有不等式约束,因此对偶问题应满足KKT条件,这里稍微说一下KKT条件怎么获得的。
KKT条件

(图来自https://zhuanlan.zhihu.com/p/24638007)
不等式约束
g
(
x
)
≤
0
g(x)\leq0
g(x)≤0即为图中的可行解区域,最优解 $x^{*} $的位置有两种情况:在可行区域边界上或者在可行区域内部。
**在边界上:**这种情况下
g
(
x
)
=
0
g(x)=0
g(x)=0,目标函数
f
(
x
)
f(x)
f(x)在可行解区域边缘更大,可行解区域其他地方更小,而
g
(
x
)
g(x)
g(x)在可行解区域内小于0,外部大于0,意味着
f
(
x
)
f(x)
f(x)的梯度方向与约束条件函数
g
(
x
)
g(x)
g(x)的梯度方向相反,则在最优解处满足下式:
∇
f
(
x
∗
)
+
λ
∇
g
(
x
∗
)
=
0
\nabla f(\mathbf{x^{*}})+\lambda \nabla g(\mathbf{x^{*}})=0
∇f(x∗)+λ∇g(x∗)=0
根据上式可以推出当最优解在边界上时
λ
>
0
\lambda >0
λ>0
**在区域内:**这种情况相当于约束条件不存在,因此拉格朗日乘子
λ
=
0
\lambda =0
λ=0,
g
(
x
)
<
0
g(x)<0
g(x)<0
这样就得出了KKT条件
{
g
(
x
)
≤
0
λ
≥
0
λ
g
(
x
)
=
0
\left\{\begin{matrix} g(\mathbf{x})\leq 0\\ \lambda \geq 0\\ \lambda g(\mathbf{x})=0 \end{matrix}\right.
⎩⎨⎧g(x)≤0λ≥0λg(x)=0
其中第一个式子是约束本身,第二个式子是对拉格朗日乘子的描述,第三个式子是综合上述2种情况后获得的表达。
现在我们再回到之前的对偶问题中,(2.4)需要满足的KKT条件为:
{
α
i
≥
0
y
i
f
(
x
i
)
−
1
≥
0
α
i
(
y
i
f
(
x
i
)
−
1
)
=
0
\left\{\begin{matrix} \alpha _{i}\geq 0\\ y_{i}f(\mathbf{x_{i}})-1\geq 0\\ \alpha _{i}(y_{i}f(\mathbf{x_{i}})-1)=0 \end{matrix}\right.
⎩⎨⎧αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0
于是,对于任意训练样本,总有
α
i
=
0
\alpha _{i}= 0
αi=0或
y
i
f
(
x
i
)
=
1
y_{i}f(\mathbf{x_{i}})=1
yif(xi)=1,当
α
i
=
0
\alpha _{i}= 0
αi=0时,该样本不会对目标函数产生影响,若
α
i
>
0
\alpha _{i}> 0
αi>0,则必有
y
i
f
(
x
i
)
=
1
y_{i}f(\mathbf{x_{i}})=1
yif(xi)=1,此时对应样本位于最大间隔边界上,是一个支持向量。
##3. 核函数##
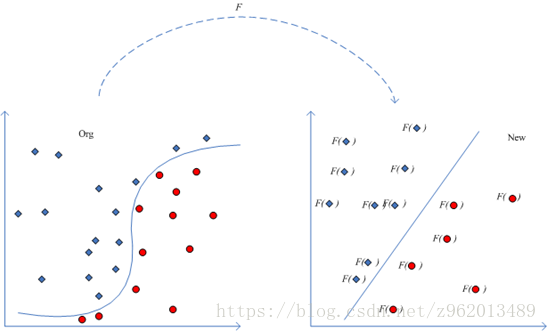
前面我们举的例子都是线性可分的,如果找不到一条直线将两个数据集分离的时候该怎么办呢?
(图片来自http://www.360doc.com/content/14/0526/16/10724725_381159791.shtml)
对于这样的问题,我们可以通过将样本点从原始空间映射到一个更高维的特征空间,使在这个新的特征空间内,样本点变得线性可分,就像上图描述的那样,我们用
φ
(
x
)
\varphi (\textbf{x})
φ(x)来表示将x映射后的特征向量,于是我们就可以将模型写为:
f
(
x
)
=
ω
T
φ
(
x
)
+
b
=
∑
i
=
1
m
α
i
y
i
φ
(
x
)
T
φ
(
x
i
)
+
b
(3.1)
f(\mathbf{x})=\omega ^{T}\varphi (\textbf{x})+b\\ =\sum_{i=1}^{m}\alpha _{i}y_{i}\varphi (\textbf{x})^{T}\varphi (\mathbf{x_{i}})+b \tag{3.1}
f(x)=ωTφ(x)+b=i=1∑mαiyiφ(x)Tφ(xi)+b(3.1)
对偶问题也描述为:
m
a
x
.
