










前言
前面已经介绍了RBM和CNN了,就剩最后一个RNN了,抽了一天时间简单看了一下原理,但是没细推RNN的参数更新算法BPTT,全名是Backpropagation Through Time。
【注】严谨来说RNN有两个称呼:①结构上递归的recursive neural network,通常称为递归神经网络;②时间上递归的recurrent neural network,通常称为循环神经网络。我们说的RNN是后者,本博客中RNN指的即为循环神经网络。
国际惯例,参考网址:
书籍《深度学习导论及案例分析》
理论
书籍《深度学习导论及案例分析》中说明了RNN具有两种基本结构Elman结构和Jordan结构,不同之处在于:
Elman结构中:将上一时刻的隐层输出作为上下文节点Jordan结构中:将上一时刻的输出作为上下文节点
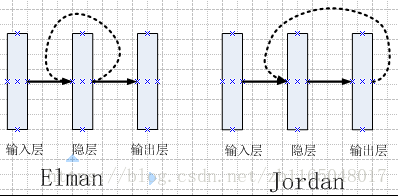
图中实线代表正常的连接,虚线代表复制所连接层(Elman隐层或Jordan输出层)的上一时刻数据作为加权到箭头所指位置(其实就是隐层),其实从结构上看,把虚线去掉,就是传统的三层神经网络,只不过改变成RNN时,将某个时刻的隐层或者输出层的数值拉了一根线出来,在计算下一时刻隐层单元值的时候与输入层传递的值做加和处理。嘴上说不清楚,看公式:
Elman神经网络
h(t)h(t)o(t)=f(u(t))=f(Vx(t)+b),t=0=f(u(t))=f(Vx(t)+Uh(t−1)+b),1≤t≤T=g(v(t))=g(Wh(t)+α) h ( t ) = f ( u ( t ) ) = f ( V x ( t ) + b ) , t = 0 h ( t ) = f ( u ( t ) ) = f ( V x ( t ) + U h ( t − 1 ) + b ) , 1 ≤ t ≤ T o ( t ) = g ( v ( t ) ) = g ( W h ( t ) + α )Jordan神经网络
h(t)h(t)o(t)=f(u(t))=f(Vx(t)+b),t=0=f(u(t))=f(Vx(t)+Uo(t−1)+b),1≤t≤T=g(v(t))=g(Wh(t)+α) h ( t ) = f ( u ( t ) ) = f ( V x ( t ) + b ) , t = 0 h ( t ) = f ( u ( t ) ) = f ( V x ( t ) + U o ( t − 1 ) + b ) , 1 ≤ t ≤ T o ( t ) = g ( v ( t ) ) = g ( W h ( t ) + α )
很显然,公式的 h h 代表隐单元值,代表输出层单元值, x x 代表输入数据,代表时刻
上述公式求导也不难,我就直接把书上结果粘贴过来了,这里简化一下上下标,假设就一个样本,参数更新使用的是MSE损失
代码实现
主要参考前言中所贴网址,但是做了一些精简,具体的可以去看看官方实现,这里主要针对Elman结构码公式:
首先导入一堆包:
#Elman recurrent neural network
import numpy as np
import theano
import theano.tensor as T
import theano.tensor.shared_randomstreams as RandomStreams
import os
import matplotlib.pyplot as plt
plt.ion()直入主题,码公式,构建网络:
①首先确定所需的参数,三个权重,两个偏置:
#建立Elman循环神经网络
class Elman(object):
def __init__(self,input,n_in,n_hidden,n_out,activation=T.tanh,output_type='real'):
self.input=input
self.activation=activation
self.output_type=output_type
self.softmax=T.nnet.softmax
#隐层到上下文的连接权重
W_init=np.asarray(np.random.uniform(size=(n_hidden,n_hidden),\
low=-.01,high=.01),\
dtype=theano.config.floatX)
self.W=theano.shared(value=W_init,name='W')
#输入层到隐层的连接权重
W_in_init=np.asarray(np.random.uniform(size=(n_in,n_hidden),\
low=-.01,high=.01),\
dtype=theano.config.floatX)
self.W_in=theano.shared(value=W_in_init,name='W_in')
#隐层到输出层的连接权重
W_out_init=np.asarray(np.random.uniform(size=(n_hidden,n_out),\
low=-.01,high=.01),
dtype=theano.config.floatX)
self.W_out=theano.shared(value=W_out_init,name='W_out')
#隐层初始状态
h0_init=np.zeros((n_hidden,),dtype=theano.config.floatX)
self.h0=theano.shared(value=h0_init,name='h0')
#隐层偏置
bh_init=np.zeros((n_hidden,),dtype=theano.config.floatX)
self.bh=theano.shared(value=bh_init,name='bh')
#输出层偏置
by_init=np.zeros((n_out,),dtype=theano.config.floatX)
self.by=theano.shared(value=by_init,name='by')
#模型参数
self.params=[self.W,self.W_in,self.W_out,self.h0,self.bh,self.by]
#对于每个参数,保留最后一次更新
self.updates={}
for param in self.params:
init=np.zeros(param.get_value(borrow=True).shape,\
dtype=theano.config.floatX)
