







2019年Arxiv上的一篇预训练模型RoBERTa: A Robustly Optimized BERT Pretraining Approach,虽然后来也没看到这个模型被哪个会议录用了,大概是因为创新点并不大。不过似乎因为效果比Bert好了一些些,而被研究者们广泛使用了(虽然也有人说没比Bert强到哪里去)。
代码放在facebook中的fairseq工具包里,该代码库在https://github.com/facebookresearch/fairseq。
具体的,可以在ReadMe里找到RoBerta的预训练模型。
pass1
看标题:主体是Bert,形容词是Robustly Optimized,那么本文看上去就是经过更好、更鲁棒训练的Bert
看单位:华盛顿大学的Allen school和Facebook,那么这篇工作应该是比较靠谱的。
看摘要:大规模语言模型的预训练是非常麻烦的,因此,对于不同预训练模型的比较是非常艰难的。本文对bert的超参数和训练过程进行了详细的分析,在GLUE, RACE and SQuAD等数据集上进行训练,证明此前的bert并没有被非常好的训练,即有一些技巧的好处被低估。同时,很多在Bert和Roberta之间的模型所带来的增长,是否也被高估了呢?
看总结: 本文采用的多种训练技巧,例如:
- training the model longer:采用更长的训练时间。
- with bigger batches over more data:使用更大批(Batch)的训练数据。
- removing the next sentence prediction objective:不使用NSP任务。
- training on longer sequences:使用更长的句子训练。
- dynamically changing the masking pattern applied to the training data:动态地更换训练数据。
在具体的GLUE, RACE and SQuAD任务上使用的时候,不需要在GLUE 或SQuAD的数据上做multi-task finetuning。此外,这里使用了一个新的数据集CC-NEWS,可能是用来做自监督预训练的?
关键图表:本论文主要是讲述实验的,在模型上并没有重大创新,但是在技巧上,能给研究者一些启发。这里图标有点多,放在Pass2中看。
Pass2
1. Introduction
近期,相关的自监督训练方法发展很快,包括ELmo、GPT、BERT、XLM、XLNet,但其实我们很难证明它们提出的多项技术中,哪一些是最为有效的进步。因为这些模型的训练复杂度很高,而且都在一些各自的数据集训练,这些数据集大小迥异,因此使得模型本身的进展难以评价。本文对Bert进行重新研究,进行一些技术上的修改,例如:
- training the model longer, with bigger batches, over more data;
- removing the next sentence prediction objective;
- training on longer sequences;
- dynamically changing the masking pattern applied to the training data.
- 准备了CC-NEWS数据集,以作为大小旗鼓相当的数据集,用于比较训练。
相应的,我们得出了结论:
- 展示了BERT模型中提出重要的设计和训练技巧;并引入一些新的更好的技术,使得模型在下游任务表现更好;
- 用新的CC-NEWs数据集,证明使用更多的data预训练,能够提升在下游任务的效果;
- 正确的使用MLM预训练方法,能够使得其效果和最近提出的模型效果相当。
2.回顾BERT
BERT主要采用的技巧,就不在这里回顾了。。模型的输入是两个Segment的文本(两段话),中间用一个[SEP]隔开。任务是利用Masked Language model,做完形填空式的猜词语,以及Next Sentence Prediction,即判断两段话,是否来自于同一篇文章的上下两段。其它就是一些学习率、字符词表构建的问题。这里直接引用原文看看。