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
,
j
=
1
m
α
i
α
j
y
i
y
j
φ
(
x
i
)
T
φ
(
x
j
)
s
.
t
.
α
i
≥
0
∑
i
=
1
m
α
i
y
i
(3.2)
max. \sum_{i=1}^{m}\alpha _{i}-\frac{1}{2}\sum_{i=1,j=1}^{m}\alpha _{i}\alpha _{j}y_{i}y_{j}\varphi (\textbf{x}_{i})^{T}\varphi (\mathbf{x_{j}})\\ s.t.\ \alpha _{i}\geq 0 \quad \sum_{i=1}^{m}\alpha _{i}y_{i}\tag{3.2}
max.i=1∑mαi−21i=1,j=1∑mαiαjyiyjφ(xi)Tφ(xj)s.t. αi≥0i=1∑mαiyi(3.2)
求解(3.2)涉及到计算
φ
(
x
i
)
T
φ
(
x
j
)
\varphi (\textbf{x}_{i})^{T}\varphi (\mathbf{x_{j}})
φ(xi)Tφ(xj)考虑到样本x映射到特征空间后维数可能很高,因此直接计算
φ
(
x
i
)
T
φ
(
x
j
)
\varphi (\textbf{x}_{i})^{T}\varphi (\mathbf{x_{j}})
φ(xi)Tφ(xj)是很困难的,为了避免这种情况,我们引入下面这样的函数:
κ
i
j
=
κ
(
x
i
,
x
j
)
=
⟨
φ
(
x
i
)
,
φ
(
x
j
)
⟩
=
φ
(
x
i
)
T
φ
(
x
j
)
\kappa _{ij}=\kappa (\mathbf{x_{i},x_{j}})=\left \langle \varphi (\mathbf{x_{i}}),\varphi (\mathbf{x_{j}}) \right \rangle=\varphi (\mathbf{x_{i}})^{T}\varphi (\mathbf{x_{j}})
κij=κ(xi,xj)=⟨φ(xi),φ(xj)⟩=φ(xi)Tφ(xj)
即
x
i
\mathbf{x_{i}}
xi和
x
j
\mathbf{x_{j}}
xj在特征空间的内积等于他们在原始样本空间中通过函数
κ
(
x
i
,
x
j
)
\kappa (\mathbf{x_{i},x_{j}})
κ(xi,xj)计算的结果,于是式(3.2)就可以重新写为:
m
a
x
.
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
,
j
=
1
m
α
i
α
j
y
i
y
j
κ
i
j
s
.
t
.
α
i
≥
0
∑
i
=
1
m
α
i
y
i
(3.3)
max. \sum_{i=1}^{m}\alpha _{i}-\frac{1}{2}\sum_{i=1,j=1}^{m}\alpha _{i}\alpha _{j}y_{i}y_{j}\kappa _{ij}\\ s.t.\ \alpha _{i}\geq 0 \quad \sum_{i=1}^{m}\alpha _{i}y_{i}\tag{3.3}
max.i=1∑mαi−21i=1,j=1∑mαiαjyiyjκijs.t. αi≥0i=1∑mαiyi(3.3)
式(3.1)重写为:
f
(
x
)
=
ω
T
φ
(
x
)
+
b
=
∑
i
=
1
m
α
i
y
i
κ
(
x
i
,
x
)
+
b
(3.4)
f(\mathbf{x})=\omega ^{T}\varphi (\textbf{x})+b\\ =\sum_{i=1}^{m}\alpha _{i}y_{i}\kappa (\mathbf{x_{i},x})+b\tag{3.4}
f(x)=ωTφ(x)+b=i=1∑mαiyiκ(xi,x)+b(3.4)
这里的
κ
(
x
i
,
x
j
)
\kappa (\mathbf{x_{i},x_{j}})
κ(xi,xj)就是核函数,显然,如果已知合适的
φ
(
x
)
\varphi (\mathbf{x})
φ(x),我们很容易就可以写出核函数
κ
(
x
i
,
x
j
)
\kappa (\mathbf{x_{i},x_{j}})
κ(xi,xj),但是在一个任务中我们通常都不知道
φ
(
x
)
\varphi (\mathbf{x})
φ(x)是什么形式的,那么我们该怎么取核函数呢?
令
χ
\chi
χ为输入空间,
κ
(
x
i
,
x
j
)
\kappa (\mathbf{x_{i},x_{j}})
κ(xi,xj)是定义在
χ
×
χ
\chi \times \chi
χ×χ上的对称函数,则
κ
\kappa
κ是核函数当且仅当对于任意数据
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
D=\left \{ \mathbf{x_{1},x_{2},...,x_{m}} \right \}
D={x1,x2,...,xm},“核矩阵”K总是半正定的:
K
=
[
κ
(
x
1
,
x
1
)
.
.
.