self.updates[param]=theano.shared(init)②初始化完毕,就码公式,其中需要注意的是input是一个二维矩阵,分别代表时刻与当前时刻的样本值向量,比如第一秒的图片
#对于循环函数采用tanh激活,线性输出
def step(x_t,h_tm1):
h_t=self.activation(T.dot(x_t,self.W_in)+ T.dot(h_tm1,self.W)+self.bh)
y_t=T.dot(h_t,self.W_out)+self.by
return h_t,y_t
[self.h,self.y_pred],_=theano.scan(step,sequences=self.input,outputs_info=[self.h0,None])
# L1归一化
self.L1=abs(self.W.sum())+abs(self.W_in.sum())+abs(self.W_out.sum())
# L2归一化
self.L2_sqr=(self.W**2).sum()+(self.W_in**2).sum()+(self.W_out**2).sum()上面这个代码中用到了scan函数进行迭代,但是我们发现这个输入其实是一个矩阵,而且没有指定迭代次数,那么scan这个函数可以从输入矩阵中取出每一时刻的样本值(向量)么?我们在文末单独验证。
接下来Taylor大佬想的很全面,分别针对实值、二值、多分类任务设计了不同的损失:
# 针对不同的输出类型有不同的损失函数
if self.output_type=='real':
self.loss=lambda y:self.mse(y)
elif self.output_type=='binary':
self.p_y_given_x=T.nnet.sigmoid(self.y_pred)
self.y_out=T.round(self.p_y_given_x)
self.loss=lambda y:self.nll_binary(y)
elif self.output_type=='softmax':
self.p_y_given_x=self.softmax(self.y_pred)
self.y_out=T.argmax(self.p_y_given_x,axis=-1)
self.loss=lambda y:self.nll_multiclass(y)
else:
raise NotImplementedError
# 定义几种不同的损失
def mse(self,y):
return T.mean((self.y_pred-y)**2)
def nll_binary(self,y):
return T.mean(T.nnet.binary_crossentropy(self.p_y_given_x,y))
def nll_multiclass(self,y):
return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]),y])定义误差函数,就是预测值与实际值差的均值
def error(self,y):
if y.ndim!=self.y_out.ndim:
raise TypeError('y should have the same shape as self.y_out','y',y.type,'y_out',self.y_out.type)
if self.output_type in ('binary','softmax'):
if y.dtype.startwith('int'):
return T.mean(T.neq(self.y_out,y))
else:
raise NotImplementedError()③构建模型,用于初始化模型相关参数与训练模型
class MetaRNN():
def __init__(self,n_in=5,n_hidden=50,n_out=5,learning_rate=0.01,\
n_epochs=100,L1_reg=0.00,L2_reg=0.00,learning_rate_decay=1,\
activation='tanh',output_type='real',\
final_momentum=0.9,initial_momentum=0.5,\
momentum_switchover=5):
self.n_in=int(n_in)
self.n_hidden=int(n_hidden)
self.n_out=int(n_out)
self.learning_rate=float(learning_rate)
self.learning_rate_decay=float(learning_rate_decay)
self.n_epochs=int(n_epochs)
self.L1_reg=float(L1_reg)
self.L2_reg=float(L2_reg)
self.activation=activation
self.output_type=output_type
self.initial_momentum=float(initial_momentum)
self.final_momentum=float(final_momentum)
self.momentum_switchover=int(momentum_switchover)
self.ready()这里的ready函数是指构建RNN网络,以及计算它的输出
def ready(self):
self.x=T.matrix()
if self.output_type=='real':
self.y=T.matrix(name='y',dtype=theano.config.floatX)
elif self.output_type=='binary':
self.y=T.matrix(name='y',dtype='int32')
elif self.output_type=='softmax':
self.y=T.vector(name='y',dtype='int32')
else:
raise NotImplementedError
self.h0=T.vector()#RNN的初始状态
self.lr=T.scalar()#学习率
if self.activation=='tanh':
activation=T.tanh
elif self.activation=='sigmoid':
activation=T.nnet.sigmoid
elif self.activation=='relu':