3.实验设置
4.训练过程分析
实验是基于 B E R T B A S E BERT_{BASE} BERTBASE的模型进行调试的。
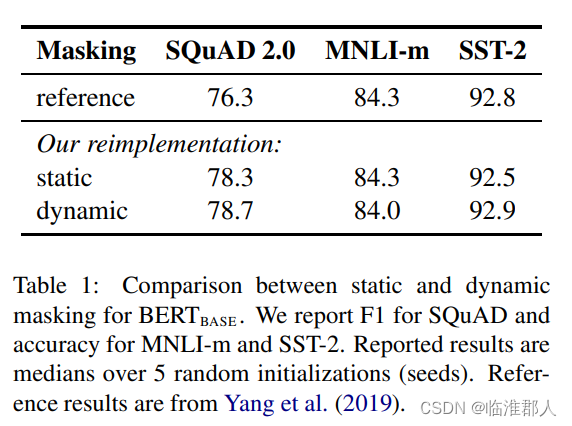
4.1 静态、动态Mask
首先是在做MLM任务时,数据的处理。原本的BERT模型训练的时候,使用的是静态的MASK,也就是在数据预处理的时候事先做好MASK。这里作者部署的静态MASK,稍微有一点变化,即对每一句话静态的选用多种不同的MASK方法,并对训练数据重复10次。
另外还有动态的方法,也就是每次训练的时候,都进行相应的MASK操作。
从结果上看,本文部署的方法效果都不错,都比原本的静态MASK方法好(Refence并不是原文的结果啊)。作者认为,动态的MASK在操作上比较高效一点,因此在后续实验中采用动态的MASK。
4.2 自监督输入与NSP任务
这一小节说的是不同的输入数据与NSP任务是否有用。因为有的研究者认为NSP任务很有用,而有的文章认为NSP任务没有什么用。
对应于下表中的前四个内容。
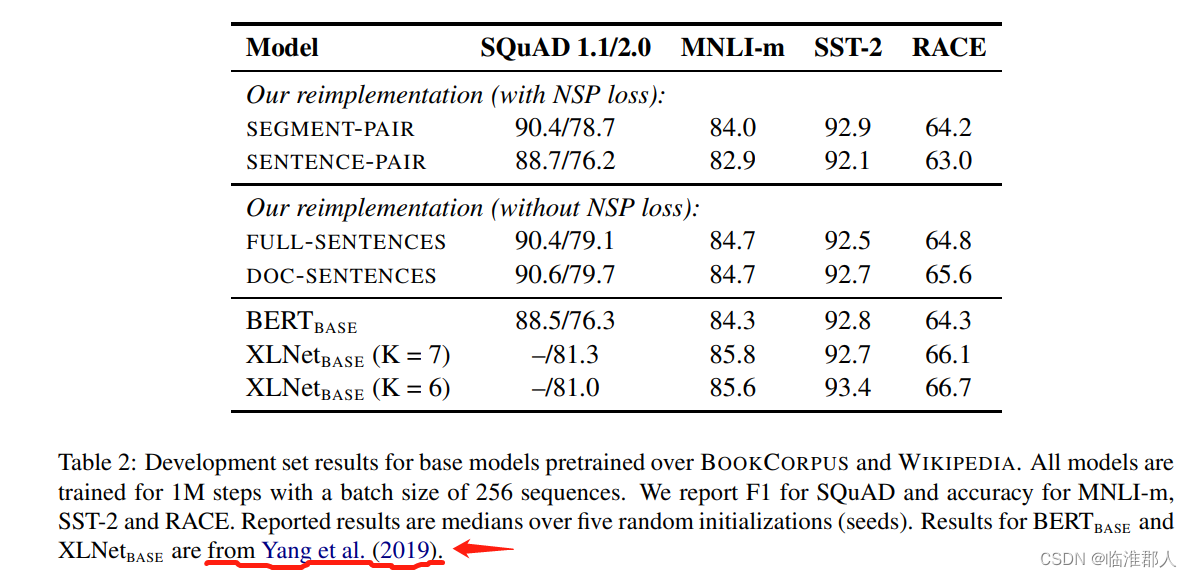
- Segment-Pair+NSP:和BERT一样,输入的是两个Segment语段,然后执行NSP任务。
- Sentence-Pair+NSP:输入的是两句话。一个Segment的语段可能由很多的语句组成,因此语句是很短的,远远比512个token短。这里采取提高Batch大小训练。
- Full-Sentences:不进行NSP的训练。输入的语段就是从文档中抽样得到的连续语句,即语句到达文档末尾后,可以继续从新的文档中采样。
- Doc-Sentences:不进行NSP的训练。输入的语段就是由单个文档的语句。
首先是比较输入的文档长度的影响,同样都具有NSP的损失:本文发现,使用单个句子组成的语段效果并不好。 作者认为语段短则不利于捕捉长距离的依赖。
其次是比较有无NSP损失的影响。可以看到,其实Doc-Sentence而没有NSP损失的情况,效果最好。也就是说,去掉NSP损失其实也不会损害模型的效果。
最后是考察没有NSP情况下,文档长度的影响。其中使用来自单文档的输入,效果比较好。
4.3 使用更大的Batch
有研究表明,在机器翻译任务中。使用更大的batch,并使用更大的学习率时,可以加速训练优化的速度,并且提高下游任务的效率。最近的研究也表明,BERT也具有这样的效果。
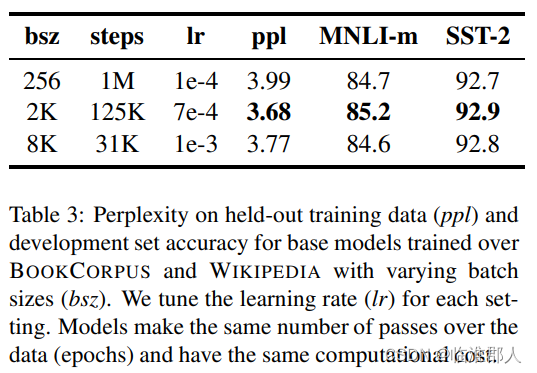
如上图中的实验,使用了不同的batchsize和训练的steps,这里其实是保持batchsize*steps相同,意思是保持相同的gradient accumulation。从结果上看,适当大的batchsize可以降低模型的困惑都,并提升模型的效果,不过效果确实比较微弱。但是值得注意的是,更大的batchsize,使得模型可以更好的并行训练。这里给出了如下的备注。

作者说,根据上面的结果,采用batchsize=8K进行训练。
4.4 文本编码方法
这里主要讨论的是,词表的构建方法。一般的,预料比较多的时候,采用BPE编码方法。即这是一种介于character和word级别的表达方法。一般的,BPE词表大小在10K到100K个subword单元之间。但是,词表的很大一部分都是由 unicode characters组成(没看懂这是什么?)。因此文献【1】提出了另一种BPE部署方式,使用bytes而不是unicode character作为subword单元的基础。这样的方法可以组成一个恰当大小的(50K units)的词表。
原本的BERT的词表大小是30K,而用【1】的方法,词表大小为50K。早期的实验表明,后者的效果不是很好。但是,本文相信【1】提出的universal encoding方法其实是更好,并且在实验中也使用这种方法。
5.下游实验
暂略
参考文献
【1】Alec Radford, Jeffrey Wu, Rewon Child, David Luan,Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. Technical report, OpenAI















 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