κ
(
x
1
,
x
j
)
.
.
.
κ
(
x
1
,
x
m
)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
κ
(
x
i
,
x
1
)
.
.
.
κ
(
x
i
,
x
j
)
.
.
.
κ
(
x
i
,
x
m
)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
κ
(
x
m
,
x
1
)
.
.
.
κ
(
x
m
,
x
j
)
.
.
.
κ
(
x
m
,
x
m
)
]
K=\begin{bmatrix} \kappa (\mathbf{x_{1},x_{1}}) & ... & \kappa (\mathbf{x_{1},x_{j}}) & ... & \kappa (\mathbf{x_{1},x_{m}})\\ ... & ... & ... & ... & ...\\ \kappa (\mathbf{x_{i},x_{1}}) & ... & \kappa (\mathbf{x_{i},x_{j}}) & ... & \kappa (\mathbf{x_{i},x_{m}})\\ ... & ... & ... & ... & ...\\ \kappa (\mathbf{x_{m},x_{1}}) & ... & \kappa (\mathbf{x_{m},x_{j}}) & ... & \kappa (\mathbf{x_{m},x_{m}}) \end{bmatrix}
K=⎣⎢⎢⎢⎢⎡κ(x1,x1)...κ(xi,x1)...κ(xm,x1)...............κ(x1,xj)...κ(xi,xj)...κ(xm,xj)...............κ(x1,xm)...κ(xi,xm)...κ(xm,xm)⎦⎥⎥⎥⎥⎤
只要一个对称函数所对应的核矩阵半正定,他就能作为核函数使用,实际上,对于一个半正定核矩阵,总能找到一个与之对应的映射$\varphi $,换言之,任何一个核函数都隐式地定义了一个称为“再生和希尔伯特空间”的特征空间。前面说过,我们希望选取合适的核函数使样本在新特征空间内线性可分,因此特征空间的好坏对SVM的性能至关重要,下面给出一些常用的核函数:
- 线性核: κ i j = κ ( x i , x j ) = x i T x j \kappa _{ij}= \kappa (\mathbf{x_{i},x_{j}})=\mathbf{x_{i}^{T}x_{j}} κij=κ(xi,xj)=xiTxj
- 多项式核: κ i j = κ ( x i , x j ) = ( x i T x j ) d \kappa _{ij}= \kappa (\mathbf{x_{i},x_{j}})=\left (\mathbf{x_{i}^{T}x_{j}} \right )^{d} κij=κ(xi,xj)=(xiTxj)d
- 高斯核: κ i j = κ ( x i , x j ) = e x p ( − ∥ x i − x j ∥ 2 2 σ 2 ) \kappa _{ij}= \kappa (\mathbf{x_{i},x_{j}})= exp\left ( -\frac{\left \| \mathbf{x_{i}-x_{j}} \right \|^{2}}{2\sigma ^{2}} \right ) κij=κ(xi,xj)=exp(−2σ2∥xi−xj∥2)
- 拉普拉斯核: κ i j = κ ( x i , x j ) = e x p ( − ∥ x i − x j ∥ σ ) \kappa _{ij}= \kappa (\mathbf{x_{i},x_{j}})= exp\left ( -\frac{\left \| \mathbf{x_{i}-x_{j}} \right \|}{\sigma } \right ) κij=κ(xi,xj)=exp(−σ∥xi−xj∥)
- Sigmoid核: κ i j = κ ( x i , x j ) = t a n h ( β x i T x j + θ ) \kappa _{ij}= \kappa (\mathbf{x_{i},x_{j}})= tanh(\beta \mathbf{x_{i}^{T}x_{j}}+\theta ) κij=κ(xi,xj)=tanh(βxiTxj+θ)
此外,还可以通过函数组合得到核函数:
- 存在2个核函数 κ 1 \kappa _{1} κ1和 κ 2 \kappa _{2} κ2,他们的线性组合 a κ 1 + b κ 2 a\kappa _{1}+b\kappa _{2} aκ1+bκ2也是核函数
- 存在2个核函数 κ 1 \kappa _{1} κ1和 κ 2 \kappa _{2} κ2,他们的直积 κ 1 ⊗ κ 2 \kappa _{1}\otimes \kappa _{2} κ1⊗κ2也是核函数
- 存在核函数 κ 1 \kappa _{1} κ1,对于任意函数 g ( x ) g(\mathbf{x}) g(x), κ = g ( x ) κ 1 g ( x ) \kappa =g(\mathbf{x})\kappa _{1}g(\mathbf{x}) κ=g(x)κ1g(x)也是核函数
###传送门###
支持向量机(SVM)和python实现(二)https://blog.csdn.net/z962013489/article/details/82559626
支持向量机(SVM)和python实现(三)https://blog.csdn.net/z962013489/article/details/82622036














 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