activation=lambda x:x*(x>0)
elif self.activation=='cappedrelu':
activation=lambda x:T.minimum(x*(x>0),6)
else:
raise NotImplementedError
self.rnn=Elman(input=self.x,n_in=self.n_in,n_hidden=self.n_hidden,\
n_out=self.n_out,activation=activation,output_type=self.output_type)
if self.output_type=='real':
self.predict=theano.function(inputs=[self.x,],outputs=self.rnn.y_pred)
elif self.output_type=='binary':
self.predict_proba=theano.function(inputs=[self.x,],outputs=self.rnn.p_y_given_x)
self.predict=theano.function(inputs=[self.x,],outputs=T.round(self.rnn.p_y_given_x))
elif self.output_type=='softmax':
self.predict_proba=theano.function(inputs=[self.x,],outputs=self.rnn.p_y_given_x)
self.predict=theano.function(inputs=[self.x,],outputs=self.rnn.y_out)
else:
raise NotImplementedError接下来计算梯度和更新参数
def fit(self,X_train,Y_train,X_test=None,Y_test=None,validation_frequency=100):
train_set_x,train_set_y=self.shared_dataset((X_train,Y_train))
n_train=train_set_x.get_value(borrow=True).shape[0]
print('...build the model')
index=T.lscalar('index')
l_r=T.scalar('l_r',dtype=theano.config.floatX)
mom=T.scalar('mom',dtype=theano.config.floatX)
cost=self.rnn.loss(self.y)+self.L1_reg*self.rnn.L1+self.L2_reg*self.rnn.L2_sqr
compute_train_error=theano.function(inputs=[index,],\
outputs=self.rnn.loss(self.y),\
givens={
self.x:train_set_x[index],
self.y:train_set_y[index]
})
# 计算梯度,更新参数
gparams=[]
for param in self.rnn.params:
gparam=T.grad(cost,param)
gparams.append(gparam)
updates={}
for param,gparam in zip(self.rnn.params,gparams):
weight_update=self.rnn.updates[param]
upd=mom*weight_update-l_r*gparam
updates[weight_update]=upd
updates[param]=param+upd
#训练模型
train_model=theano.function(inputs=[index,l_r,mom],\
outputs=cost,\
updates=updates,\
givens={
self.x:train_set_x[index],
self.y:train_set_y[index]
})采用提前终止算法训练,这与前面的theano教程一模一样
print('...开始训练')
epoch=0
while(epoch<self.n_epochs):
epoch=epoch+1
for idx in range(n_train):
effective_momentum=self.final_momentum\
if epoch>self.momentum_switchover\
else self.initial_momentum
example_cost=train_model(idx,self.learning_rate,effective_momentum)
iter=(epoch-1)*n_train+idx+1
if iter%validation_frequency==0:
train_losses=[compute_train_error(i) for i in range(n_train)]
this_train_loss=np.mean(train_losses)
print('epoch %i,seq %i%i, train loss %f,lr:%f' %\
(epoch,idx+1,n_train,this_train_loss,self.learning_rate) )
self.learning_rate*=self.learning_rate_decay④最后就可以用一个实例来测试网络性能,这里只贴一个实值的例子:
首先初始化一个三维矩阵
(100×10×5)
(
100
×
10
×
5
)
表示100个样本,每个样本包含的时间长度为10,每个样本每一时刻的输入维度是5;
随后初始化一个全零的矩阵作为输出目标,大小为
(100×10×3)
(
100
×
10
×
3
)
,代表100个样本10个时刻分别的输出维度为3,通俗点讲就是输入单元维度为5,输出单元维度为3,时间长(scan的迭代次数为10),然后对输出的目标矩阵进行赋值:
- 所有样本输出数据的第0个维度从第2至10时刻的输出是输入数据的第3个维度从时刻1至9的数据
- 所有样本输出数据的第1个维度从第2至10时刻的输出是输入数据的第2个维度从时刻1至9的数据
- 所有样本输出数据的第2个维度从第2至10时刻的输出是输入数据的第0个维度从时刻1至8的数据
