








1 简介
本文根据2019年《Is Word Segmentation Necessary for Deep Learning of Chinese Representations?》翻译总结,即汉语的深度学习是否有必要进行分词。
英文因为其天然的用空格分割,不需要分词,而中文是连在一起的,所以存在了分词(Chinese Word Segmentation (CWS))。现在也有很多开源的分词工具。
在处理中文文本时,通常第一步是进行分词,但它是否有效很少被探索。我们发现不分词反而比分词效果好。
采用分词的模型(word-based models)是数据稀疏的,数据稀疏意味着大量的参数存在,容易产生过拟合。同时因为其不可能保存一个巨大的词库,导致许多词是OOV(out-of-vocabulary),存在OOV问题。分词模型也不能很好的跨领域适配,如在一个训练数据集上训练后,不能很好的准确预测另一个不同分布的数据集。本文分词采用开源的jiaba。
我们不基于分词的模型叫做char-based models。
我们char-based模型在下面4个任务中超过基于分词(word-based)的模型。可以分词不一定有必要。
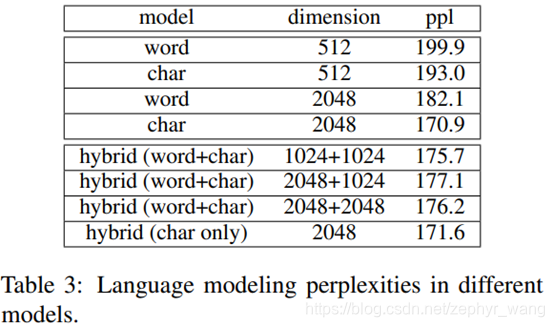
2 语言模型实验结果
该模型指根据前面的文本预测接下来的文本。可以看到基于char的模型ppl最好(低表示好),混合模型(word+char)的效果介于char模型和word模型之间。
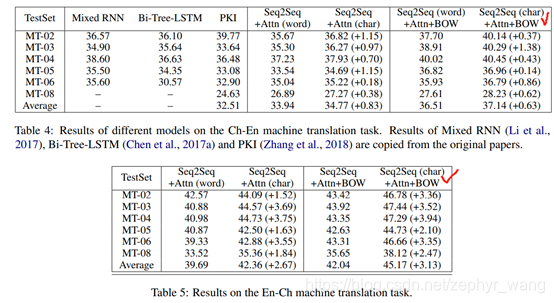
3 机器翻译实验结果
可以看出基于char的模型好于基于word的。
4 句子匹配实验结果
句子匹配指给定两个句子,看它们两的意思是不是一样。可以看出基于char的模型好于基于word的。

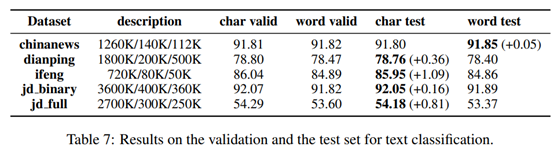
5 文本分类
可以看出基于char的模型好于基于word的,除了第一个只差0.05外。
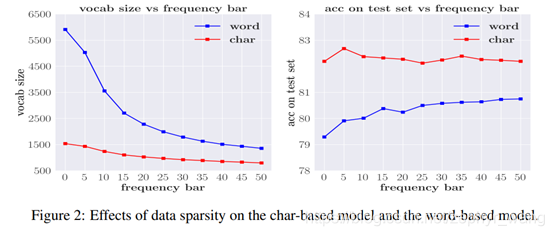
6 稀疏性分析
从下图左图可以看到,基于word的词汇表很大,较稀疏;从右图看出,基于word的模型不断的提高词的频率(即在这个频率之下的词会被标记为UNK),模型效果才更好,也反应出存在很多低频数据,即稀疏性。此外右图可以看到基于char的准确率比基于word的高,而且在频率限制到5时就准确率达到最高了,没有很多低频数据,数据不稀疏。
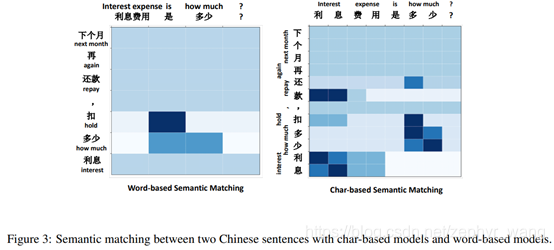
7 注意力展示
Word-based的模型,分词“利息费用”没有和“利息”建立很好的注意力关系。Char-base的模型,“利 息”和“利息”建立了很好的注意力关系

















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