其实上述操作就是将输入数据的某几个维度做了一个延迟作为输出目标,比如我们用第1至10时刻的图片预测时候,输出是第2至11时刻的图片,最后对整个输出目标矩阵附加高斯噪声。
def test_real():
#测试实值输出的RNN:
n_hidden=10
n_in=5
n_out=3
n_steps=10
n_seq=100
np.random.seed(0)
seq=np.asarray(np.random.randn(n_seq,n_steps,n_in),dtype=theano.config.floatX)
targets=np.zeros((n_seq,n_steps,n_out),dtype=theano.config.floatX)
targets[:,1:,0]=seq[:,:-1,3]
targets[:,1:,1]=seq[:,:-1,2]
targets[:,2:,2]=seq[:,:-2,0]
targets+=0.01*np.random.standard_normal(targets.shape)
model=MetaRNN(n_in=n_in,n_hidden=n_hidden,n_out=n_out,
learning_rate=0.001,learning_rate_decay=0.999,
n_epochs=500,activation='tanh')
model.fit(seq,targets,validation_frequency=1000)
plt.close('all')
fig=plt.figure()
ax1=plt.subplot(211)
plt.plot(seq[0])
ax1.set_title('input')
ax2=plt.subplot(212)
true_targets=plt.plot(targets[0])
guess=model.predict(seq[0])
guessed_targets=plt.plot(guess,linestyle='--')
for i,x in enumerate(guessed_targets):
x.set_color(true_targets[i].get_color())
ax2.set_title('solid:true output ,dashed:model output')结果
...build the model
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py:95: UserWarning: The parameter 'updates' of theano.function() expects an OrderedDict, got <class 'dict'>. Using a standard dictionary here results in non-deterministic behavior. You should use an OrderedDict if you are using Python 2.7 (theano.compat.OrderedDict for older python), or use a list of (shared, update) pairs. Do not just convert your dictionary to this type before the call as the conversion will still be non-deterministic.
...开始训练
epoch 10,seq 100100, train loss 0.865682,lr:0.000991
epoch 20,seq 100100, train loss 0.865654,lr:0.000981
epoch 30,seq 100100, train loss 0.865589,lr:0.000971
epoch 40,seq 100100, train loss 0.865428,lr:0.000962
epoch 50,seq 100100, train loss 0.864999,lr:0.000952
epoch 60,seq 100100, train loss 0.863422,lr:0.000943
epoch 70,seq 100100, train loss 0.831402,lr:0.000933
epoch 80,seq 100100, train loss 0.569127,lr:0.000924
epoch 90,seq 100100, train loss 0.567128,lr:0.000915
epoch 100,seq 100100, train loss 0.565494,lr:0.000906
epoch 110,seq 100100, train loss 0.562675,lr:0.000897
epoch 120,seq 100100, train loss 0.520082,lr:0.000888
epoch 130,seq 100100, train loss 0.279635,lr:0.000879
epoch 140,seq 100100, train loss 0.274908,lr:0.000870
epoch 150,seq 100100, train loss 0.272029,lr:0.000862
epoch 160,seq 100100, train loss 0.270034,lr:0.000853
epoch 170,seq 100100, train loss 0.268564,lr:0.000844
epoch 180,seq 100100, train loss 0.267410,lr:0.000836
epoch 190,seq 100100, train loss 0.266435,lr:0.000828
epoch 200,seq 100100, train loss 0.265549,lr:0.000819
epoch 210,seq 100100, train loss 0.264681,lr:0.000811
epoch 220,seq 100100, train loss 0.263752,lr:0.000803
epoch 230,seq 100100, train loss 0.262604,lr:0.000795
epoch 240,seq 100100, train loss 0.260679,lr:0.000787
epoch 250,seq 100100, train loss 0.254478,lr:0.000779
epoch 260,seq 100100, train loss 0.203689,lr:0.000772
epoch 270,seq 100100, train loss 0.130576,lr:0.000764
epoch 280,seq 100100, train loss 0.033863,lr:0.000756
epoch 290,seq 100100, train loss 0.018814,lr:0.000749
epoch 300,seq 100100, train loss 0.014290,lr:0.000741
epoch 310,seq 100100, train loss 0.011918,lr:0.000734
epoch 320,seq 100100, train loss 0.010433,lr:0.000727
epoch 330,seq 100100, train loss 0.009397,lr:0.000720
epoch 340,seq 100100, train loss 0.008622,lr:0.000712
epoch 350,seq 100100, train loss 0.008012,lr:0.000705
epoch 360,seq 100100, train loss 0.007515,lr:0.000698
epoch 370,seq 100100, train loss 0.007100,lr:0.000691
epoch 380,seq 100100, train loss 0.006746,lr:0.000684
epoch 390,seq 100100, train loss 0.006440,lr:0.000678
epoch 400,seq 100100, train loss 0.006171,lr:0.000671
epoch 410,seq 100100, train loss 0.005933,lr:0.000664
epoch 420,seq 100100, train loss 0.005720,lr:0.000658
epoch 430,seq 100100, train loss 0.005528,lr:0.000651
epoch 440,seq 100100, train loss 0.005353,lr:0.000645
epoch 450,seq 100100, train loss 0.005194,lr:0.000638
epoch 460,seq 100100, train loss 0.005048,lr:0.000632
epoch 470,seq 100100, train loss 0.004914,lr:0.000625
epoch 480,seq 100100, train loss 0.004790,lr:0.000619
epoch 490,seq 100100, train loss 0.004675,lr:0.000613
epoch 500,seq 100100, train loss 0.004567,lr:0.000607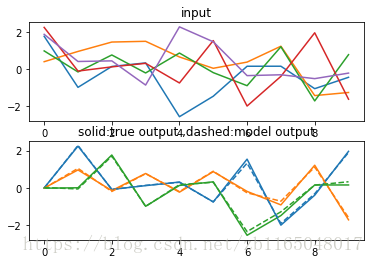
这个实验结果图中,列出了第一个样本序列的10个时刻,每一时刻的5个维度数据,横坐标代表时间,纵坐标的五条曲线分别代表五个输入维度,就我所观察,输入维度与输出维度的对应关系是:
- 绿线输入对应黄线输出,延迟为1
- 红线输入对应蓝线输出,延迟为1
- 蓝线输入对应绿线输出,延迟为2
因为我们的预测(输出)数据其实就是历史(输入数据),这个历史到底是多久的历史,可以自己定义(上面的历史分别是1,1,2),而且预测的数据维度不一定等于输入数据的维度,比如上例中就是用五条彩线预测其中三条彩线,这三条彩线的数据来源于五条彩线,只不过是对五条彩线做了个延迟处理,即用五条彩线上当前时刻的五个数据预测五条彩线未来时刻的五个数据中的3个。
实验结果中实线是原始数据,虚线是拟合数据,貌似效果很不错啊
验证scan
前面留了个问题,当输入是矩阵,代表时刻与当前时刻的样本数据时,使用scan能否在每次迭代中取出当前样本值?
简单回顾一下我们需要了解的scan的输入:
sequence:会被迭代取值的输入non_sequence:不会被迭代取值的输入
本博客就只用到它俩,主要验证当sequence作为输入的时候,scan的每次迭代是如何取值的。
这里我们先拿两个2x2的矩阵相乘试试:
简单的function复习
复习一下简单的function做矩阵乘法
X=T.matrix('X');
W=T.matrix('W');
out_WX=T.dot(W,X);
fn=theano.function(inputs=[W,X],outputs=out_WX)
A=np.asarray([[1,2],[3,4]],dtype=theano.config.floatX)
B=np.asarray([[2,3],[5,7]],dtype=theano.config.floatX)
print(fn(A,B))
print(np.dot(A,B))结果:
[[12. 17.]
[26. 37.]]
[[12. 17.]
[26. 37.]]使用scan迭代取值
使用scan对B进行迭代取值,看看计算结果
import theano
import theano.tensor as T
import numpy as np
#查看scan对于矩阵的索引操作
X=T.matrix('X');
W=T.matrix('W');
results,updates=theano.scan(lambda X,W:T.dot(W,X),sequences=X,non_sequences=W)
result=results[0]
test_mxm=theano.function(inputs=[W,X],outputs=results)上述就是设计好了一个scan函数,其中W是固定的权重系数,X是输入序列矩阵,我们验证一下每次与W相乘是X的行还是列:
A=np.asarray([[1,2],[3,4]],dtype=theano.config.floatX)
B=np.asarray([[2,3],[5,7]],dtype=theano.config.floatX)
C=test_mxm(A,B)
print('A:\n',A)
print ('B:\n',B)
print('C:\n',C)结果
A:
[[1. 2.]
[3. 4.]]
B:
[[2. 3.]
[5. 7.]]
C:
[[ 8. 18.]
[19. 43.]]很容易发现:
那么很容易得出结论:当
scan的输入是矩阵的时候,每次迭代会从矩阵中选择一行做对应计算,即每行代表一个时刻的样本。
理论
准备
为了更清晰了解RNN的求导,还是推导一遍吧,这回算是把RBM、CNN、RNN三大DL模型全部推导一遍了,求个圆满,先定义一堆计算吧,即RNN的前向计算和误差函数:
误差 L L 就是每个时刻误差的累积值,如果每时刻的误差是
MSE误差 每时刻的输出 yt=f(VSt) y t = f ( V S t ) ,其中 St=g(Uxt+WSt−1) S t = g ( U x t + W S t − 1 )
这样三个权重都有了,V代表隐层到输出层的连接权重,U代表输入层到隐层的连接权重,W代表上下文权重,在Elman结构中代表上一时刻的隐层到下一时刻隐层的连接权重。
求梯度(网传算法证明)
先看损失函数对于隐层到输出层连接权重V的导数:
再看损失函数对于输入到隐层的连接权重U的导数:
重头戏来了,损失函数对于上下文节点的连接权重W的导数:
前一项简单,看后一项的计算,一定要注意的是 St−1 S t − 1 也与 W W 有关,所以不要跟上面两个求导一样求嗨了,少一项就扎心了:
这里的 g′t g t ′ 代表 g(Uxt+WSt−1) g ( U x t + W S t − 1 ) 的导数,可以发现 t t 时刻的损失对上下文权重的偏导计算是一个链式过程,一直链接到初始时刻,而且乘了很多次 W W ,乘的次数越多,越可能导致梯度消失或者梯度爆炸。
【PS】这里我一直有一个疑问,网上有一个千篇一律的写法,即在计算 的时候,直接写出了下式:
几乎大部分有关RNN推导的博客都是这个式子,可以看:
Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients
Recurrent Neural Network系列3–理解RNN的BPTT算法和梯度消失
RNN(Recurrent Neural Networks)公式推导和实现
Recurrent Neural Network系列3–理解RNN的BPTT算法和梯度消失
貌似都是copy第一篇英文博客,这个求和的链式花了我半天时间去证明,这个式子不可能直接手写出来,共享权重,怎么可能这么容易就求出导数了。
感觉这个式子就等价于:
假设 S0=g(Ux0) S 0 = g ( U x 0 ) ,那么上式继续简化:
这他丫的怎么求 ∂S3∂W ∂ S 3 ∂ W 的结果向中还有 ∂S3∂W ∂ S 3 ∂ W ?这是在玩蛇?
如果按照我自己的求导算法理解:
看到这里,肯定有人奇怪,这怎么就花了你半天时间?原因就在于我将自己所求解的结果变换到网上流传的版本的时候一直没成功,然而后来我灵光一闪,我的计算和网络的计算都是三项,那么,如果我这样想
也就是说忽略掉求解 ∂St∂W ∂ S t ∂ W 需要的 ∂St−1∂W ∂ S t − 1 ∂ W , 也就说忽略掉链式,把每个时间块看成独立的,那么:
我当场就懵逼了, 原来网上流传的结果在求解 ∂S3W ∂ S 3 W 的时候说,求这个的时候不要忘记它还与 ∂S2∂W ∂ S 2 ∂ W 之类的有关,但是在结果项中, ∂S3∂W ∂ S 3 ∂ W 与其它时间的 S S 对的偏导比如 ∂S2∂ ∂ S 2 ∂ 是完全无关的,也就是说把W看成了与 St−k S t − k 无关的量去求导。
求梯度总结
那么以后我们对于任意长度的反传梯度都可以直接写出来:
但是一定要记住对于右边的式子
容我心里嘀咕一句MMP哦~_~
后记
感觉RNN的理论很简单,没RBM的采样算法和多层CNN的反向传播算法那么复杂,这个反向传播就是传统三层神经网络多了一个时间线求导,这个时间线的长度与梯度消失的可能性成正比,时间越长,针对时间线权重的反传梯度越小。
贴一下完整代码吧:链接: https://pan.baidu.com/s/1-bw1MhCn2uBCyH6otoE7AQ 密码: aw2b
后面就研究研究RNN的优化结构,听说包括LSTM和GRU,后面再看吧


















 2296
2296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











